VGG-Net
目的
这篇文章是以比赛为目的——解决ImageNet中的1000类图像分类和定位问题。在此过程中,作者做了六组实验,对应6个不同的网络模型,这六个网络深度逐渐递增的同时,也有各自的特点。实验表明最后两组,即深度最深的两组16和19层的VGGNet网络模型在分类和定位任务上的效果最好。作者因此斩获2014年分类第二(第一是GoogLeNet),定位任务第一。
其中,模型的名称——“VGG”代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人。
VGG16包含16层,VGG19包含19层。一系列的VGG在最后三层的全连接层上完全一样,整体结构上都包含5组卷积层,卷积层之后跟一个MaxPool。所不同的是5组卷积层中包含的级联的卷积层越来越多。
任务背景

深度神经网络一般由卷积部分和全连接部分构成。卷积部分一般包含卷积(可以有多个不同尺寸的核级联组成)、池化、Dropout等,其中Dropout层必须放在池化之后。全连接部分一般最多包含2到3个全连接,最后通过Softmax得到分类结果,由于全连接层参数量大,现在倾向于尽可能的少用或者不用全连接层。神经网络的发展趋势是考虑使用更小的过滤器,如1*1,3*3等;网络的深度更深(2012年AlenNet8层,2014年VGG19层、GoogLeNet22层,2015年ResNet152层);减少全连接层的使用,以及越来越复杂的网络结构,如GoogLeNet引入的Inception模块结构。
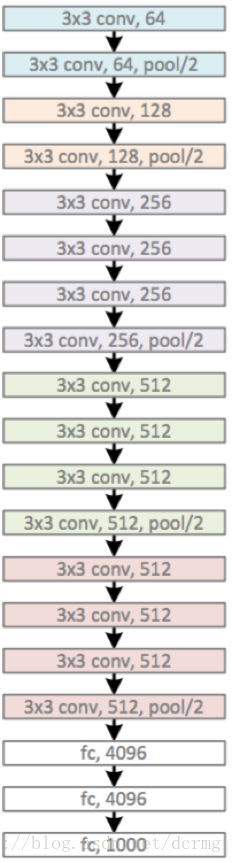
VGG在AlexNet基础上做了改进,整个网络都使用了同样大小的3*3卷积核尺寸和2*2最大池化尺寸,网络结果简洁。一系列VGG模型的结构图:

基本思想及其过程
VGGNet网络配置情况:
为了在公平的原则下探究网络深度对模型精确度的影响,所有卷积层有相同的配置,即卷积核大小为3x3,步长为1,填充为1;共有5个最大池化层,大小都为2x2,步长为2;共有三个全连接层,前两层都有4096通道,第三层共1000路及代表1000个标签类别;最后一层为softmax层;所有隐藏层后都带有ReLU非线性激活函数;经过实验证明,AlexNet中提出的局部响应归一化(LRN)对性能提升并没有什么帮助,而且还浪费了内存的计算的损耗。
下图为VGG-16的结构图:
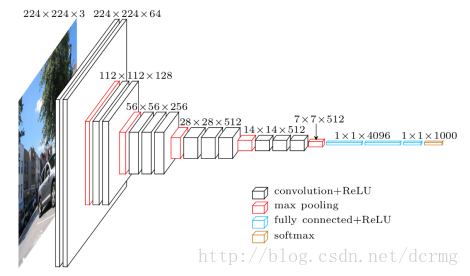
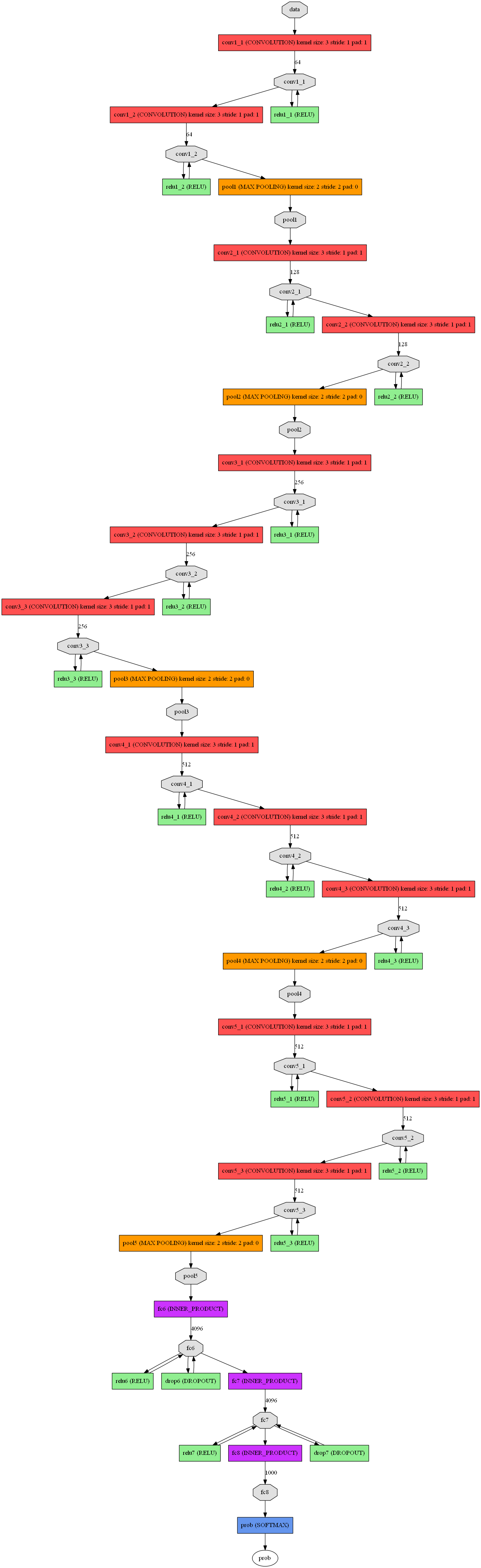
VGG16包含16层,VGG19包含19层。一系列的VGG在最后三层的全连接层上完全一样,整体结构上都包含5组卷积层,卷积层之后跟一个MaxPool。所不同的是5组卷积层中包含的级联的卷积层越来越多。
