python气象分析
数据分析实例 -- 气象数据
一、实验介绍
本实验将对意大利北部沿海地区的气象数据进行分析与可视化。我们在实验过程中先会运用 Python 中matplotlib库的对数据进行图表化处理,然后调用 scikit-learn 库当中的的 SVM 库对数据进行回归分析,最终在图表分析的支持下得出我们的结论。
1.1 课程来源
本课程基于 图灵教育 的 《Python数据分析实战》 第2章制作,感谢 图灵教育 授权实验楼发布。如需系统的学习本书,请购买《Python数据分析实战》。
为了保证可以在实验楼环境中完成本次实验,我们在原书内容基础上补充了一系列的实验指导,比如实验截图,代码注释,帮助您更好得实战。
如果您对于实验有疑惑或者建议可以随时在讨论区中提问,与同学们一起探讨。
1.2 实验知识点
- matplotlib 库画出图像
- scikit-learn 库对数据进行回归分析
- numpy 库对数据进行切片
1.3 实验环境
- python2.7
- spyder
- Xfce终端
1.4 适合人群
本课程难度为中等,适合具有Python基础的用户,如果对 matplotlib 模块有了解会更快的上手。
1.5 代码获取
你可以通过下面命令将代码下载到实验楼环境中,作为参照对比进行学习。
$ wget http://labfile.oss.aliyuncs.com/courses/780/SourceCode.zip
$ wget http://labfile.oss.aliyuncs.com/courses/780/WeatherData.zip
本实验在交互式的环境当中完成,代码不能直接在命令行中运行(因为要画图)。如果想要看效果的同学可以把 SourceCode.zip 和 WeatherData.zip解压,然后打开桌面上的 spyder, 在Ipython console的交互式环境中进入WeatherData所在路径,然后把代码黏贴到 console 当中去。具体方式请看如下的 gif 图。
在这里还是要呼吁大家不要简单的复制粘贴代码,还是要依照本实验的教程自己一步步得实现。
二、实验原理
气象数据是在网上很容易找到的一类数据。很多网站都提供以往的气压、气温、湿度和降雨量等气象数据。只需指定位置和日期,就能获取一个气象数据文件。这些测量数据是由气象站收集的。气象数据这类数据源涵盖的信息范围较广。数据分析的目的是把原始数据转化为信息,再把信息转化为知识,因此拿气象数据作为数据分析的对象来讲解数据分析全过程再合适不过。
2.1 待检验的假设:靠海对气候的影响
写作本章时,虽正值夏初,却已酷热难耐,住在大城市的人感受更为强烈。于是周末很多人到山村或海滨城市去游玩,放松一下身心,远离内陆城市的闷热天气。我常常想,靠海对气候有什么影响?这个问题可以作为数据分析的一个不错的出发点。我不想把本章写成科学类读物,只是想借助这样一种方式,让数据分析爱好者能够把所学用于实践,解决“海洋对一个地区的气候有何影响”这个问题。
研究系统:亚得里亚海和波河流域
既然已定义好问题,就需要寻找适合研究数据的系统,提供适合回答这个问题的环境。首先,需要找到一片海域供你研究。我住在意大利,可选择的海有很多,因为意大利是一个被海洋包围的半岛国家。为什么要把自己的选择局限在意大利呢?因为我们所研究的问题刚好和意大利人的一种典行为相关,也就是夏天我们喜欢躲在海边,以躲避内陆的酷热。我不知道在其他国家这种行为是否也很普遍,因此我只把自己熟悉的意大利作为一个系统进行研究。但是你可能会考虑研究意大利的哪个地区呢?上面说过,意大利是半岛国家,找到可研究的海域不是问题,但是如何衡量海洋对其远近不同的地方的影响?这就引出了一个大问题。意大利其实多山地,离海差不多远,可以彼此作为参照的内陆区域较少。为了衡量海洋对气候的影响,我排除了山地,因为山地也许会引入其他很多因素,比如海拔。
意大利波河流域这块区域就很适合研究海洋对气候的影响。这一片平原东起亚得里亚海,向内陆延伸数百公里(见图9-1)。它周边虽不乏群山环绕,但由于它很宽广,削弱了群山的影响。此外,该区域城镇密集,也便于选取一组离海远近不同的城市。我们所选的几个城市,两个城市间的最大距离约为400公里。

第一步,选10个城市作为参照组。选择城市时,注意它们要能代表整个平原地区(见图9-2)。

如图9-2所示,我们选取了10个城市。随后将分析它们的天气数据,其中5个城市在距海100公里范围内,其余5个距海100~400公里。
选作样本的城市列表如下:
- Ferrara(费拉拉)
- Torino(都灵)
- Mantova(曼托瓦)
- Milano(米兰)
- Ravenna(拉文纳)
- Asti(阿斯蒂)
- Bologna(博洛尼亚)
- Piacenza(皮亚琴察)
- Cesena(切塞纳)
- Faenza(法恩莎)
现在,我们需要弄清楚这些城市离海有多远。方法有多种。这里使用TheTimeNow网站提供的服务,它支持多种语言(见图9-3)。

有了计算两城市间距离这样的服务,我们就可以计算每个城市与海之间的距离。你可以选择 海滨城市Comacchio作为基点,计算其他城市与它之间的距离(见图9-2)。使用上述服务计算完 所有距离后,得到的结果如表9-1所示。


三、开发准备
定义好要研究的系统之后,我们就需要创建数据源,以获取研究所需的数据。上网浏览一番,你就会发现很多网站都提供世界各地的气象数据,其中就有Open Weather Map,它的网址是 http://openweathermap.org/ (见图9-4)。


