手把手丨我们在UCL找到了一个糖尿病数据集,用机器学习预测糖尿病(三)
梯度提升:
from sklearn.ensemble import GradientBoostingClassifier
gb=GradientBoostingClassifier(random_state=0)
gb.fit(x_train,y_train)
print("Accuracy on training set:{:.3f}".format(gb.score(x_train,y_train)))
print("Accuracy on test set:{:.3f}".format(gb.score(x_test,y_test)))
Accuracy on training set:0.917
Accuracy on test set:0.792
我们可能是过拟合了。为了降低这种过拟合,我们可以通过限制最大深度或降低学习速率来进行更强的修剪:
gb1=GradientBoostingClassifier(random_state=0,max_depth=1)
gb1.fit(x_train,y_train)
print("Accuracy on training set:{:.3f}".format(gb1.score(x_train,y_train)))
print("Accuracy on test set:{:.3f}".format(gb1.score(x_test,y_test)))
Accuracy on training set:0.804
Accuracy on test set:0.781
gb2=GradientBoostingClassifier(random_state=0,learning_rate=0.01)
gb2.fit(x_train,y_train)
print("Accuracy on training set:{:.3f}".format(gb2.score(x_train,y_train)))
print("Accuracy on test set:{:.3f}".format(gb2.score(x_test,y_test)))
Accuracy on training set:0.802
Accuracy on test set:0.776
如我们所期望的,两种降低模型复杂度的方法都降低了训练集的准确度。可是测试集的泛化性能并没有提高。
尽管我们对这个模型的结果不是很满意,但我们还是希望通过特征重要度的可视化来对模型做更进一步的了解。
plot_feature_importances_diabetes(gb1)
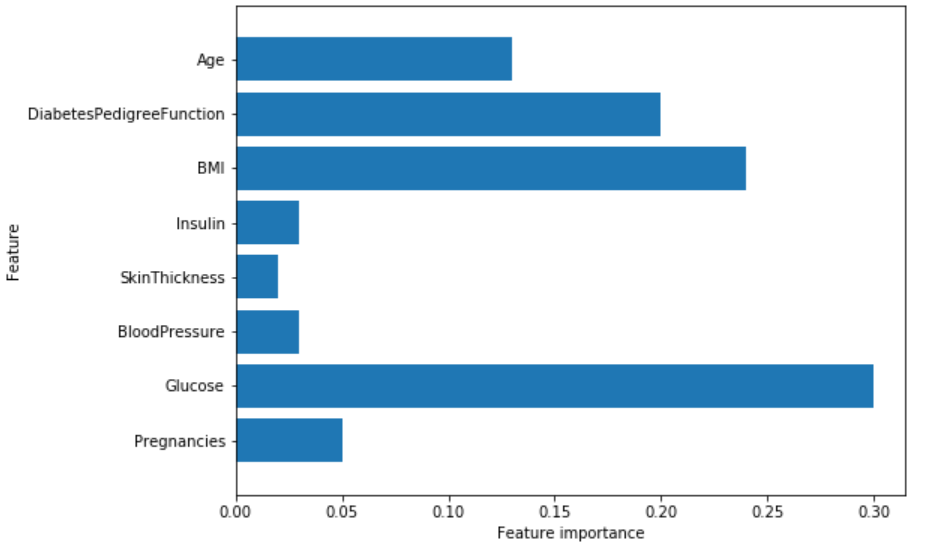
我们可以看到,梯度提升树的特征重要度与随机森林的特征重要度有点类似,同时它给这个模型的所有特征赋了重要度值。
支持向量机:
from sklearn.svm import SVC
svc=SVC()
svc.fit(x_train,y_train)
print("Accuracy on training set:{:.2f}".format(svc.score(x_train,y_train)))
print("Accuracy on test set:{:.2f}".format(svc.score(x_test,y_test)))
Accuracy on training set:1.00
Accuracy on test set:0.65
这个模型过拟合比较明显,虽然在训练集中有一个完美的表现,但是在测试集中仅仅有65%的准确度。
SVM要求所有的特征要在相似的度量范围内变化。我们需要重新调整各特征值尺度使其基本上在同一量表上。
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
x_train_scaled=scaler.fit_transform(x_train)
x_test_scaled=scaler.fit_transform(x_test) svc=SVC()
svc.fit(x_train_scaled,y_train) print("Accuracy on training set:{:.2f}".format(svc.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.2f}".format(svc.score(x_test_scaled,y_test)))
Accuracy on training set:0.77
Accuracy on test set:0.77
数据的度量标准化后效果大不同!现在我们的模型在训练集和测试集的结果非常相似,这其实是有一点过低拟合的,但总体而言还是更接近100%准确度的。这样来看,我们还可以试着提高C值或者gamma值来配适更复杂的模型。
svc=SVC(C=1000)
svc.fit(x_train_scaled,y_train) print("Accuracy on training set:{:.2f}".format(svc.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.2f}".format(svc.score(x_test_scaled,y_test)))
Accuracy on training set:0.79
