MySQL中间件之ProxySQL(11):链式规则( flagIN 和 flagOUT )
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html
1.理解链式规则
在mysql_query_rules表中,有两个特殊字段"flagIN"和"flagOUT",它们分别用来定义规则的入口和出口,从而实现链式规则(chains of rules)。
链式规则的实现方式如下:
- 当入口值flagIN设置为0时,表示开始进入链式规则。如未显式指定规则的flagIN值,则默认都为0。
- 当语句匹配完当前规则后,将记下当前规则的flagOUT值,如果flagOUT值非空(NOT NULL),则为该语句打上flagOUT标记。如果该规则的apply字段值不是1,则继续向下匹配。
- 如果语句的flagOUT标记和下一条规则的flagIN值不同,则跳过该规则,继续向下匹配。直到匹配到
flagOUT=flagIN的规则,则匹配该规则。该规则是链式规则中的另一条规则。 - 直到某规则的apply字段设置为1,或者已经匹配完所有规则,则最后一次被评估的规则将直接生效,不再继续向下匹配。
通过下面两张图,应该很容易理解链式规则的生效方式。
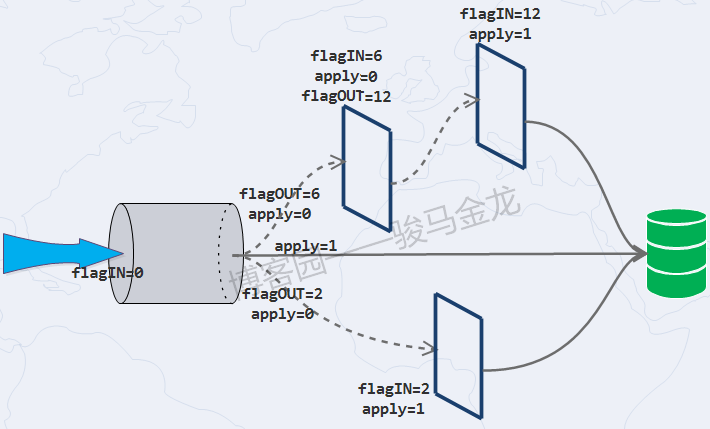
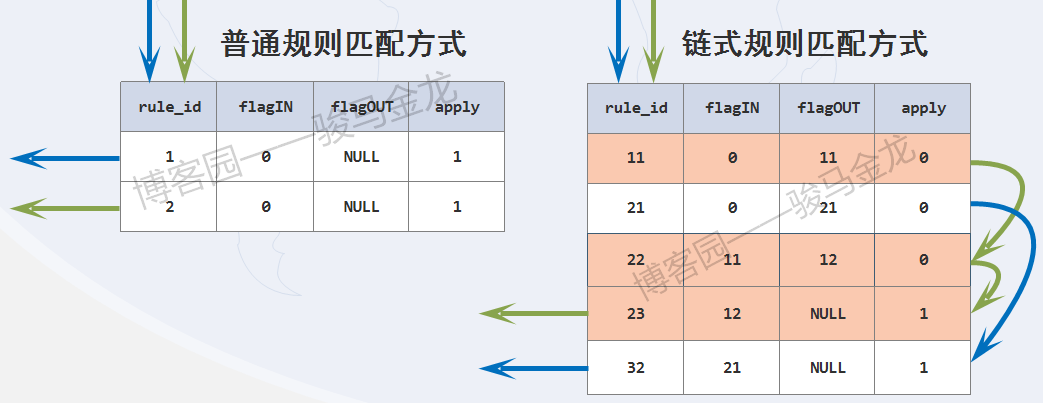
必须注意,规则是按照rule_id的大小顺序进行的。且并非只有apply=1时才会应用规则,当无规则可匹配,或者某规则的flagIN和flagOUT值相同,都会应用最后一次被评估的规则。
以下几个示例,可以解释生效规则:
# rule_id=3 生效+---------+-------+--------+---------+| rule_id | apply | flagIN | flagOUT |+---------+-------+--------+---------+| 1 | 0 | 0 | 23 || 2 | 0 | 23 | 23 || 3 | 0 | 23 | NULL |+---------+-------+--------+---------+# rule_id=2 生效+---------+-------+--------+---------+| rule_id | apply | flagIN | flagOUT |+---------+-------+--------+---------+| 1 | 0 | 0 | 23 || 2 | 0 | 23 | 23 || 3 | 0 | 24 | NULL |+---------+-------+--------+---------+# rule_id=2 生效,因为匹配完rule_id=2后,还打着flagOUT=23标记+---------+-------+--------+---------+| rule_id | apply | flagIN | flagOUT |+---------+-------+--------+---------+| 1 | 0 | 0 | 23 || 2 | 0 | 23 | NULL || 3 | 1 | 24 | NULL |+---------+-------+--------+---------+# rule_id=3 生效,因为匹配完rule_id=2后,还打着flagOUT=23标记+---------+-------+--------+---------+| rule_id | apply | flagIN | flagOUT |+---------+-------+--------+---------+| 1 | 0 | 0 | 23 || 2 | 0 | 23 | NULL || 3 | 1 | 23 | NULL |+---------+-------+--------+---------+
2.链式规则示例
有了普通规则匹配方式,为什么还要设计链式规则呢?虽然ProxySQL通过正则表达式实现了很灵活的规则匹配模式,但需求总是千变万化的,有时候仅通过一条正则匹配规则和替换规则很难实现比较复杂的要求,例如sharding时。
链式规则除了常用的多次替换,还可巧用于多次匹配。
本文简单演示一下链式规则,不具有实际意义,只为后面ProxySQL实现sharding的文章做基础知识铺垫。
2个测试库,共4张表test{1,2}.t{1,2}。
mysql> select * from test1.t1;+------------------+| name |+------------------+| test1_t1_malong1 || test1_t1_malong2 || test1_t1_malong3 |+------------------+mysql> select * from test1.t2;+------------------+| name |+------------------+| test1_t2_malong1 || test1_t2_malong2 || test1_t2_malong3 |+------------------+mysql> select * from test2.t1;+--------------------+| name |+--------------------+| test2_t1_xiaofang1 || test2_t1_xiaofang2 || test2_t1_xiaofang3 |+--------------------+mysql> select * from test2.t2;+--------------------+| name |+--------------------+| test2_t2_xiaofang1 || test2_t2_xiaofang2 || test2_t2_xiaofang3 |+--------------------+
