【转】五分钟读懂大数据核心MapReduce架构及原理
什么是MapReduce
Hadoop中的MapReduce是一个简单的软件框架,基于它写出的应用程序可以运行在由上千个商用机器组成的大型集群上,并以一种可靠容错式并行处理TB级数据
MapReduce的起源
源于谷歌在2004年发表的一篇MapReduce的论文,而Hadoop Reduce实际上就是谷歌MapReduce的克隆版本
MapReduce具有的特点
众所周知MapReduce是一种很受欢迎的软件框架,尤其是我们国家发展到现在互联网的浪潮愈演愈烈,那么它都有什么特点呢?
1.易于编程:MapReduce通过相应的接口,程序员只需要简单的调用就可以完成对一个复杂的分布式程序的编写。
2.易扩展性:在计算资源不足时可以通过增加机器来增加计算能力
3.高容错性:要知道MapReduce的提出就是为了运行在廉价的商用pc中,而商用pc得到问题也是颇多,经常会出现pc挂掉的情况,这时候就需要可以迅速的把计算任何和资源转移到另外的一个节点上运行,从而保证任务、作业的顺利运行。
4.海量PB级数据的离线处理,所谓离线处理即为它不具体毫秒级别的迅速反馈能力,在对反馈要求非常及时的场景下,自然是不可用的
那么MapReduce有哪些不适合的场景呢?
1.实时计算。没有mysql等数据库的毫秒级反馈能力,尽管可以用过hive等数据库进行高速的计算但是速度还是不及
2.流式计算。流式计算的输入数据时动态的,而 MapReduce 的输入数据集是静态的,不能动态变化。这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的
3.DAG(有向图)模式:即每个作业或者任务之间都有很强的连接性,下一个作业的运行需要另外一个作业的运行结果的数据,这种情况下MapReduce的性能非常低,因为每个MapReduce的作业都会把计算写入到磁盘中,若如此做则会造成大量的磁盘IO,性能低下。
MapReduce的编程模型
MapReduce 实例
为了分析 MapReduce 的编程模型,这里我们以 WordCount 为实例。就像 Java、C++等编程语言的入门程序 hello word 一样,WordCount 是 MapReduce 最简单的入门程序。下面我们就来逐步分析。
1、场景:假如有大量的文件,里面存储的都是单词。
类似应用场景:WordCount 虽然很简单,但它是很多重要应用的模型。
1) 搜索引擎中,统计最流行的 K 个搜索词。
2) 统计搜索词频率,帮助优化搜索词提示。
2、任务:我们该如何统计每个单词出现的次数?
3、将问题规范为:有一批文件(规模为 TB 级或者 PB 级),如何统计这些文件中所有单词出现的次数。
4、解决方案:首先,分别统计每个文件中单词出现的次数;然后,累加不同文件中同一个单词出现次数。
MapReduce 执行流程
通过上面的分析可知,它其实就是一个典型的 MapReduce 过程。下面我们通过示意图来分析 MapReduce 过程。
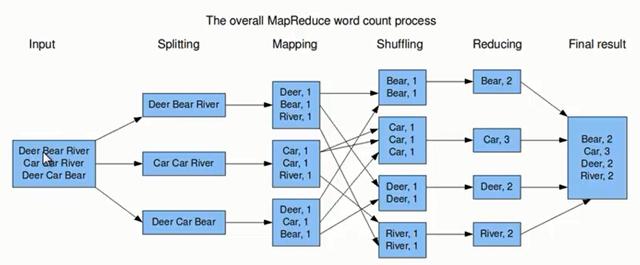
上图的流程大概分为以下几步。
第一步:假设一个文件有三行英文单词作为 MapReduce 的Input(输入),这里经过 Splitting 过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。
第二步:每个 map 线程中,以每个单词为key,以1作为词频数value,然后输出。
第三步:每个 map 的输出要经过 shuffling(混洗),将相同的单词key放在一个桶里面,然后交给 reduce 处理。
第四步:reduce 接受到 shuffling 后的数据, 会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
上述就是 MapReduce 的大致流程,前两步可以看做 map 阶段,后两步可以看做 reduce 阶段。下面我们来看看 MapReduce 大致实现。
1、Input:首先 MapReduce 输入的是一系列key/value对。key表示每行偏移量,value代表每行输入的单词。
2、用户提供了 map 函数和 reduce 函数的实现:
map(k,v) ——> list(k1,v1)
reduce(k1,list(v1)) ——>(k2,v2)
map 函数将每个单词转化为key/value对输出,这里key为每个单词,value为词频1。(k1,v1)是 map 输出的中间key/value结果对。reduce 将相同单词的所有词频进行合并,比如将单词k1,词频为list(v1),合并为(k2,v2)。reduce 合并完之后,最终输出一系列(k2,v2)键值对。
下面我们来看一下 MapReduce 的伪代码。