Accuracy on test set:0.80
提高了C值后,模型效果确实有一定提升,测试集准确度提至79.7%。
深度学习:
from sklearn.neural_network import MLPClassifier
mlp=MLPClassifier(random_state=42)
mlp.fit(x_train,y_train) print("Accuracy on training set:{:.2f}".format(mlp.score(x_train,y_train)))
print("Accuracy on test set:{:.2f}".format(mlp.score(x_test,y_test)))
Accuracy on training set:0.71
Accuracy on test set:0.67
多层神经网络(MLP)的预测准确度并不如其他模型表现的好,这可能是数据的尺度不同造成的。深度学习算法同样也希望所有输入的特征在同一尺度范围内变化。理想情况下,是均值为0,方差为1。所以,我们必须重新标准化我们的数据,以便能够满足这些需求。
from sklearn.preprocessing import StandardScaler scaler=StandardScaler()
x_train_scaled=scaler.fit_transform(x_train)
x_test_scaled=scaler.fit_transform(x_test) mlp=MLPClassifier(random_state=0)
mlp.fit(x_train_scaled,y_train) print("Accuracy on training set:{:.3f}".format(mlp.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.3f}".format(mlp.score(x_test_scaled,y_test)))
Accuracy on training set:0.823
Accuracy on test set:0.802
让我们增加迭代次数:
mlp=MLPClassifier(max_iter=1000,random_state=0)
mlp.fit(x_train_scaled,y_train) print("Accuracy on training set:{:.3f}".format(mlp.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.3f}".format(mlp.score(x_test_scaled,y_test)))
Accuracy on training set:0.877
Accuracy on test set:0.755
增加迭代次数仅仅提升了训练集的性能,而对测试集没有效果。
让我们调高alpha参数并且加强权重的正则化。
mlp=MLPClassifier(max_iter=1000,alpha=1,random_state=0)
mlp.fit(x_train_scaled,y_train) print("Accuracy on training set:{:.3f}".format(mlp.score(x_train_scaled,y_train)))
print("Accuracy on test set:{:.3f}".format(mlp.score(x_test_scaled,y_test)))
Accuracy on training set:0.795
Accuracy on test set:0.792
这个结果是好的,但我们无法更进一步提升测试集准确度。因此,到目前为止我们最好的模型是在数据标准化后的默认参数深度学习模型。最后,我们绘制了一个在糖尿病数据集上学习的神经网络的第一层权重热图。
plt.figure(figsize=(20,5))
plt.imshow(mlp.coefs_[0],interpolation='none',cmap='viridis')
plt.yticks(range(8),diabetes_features)
plt.xlabel("Columns in weight matrix")
plt.ylabel("Input feature")
plt.colorbar()
从这个热度图中,快速指出哪个或哪些特征的权重较高或较低是不容易的。
设置正确的参数非常重要:
本文我们练习了很多种不同的机器学习模型来进行分类和回归,了解了它们的优缺点是什么,以及如何控制其模型复杂度。我们同样看到,对于许多算法来说,设置正确的参数对于性能良好是非常重要的。
手把手丨我们在UCL找到了一个糖尿病数据集,用机器学习预测糖尿病(三)的更多相关文章
- 【转】手把手教你把Vim改装成一个IDE编程环境(图文)
手把手教你把Vim改装成一个IDE编程环境(图文) By: 吴垠 Date: 2007-09-07 Version: 0.5 Email: lazy.fox.wu#gmail.com Homepage ...
- POJ:1833 按字典序找到下一个排列:
http://poj.org/problem?id=1833 按照字典的顺序(a-z) (1-9),可以得出任意两个数字串的大小.比如“123”, 最小的是“123”(从小到大),最大的是“321”( ...
