scrapy关键字爬取百度图库(一)
刚入门学习python的菜鸟,如有错误,还望指教 爬取百度图库需要知道百度图库的加载方式是通过下拉加载的,所以我们需要分析Ajax请求来爬取每一页的数据信息
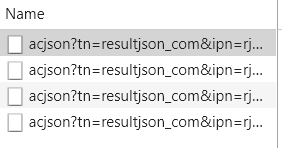
表述不清直接上图片
图片一是刷新页面后加载的四条json格式的数据,随便点开一条,可以看到它的Requset URL,每一个json数据中包含了30张图片。
所根据观察发现,每一条URL变化的地方在queryword=(关键字)和pn=(从零开始,以30为步长),所以根据此我们可以通过改变请求的URL来加载下一个json数据,这样就可以实现下拉功能。
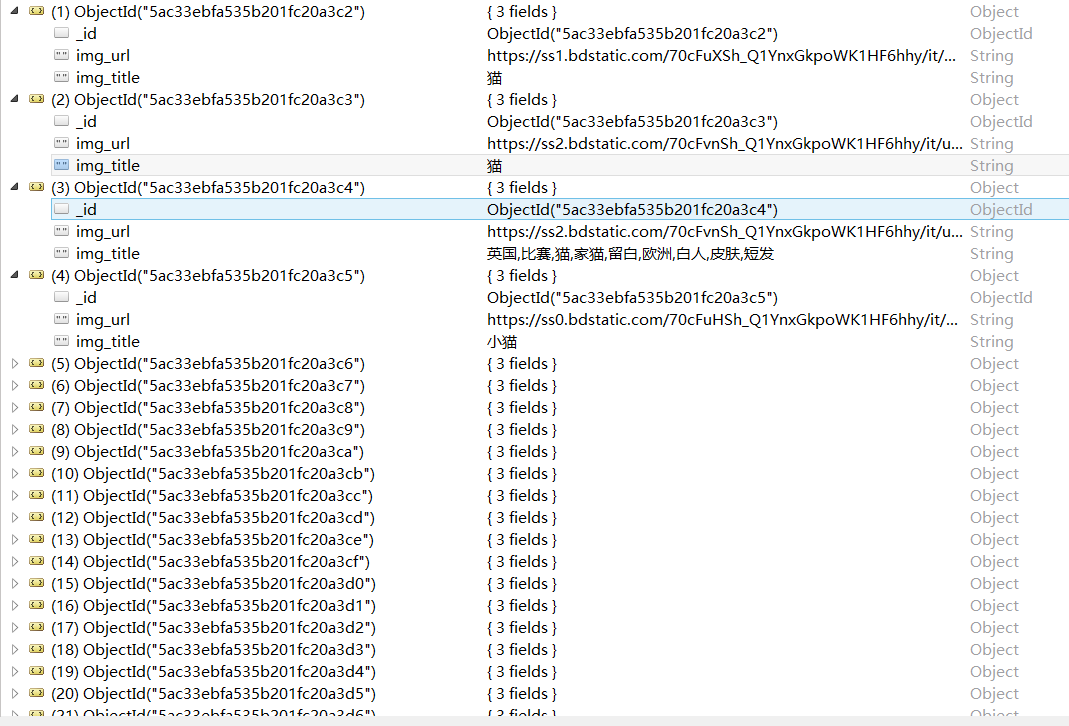
点开data中的一项我们可以看到想要的信息都在里面,我们选取它的名称和图片地址来存储
代码实现:
scrapy框架好的地方在于它已经把每一个过程分块化,我们只需要关注每一块要实现的功能,而不用关心块与块如何连接的问题
settings.py


MONGO_URI='localhost'
MONGO_DB='picture' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Pic_search (+http://www.yourdomain.com)' # Obey robots.txt rules
#协议文件
ROBOTSTXT_OBEY = False
要把信息存入MongoDB中
items.py
import scrapy
class PicSearchItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_title = scrapy.Field()
img_url = scrapy.Field()
Item 对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like) 的API以及用于声明可用字段的简单语法。
spiders.py
# -*- coding: utf-8 -*-
#初始化spider:scrapy genspider spider image.baidu.com
#运行spider:scrapy crawl spider
from scrapy import Spider,Request
import json
from Pic_search.items import PicSearchItem
import itertools
import urllib
import time u_word = input("请输入你要下载的图片关键词:\n")
word = urllib.parse.quote(u_word)
pn = 0
urls = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word={word}&face=0&istype=2&nc=1&pn={pn}&rn=30" class SpiderSpider(Spider):
name = 'spider'
allowed_domains = ['image.baidu.com']
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
} def start_requests(self):
#print(word)
url = urls.format(word=word,pn=0)
yield Request(url, headers=self.headers) def parse(self, response):
hjsons = json.loads(response.body)
img_datas = hjsons['data']
if hjsons:
for data in img_datas:
try:
item = PicSearchItem()
print(data['fromPageTitleEnc'])
print(data['thumbURL'])
item['img_url'] = data['thumbURL']
item['img_title'] = data['fromPageTitleEnc']
yield item
except:
pass for x in itertools.count(start=30, step=30):
next_url = urls.format(word=word,pn=x) #生成下一页地址
yield Request(url=next_url, callback=self.parse) #回调
time.sleep(1)

pipelines.py
import pymongo
from scrapy.exceptions import DropItem class MongoPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