map(key,value)://map 函数,key代表偏移量,value代表每行单词
for each word w in value: //循环每行数据,输出每个单词和词频的键值对(w,1)
emit(w,1)
reduce(key,values)://reduce 函数,key代表一个单词,value代表这个单词的所有词频数集合
result=0
for each count v in values: //循环词频集合,求出该单词的总词频数,然后输出(key,result)
result+=v
emit(key,result)
讲到这里,我们可以对 MapReduce 做一个总结。MapReduce 将 作业的整个运行过程分为两个阶段:Map 阶段和Reduce 阶段。
1、Map 阶段
Map 阶段是由一定数量的 Map Task 组成。这些 Map Task 可以同时运行,每个 Map Task又是由以下三个部分组成。
1) 对输入数据格式进行解析的一个组件:InputFormat。因为不同的数据可能存储的数据格式不一样,这就需要有一个 InputFormat 组件来解析这些数据的存放格式。默认情况下,它提供了一个 TextInputFormat 来解释数据格式。TextInputFormat 就是我们前面提到的文本文件输入格式,它会将文件的每一行解释成(key,value),key代表每行偏移量,value代表每行数据内容。 通常情况我们不需要自定义 InputFormat,因为 MapReduce 提供了很多种InputFormat的实现,我们根据不同的数据格式,选择不同的 InputFormat 来解释就可以了。这一点我们后面会讲到。
2)输入数据处理:Mapper。这个 Mapper 是必须要实现的,因为根据不同的业务对数据有不同的处理。
3)数据分组:Partitioner。Mapper 数据处理之后输出之前,输出key会经过 Partitioner 分组或者分桶选择不同的reduce。默认的情况下,Partitioner 会对 map 输出的key进行hash取模,比如有6个Reduce Task,它就是模(mod)6,如果key的hash值为0,就选择第0个 Reduce Task,如果key的hash值为1,就选择第一个 Reduce Task。这样不同的 map 对相同单词key,它的 hash 值取模是一样的,所以会交给同一个 reduce 来处理。
2、Reduce 阶段
Reduce 阶段由一定数量的 Reduce Task 组成。这些 Reduce Task 可以同时运行,每个 Reduce Task又是由以下四个部分组成。
1) 数据运程拷贝。Reduce Task 要运程拷贝每个 map 处理的结果,从每个 map 中读取一部分结果。每个 Reduce Task 拷贝哪些数据,是由上面 Partitioner 决定的。
2) 数据按照key排序。Reduce Task 读取完数据后,要按照key进行排序。按照key排序后,相同的key被分到一组,交给同一个 Reduce Task 处理。
3) 数据处理:Reducer。以WordCount为例,相同的单词key分到一组,交个同一个Reducer处理,这样就实现了对每个单词的词频统计。
4) 数据输出格式:OutputFormat。Reducer 统计的结果,将按照 OutputFormat 格式输出。默认情况下的输出格式为 TextOutputFormat,以WordCount为例,这里的key为单词,value为词频数。
InputFormat、Mapper、Partitioner、Reducer和OutputFormat 都是用户可以实现的。通常情况下,用户只需要实现 Mapper和Reducer,其他的使用默认实现就可以了。
【转】五分钟读懂大数据核心MapReduce架构及原理的更多相关文章
- [转载] 2 分钟读懂大数据框架 Hadoop 和 Spark 的异同
转载自https://www.oschina.net/news/73939/hadoop-spark-%20difference 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字 ...
- 2分钟读懂大数据框架Hadoop和Spark的异同
转自:https://www.cnblogs.com/reed/p/7730313.html 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生.但我们往往对它们的理解只是 ...
- zookeeper核心-zab协议-《每日五分钟搞定大数据》
上篇文章<paxos与一致性>说到zab是在paxos的基础上做了重要的改造,解决了一系列的问题,这一篇我们就来说下这个zab. zab协议的全称是ZooKeeper Atomic Bro ...
