《Enhanced LSTM for Natural Language Inference》(自然语言推理)
解决的问题
自然语言推理,判断a是否可以推理出b。简单讲就是判断2个句子ab是否有相同的含义。
方法
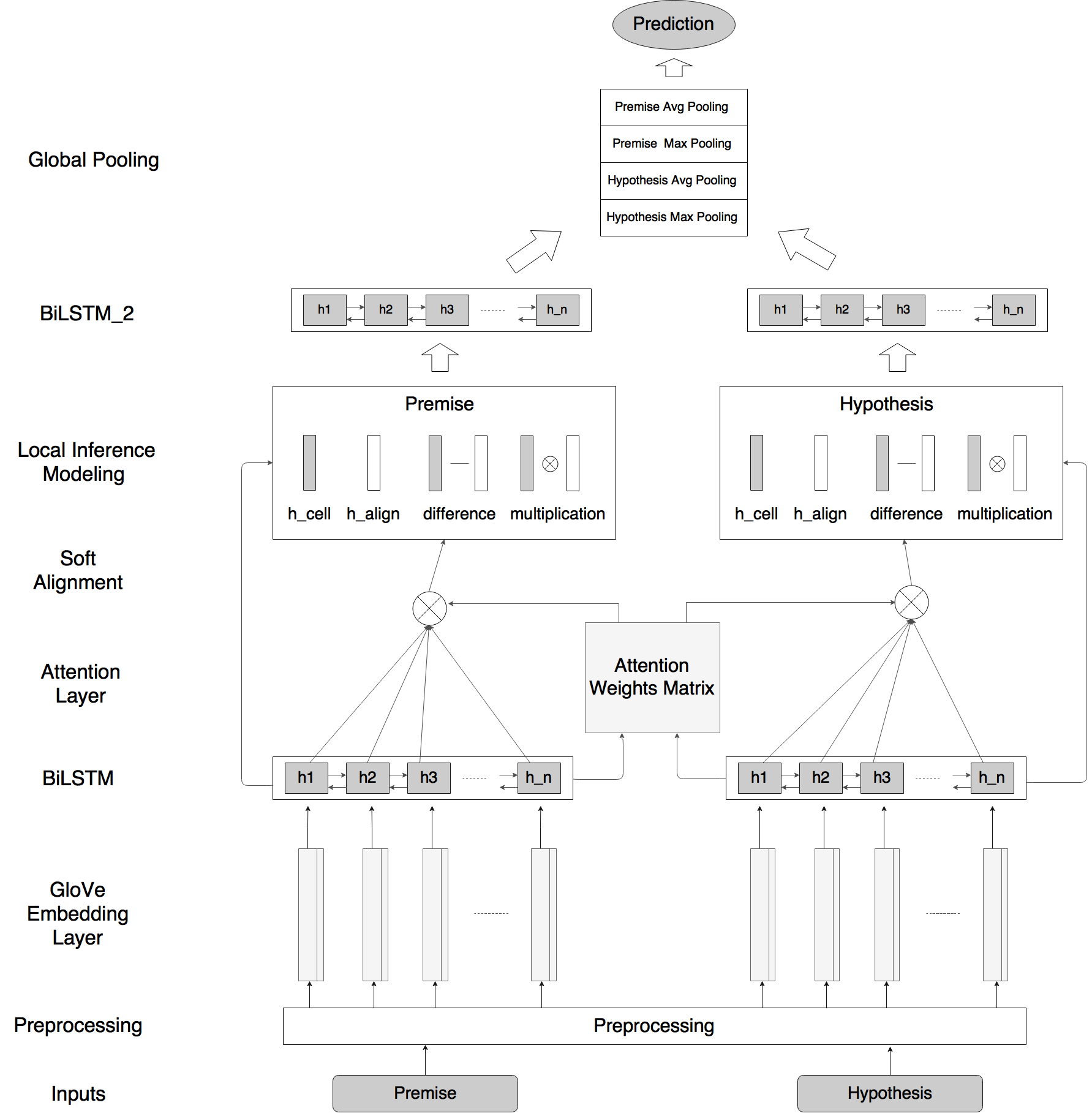
我们的自然语言推理网络由以下部分组成:输入编码(Input Encoding ),局部推理模型(Local Inference Modeling ),和推理合成(inference composition)。结构图如下所示:
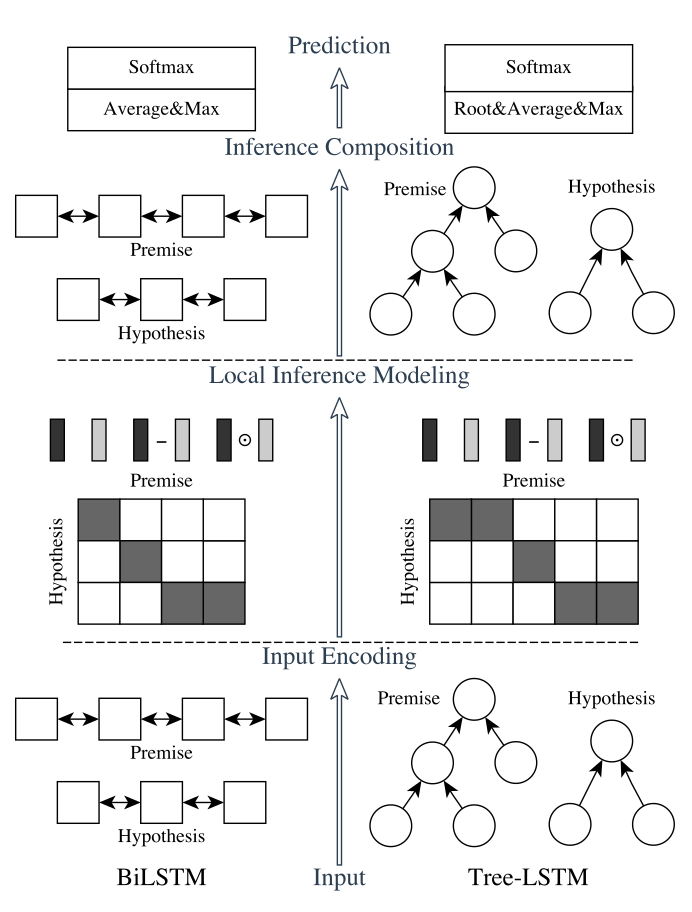
垂直来看,上图显示了系统的三个主要组成部分;水平来看,左边代表称为ESIM的序列NLI模型,右边代表包含了句法解析信息的树形LSTM网络。
输入编码
# Based on arXiv:1609.06038
q1 = Input(name='q1', shape=(maxlen,))
q2 = Input(name='q2', shape=(maxlen,)) # Embedding
embedding = create_pretrained_embedding(
pretrained_embedding, mask_zero=False)
bn = BatchNormalization(axis=2)
q1_embed = bn(embedding(q1))
q2_embed = bn(embedding(q2)) # Encode
encode = Bidirectional(LSTM(lstm_dim, return_sequences=True))
q1_encoded = encode(q1_embed)
q2_encoded = encode(q2_embed)
有2种lstm:
A: sequential model 的做法
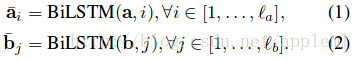
句子中的每个词都有了包含周围信息的 word representation
B: Tree-LSTM model的做法
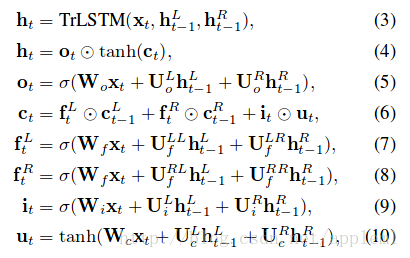
树中的每个节点(短语或字句)有了向量表示 htt
关于tree-LSTM 的介绍需要看文章:
[1] Improved semantic representations from tree-structured long short-term memory networks