) def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def process_item(self,item,spider):
name = item.__class__.__name__
#两条下划线
self.db[name].insert(dict(item))
return item def close_spider(self,spider):
self.client.close()
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理
以下是item pipeline的一些典型应用:
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
结果图片:
但是代码还是存在问题和不足,还有需要很多提升
1.解决无限循环,解决异常问题
2.采用分布式爬取
3.爬取多个网站图片
所以未完,待续。。。。。。。
scrapy关键字爬取百度图库(一)的更多相关文章
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 十三 web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息, ...
- 基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子 站点分析 首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎 点进看到有四种搜索方式,分别试一次,观察url变化 我们得知: 搜 ...
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- WebCollector爬取百度搜索引擎样例
使用WebCollector来爬取百度搜索引擎依照关键字搜索的结果页面,解析规则可能会随百度搜索的改版而失效. 代码例如以下: package com.wjd.baidukey.crawler; im ...
- python 爬取百度url
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-29 18:38:23 # @Author : EnderZhou (z ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
随机推荐
- Lodop输出页面input文本框的最新值
默认使用Lodop打印页面上的文本框等,会发现虽然页面上文本框输入了值,打印预览却是空的,这是由于没有把最新的值传入Lodop. 如图,演示的是Lodop如何输出文本框内的新值,这里整个页面只有inp ...
- 常用css样式处理
1:如何设置html的input框的高度和宽度! 用style来设置,<input style="width:111px;height:111px">
- codeforces285C
Building Permutation CodeForces - 285C Permutation p is an ordered set of integers p1, p2, ..., p ...
- JQ用法
jQuery简称jq,是一款同prototype一样优秀js开发库类,特别是对css和XPath的支持,使我们写js变得更加方便!如果你不是个js高手又想写出优 秀的js效果,jq可以帮你达到目的!下 ...
- Vue 计算
目标:字段c=字段a+字段b 方法1 直接使用Mustache(胡子表达式) <body> <div id="example" > <input v- ...
- 【XSY1515】【GDKOI2016】小学生数学题 组合数学
题目描述 给你\(n,k,p\)(\(p\)为质数),求 \[ \sum_{i=1}^n\frac{1}{i}\mod p^k \] 保证有解. \(p\leq {10}^5,np^k\leq {10 ...
- mysql中存储字段类型的查询效率
检索性能从快到慢的是(此处是听人说的): 第一:tinyint,smallint,mediumint,int,bigint第二:char,varchar第三:NULL 解释(转载): 整数类型1.TI ...
- day5 range 用法示例
函数语法 range(start, stop[, step]) 参数说明: start: 计数从 start 开始.默认是从 0 开始.例如range(5)等价于range(0, 5); stop: ...
- synchronized 关键字解析
synchronized 关键字解析 同步锁依赖于对象,每个对象都有一个同步锁. 现有一成员变量 Test,当线程 A 调用 Test 的 synchronized 方法,线程 A 获得 Test 的 ...
- WC2019 划水记
写在前面: 本篇是擅长咕咕咕的\(\text{BLUESKY007}\)同学难得不咕写的游记,将会记录\(WC2019(2019.1.24(Day\ 0)\sim2019.1.30(Day\ 6))\ ...