- zookeeper-架构设计与角色分工-《每日五分钟搞定大数据》
本篇文章阅读时间5分钟左右 点击看<每日五分钟搞定大数据>完整思维导图 zookeeper作为一个分布式协调系统,很多组件都会依赖它,那么此时它的可用性就非常重要了,那么保证可用性的同 ...
- HDFS-异常大全-《每日五分钟搞定大数据》
点击看<每日五分钟搞定大数据>完整思维导图以及所有文章目录 问题1:Decomminssioning退役datanode(即删除节点) 1.配置exclude: <name>d ...
- 五分钟读懂UML类图
平时阅读一些远吗分析类文章或是设计应用架构时没少与UML类图打交道.实际上,UML类图中最常用到的元素五分钟就能掌握,下面赶紧来一起认识一下它吧: 一.类的属性的表示方式 在UML类图中,类使用包含类 ...
- 五分钟读懂UML类图(转)
平时阅读一些远吗分析类文章或是设计应用架构时没少与UML类图打交道.实际上,UML类图中最常用到的元素五分钟就能掌握,下面赶紧来一起认识一下它吧: 一.类的属性的表示方式 在UML类图中,类使用包含类 ...
- zookeeper-操作与应用场景-《每日五分钟搞定大数据》
Zookeeper作为一个分布式协调系统提供了一项基本服务:分布式锁服务,分布式锁是分布式协调技术实现的核心内容.像配置管理.任务分发.组服务.分布式消息队列.分布式通知/协调等,这些应用实际上都是基 ...
- 五分钟读懂UML类图(转)
平时阅读一些远吗分析类文章或是设计应用架构时没少与UML类图打交道.实际上,UML类图中最常用到的元素五分钟就能掌握,下面赶紧来一起认识一下它吧: 一.类的属性的表示方式 在UML类图中,类使用包含类 ...
随机推荐
- ftok函数
ftok函数 系统建立IPC通讯(消息队列.信号量和共享内存)时必须指定一个ID值.通常情况下,该id值通过ftok函数得到. ftok原型 头文件: #include <sys/types.h ...
- Win7去掉桌面图标小箭头
去掉win7的快捷方式的小箭头: 每当我们装完一个软件,在桌面生成快捷方式的时候总会有个小箭头,有些朋友看到觉得很烦,如何去掉这个小箭头呢? 点击开始图标 - 附件 - 命令提示符(有情提示,请右击用 ...
- vue中打包生成可配置文件以便修改接口地址
vue打包上传到服务器之后,如果数据接口域名发生变化,需要手动修改接口地址,在发布的时候也麻烦,于是.. 在打包之后如果有一个json配置文件以便修改那不是方便很多 在网上找了一些方法貌似都是异步请求 ...
- 推荐系统之最小二乘法ALS的Spark实现
1.ALS算法流程: 初始化数据集和Spark环境----> 切分测试机和检验集------> 训练ALS模型------------> 验证结果-----------------& ...
- HIT 2739 - The Chinese Postman Problem - [带权有向图上的中国邮路问题][最小费用最大流]
题目链接:http://acm.hit.edu.cn/hoj/problem/view?id=2739 Time limit : 1 sec Memory limit : 64 M A Chinese ...
- Pandas的concat方法
在此我用的concat作用是加入新的记录,存储数据来用过的,不知道数据量大时候,效率会怎样 # 使用pandas来保存数据 df1 = pd.DataFrame([poem], columns=['p ...
- flume学习笔记
#################################################################################################### ...
- bisecting k-means
总结 1.二分法 2.总体中的最值 bisecting k-means :在初始时将所有数据当成一个聚簇,然后递归地将最不紧凑的聚簇用2-means拆分为2个聚簇,直至满意
- SEO工作中如何增加用户体验?10个细节要注意!
我们一直在做的网站SEO工作,如果你认为它的目的仅仅是为了提高网站的排名那就错了,还有一个同样很重要的方面就是增加用户的体验,使网站更加符合网民的浏览习惯,需要做到这个方面的成功我们有10个小细节是需 ...
- 设置elasticsearch一次最大数量查询
PUT my_index/_settings?preserve_existing=true{ "max_result_window": "2000000000" ...