ELMO模型(Deep contextualized word representation)
1 概述
word embedding 是现在自然语言处理中最常用的 word representation 的方法,常用的word embedding 是word2vec的方法,然而word2vec本质上是一个静态模型,也就是说利用word2vec训练完每个词之后,词的表示就固定了,之后使用的时候,无论新句子上下文的信息是什么,这个词的word embedding 都不会跟随上下文的场景发生变化,这种情况对于多义词是非常不友好的。例如英文中的 Bank这个单词,既有河岸的意思,又有银行的意思,但是在利用word2vec进行word embedding 预训练的时候会获得一个混合多种语义的固定向量表示。即使在根据上下文的信息能明显知道是“银行”的情况下,它对应的word embedding的内容也不会发生改变。
ELMO的提出就是为了解决这种语境问题,动态的去更新词的word embedding。ELMO的本质思想是:事先用语言模型在一个大的语料库上学习好词的word embedding,但此时的多义词仍然无法区分,不过没关系,我们接着用我们的训练数据(去除标签)来fine-tuning 预训练好的ELMO 模型。作者将这种称为domain transfer。这样利用我们训练数据的上下文信息就可以获得词在当前语境下的word embedding。作者给出了ELMO 和Glove的对比
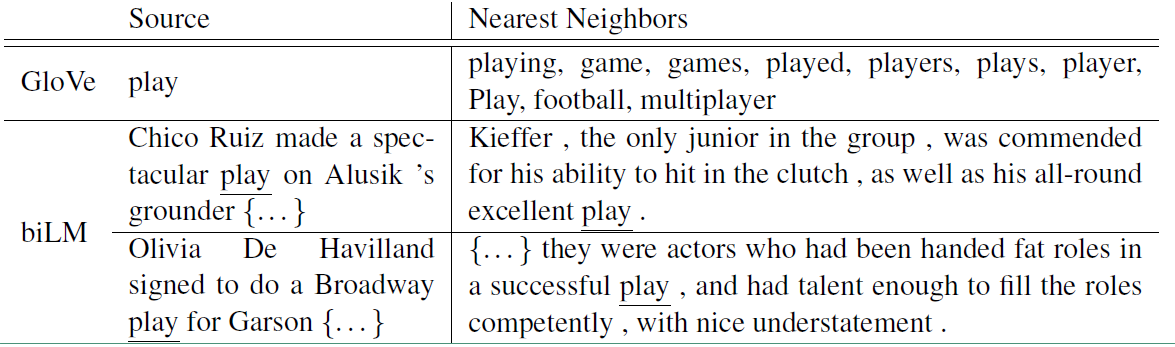
对于Glove训练出来的word embedding来说,多义词play,根据他的embedding 找出的最接近的其他单词大多数几种在体育领域,这主要是因为训练数据中包含play的句子大多数来源于体育领域,之后在其他语境下,play的embedding依然是和体育相关的。而使用ELMO,根据上下文动态调整后的embedding不仅能够找出对应的“表演”相同的句子,还能保证找出的句子中的play对应的词性也是相同的。接下来看看ELMO是怎么实现这样的结果的。
2 模型结构
ELMO 基于语言模型的,确切的来说是一个 Bidirectional language models,也是一个 Bidirectional LSTM结构。我们要做的是给定一个含有N个tokens的序列
$ {t_1, t_2, ..., t_N}$
其前向表示为:

反向表示为:
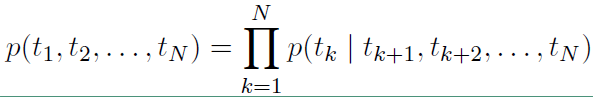
从上面的联合概率来看是一个典型的语言模型,前向利用上文来预测下文,后向利用下文来预测上文。假设输入的token是 $ x_k^{LM}$,在每一个位置 $k$ ,每一层LSTM 上都输出相应的context-dependent的表征 $\overrightarrow{h}_{k, j}^{LM}$。这里
$j = 1, 2, ..., L$, $L$表示LSTM的层数。顶层的LSTM 输出 $\overrightarrow{h}_{k, L}^{LM}$ ,通过softmax层来预测下一个 $token_{k+1}$。
对数似然函数表示如下:
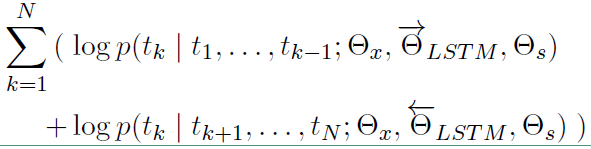
模型的结构图如下:
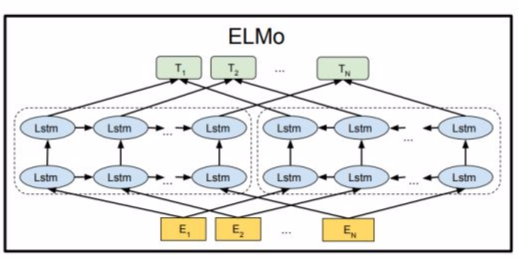
ELMO 模型不同于之前的其他模型只用最后一层的输出值来作为word embedding的值,而是用所有层的输出值的线性组合来表示word embedding的值。
对于每个token,一个L层的biLM要计算出 $2L + 1$ 个表征:
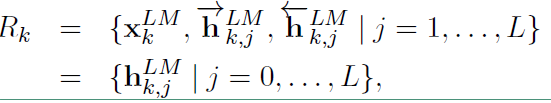
在上面 $ X_k^{LM} $ 等于 $ h_{k, j} ^ {LM} $,表示的是token层的值。
在下游任务中会把$R_k$ 压缩成一个向量:
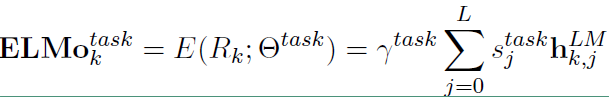
其中 $s_j^{task}$ 是softmax标准化权重,$\gamma^{task}$ 是缩放系数,允许任务模型去缩放整个ELMO向量。
ELMO的使用主要有三步:
1)在大的语料库上预训练 biLM 模型。模型由两层bi-LSTM 组成,模型之间用residual connection 连接起来。而且作者认为低层的bi-LSTM层能提取语料中的句法信息,高层的bi-LSTM能提取语料中的语义信息。
2)在我们的训练语料(去除标签),fine-tuning 预训练好的biLM 模型。这一步可以看作是biLM的domain transfer。
3)利用ELMO 产生的word embedding来作为任务的输入,有时也可以即在输入时加入,也在输出时加入。
ELMO 在六项任务上取得了the state of the art ,包括问答,情感分析等任务。总的来说,ELMO提供了词级别的动态表示,能有效的捕捉语境信息,解决多义词的问题。
ELMO模型(Deep contextualized word representation)的更多相关文章
- 论文翻译——Deep contextualized word representations
Abstract We introduce a new type of deep contextualized word representation that models both (1) com ...