该网站提供以下功能:在请求的URL中指定城市,即可获取该城市的气象数据。我们已经准备好了数据,不需要大家再去调用该网站的 API。
启动桌面上的spyder。如果您发现您桌面上没有spyder,请在该实验中重新开一个实验环境(实验楼为不同的实验创建不同的实验环境):


我们首先来获取我们的数据文件。打开 Xfce 终端
$ cd Code
$ mkdir WeatherAnalysis
$ cd WeatherAnalysis
$ wget http://labfile.oss.aliyuncs.com/courses/780/WeatherData.zip
$ unzip WeatherData.zip
这时候应该能够再 WeatherData 中间看到 10 个城市的天气数据文件(以 .csv 结尾)
双击打开 spyder ,在 Ipython Console 中进入我们的目标目录
cd Code
cd WeatherAnalysis
cd WeatherData
我们在实验里只需要用到 Ipython Console 所以别的不相关的窗口可以关闭。

import numpy as np
import pandas as pd
import datetime
如果你想用本章的数据,需要加载写作本章时保存的10个CSV文件。
df_ferrara = pd.read_csv('ferrara_270615.csv')
df_milano = pd.read_csv('milano_270615.csv')
df_mantova = pd.read_csv('mantova_270615.csv')
df_ravenna = pd.read_csv('ravenna_270615.csv')
df_torino = pd.read_csv('torino_270615.csv')
df_asti = pd.read_csv('asti_270615.csv')
df_bologna = pd.read_csv('bologna_270615.csv')
df_piacenza = pd.read_csv('piacenza_270615.csv')
df_cesena = pd.read_csv('cesena_270615.csv')
df_faenza = pd.read_csv('faenza_270615.csv')
我们把这些数据读入内存,完成了实验准备的部分。
四、项目文件结构