现在借用链式规则,一步一步地将对test1.t1表的查询路由到test2.t2表的查询。再次声明,此处示例毫无实际意义,仅为演示链式规则的基本用法。
大致链式匹配的过程为:
test1.t1 --> test1.t2 --> test2.t1 --> test2.t2
以下是具体插入的规则:
delete from mysql_query_rules;select * from stats_mysql_query_digest_reset where 1=0;insert into mysql_query_rules(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values(1,1,0,0,23,"test1\.t1","test1.t2");insert into mysql_query_rules(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values(2,1,0,23,24,"test1\.t2","test2.t1");insert into mysql_query_rules(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern,destination_hostgroup) values(3,1,1,24,NULL,"test2\.t1","test2.t2",30);load mysql query rules to runtime;save mysql query rules to disk;admin> select rule_id,apply,flagIN,flagOUT,match_pattern,replace_pattern,destination_hostgroup DHfrom mysql_query_rules;+---------+-------+--------+---------+---------------+-----------------+------+| rule_id | apply | flagIN | flagOUT | match_pattern | replace_pattern | DH |+---------+-------+--------+---------+---------------+-----------------+------+| 1 | 0 | 0 | 23 | test1\.t1 | test1.t2 | NULL || 2 | 0 | 23 | 24 | test1\.t2 | test2.t1 | NULL || 3 | 1 | 24 | NULL | test2\.t1 | test2.t2 | 30 |+---------+-------+--------+---------+---------------+-----------------+------+
查询test1.t1表,测试结果。
[root@xuexi ~]# mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;"+--------------------+| name |+--------------------+| test2_t2_xiaofang1 | <-- 查询返回结果为test2.t2内容| test2_t2_xiaofang2 || test2_t2_xiaofang3 |+--------------------+admin> select * from stats_mysql_query_rules;+---------+------+| rule_id | hits |+---------+------+| 1 | 1 | <-- 3条规则全都命中| 2 | 1 || 3 | 1 |+---------+------+admin> select hostgroup,digest_text from stats_mysql_query_digest;+-----------+----------------------------------+| hostgroup | digest_text |+-----------+----------------------------------+| 30 | select * from test2.t2 | <-- 路由目标hg=30+-----------+----------------------------------+
显然,已经按照预想中的方式进行匹配、替换、路由。
一个问题:如果查询的是test1.t2表或test2.t1表,会进行链式匹配吗?