- 深度学习论文笔记-Deep Learning Face Representation from Predicting 10,000 Classes
来自:CVPR 2014 作者:Yi Sun ,Xiaogang Wang,Xiaoao Tang 题目:Deep Learning Face Representation from Predic ...
- 翻译 Improved Word Representation Learning with Sememes
翻译 Improved Word Representation Learning with Sememes 题目 Improved Word Representation Learning with ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- NLP直播-1 词向量与ELMo模型
翻车2次,试水2次,今天在B站终于成功直播了. 人气11万. 主要讲了语言模型.词向量的训练.ELMo模型(深度.双向的LSTM模型) 预训练与词向量 词向量的常见训练方法 深度学习与层次表示 LST ...
- 理解GloVe模型(Global vectors for word representation)
理解GloVe模型 概述 模型目标:进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息.输入:语料库输出:词向量方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学 ...
- 【NLP CS224N笔记】Lecture 3 GloVe: Global Vectors for Word Representation
I. 复习word2vec的核心思路 1. Skip-gram 模型示意图: 2.word vectors的随机梯度 假设语料库中有这样一行句子: I love deep learning and N ...
- Learning a Deep Compact Image Representation for Visual Tracking
这篇博客对论文进行了部分翻译http://blog.csdn.net/vintage_1/article/details/19546953,不过个人觉得博主有些理解有误. 这篇博客简单分析了代码htt ...
随机推荐
- 【设计模式】不同设计模式体现IOC控制反转
使用过Spring的开发者应该都对IOC控制反转功能有所了解,最开始学习时应该都知道使用依赖注入来实现IOC的功能,本文来介绍使用IOC控制反转思想的几种设计模式. 依赖注入来实现IOC 注入依赖是I ...
- 使用EF保存数据时 提示: 其他信息: 对一个或多个实体的验证失败。有关详细信息,请参阅“EntityValidationErrors”属性。
错误提示: 解决方法: →使用try...catch捕获→在catch所在行打上断点,运行,对ex添加监视或者运行到ex的时候 按Shift+f9天假快速监视→在EntityValidationEr ...
- python名片管理
python名片管理是我根据视频自己敲敲的代码,后续学习会持续更新 代码 card_main.py import card_tools # 无限循环,由用户决定什么时候退出 while True: # ...
- Git学习(一)
版本控制系统是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统.版本控制系统不仅可以应用于软件源代码的文本文件,而且可以对任何类型的文件进行版本控制. 一.集中式版本控制系统 v.s ...
- K8S 部署 ingress-nginx (一) 原理及搭建
Kubernetes 暴露服务的有三种方式,分别为 LoadBlancer Service.NodePort Service.Ingress.官网对 Ingress 的定义为管理对外服务到集群内服务之 ...
- [CSS] 点击事件触发的动画
源码 https://github.com/YouXianMing/CSS-Animations/tree/master/Event 效果 细节 1) 一个完整的可回溯的动画至少包括了两种状态,以及两 ...
- springboot 数据验证
不能相信前端传过来的任何数据 一定不能相信前端传过来的任何数据 绝对不能相信前端传过来的任何数据 @JsonFormat 时间必须是指定的格式(这里是接收参数格式,不是取数据来格式化) @Null 必 ...
- ViewPager结合Fragment进行无限滑动
实现ViewPager结合Fragment实现无限循环切换,这里也是在适配器里面进行的,当然使用滑动监听也能够实现 import android.support.v4.app.Fragment; im ...
- 使用VSTS的Git进行版本控制(五)——从Team Services Portal管理分支
使用VSTS的Git进行版本控制(五)--从Team Services Portal管理分支 任务1:创建新分支 1.登录Visual Studio Team Services账号 2.打开Code ...
- JavaScript中,JSON格式的字符串与JSON格式的对象相互转化
前言:JSON是一个独立于任何语言的数据格式,因此,严格来说,没有“JSON对象”和“JSON字符串”这个说法(然而”菜鸟教程“和”W3school“使用了“JSON对象”和“JSON字符串”这个说法 ...