Pic9-* 代表的是每一张分析图所使用的代码。
WeatherData 是我们的数据。
五、实验步骤
从数据可视化入手分析收集到的数据是常见的做法。前面讲过,matplotlib库提供一系列图表生成工具,能够以可视化形式表示数据。数据可视化在数据分析阶段非常有助于发现研究系统的一些特点。
导入以下必要的库:
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from dateutil import parser
5.1 温度数据分析
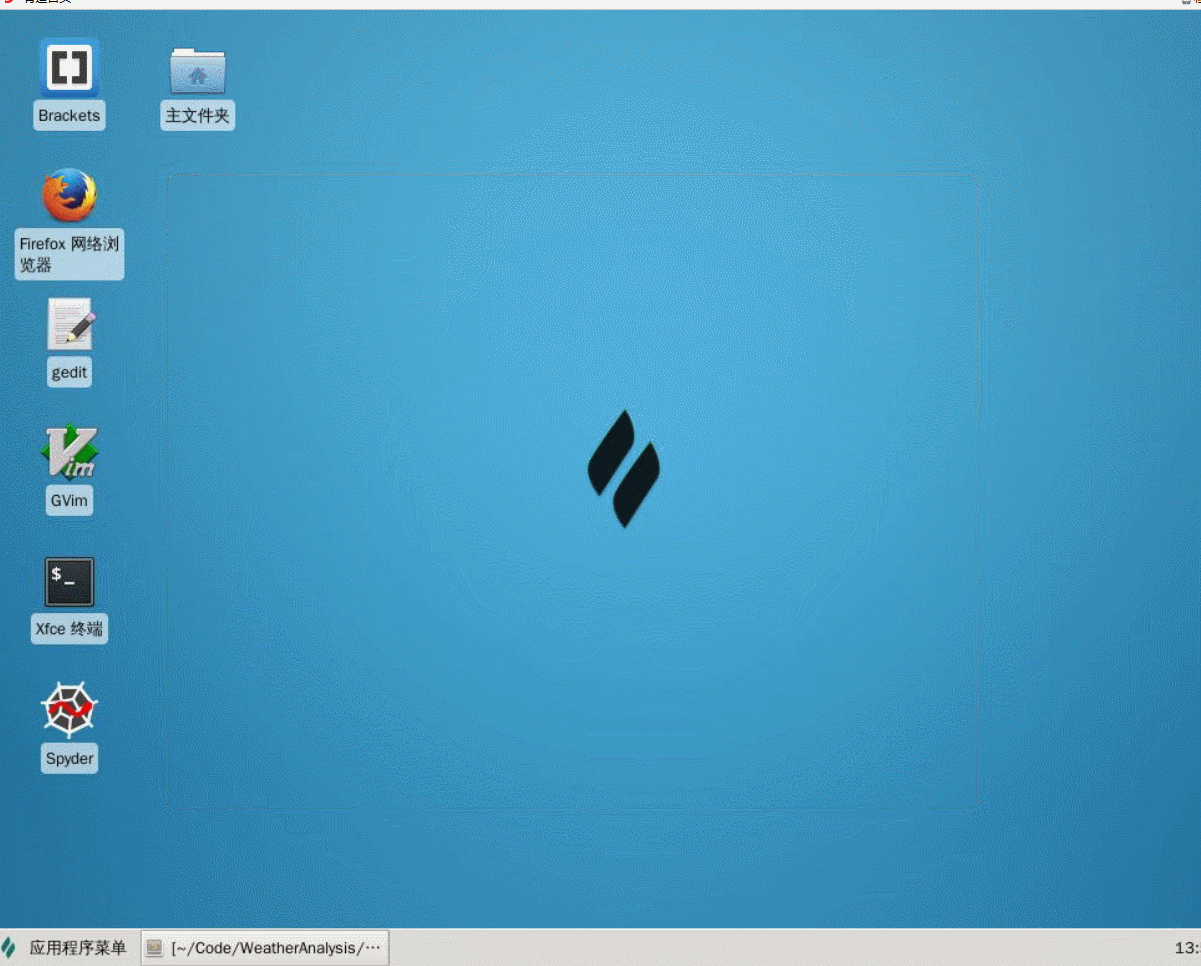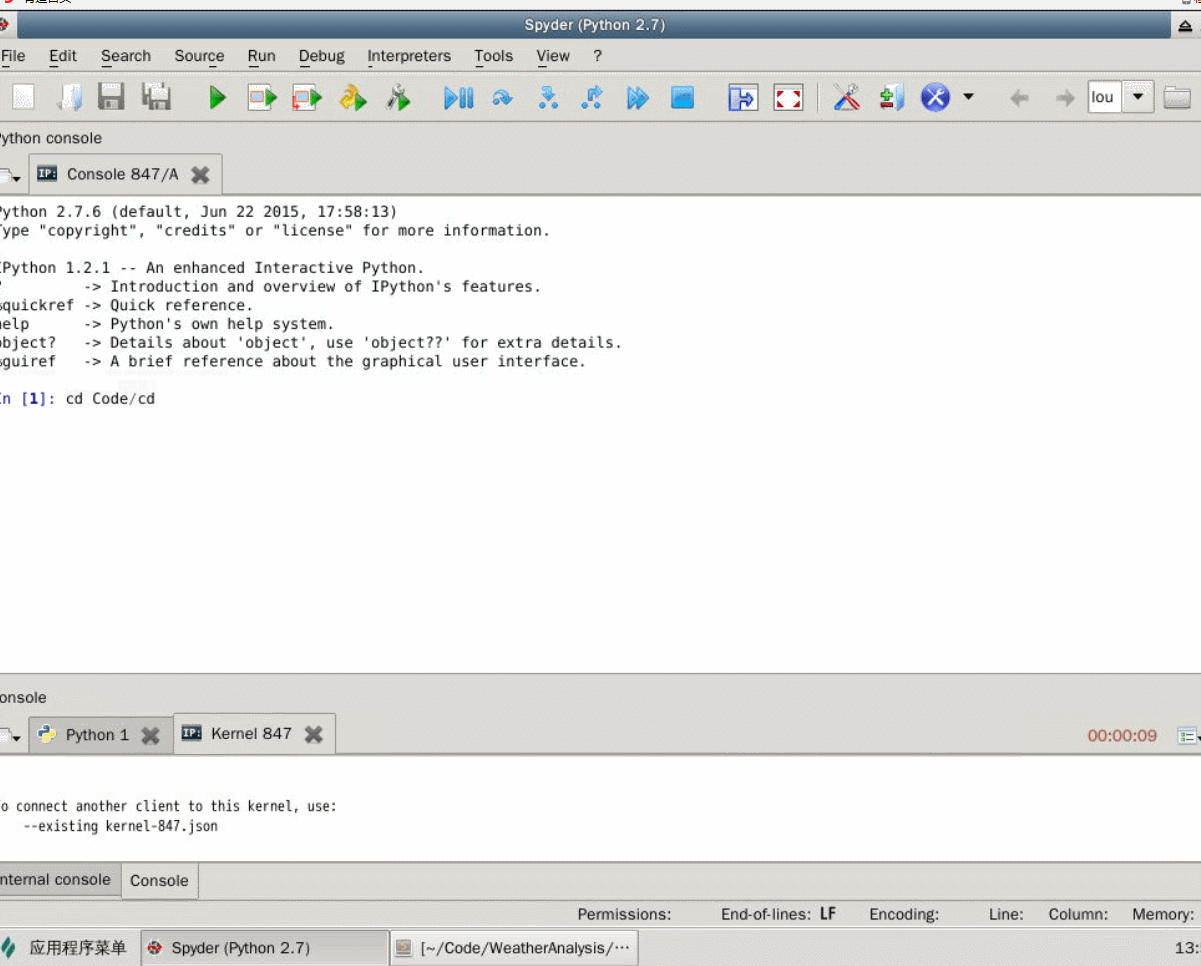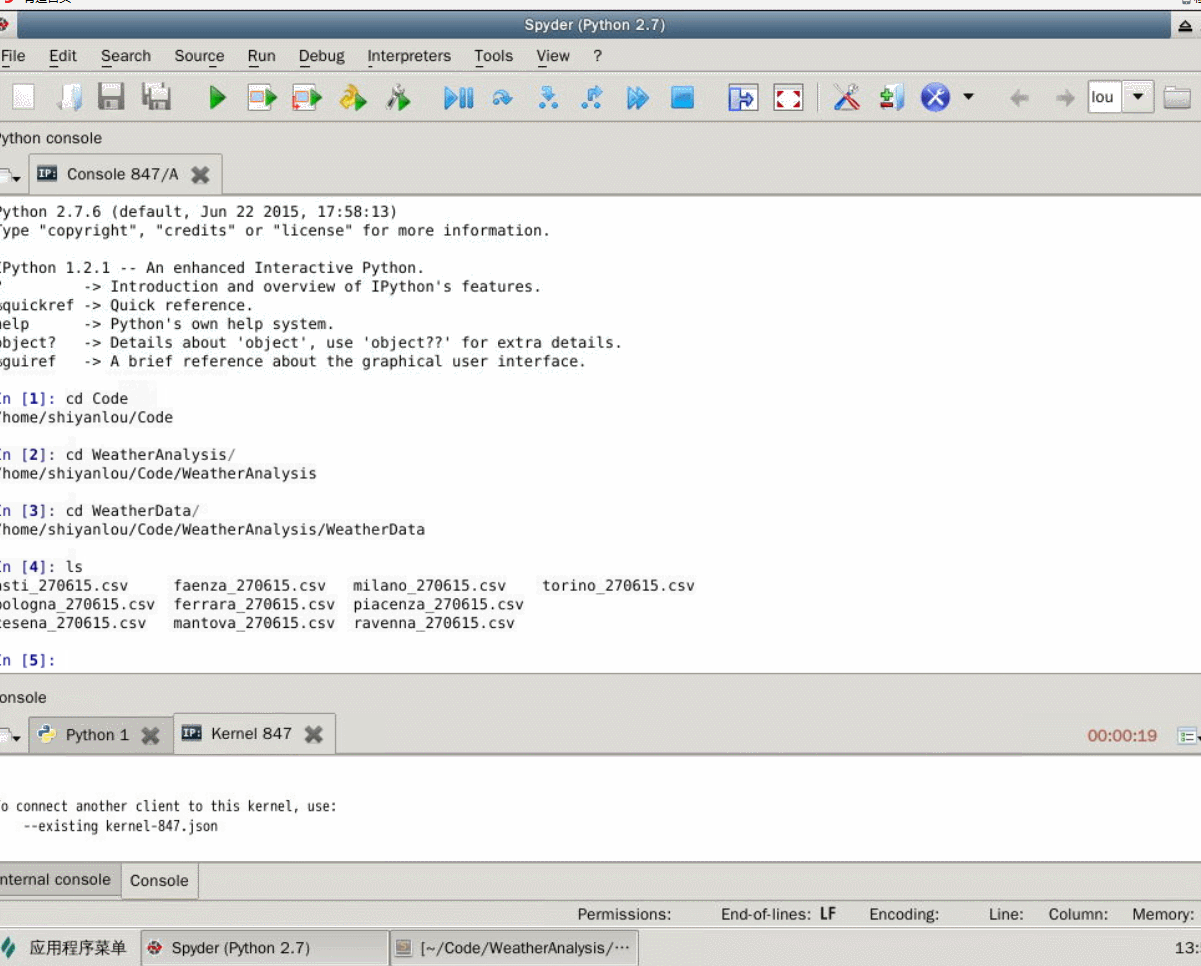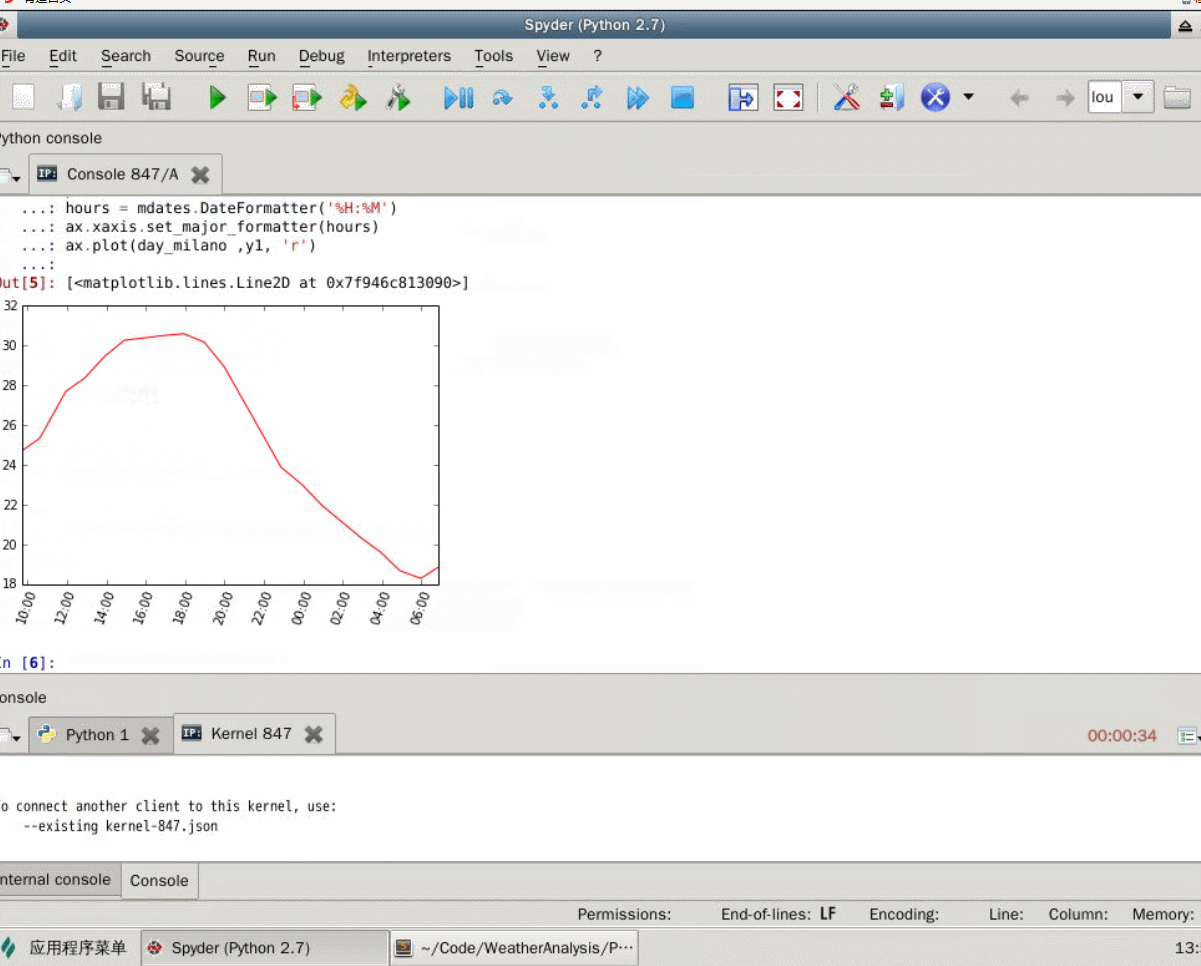
举例来说,非常简单的分析方法是先分析一天中气温的变化趋势。我们以城市米兰为例。
# 读取米兰的城市气象数据
df_milano = pd.read_csv('milano_270615.csv')
# 取出我们要分析的温度和日期数据
y1 = df_milano['temp']
x1 = df_milano['day']
# 把日期数据转换成 datetime 的格式
day_milano = [parser.parse(x) for x in x1]
# 调用 subplot 函数, fig 是图像对象,ax 是坐标轴对象
fig, ax = plt.subplots()
# 调整x轴坐标刻度,使其旋转70度,方便查看
plt.xticks(rotation=70)
# 设定时间的格式
hours = mdates.DateFormatter('%H:%M')
# 设定X轴显示的格式
ax.xaxis.set_major_formatter(hours)
# 画出图像,day_milano是X轴数据,y1是Y轴数据,‘r’代表的是'red' 红色
ax.plot(day_milano ,y1, 'r')
# 显示图像
fig
执行上述代码,将得到如图9-8所示的图像。由图可见,气温走势接近正弦曲线,从早上开始气温逐渐升高,最高温出现在下午两点到六点之间,随后气温逐渐下降,在第二天早上六点时达到最低值。