AlexNet中每层卷积层中只包含一个卷积,卷积核的大小是7*7,。在VGGNet中每层卷积层中包含2~4个卷积操作,卷积核的大小是3*3,卷积步长是1,池化核是2*2,步长为2,。VGGNet最明显的改进就是降低了卷积核的尺寸,增加了卷积的层数。
使用多个较小卷积核的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面作者认为相当于进行了更多的非线性映射,增加了网络的拟合表达能力。
VGGNet的图片预处理
VGG的输入224*224的RGB图像,预处理就是每一个像素减去了均值。
VGG的多尺度训练
VGGNet使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224′224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。VGG作者在尝试使用LRN之后认为LRN的作用不大,还导致了内存消耗和计算时间增加。
虽然网络层数加深,但VGG在训练的过程中比AlexNet收敛的要快一些,主要因为:
(1)使用小卷积核和更深的网络进行的正则化;
(2)在特定的层使用了预训练得到的数据进行参数的初始化。对于较浅的网络,如网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
小卷积核
说到网络深度,这里就不得不提到卷积,虽然AlexNet有使用了11x11和5x5的大卷积,但大多数还是3x3卷积,对于stride=4的11x11的大卷积核,我认为在于一开始原图的尺寸很大因而冗余,最为原始的纹理细节的特征变化用大卷积核尽早捕捉到,后面的更深的层数害怕会丢失掉较大局部范围内的特征相关性,后面转而使用更多3x3的小卷积核(和一个5x5卷积)去捕捉细节变化。
而VGGNet则清一色使用3x3卷积。因为卷积不仅涉及到计算量,还影响到感受野。前者关系到是否方便部署到移动端、是否能满足实时处理、是否易于训练等,后者关系到参数更新、特征图的大小、特征是否提取的足够多、模型的复杂度和参数量等等。
计算量
在计算量这里,为了突出小卷积核的优势,我拿同样conv3x3、conv5x5、conv7x7、conv9x9和conv11x11,在224x224x3的RGB图上(设置pad=1,stride=4,output_channel=96)做卷积,卷积层的参数规模和得到的feature map的大小如下:
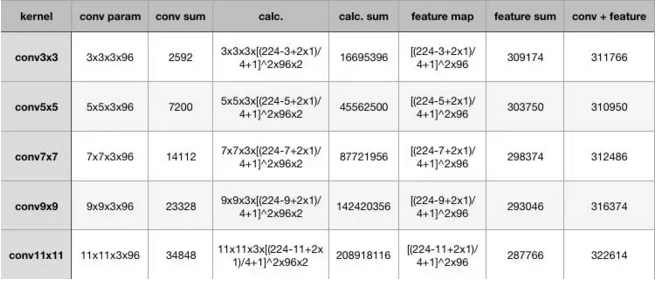
从上表可以看出,大卷积核带来的特征图和卷积核得参数量并不大,无论是单独去看卷积核参数或者特征图参数,不同kernel大小下这二者加和的结构都是30万的参数量,也就是说,无论大的卷积核还是小的,对参数量来说影响不大甚至持平。
