python进行数据分析------相关分析
相关分析
import statsmodels.api as sm
import pandas as pd
import numpy as np
from patsy.highlevel import dmatrices # 这个是线性回归的
from common.util.my_sqlalchemy import sqlalchemy_engine
import math from scipy.stats.stats import pearsonr sql = "select Q1R3, Q1R5, Q1R6, Q1R7 from db2017091115412316222027656281_1;"
df = pd.read_sql(sql, sqlalchemy_engine)
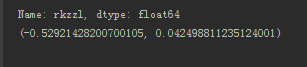
df_dropna = df.dropna() result = pearsonr(df_dropna['Q1R3'], df_dropna['Q1R5'])
print(result)
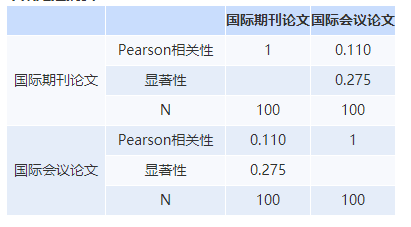
报告展示:
相关性检验显示,rkzzl与gmsr显著负相关(Pearson’r=-0.529,p<0.05)。
若p>0.5则写:rkzzl与gmsr无显著相关关系(Pearson’r=-0.529,p>0.05)。
|
Pearson’r |
p |
|
|
-0.5292 |
0.0425 |
| A | B | C | |
| A | AA | AB | AC |
| B | AB | BB | BC |
| C | AC | CB | CC |
二期
经过数据分析部指导,系数做了算法优化
def CorrelationAnalysisDetail(UserID,ProjID,QuesID,VariableNames,CasesCondition,VariableIDs,Corr):
select_id_ret = select_ques_datatableid_optionid()
whether_datatableid = select_id_ret.SelectDatatableIDTwoSql(UserID, ProjID, QuesID, VariableIDs[0])
select_id_ret.close()
if whether_datatableid:
DataTableID = whether_datatableid[0]["DataTableID"]
DatabaseName = whether_datatableid[0]["DatabaseName"]
TableName = JoinTableName(whether_datatableid)
df_dropna = CorrelationAnalysisModel(VariableNames,TableName, DatabaseName, CasesCondition)
# spearman 斯皮尔曼系数
# kendall 肯德尔系数
# pearson 皮尔逊系数
# return pearsonr(df_dropna[xVariable], df_dropna[yVariable]) return df_dropna.corr(method=Corr).to_dict()
python进行数据分析------相关分析的更多相关文章
- python进行数据分析
1. python进行数据分析----线性回归 2. python进行数据分析------相关分析 3. python进行数据分析---python3卡方 4. 多重响应分析,多选题二分法思路 5. ...
- 像Excel一样使用python进行数据分析
Excel是数据分析中最常用的工具,本篇文章通过python与excel的功能对比介绍如何使用python通过函数式编程完成excel中的数据处理及分析工作.在Python中pandas库用于数据处理 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
随机推荐
- jQuery正则的使用
转自:http://www.maiziedu.com/wiki/jquery/regular/ 基础正则 1.正则表达式的创建 a) var checkNum = /^[A-Za-z0-9]+$/; ...
- 【iOS XMPP】使用XMPPFramewok(一):添加XMPPFramework(XCode 4.6.2)
转自:http://www.cnblogs.com/dyingbleed/archive/2013/05/09/3069145.html XMPPFramework GitHub: https://g ...
- App开放接口API安全性 — Token签名sign的设计与实现
在app开放接口API的设计中,避免不了的就是安全性问题. 一.https协议 对于一些敏感的API接口,需要使用https协议. https是在http超文本传输协议加入SSL层,它在网络间通信是加 ...
- javascript基础拾遗(八)
1.原型继承 如何让一个对象继承另一个对象? function Language(name){ this.name = name this.score = 8.0 } Language.prototy ...
- 【驱动】linux设备驱动·字符设备驱动开发
Preface 前面对linux设备驱动的相应知识点进行了总结,现在进入实践阶段! <linux设备驱动入门篇>:http://infohacker.blog.51cto.com/6751 ...
- 豆瓣源安装requirements.txt
豆瓣源安装requirements.txt pip install -i https://pypi.doubanio.com/simple/ -r requirements.txt
- 【Ubuntu】任务管理器loadruner
linux1 准备工作 可以通过两种方法验证服务器上是否配置了rstatd守护程序: ①使用rup命令,它用于报告计算机的各种统计信息,其中就包括rstatd的配置信息.使用命令rup 10 ...
- 06-老马jQuery教程-jQuery高级
1.jQuery原型对象解密 jQuery里面的大部分API都是在jQuery的原型对象上定义的.jQuery源码中对原型对象做了简写的处理.也就是说:jQuery.fn === jQuery.pro ...
- 数据库并发事务控制四:postgresql数据库的锁机制二:表锁 <转>
在博文<数据库并发事务控制四:postgresql数据库的锁机制 > http://blog.csdn.net/beiigang/article/details/43302947 中后面提 ...
- MVC源码学习之AuthorizeAttribute
常见的Controller定义方式: public class HomeController : Controller { public ActionResult Index() { return V ...