我们进行数据分析的目的是尝试解释是否能够评估海洋是怎样影响气温的,以及是否能够影响气温趋势,因此我们同时来看几个不同城市的气温趋势。这是检验分析方向是否正确的唯一方式。因此,我们选择三个离海最近以及三个离海最远的城市。
# 读取数据文件(之前没读取数据的同学,这里一定要读取啦)
df_ravenna = pd.read_csv('ravenna_270615.csv')
df_faenza = pd.read_csv('faenza_270615.csv')
df_cesena = pd.read_csv('cesena_270615.csv')
df_asti = pd.read_csv('asti_270615.csv')
df_torino = pd.read_csv('torino_270615.csv')
df_milano = pd.read_csv('milano_270615.csv')
# 读取温度和日期数据
y1 = df_ravenna['temp']
x1 = df_ravenna['day']
y2 = df_faenza['temp']
x2 = df_faenza['day']
y3 = df_cesena['temp']
x3 = df_cesena['day']
y4 = df_milano['temp']
x4 = df_milano['day']
y5 = df_asti['temp']
x5 = df_asti['day']
y6 = df_torino['temp']
x6 = df_torino['day']
# 把日期从 string 类型转化为标准的 datetime 类型
day_ravenna = [parser.parse(x) for x in x1]
day_faenza = [parser.parse(x) for x in x2]
day_cesena = [parser.parse(x) for x in x3]
dat_milano = [parser.parse(x) for x in x4]
day_asti = [parser.parse(x) for x in x5]
day_torino = [parser.parse(x) for x in x6]
# 调用 subplots() 函数,重新定义 fig, ax 变量
fig, ax = plt.subplots()
plt.xticks(rotation=70)
hours = mdates.DateFormatter('%H:%M')
ax.xaxis.set_major_formatter(hours)
#这里需要画出三根线,所以需要三组参数, 'g'代表'green'
ax.plot(day_ravenna,y1,'r',day_faenza,y2,'r',day_cesena,y3,'r')
ax.plot(dat_milano,y4,'g',day_asti,y5,'g',day_torino,y6,'g')
fig
上述代码将生成如图9-9所示的图表。离海最近的三个城市的气温曲线使用红色,而离海最远的三个城市的曲线使用绿色。