增大的反而是卷积的计算量,在表格中列出了计算量的公式,最后要乘以2,代表乘加操作。为了尽可能证一致,这里所有卷积核使用的stride均为4,可以看到,conv3x3、conv5x5、conv7x7、conv9x9、conv11x11的计算规模依次为:1600万,4500万,1.4亿、2亿,这种规模下的卷积,虽然参数量增长不大,但是计算量是惊人的。
总结一下,我们可以得出两个结论:
- 同样stride下,不同卷积核大小的特征图和卷积参数差别不大;
- 越大的卷积核计算量越大。
其实对比参数量,卷积核参数的量级在十万,一般都不会超过百万。相比全连接的参数规模是上一层的feature map和全连接的神经元个数相乘,这个计算量也就更大了。其实一个关键的点——多个小卷积核的堆叠比单一大卷积核带来了精度提升,这也是最重要的一点。
感受野
说完了计算量我们再来说感受野。这里给出一张VGG作者的PPT,作者在VGGNet的实验中只用了两种卷积核大小:1x1和3x3。作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。
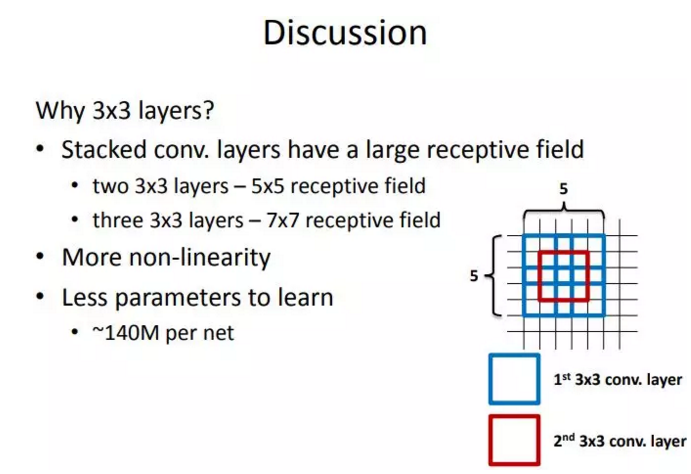
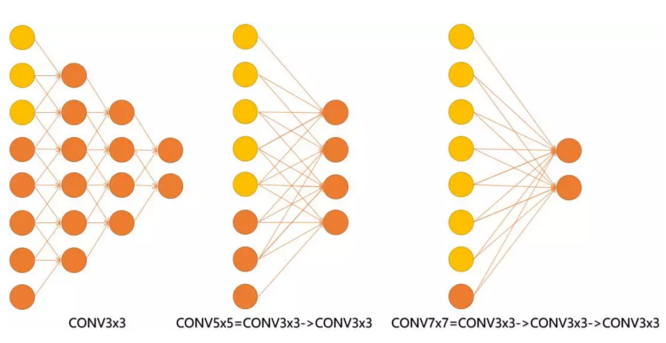
见下图,输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
- input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
- input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
或者我们也可以说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层(也就是输入)是7。
此外,倒着看网络,也就是backprop的过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。在分割问题中卷积核的大小对结果有一定的影响,在上图三层的conv3x3中,最后一个神经元的计算是基于第一层输入的7个神经元,换句话说,反向传播时,该层会影响到第一层conv3x3的前7个参数。从输出层往回forward同样的层数下,大卷积影响(做参数更新时)到的前面的输入神经元越多。
优点
既然说到了VGG清一色用小卷积核,结合作者和自己的观点,这里整理出小卷积核比用大卷积核的三点优势:
