Python爬虫之多线程下载豆瓣Top250电影图片
爬虫项目介绍
本次爬虫项目将爬取豆瓣Top250电影的图片,其网址为:https://movie.douban.com/top250, 具体页面如下图所示:

本次爬虫项目将分别不使用多线程和使用多线程来完成,通过两者的对比,显示出多线程在爬虫项目中的巨大优势。本文所使用的多线程用到了concurrent.futures模块,该模块是Python中最广为使用的并发库,它可以非常方便地将任务并行化。在concurrent.futures模块中,共有两种并发模块,分别如下:
- 多线程模式:ThreadPoolExecutor,适合 IO密集型任务;
- 多进程模式:ProcessPoolExecutor,适合计算密集型任务。
具体的关于该模块的介绍可以参考其官方网址:https://docs.python.org/3/library/concurrent.futures.html 。
本次爬虫项目将会用到concurrent.futures模块中的ThreadPoolExecutor类,多线程下载豆瓣Top250电影图片。下面将会给出本次爬虫项目分别不使用多线程和使用多线程的对比,以此来展示多线程在爬虫中的巨大优势。
不使用多线程
首先,我们不使用多线程来下载豆瓣Top250电影图片,其完整的Python代码如下:
import time
import requests
import urllib.request
from bs4 import BeautifulSoup
# 该函数用于下载图片
# 传入函数: 网页的网址url
def download_picture(url):
# 获取网页的源代码
r = requests.get(url)
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(r.text, "lxml")
# 获取网页中的电影图片
content = soup.find('div', class_='article')
images = content.find_all('img')
# 获取电影图片的名称和下载地址
picture_name_list = [image['alt'] for image in images]
picture_link_list = [image['src'] for image in images]
# 利用urllib.request..urlretrieve正式下载图片
for picture_name, picture_link in zip(picture_name_list, picture_link_list):
urllib.request.urlretrieve(picture_link, 'E://douban/%s.jpg' % picture_name)
def main():
# 全部10个网页
start_urls = ["https://movie.douban.com/top250"]
for i in range(1, 10):
start_urls.append("https://movie.douban.com/top250?start=%d&filter=" % (25 * i))
# 统计该爬虫的消耗时间
t1 = time.time()
print('*' * 50)
for url in start_urls:
download_picture(url)
t2 = time.time()
print('不使用多线程,总共耗时:%s'%(t2-t1))
print('*' * 50)
main()
其输出结果如下:
**************************************************
不使用多线程,总共耗时:79.93260931968689
**************************************************
去E盘中的douban文件夹查看,如下图:
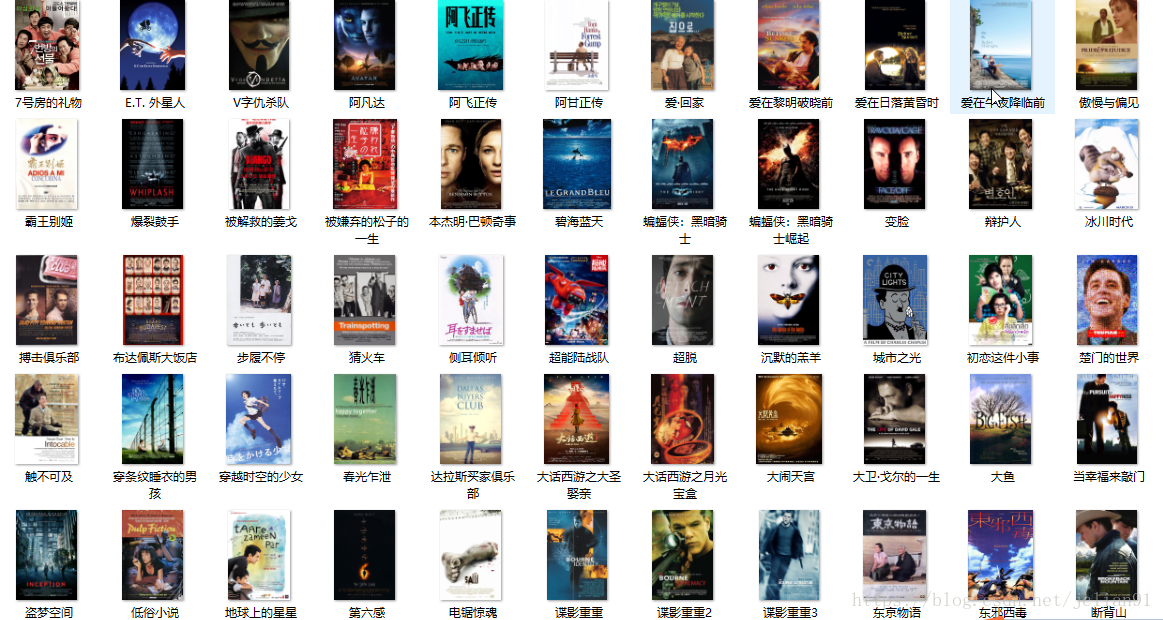
我们可以看到,在不使用多线程的情况下,这个爬虫总共耗时约80s,完成了豆瓣Top250电影图片的下载。
使用多线程
接下来,我们使用多线程来下载豆瓣Top250电影图片,其完整的Python代码如下:
import time
import requests
import urllib.request
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 该函数用于下载图片
# 传入函数: 网页的网址url
def download_picture(url):
# 获取网页的源代码
r = requests.get(url)
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(r.text, "lxml")
# 获取网页中的电影图片
content = soup.find('div', class_='article')
images = content.find_all('img')
# 获取电影图片的名称和下载地址
picture_name_list = [image['alt'] for image in images]
picture_link_list = [image['src'] for image in images]
# 利用urllib.request..urlretrieve正式下载图片
for picture_name, picture_link in zip(picture_name_list, picture_link_list):
urllib.request.urlretrieve(picture_link, 'E://douban/%s.jpg' % picture_name)
def main():
# 全部10个网页
start_urls = ["https://movie.douban.com/top250"]
for i in range(1, 10):
start_urls.append("https://movie.douban.com/top250?start=%d&filter=" % (25 * i))
# 统计该爬虫的消耗时间
print('*' * 50)
t3 = time.time()
# 利用并发下载电影图片
executor = ThreadPoolExecutor(max_workers=10) # 可以自己调整max_workers,即线程的个数
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(download_picture, url) for url in start_urls]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
t4 = time.time()
print('使用多线程,总共耗时:%s' % (t4 - t3))
print('*' * 50)
main()
其输出结果如下:
**************************************************
使用多线程,总共耗时:9.361606121063232
**************************************************
再去E盘中的douban文件夹查看,发现同样也下载了250张电影图片。
总结
通过上述两个爬虫程序的对比,我们不难发现,同样是下载豆瓣Top250电影,10个网页中的图片,在没有使用多线程的情况下,总共耗时约80s,而在使用多线程(10个线程)的情况下,总共耗时约9.5秒,效率整整提高了约8倍。这样的效率提升在爬虫中无疑是令人兴奋的。
希望读者在看了本篇博客后,也能尝试着在自己的爬虫中使用多线程,说不定会有意外的惊喜哦~~因为,大名鼎鼎的Python爬虫框架Scrapy,也是使用多线程来提升爬虫速度的哦!