[2] Natural Language inference by tree-based convolution and heuristic matching
[3] Long short-term memory over recursive structures
局部推理(Local Inference Modeling )
个人感觉就是一个attention的过程,取了个名字叫局部推理。
A: sequential model
def soft_attention_alignment(input_1, input_2):
"Align text representation with neural soft attention"
attention = Dot(axes=-1)([input_1, input_2]) #计算两个tensor中样本的张量乘积。例如,如果两个张量a和b的shape都为(batch_size, n),
#则输出为形如(batch_size,1)的张量,结果张量每个batch的数据都是a[i,:]和b[i,:]的矩阵(向量)点积。 w_att_1 = Lambda(lambda x: softmax(x, axis=1),
output_shape=unchanged_shape)(attention)
w_att_2 = Permute((2, 1))(Lambda(lambda x: softmax(x, axis=2),
output_shape=unchanged_shape)(attention))
#Permute层将输入的维度按照给定模式进行重排,例如,当需要将RNN和CNN网络连接时,可能会用到该层。
#dims:整数tuple,指定重排的模式,不包含样本数的维度。重拍模式的下标从1开始。
#例如(2,1)代表将输入的第二个维度重拍到输出的第一个维度,而将输入的第一个维度重排到第二个维度 in1_aligned = Dot(axes=1)([w_att_1, input_1])
in2_aligned = Dot(axes=1)([w_att_2, input_2])
return in1_aligned, in2_aligned
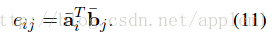
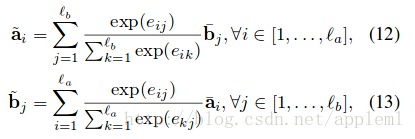
两句话相似或相反的对应
B: Tree-LSTM model
待续
推理合成(inference composition)
a是上层局部推理得到的。

ma 输入LSTM

对 lstm 每个time step 的结果进行pooling.