更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,更多的卷积核的使用可使决策函数更加具有辨别能力,此外就卷积本身的作用而言,3x3比7x7就足以捕获特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化。主要在于3个堆叠起来后,三个3x3近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,(特征多样性和参数参数量的增大)使得网络容量更大(关于model capacity,AlexNet的作者认为可以用模型的深度和宽度来控制capacity),对于不同类别的区分能力更强(此外,从模型压缩角度也是要摒弃7x7,用更少的参数获得更深更宽的网络,也一定程度代表着模型容量,后人也认为更深更宽比矮胖的网络好);
卷积层的参数减少。相比5x5、7x7和11x11的大卷积核,3x3明显地减少了参数量,这点可以回过头去看上面的表格。比方input channel数和output channel数均为C,那么3层conv3x3卷积所需要的卷积层参数是:3x(Cx3x3xC)=27C^2,而一层conv7x7卷积所需要的卷积层参数是:Cx7x7xC=49C^2。conv7x7的卷积核参数比conv3x3多了(49-27)/27x100% ≈ 81%;
小卷积核代替大卷积核的正则作用带来性能提升。作者用三个conv3x3代替一个conv7x7,认为可以进一步分解(decomposition)原本用7x7大卷积核提到的特征,这里的分解是相对于同样大小的感受野来说的。关于正则的理解我觉得还需要进一步分析。
其实最重要的还是多个小卷积堆叠在分类精度上比单个大卷积要好。
小池化核
这里的“小”是相对于AlexNet的3x3的池化核来说的。不过在说池化前,先说一下CS231n的博客里的描述网络结构的layer pattern,一般常见的网络都可以表示为:INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC的形式,其中,?表示pool是一个可选项。这样的pattern因为可以对小卷积核堆叠,很自然也更适合描述深层网络的构建,例如INPUT -> FC表示一个线性分类器。
不过从layer pattern中的[[CONV -> RELU]*N -> POOL?]*M部分,可以看出卷积层一般后面接完激活函数就紧跟池化层。对于这点我的理解是,池化做的事情是根据对应的max或者average方式进行特征筛选,还是在做特征工程上的事情。
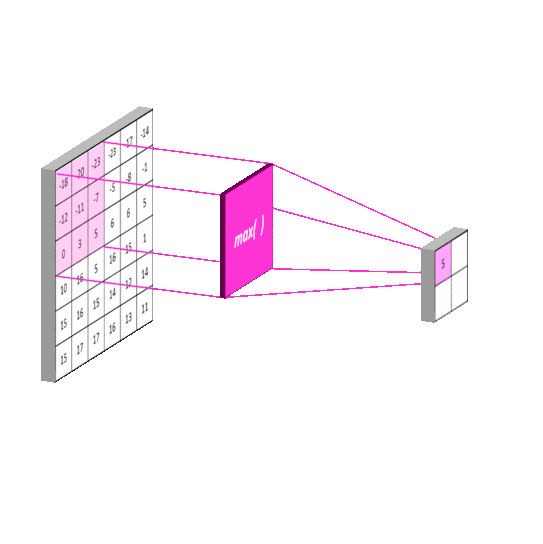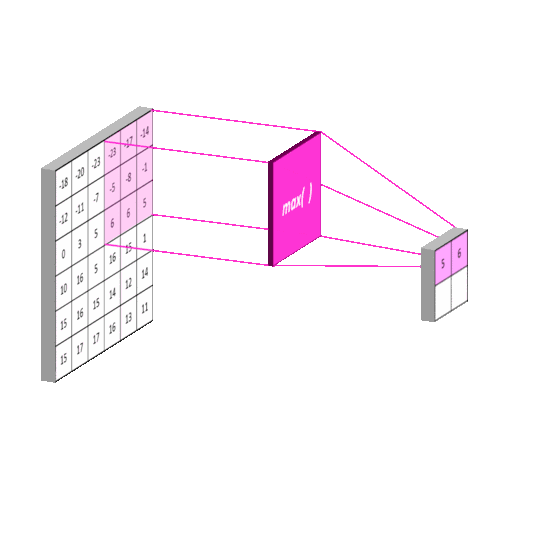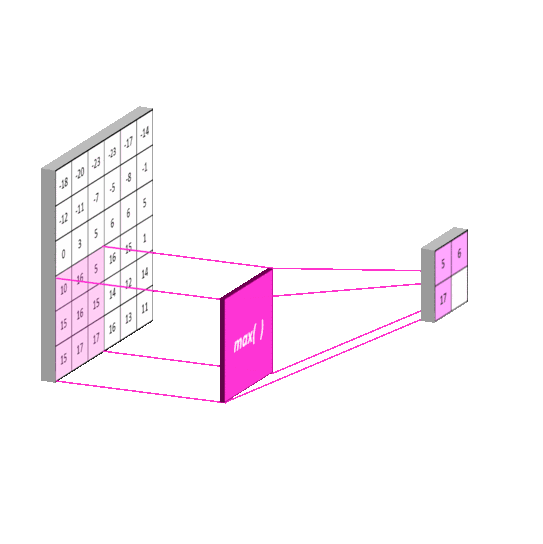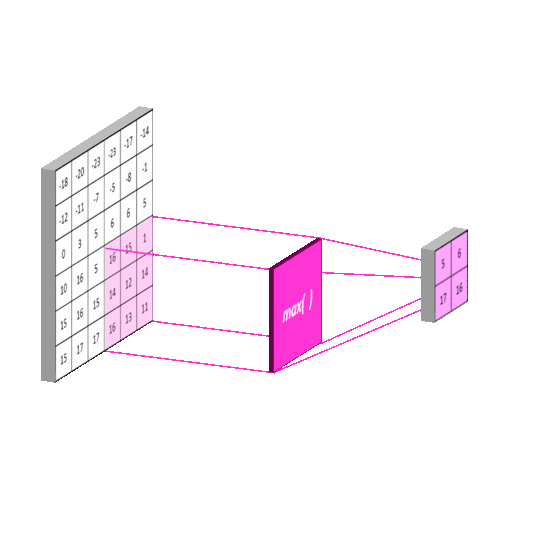