注意:本人现已开通两个微信公众号: 因为Python(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~
Python爬虫之多线程下载豆瓣Top250电影图片的更多相关文章
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- Python爬虫之多线程下载程序类电子书
近段时间,笔者发现一个神奇的网站:http://www.allitebooks.com/ ,该网站提供了大量免费的编程方面的电子书,是技术爱好者们的福音.其页面如下: 那么我们是否可以通过Py ...
- 爬虫之爬取豆瓣top250电影排行榜及爬取斗图啦表情包解读及爬虫知识点补充
今日内容概要 如何将爬取的数据直接导入Excel表格 #如何通过Python代码操作Excel表格 #前戏 import requests import time from openpyxl impo ...
- Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法: ...
- python爬虫知识点三--解析豆瓣top250数据
一.利用cookie访问import requests headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKi ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- python爬虫之多线程、多进程+代码示例
python爬虫之多线程.多进程 使用多进程.多线程编写爬虫的代码能有效的提高爬虫爬取目标网站的效率. 一.什么是进程和线程 引用廖雪峰的官方网站关于进程和线程的讲解: 进程:对于操作系统来说,一个任 ...
- 爬取豆瓣TOP250电影
自己跟着视频学习的第一个爬虫小程序,里面有许多不太清楚的地方,不如怎么找到具体的电影名字的,那么多级关系,怎么以下就找到的是那个div呢? 诸如此类的,有许多,不过先做起来再说吧,后续再取去弄懂. i ...
- Python之FTP多线程下载文件之分块多线程文件合并
Python之FTP多线程下载文件之分块多线程文件合并 欢迎大家阅读Python之FTP多线程下载系列之二:Python之FTP多线程下载文件之分块多线程文件合并,本系列的第一篇:Python之FTP ...
随机推荐
- Strusts2
Strusts2的原理很简单,首先,地址栏输入http://xxxx/xxxx/webapp/xx.action首先,请求会通过httpservlet发送给tomcat容器,tomcat发现这个请求是 ...
- SSM_CRUD新手练习(10)返回分页的JSON数据
我们完成了员工的分页查询,但是现在这种做法只能适应浏览器和服务器的交互模式,但在移动互联网时代,客户端不仅仅只有浏览器,还有安卓和IOS客户端.我们的解决方式是AJAX+JSON方式来实现平台无关性. ...
- Spring Boot中Web应用的统一异常处理 转载来自翟永超
我们在做Web应用的时候,请求处理过程中发生错误是非常常见的情况.Spring Boot提供了一个默认的映射:/error,当处理中抛出异常之后,会转到该请求中处理,并且该请求有一个全局的错误页面用来 ...
- 基于MFC的socket编程
网络编程 1.windows 套接字编程(开放的网络编程接口)添加头文件#include<windows.h> 2.套接字及其分类 socket分为两种:(1)数据报socket:无连接套 ...
- 项目设计day1
项目内容:一个实时监控斗鱼TV某个主播弹幕的设计 通过python爬虫获取当前弹幕,通过flume采集数据,接下来数据分为线上和线下两种方案: 线上:实时分析,分为两种方案:(1) flume+kaf ...
- 1-C++的并发世界
1.1 何谓并发 并发的两种方式 多核机器上的真正并行 单核机器的任务切换 并发的两种途径 多进程并发 1.1 多进程并发需要通过操作系统进行进程间通信 多线程并发 2.1 多线程并发需要共享内存 1 ...
- why microsoft named their cloud service Azure?
best guess I can personally make is that because Azure literally means “bright blue color of the clo ...
- 我所理解的HTTP协议
前言 对于HTTP协议,想必大家都不陌生,在工作中经常用到,特别是针对移动端和前端开发人员来说,要获取服务端数据,基本走的网络请求都是基于HTTP协议,特别是RESTFUL + JSON 这种搭配特别 ...
- 使用《JAVA面向对象编程》总结
抽象和封装 现实世界是“面向对象”的,面向对象就是采用“现实模拟” 的方法设计和开发程序. 面向对象设计是目前计算软件开发中最流行的技术.面向对象设计的过程就是抽象的过程. 类是对某一类事物的描述,是 ...
- 几种归一化方法的概念及python实现
一 (0,1)标准化: 这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据 ...