# Compare
q1_combined = Concatenate()(
[q1_encoded, q2_aligned, submult(q1_encoded, q2_aligned)])
q2_combined = Concatenate()(
[q2_encoded, q1_aligned, submult(q2_encoded, q1_aligned)])
compare_layers = [
Dense(compare_dim, activation=activation),
Dropout(compare_dropout),
Dense(compare_dim, activation=activation),
Dropout(compare_dropout),
]
q1_compare = time_distributed(q1_combined, compare_layers)
q2_compare = time_distributed(q2_combined, compare_layers) # Aggregate
q1_rep = apply_multiple(q1_compare, [GlobalAvgPool1D(), GlobalMaxPool1D()])
q2_rep = apply_multiple(q2_compare, [GlobalAvgPool1D(), GlobalMaxPool1D()])
《Enhanced LSTM for Natural Language Inference》(自然语言推理)的更多相关文章
- <A Decomposable Attention Model for Natural Language Inference>(自然语言推理)
http://www.xue63.com/toutiaojy/20180327G0DXP000.html 本文提出一种简单的自然语言推理任务下的神经网络结构,利用注意力机制(Attention Mec ...
- 论文阅读笔记: Natural Language Inference over Interaction Space
这篇文章提出了DIIN(DENSELY INTERACTIVE INFERENCE NETWORK)模型. 是解决NLI(NATURAL LANGUAGE INFERENCE)问题的很好的一种方法. ...
- <<Natural Language Inference over Interaction Space >> 句子匹配
模型结构 code :https://github.com/YichenGong/Densely-Interactive-Inference-Network 首先是模型图: Embedding Lay ...
- 第四篇:NLP(Natural Language Processing)自然语言处理
NLP自然语言处理: 百度AI的 NLP自然语言处理python语言--pythonSDK文档: https://ai.baidu.com/docs#/NLP-Python-SDK/top 第三方模块 ...
- 《Bilateral Multi-Perspective Matching for Natural Language Sentences》(句子匹配)
问题: Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术.针对NLSM任务,目前有两种流 ...
- Bilateral Multi-Perspective Matching for Natural Language Sentences---读书笔记
自然语言句子的双向.多角度匹配,是来自IBM 2017 年的一篇文章.代码github地址:https://github.com/zhiguowang/BiMPM 摘要 这篇论文主要 ...
- 论文笔记:Tracking by Natural Language Specification
Tracking by Natural Language Specification 2018-04-27 15:16:13 Paper: http://openaccess.thecvf.com/ ...
- 【翻译】Knowledge-Aware Natural Language Understanding(摘要及目录)
翻译Pradeep Dasigi的一篇长文 Knowledge-Aware Natural Language Understanding 基于知识感知的自然语言理解 摘要 Natural Langua ...
- BiMPM:Bilateral Multi-Perspctive Matching for Natural Language Sentences
导言 本论文的工作主要是在 'matching-aggregation'的sentence matching的框架下,通过增加模型的特征(实现P与Q的双向匹配和多视角匹配),来增加NLSM(Natur ...
随机推荐
- rsyslog local0-local7的用法
很多时候我们需要将一个服务的日志文件导向一个指定的文件,这个时候可以设置log-facility 如在dhcpd.conf中配置 1 : update log-facility in the dhcp ...
- Egret 中实现3种状态切换按钮
一.游戏中的常用3种状态按钮 Egret种提供了2种状态切换的按钮ToggleButton. 但是在游戏中常用到3种状态的按钮,比如任务系统的领取.已领取.未领取. 比如下图中宝箱的打开.浏览后打开. ...
- 关于IE和360安全浏览器如何添加百度搜索为默认的搜索引擎
以IE和360浏览器为例,细心的人可能会发现.IE浏览器默认使用的必应搜索引擎(cn.bing.com) 而360安全浏览器默认使用的好搜搜索引擎.(haosou.com),对于两种浏览器,我们都可以 ...
- [深入浅出Cocoa]iOS网络编程之Socket
http://blog.csdn.net/kesalin/article/details/8798039 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[+] [深入浅出Co ...
- 8.23 js
2018-8-23 15:12:05 js 参考 :https://www.cnblogs.com/liwenzhou/p/8011504.html 2018-8-23 20:56:29 上面js的东 ...
- PAT甲1031 Hello World for U【字符串】
1031 Hello World for U (20 分) Given any string of N (≥5) characters, you are asked to form the chara ...
- Scala学习笔记(1)-基本类型归纳
1.小试牛刀 使用Scala自带的REPL shell(Read Evaluate Print Loop)学习和尝试Scala语言库,创建的变量在会话期间都是有效的. Ctrl+D可退出REPL sh ...
- spring读取配置文件内容并自动注入
添加注解: @PropertySource(value={"classpath:venus.properties"}) 示例: import org.springframework ...
- 【make install】自定义安装目录,添加动态链接库 【--prefix】 【ldconfig】 【LD_LIBRARY_PATH】
怎么卸载make install安装的软件? https://www.zhihu.com/question/20092756 怎么指定安装目录以及对应的添加动态库的方法 linux库在不指定安装路径时 ...
- 【Python】Pycharm2018激活方式【亲测好用】
2.激活码激活 优点:Window.Mac.Ubantu都稳定有效,关键是这种激活方式不会产生其他影响 缺点:需要修改hosts文件 修改hosts文件将0.0.0.0 account.jetbrai ...