2012年的AlexNet,其pooling的kernel size全是奇数,里面所有池化采用kernel size为3x3,stride为2的max-pooling。而VGGNet所使用的max-pooling的kernel size均为2x2,stride为2的max-pooling。pooling kernel size从奇数变为偶数。小kernel带来的是更细节的信息捕获,且是max-pooling更见微的同时进一步知躇。
在当时也有average pooling,但是在图像任务上max-pooling的效果更胜一筹,所以图像大多使用max-pooling。在这里我认为max-pooling更容易捕捉图像上的变化,梯度的变化,带来更大的局部信息差异性,更好地描述边缘、纹理等构成语义的细节信息,这点尤其体现在网络可视化上。
VGGNet改进点总结
一、使用了更小的3*3卷积核,和更深的网络。两个3*3卷积核的堆叠相对于5*5卷积核的视野,三个3*3卷积核的堆叠相当于7*7卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3*3结构只有7*7结构参数数量的(3*3*3)/(7*7)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
二、在VGGNet的卷积结构中,引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
三、训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
四、采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率
参考:
https://blog.csdn.net/abc_138/article/details/80568450
https://blog.csdn.net/qq_26591517/article/details/81071393
https://blog.csdn.net/dcrmg/article/details/79254654
https://blog.csdn.net/u014281392/article/details/75152809
VGG-Net的更多相关文章
- #Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
CNN的发展史 上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服.当时有流传的段 ...
- [caffe]深度学习之图像分类模型VGG解读
一.简单介绍 vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper.跟googlenet不同的是.vgg继承了lenet以及alexnet ...