如图9-9所示,结果看起来不错。离海最近的三个城市的最高气温比离海最远的三个城市低不少,而最低气温看起来差别较小。
我们可以沿着这个方向做深入研究,收集10个城市的最高温和最低温,用线性图表示气温最值点和离海远近之间的关系。
# dist 是一个装城市距离海边距离的列表
dist = [df_ravenna['dist'][0],
df_cesena['dist'][0],
df_faenza['dist'][0],
df_ferrara['dist'][0],
df_bologna['dist'][0],
df_mantova['dist'][0],
df_piacenza['dist'][0],
df_milano['dist'][0],
df_asti['dist'][0],
df_torino['dist'][0]
]
# temp_max 是一个存放每个城市最高温度的列表
temp_max = [df_ravenna['temp'].max(),
df_cesena['temp'].max(),
df_faenza['temp'].max(),
df_ferrara['temp'].max(),
df_bologna['temp'].max(),
df_mantova['temp'].max(),
df_piacenza['temp'].max(),
df_milano['temp'].max(),
df_asti['temp'].max(),
df_torino['temp'].max()
]
# temp_min 是一个存放每个城市最低温度的列表
temp_min = [df_ravenna['temp'].min(),
df_cesena['temp'].min(),
df_faenza['temp'].min(),
df_ferrara['temp'].min(),
df_bologna['temp'].min(),
df_mantova['temp'].min(),
df_piacenza['temp'].min(),
df_milano['temp'].min(),
df_asti['temp'].min(),
df_torino['temp'].min()
]
先把最高温画出来。
fig, ax = plt.subplots()
ax.plot(dist,temp_max,'ro')
fig
结果如图9-10所示。