- 一个普通的 Zepto 源码分析(三) - event 模块
一个普通的 Zepto 源码分析(三) - event 模块 普通的路人,普通地瞧.分析时使用的是目前最新 1.2.0 版本. Zepto 可以由许多模块组成,默认包含的模块有 zepto 核心模块, ...
- Java集合-5. (List)已知有一个Worker 类如下: 完成下面的要求 1) 创建一个List,在List 中增加三个工人,基本信息如下: 姓名 年龄 工资 zhang3 18 3000 li4 25 3500 wang5 22 3200 2) 在li4 之前插入一个工人,信息为:姓名:zhao6,年龄:24,工资3300 3) 删除wang5 的信息 4) 利用for 循
第六题 5. (List)已知有一个Worker 类如下: public class Worker { private int age; private String name; private do ...
- 给定一个字符串里面只有"R" "G" "B" 三个字符,请排序,最终结果的顺序是R在前 G中 B在后。 要求:空间复杂度是O(1),且只能遍历一次字符串。
题目:给定一个字符串里面只有"R" "G" "B" 三个字符,请排序,最终结果的顺序是R在前 G中 B在后. 要求:空间复杂度是O(1),且 ...
- Linux下一个最简单的不依赖第三库的的C程序(1)
如下代码是一段汇编代码,虽然标题中使用了C语言这个词语,但下面确实是一段汇编代码,弄清楚了这个代码,后续的知识点才会展开. simple_asm.s: #PURPOSE: Simple program ...
- 我的第一个netcore2.2 api项目搭建(三)续
上一章快速陈述了自定义验证功能添加的过程,我的第一个netcore2.2 api项目搭建(三) 但是并没有真正的去实现,这一章将要实现验证功能的添加. 这一章实现目标三:jwt认证授权添加 在netc ...
- 好几个div(元素)找到最后一个
<div> <div></div> <div></div> <div></div> </div> //找 ...
- 「Netty实战 02」手把手教你实现自己的第一个 Netty 应用!新手也能搞懂!
大家好,我是 「后端技术进阶」 作者,一个热爱技术的少年. 很多小伙伴搞不清楚为啥要学习 Netty ,今天这篇文章开始之前,简单说一下自己的看法: @ 目录 服务端 创建服务端 自定义服务端 Cha ...
随机推荐
- Java实现Base64加密
阅读本文约“2.5分钟” Java加解密系列,介绍Java加密解密的基础知识,并使用Base64算法实现加解密. 对于加密在企业中是非常常见的,就如邮件的传输,每个企业都会有自己设置安全方式,设置加密 ...
- java多线程高并发
旭日Follow_24 的CSDN 博客 ,全文地址请点击: https://blog.csdn.net/xuri24/article/details/81293321 “高并发和多线程”总是被一起提 ...
- linux 下修改mysql下root 权限来允许远程连接
MySQL默认只允许root帐户在本地登录,如果要在其它机器上连接mysql,必须修改root允许远程连接. 其操作简单,如下所示: 1. 进入mysql: /usr/local/mysql/bin/ ...
- 三、HTTP基础路由详解
1.一次请求的完整实现过程 2.基础路由 Route::get($uri,$callback); Route::post($uri,$callback); Route::put($uri,$callb ...
- blfs(systemd版本)学习笔记-构建ibus-libpinyin使用中文输入法
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! 一.包的下载地址 1.libpinyin 下载地址:http://deb.debian.org/debian/pool/main ...
- 一位ML工程师构建深度神经网络的实用技巧
一位ML工程师构建深度神经网络的实用技巧 https://mp.weixin.qq.com/s/2gKYtona0Z6szsjaj8c9Vg 作者| Matt H/Daniel R 译者| 婉清 编辑 ...
- 关于相机拍照获取图片onActivityResult返回data 为null的问题
调用相机拍摄方法 /** * capture new image */ protected void selectPicFromCamera() { if (!EaseCommonUtils.isSd ...
- Android studio 下的SDK Manager只显示已安装包的情况
原因是连接不上Google的更新服务器: 解决方法: 选择第三个Options: 修改Http Proxy Server: mirrors.neusoft.edu.cn Http Proxy Port ...
- "BLAME" is out.
The latest feature animation film "BLAME" is watchable on the Netflix. Rendering was done ...
- Android IPC机制(一)开启多进程
1. 为何要开启多进程 为何开启android应用要开启多进程,主要有以下几点: 单进程所分配的内存不够,需要更多的内存.在早期android系统只为一个单进程的应用分配了16M的可用内存,随着手机的 ...