- 第五弹:VGG
接下来讲一个目前经常被用到的模型,来自牛津大学的VGG,该网络目前还有很多改进版本,这里只讲一下最初的模型,分别从论文解析和模型理解两部分组成. 一.论文解析 一:摘要 -- 从Alex-net发展而 ...
- 【深度学习系列】用PaddlePaddle和Tensorflow实现经典CNN网络Vgg
上周我们讲了经典CNN网络AlexNet对图像分类的效果,2014年,在AlexNet出来的两年后,牛津大学提出了Vgg网络,并在ILSVRC 2014中的classification项目的比赛中取得 ...
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- VGG网路结构
VGG网络的基本结构 如图所示,从A到E网络的深度是逐渐增加的,在A中有11个权重层(8个卷积层,3个全连接层),在E中有19个权重层(16个卷积层,3个全连接层),卷积层的宽度是十分小的,开始时在第 ...
- 学习TensorFlow,调用预训练好的网络(Alex, VGG, ResNet etc)
视觉问题引入深度神经网络后,针对端对端的训练和预测网络,可以看是特征的表达和任务的决策问题(分类,回归等).当我们自己的训练数据量过小时,往往借助牛人已经预训练好的网络进行特征的提取,然后在后面加上自 ...
- 卷积神经网络之VGG
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比 ...
- VGG
2019-04-08 13:30:58 VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet.但是VGG模型在多个迁移学习任务中的表现要优于googLeNet.而且,从图像中提取 ...
- VGG网络结构
这个结构其实不难,但是它里面训练的一些东西我还没有搞清楚,打算把昨天写的代码传上来,方便日后来看,发现了一个很有意思的库叫TF-slim打算哪天看看有没有好用的东西 from datetime imp ...
随机推荐
- ng directive compile pre-link post-link
原文链接: http://www.jb51.net/article/58229.htm 1.ng在link之前编译所有的指令,然后link又分为 pre-link 与 post-link阶段compi ...
- scss转css的过程中 转化问题
如果 在转化过程中语法没有问题的话 测试一下是否是文件的bom头的问题
- ajax传递数组,后台更新
js: var rows = $("#stu_reg_table").datagrid("getSelections"); if(rows != "& ...
- python判断字符串是字母 数字 大小写
字符串.isalnum() 所有字符都是数字或者字母,为真返回 Ture,否则返回 False. 字符串.isalpha() 所有字符都是字母,为真返回 Ture,否则返回 False. 字符串.is ...
- codevs 1080 线段树练习(线段树)
题目: 题目描述 Description 一行N个方格,开始每个格子里都有一个整数.现在动态地提出一些问题和修改:提问的形式是求某一个特定的子区间[a,b]中所有元素的和:修改的规则是指定某一个格子x ...
- Linux运行时I/O设备的电源管理框架【转】
转自:https://www.cnblogs.com/coryxie/archive/2013/03/01/2951243.html 本文介绍Linux运行时I/O设备的电源管理框架.属于Linux内 ...
- HTTP协议04-返回状态码
状态码职责是在客户端向服务器端发送请求时候,描述返回的请求结果.借助状态码,用户可以知道服务器是否正常处理了请求,还是出错了. 状态码的类别 类别 原因短语 1XX Informational(信 ...
- vuex之 mapState, mapGetters, mapActions, mapMutations 的使用
一.介绍 vuex里面的四大金刚:State, Mutations,Actions,Getters (上次记得关于vuex笔记 http://www.cnblogs.com/adouwt/p/8283 ...
- ansible笔记(3):ansible模块的基本使用
ansible笔记():ansible模块的基本使用 在前文的基础上,我们已经知道,当我们使用ansible完成实际任务时,需要依靠ansible的各个模块,比如,我们想要去ping某主机,则需要使用 ...
- Linux命令之chmod、chown
一.chmod命令 chmod命令用于改变linux系统文件或目录的访问权限.用它控制文件或目录的访问权限.该命令有两种用法.一种是包含字母和操作符表达式的文字设定法:另一种是包含数字的数字设定法. ...