如图9-10所示,现在你可以证实,海洋对气象数据具有一定程度的影响这个假设是正确的(至 少这一天如此)。
进一步观察上图,你会发现海洋的影响衰减得很快,离海60~70公里开外,气温就已攀升到 高位。
用线性回归算法得到两条直线,分别表示两种不同的气温趋势,这样做很有趣。我们可以使 用scikit-learn库的SVR方法。(注意:这段代码会跑比较久的时间)
from sklearn.svm import SVR
# dist1是靠近海的城市集合,dist2是远离海洋的城市集合
dist1 = dist[0:5]
dist2 = dist[5:10]
# 改变列表的结构,dist1现在是5个列表的集合
# 之后我们会看到 numpy 中 reshape() 函数也有同样的作用
dist1 = [[x] for x in dist1]
dist2 = [[x] for x in dist2]
# temp_max1 是 dist1 中城市的对应最高温度
temp_max1 = temp_max[0:5]
# temp_max2 是 dist2 中城市的对应最高温度
temp_max2 = temp_max[5:10]
# 我们调用SVR函数,在参数中规定了使用线性的拟合函数
# 并且把 C 设为1000来尽量拟合数据(因为不需要精确预测不用担心过拟合)
svr_lin1 = SVR(kernel='linear', C=1e3)
svr_lin2 = SVR(kernel='linear', C=1e3)
# 加入数据,进行拟合(这一步可能会跑很久,大概10多分钟,休息一下:) )
svr_lin1.fit(dist1, temp_max1)
svr_lin2.fit(dist2, temp_max2)
# 关于 reshape 函数请看代码后面的详细讨论
xp1 = np.arange(10,100,10).reshape((9,1))
xp2 = np.arange(50,400,50).reshape((7,1))
yp1 = svr_lin1.predict(xp1)
yp2 = svr_lin2.predict(xp2)
# 限制了 x 轴的取值范围
ax.set_xlim(0,400)
# 画出图像
ax.plot(xp1, yp1, c='b', label='Strong sea effect')
ax.plot(xp2, yp2, c='g', label='Light sea effect')
fig
这里 np.arange(10,100,10) 会返回 [10, 20, 30,..., 90],如果把列表看成是一个矩阵,那么这个矩阵是 1 9 的。这里 reshape((9,1)) 函数就会把该列表变为 1 9 的, [[10], [20], ..., [90]]。这么做的原因是因为 predict() 函数的只能接受一个 N 1 的列表,返回一个 1 N 的列表。
上述代码将生成如图9-11所示的图像。


如上所见,离海60公里以内,气温上升速度很快,从28度陡升至31度,随后增速渐趋缓和(如果还继续增长的话),更长的距离才会有小幅上升。这两种趋势可分别用两条直线来表示,直线的表达式为:
x = ax + b
其中a为斜率,b为截距。
print svr_lin1.coef_ #斜率
print svr_lin1.intercept_ # 截距
print svr_lin2.coef_
print svr_lin2.intercept_
[[0.04794118]]
[ 27.65617647]
[[0.00401274]]
[ 29.98745223]
你可能会考虑将这两条直线的交点作为受海洋影响和不受海洋影响的区域的分界点,或者至少是海洋影响较弱的分界点。
from scipy.optimize import fsolve
# 定义了第一条拟合直线
def line1(x):
a1 = svr_lin1.coef_[0][0]
b1 = svr_lin1.intercept_[0]
return a1*x + b1
# 定义了第二条拟合直线
def line2(x):
a2 = svr_lin2.coef_[0][0]
b2 = svr_lin2.intercept_[0]
return a2*x + b2
# 定义了找到两条直线的交点的 x 坐标的函数
def findIntersection(fun1,fun2,x0):
return fsolve(lambda x : fun1(x) - fun2(x),x0)
result = findIntersection(line1,line2,0.0)
print "[x,y] = [ %d , %d ]" % (result,line1(result))
# x = [0,10,20, ..., 300]
x = np.linspace(0,300,31)
plt.plot(x,line1(x),x,line2(x),result,line1(result),'ro')
执行上述代码,将得到交点的坐标
[x,y] = [ 53, 30 ]
并得到如图9-12所示的图表。


因此,你可以说海洋对气温产生影响的平均距离(该天的情况)为53公里。
现在,我们可以转而分析最低气温。
# axis 函数规定了 x 轴和 y 轴的取值范围
plt.axis((0,400,15,25))
plt.plot(dist,temp_min,'bo')


在这个例子中,很明显夜间或早上6点左右的最低温与海洋无关。如果没记错的话,小时候老师教给大家的是海洋能够缓和低温,或者说夜间海洋释放白天吸收的热量。但是从我们得到情况来看并非如此。我们刚使用的是意大利夏天的气温数据,而验证该假设在冬天或其他地方是否也成立,将会非常有趣。
5.2 湿度数据分析
10个DataFrame对象中还包含湿度这个气象数据。因此,你也可以考察当天三个近海城市和 三个内陆城市的湿度趋势。
# 读取湿度数据
y1 = df_ravenna['humidity']
x1 = df_ravenna['day']
y2 = df_faenza['humidity']
x2 = df_faenza['day']
y3 = df_cesena['humidity']
x3 = df_cesena['day']
y4 = df_milano['humidity']
x4 = df_milano['day']
y5 = df_asti['humidity']
x5 = df_asti['day']
y6 = df_torino['humidity']
x6 = df_torino['day']
# 重新定义 fig 和 ax 变量
fig, ax = plt.subplots()
plt.xticks(rotation=70)
# 把时间从 string 类型转化为标准的 datetime 类型
day_ravenna = [parser.parse(x) for x in x1]
day_faenza = [parser.parse(x) for x in x2]
day_cesena = [parser.parse(x) for x in x3]
day_milano = [parser.parse(x) for x in x4]
day_asti = [parser.parse(x) for x in x5]
day_torino = [parser.parse(x) for x in x6]
# 规定时间的表示方式
hours = mdates.DateFormatter('%H:%M')
ax.xaxis.set_major_formatter(hours)
#表示在图上
ax.plot(day_ravenna,y1,'r',day_faenza,y2,'r',day_cesena,y3,'r')
ax.plot(day_milano,y4,'g',day_asti,y5,'g',day_torino,y6,'g')
fig
上述代码将生成如图9-14所示的图表。