答案是不会,因为rule_id=2和rule_id=3这两个规则的flagIN都是非0值,而每个SQL语句初始时只进入flagIN=0的规则。
此外还需注意,当某语句未按照我们的期望途经所有的链式规则,则可能会根据destination_hostgroup字段的值直接路由出去,即使没有指定该字段值,还有用户的默认路由目标组,或者基于端口的路由目标。所以,在写链式规则时,应当尽可能地针对某一类型的语句进行完完整整的定制,保证这类语句能途经我们所期望的所有规则。
MySQL中间件之ProxySQL(11):链式规则( flagIN 和 flagOUT )的更多相关文章
- ProxySQL(11):链式规则( flagIN 和 flagOUT )
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9350631.html 理解链式规则 在mysql_query_rules表中,有两个特殊字段"fl ...
- MySQL中间件之ProxySQL(7):详述ProxySQL的路由规则
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.关于ProxySQL路由的简述 当ProxySQL收到前端app发 ...
- MySQL中间件之ProxySQL(9):ProxySQL的查询缓存功能
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html ProxySQL支持查询缓存的功能,可以将后端返回的结果集缓存在自己的 ...
- MySQL中间件之ProxySQL(1):简介和安装
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.ProxySQL简介 之前的文章里,介绍了一个MySQL的中间件: ...
- MySQL中间件之ProxySQL(10):读写分离方法论
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.不同类型的读写分离 数据库中间件最基本的功能就是实现读写分离,Pr ...
- MySQL中间件之ProxySQL(6):管理后端节点
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.配置后端节点前的说明 为了让ProxySQL能够找到后端的MySQ ...
- MySQL中间件之ProxySQL(8):SQL语句的重写规则
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.为什么要重写SQL语句 ProxySQL在收到前端发送来的SQL语 ...
- MySQL中间件之ProxySQL(14):ProxySQL+PXC
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.ProxySQL+PXC 本文演示ProxySQL代理PXC(Pe ...
- MySQL中间件之ProxySQL(5):线程、线程池、连接池
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.ProxySQL的线程 ProxySQL由多个模块组成,是一个多线 ...
随机推荐
- eclipse 无法记住svn密码
每次要求输入密码,很恼人.经过一番折腾,在stackoverflow上找到了解决方案,上面大神果然多 简单的说,就是通过查看工作空间的日志文件,发现报了个java异常,缺少一个class文件(org. ...
- jwt vs session 以rails 为例 (翻译部分)
原文地址:https://pragmaticstudio.com/tutorials/rails-session-cookies-for-api-authentication 普通方式: 令牌为基础的 ...
- .Net Trace->Listeners->Remove
今天在调试一个别人写的ASP.NET老程序,log文件怎么都写不了.web.config里的trace->listeners里有这么一行: <remove type="Syste ...
- 【Android开源库】 PagerSlidingTabStrip从头到脚
简介 PagerSlidingTabStrip,是我个人经常使用到的一个和ViewPager配合的页面指示器,可以满足开发过程中常用的需求,如类似于今日头条的首页新闻内容导航栏等等,之前自己开发的Ju ...
- CSS中清除浮动的作用以及如何清除浮动
1.什么是浮动,浮动的作用 “浮动”从字面上来理解就是“悬浮移动.非固定”的意思.块级元素(div.table.span…)是以垂直方向排列,而在前端界面中往往要使用水平布局块级元素使界面更美观.这就 ...
- UnityTips:使用反射调用内部方法拓展编辑器
大家都知道Unity是一个C/C++的游戏引擎,C#只是Unity提供的脚本层.因此大部分功能都是通过C#来调用底层的C++代码的.而一些朋友可能不知道的是,其实Unity的C#代码中也有很多方法是我 ...
- 【洛谷4172】 [WC2006]水管局长(LCT)
传送门 洛谷 BZOJ Solution 如果不需要动态的话,那就是一个裸的最小生成树上的最大边权对吧. 现在动态了的话,把这个过程反着来,就是加边对吧. 现在问题变成了怎么动态维护加边的最小生成树, ...
- 聊一聊Java如何接入招行一网通支付功能
1.前提条件 相比较于支付宝和微信的支付功能接入这一块,银行相对来说更加严格,比如说支付宝,在你签约之前可以进行一些测试.但是银行来说就不是这样了,如果您现在要进行招行的支付功能开发的话,请务必先让相 ...
- SPA架构的优点和缺点以及一些思考
SPA是什么? 全称是单页面应用. 一个SPA就是一个WEB应用,它所需的资源(HTML CSS JS等),在一次请求中就加载完成,也就是不需刷新地动态加载. 用术语“单页”就是因为页面在初始化加载后 ...
- Linux的 文件 和 目录 管理
包括了文件和目录的创建.删除.修改,权限.压缩.搜索.分区.挂载 简单的一些命令: [ pwd ]查看当前所在目录 [ cd .. ]上级目录 [ cd ~ ]当前用户的家目录 [cd -]上次打开目 ...