乍看上去好像近海城市的湿度要大于内陆城市,全天湿度差距在20%左右。我们再来看一下湿度的极值和离海远近之间的关系,是否跟我们的第一印象相符。
# 获取最大湿度数据
hum_max = [df_ravenna['humidity'].max(),
df_cesena['humidity'].max(),
df_faenza['humidity'].max(),
df_ferrara['humidity'].max(),
df_bologna['humidity'].max(),
df_mantova['humidity'].max(),
df_piacenza['humidity'].max(),
df_milano['humidity'].max(),
df_asti['humidity'].max(),
df_torino['humidity'].max()
]
plt.plot(dist,hum_max,'bo')
我们把10个城市的最大湿度与离海远近之间的关系做成图表,请见图9-15。


# 获取最小湿度
hum_min = [df_ravenna['humidity'].min(),
df_cesena['humidity'].min(),
df_faenza['humidity'].min(),
df_ferrara['humidity'].min(),
df_bologna['humidity'].min(),
df_mantova['humidity'].min(),
df_piacenza['humidity'].min(),
df_milano['humidity'].min(),
df_asti['humidity'].min(),
df_torino['humidity'].min()
]
plt.plot(dist,hum_min,'bo')
再来把10个城市的最小湿度与离海远近之间的关系做成图表,请见图9-16。


由图9-15和图9-16可以确定,近海城市无论是最大还是最小湿度都要高于内陆城市。然而在 我看来,我们还不能说湿度和距离之间存在线性关系或者其他能用曲线表示的关系。我们采集的 数据点数量(10)太少,不足以描述这类趋势。
5.3 风向频率玫瑰图
在我们采集的每个城市的气象数据中,下面两个与风有关:
- 风力(风向)
- 风速
分析存放每个城市气象数据的DataFrame就会发现,风速不仅跟一天的时间段相关联,还与 一个介于0~360度的方向有关。例如,每一条测量数据也包含风吹来的方向(图9-17)。


为了更好地分析这类数据,有必要将其做成可视化形式,但是对于风力数据,将其制作成使用笛卡儿坐标系的线性图不再是最佳选择。
要是把一个DataFrame中的数据点做成散点图
plt.plot(df_ravenna['wind_deg'],df_ravenna['wind_speed'],'ro')
就会得到图9-18这样的图表,很显然该图的表现力也有不足。


要表示呈360度分布的数据点,最好使用另一种可视化方法:极区图。
首先,创建一个直方图,也就是将360度分为八个面元,每个面元为45度,把所有的数据点分到这八个面元中。
hist, bins = np.histogram(df_ravenna['wind_deg'],8,[0,360])
print hist
print bins
histogram()函数返回结果中的数组hist为落在每个面元的数据点数量。
[ 0 5 11 1 0 1 0 0]
返回结果中的数组bins定义了360度范围内各面元的边界。
[ 0. 45. 90. 135. 180. 225. 270. 315. 360.]
要想正确定义极区图,离不开这两个数组。我们将创建一个函数来绘制极区图,其中部分代码在第7章已讲过。我们把这个函数定义为showRoseWind(),它有三个参数:values数组,指的是想为其作图的数据,也就是这里的hist数组;第二个参数city_name为字符串类型,指定图表标题所用的城市名称;最后一个参数max_value为整型,指定最大的蓝色值。
定义这样一个函数很有用,它既能避免多次重复编写相同的代码,还能增强代码的模块化程度,便于你把精力放到与函数内部操作相关的概念上。
def showRoseWind(values,city_name,max_value):
N = 8
# theta = [pi*1/4, pi*2/4, pi*3/4, ..., pi*2]
theta = np.arange(0.,2 * np.pi, 2 * np.pi / N)
radii = np.array(values)
# 绘制极区图的坐标系
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
# 列表中包含的是每一个扇区的 rgb 值,x越大,对应的color越接近蓝色
colors = [(1-x/max_value, 1-x/max_value, 0.75) for x in radii]
# 画出每个扇区
plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
# 设置极区图的标题
plt.title(city_name, x=0.2, fontsize=20)
你需要修改变量colors存储的颜色表。这里,扇形的颜色越接近蓝色,值越大。定义好函数之后,调用它即可:
showRoseWind(hist,'Ravenna',max(hist))
运行上述函数,将得到如图9-19所示的极区图。


由图9-19可见,整个360度的范围被分成八个区域(面元),每个区域弧长为45度,此外每个区域还有一列呈放射状排列的刻度值。在每个区域中,用半径长度可以改变的扇形表示一个数值,半径越长,扇形所表示的数值就越大。为了增强图表的可读性,我们使用与扇形半径相对应的颜色表。半径越长,扇形跨度越大,颜色越接近于深蓝色。
从刚得到的极区图可以得知风向在极坐标系中的分布方式。该图表示这一天大部分时间风都 吹向西南和正西方向。
定义好showRoseWind()函数之后,查看其他城市的风向情况也非常简单。
hist, bin = np.histogram(df_ferrara['wind_deg'],8,[0,360])
print hist
showRoseWind(hist,'Ferrara', max(hist))

计算风速均值的分布情况
即使是跟风速相关的其他数据,也可以用极区图来表示。
定义RoseWind_Speed函数,计算将360度范围划分成的八个面元中每个面元的平均风速。
def RoseWind_Speed(df_city):
# degs = [45, 90, ..., 360]
degs = np.arange(45,361,45)
tmp = []
for deg in degs:
# 获取 wind_deg 在指定范围的风速平均值数据
tmp.append(df_city[(df_city['wind_deg']>(deg-46)) & (df_city['wind_deg']<deg)]
['wind_speed'].mean())
return np.array(tmp)
这里 df_city[(df_city['wind_deg']>(deg-46)) & (df_city['wind_deg']<deg)] 获取的是风向大于 'deg-46' 度和风向小于 'deg' 的数据。
RoseWind_Speed() 函数返回一个包含八个平均风速值的NumPy数组。该数组将作为先前定义的showRoseWind()函数的第一个参数,这个函数是用来绘制极区图的。
showRoseWind(RoseWind_Speed(df_ravenna),'Ravenna',max(hist))
图9-21所示的风向频率玫瑰图表示风速在360度范围内的分布情况。


六、实验总结
本章主要目的是演示如何从原始数据获取信息。其中有些信息无法给出重要结论,而有些信息能够验证假设,增加我们对系统状态的认识,而找出这种信息也就意味着数据分析取得了成功。
如果学完本课程,对书籍其他内容感兴趣欢迎点击以下链接购买书籍:
python气象分析的更多相关文章
- Python股票分析系列——自动获取标普500股票列表.p5
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第5部分.在本教程和接下来的几节中,我们将着手研究如何为更多公司提供大量的定价信息,以及如何一次 ...
- Python股票分析系列——基础股票数据操作(二).p4
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第4部分.在本教程中,我们将基于Adj Close列创建烛台/ OHLC图,这将允许我介绍重新采 ...
- Python股票分析系列——基础股票数据操作(一).p3
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第3部分.在本教程中,我们将使用我们的股票数据进一步分解一些基本的数据操作和可视化.我们将要使用 ...
- Python股票分析系列——数据整理和绘制.p2
该系列视频已经搬运至bilibili: 点击查看 欢迎来到Python for Finance教程系列的第2部分. 在本教程中,我们将利用我们的股票数据进一步分解一些基本的数据操作和可视化. 我们将要 ...
- Python股票分析系列——系列介绍和获取股票数据.p1
本系列转载自youtuber sentdex博主的教程视频内容 https://www.youtube.com/watch?v=19yyasfGLhk&index=4&list=PLQ ...
- Python数据采集分析告诉你为何上海二手房你都买不起
感谢关注Python爱好者社区公众号,在这里,我们会每天向您推送Python相关的文章实战干货. 来吧,一起Python. 对商业智能BI.大数据分析挖掘.机器学习,python,R等数据领域感兴趣的 ...
- 【转】python模块分析之collections(六)
[转]python模块分析之collections(六) collections是Python内建的一个集合模块,提供了许多有用的集合类. 系列文章 python模块分析之random(一) pyth ...
- 【转】python模块分析之unittest测试(五)
[转]python模块分析之unittest测试(五) 系列文章 python模块分析之random(一) python模块分析之hashlib加密(二) python模块分析之typing(三) p ...
- 【转】python模块分析之typing(三)
[转]python模块分析之typing(三) 前言:很多人在写完代码一段时间后回过头看代码,很可能忘记了自己写的函数需要传什么参数,返回什么类型的结果,就不得不去阅读代码的具体内容,降低了阅读的速度 ...
随机推荐
- [LeetCode&Python] Problem 807. Max Increase to Keep City Skyline
In a 2 dimensional array grid, each value grid[i][j] represents the height of a building located the ...
- 任务三 简单程序测试及 GitHub Issues 的使用
我提交的Issue 我被提出的Issue 在使用Issue的过程中我发现提出的Issue不能指派任务人和问题类型,被提出的Issue可以. 碰到最多的问题是测试程序的过程中, 比如用户未按指定格式输入 ...
- Codeup1085: 阶乘的和
题目描述 有些数可以表示成若干个不同阶乘的和.例如,9=1!+2!+3!.小明对这些数很感兴趣,所以他给你一个正整数n,想让你告诉他这个数是否可以表示成若干个不同阶乘的和. 输入 输入包含多组测试数据 ...
- 大家一起做训练 第一场 E Number With The Given Amount Of Divisors
题目来源:CodeForce #27 E 题目意思和题目标题一样,给一个n,求约数的个数恰好为n个的最小的数.保证答案在1018内. Orz,这题训练的时候没写出来. 这道题目分析一下,1018的不大 ...
- 强连通分量【k 算法、t 算法】
连通分量就是一个各个顶点能互相达到的图 无向图的连通分量选取任意一个顶点使用DFS遍历即可,遍历完所有顶点所需的DFS的次数就是连通分量的数量 有向图的强连通分量由于是有向的[从A点开始DFS能访问到 ...
- JQ和JS获取span标签的内容(有的情况下JQ达不到预期的目的就用JS)
https://www.cnblogs.com/anniey/p/6439021.html <span id="content">‘我是span标签的内容’</s ...
- day11 python学习 函数的建立,返回值,参数
函数的定义主要有如下要点: def:表示函数的关键字 函数名:函数的名称,日后根据函数名调用函数 函数体:函数中进行一系列的逻辑计算,如:发送邮件.计算出 [11,22,38,888,2]中的最大数等 ...
- stenciljs 学习七 路由
stenciljs路由类似react router 安装 npm install @stencil/router --save 使用 导入包 import "@stencil/router& ...
- Oracle 存储过程了解
简要记录存储过程语法与Java程序的调用方式 一 存储过程 首先,我们建立一个简单的表进行存储过程的测试 createtable xuesheng(id integer, xing_ming varc ...
- x86函数调用约定
以下摘自<IDA Pro>,貌似有一些细节之处没有交代清楚呢,需要进一步思考.实践. 了解栈帧的基本概念后,接下来详细介绍它们的结构.下面的例子涉及x86体系结构和与常见的x86编译器(如 ...