基于R进行相关性分析--转载
https://www.cnblogs.com/fanling999/p/5857122.html
一、相关性矩阵计算:
[1] 加载数据:
>data = read.csv("231-6057_2016-04-05-ZX_WD_2.csv",header=FALSE)
说明:csv格式的数据,header=FALSE 表示没有标题,即数据从第一行开始。
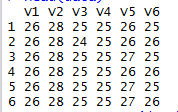
[2] 查看导入数据的前几行,
>head(data)

[3] 删除数据的7,8列,都是0
>data = data[1:6]
>head(data)
[4] 计算相关性矩阵(可以自己指定采用的方法,"pearson", "kendall", "spearman")
>cor_matr = cor(data)
>cor_matr

二 相关系数的显著性水平(Correlation significance levels (p-value))
使用Hmisc 包,不仅可以计算相关性矩阵,还可以计算对应的显著性水平
[1] 安装包 Hmisc (依赖包也会一并安装,lib代表安装包的路径)
>install.packages("Hmisc",lib="E:/Program Files/R/R-3.3.0/library/")
[2] 加载包
>library(Hmisc)
[3] 计算相关性和显著水平 (as.matrix(data) 表示将data转换成矩阵)
>rcorr(as.matrix(data))
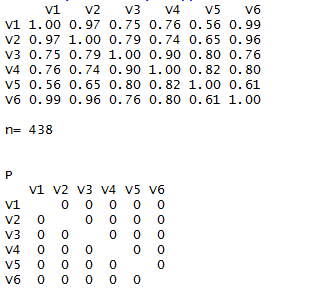
输出说明:
r :第一个矩阵为相关性矩阵
n : 处理数据的总记录数(行数)
P : 显著性水平矩阵(越小说明越显著)
三、可视化相关性分析
- symnum() function
- corrplot() function to plot a correlogram
- scatter plots
- heatmap
[1] 使用 symnum() 函数实现可视化 (cor_matr 是我们上文中cor()函数计算出来的相关性矩阵)
>symnum(cor_matr)

符号说明:在输出的最后一行,说明了符号的意义,例如 [0.9 , 0.95) 这个区间使用 * 表示。其他符号类似
[2] 使用 corrplot() 函数实现可视化(这里需要使用到corrplot包,没有安装的需要安装)
> library(corrplot)
>corrplot(cor_matr, type="upper", order="hclust", tl.col="black", tl.srt=45)
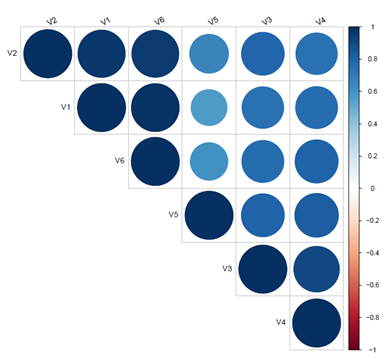
输出说明:用不同颜色表示了相关性的强度,根据最右边的颜色带来看,越接近蓝色说明相关性越高。其中圆形的大小也说明了行惯性的大小。
[3] 使用 PerformanceAnalytics 包进行可视化
>library(PerformanceAnalytics)
>chart.Correlation(data,histogram = TRUE,pch=19)
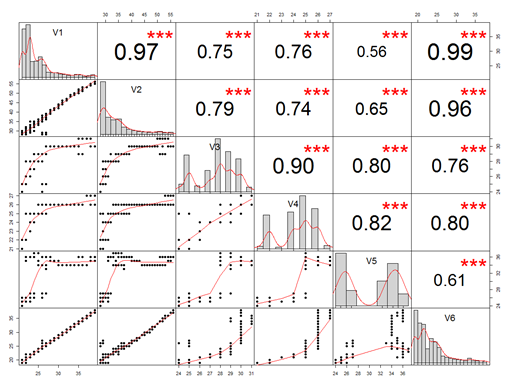
输出说明:
- 对角线给出了变量自身的分布
- 下三角形(对角线的左下方),给出了两个属性的散点图,可以看到第二行第一列的散点图显示出v1和v2具有很高的线性相关性
- 上三小形(对角线的右上方),数字表示连个属性的相关性值,型号表示显著程度(星星越多表明越显著)
[4] heatmap 可视化
>col = colorRampPalette(c("blue", "white", "red"))(20)
>heatmap(x = cor_matr, col = col, symm = TRUE)
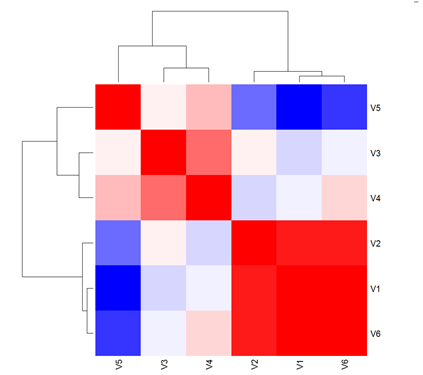
说明:第一行是制作调色板,红色表示相关性最高。第二行参数说明,x: 相关性矩阵(前文已经计算),col: 调色板,symm: 以对称矩阵的形式显示(可以看到画出来的图是中心对称的,不过前提是输入的矩阵是方阵)
参考:
[1] Correlation matrix : A quick start guide to analyze, format and visualize a correlation matrix using R software
[2] Significance of the Correlation Coefficient
http://janda.org/c10/Lectures/topic06/L24-significanceR.htm
[3] Installing R packages
基于R进行相关性分析--转载的更多相关文章
- 使用R进行相关性分析
基于R进行相关性分析 一.相关性矩阵计算: [1] 加载数据: >data = read.csv("231-6057_2016-04-05-ZX_WD_2.csv",head ...
- R_Studio(学生成绩)数据相关性分析
对“Gary.csv”中的成绩数据进行统计量分析 用cor函数来计算相关性,method默认参数是用pearson:并且遇到缺失值,use默认参数everything,结果会是NA 相关性分析 当值r ...
- R语言学习 - 非参数法生存分析--转载
生存分析指根据试验或调查得到的数据对生物或人的生存时间进行分析和推断,研究生存时间和结局与众多影响因素间关系及其程度大小的方法,也称生存率分析或存活率分析.常用于肿瘤等疾病的标志物筛选.疗效及预后的考 ...
- 基于R树索引的点面关系判断以及效率优化统计
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 在之前的博客中,我分别介绍了基于网格的空间索引(http:// ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- 【转】时间序列分析——基于R,王燕
<时间序列分析——基于R>王燕,读书笔记 笔记: 一.检验: 1.平稳性检验: 图检验方法: 时序图检验:该序列有明显的趋势性或周期性,则不是平稳序列 自相关图检验:(ac ...
- 统计学习导论:基于R应用——第二章习题
目前在看统计学习导论:基于R应用,觉得这本书非常适合入门,打算把课后习题全部做一遍,记录在此博客中. 第二章习题 1. (a) 当样本量n非常大,预测变量数p很小时,这样容易欠拟合,所以一个光滑度更高 ...
- Python文章相关性分析---金庸武侠小说分析
百度到<金庸小说全集 14部>全(TXT)作者:金庸 下载下来,然后读取内容with open('names.txt') as f: data = [line.strip() for li ...
- R语言︱情感分析—词典型代码实践(最基础)(一)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:词典型情感分析对词典要求极高,词典中 ...
随机推荐
- win10 问题:你没有权限在此位置中保存文件。请与管理员联系以获得相应权限。
https://jingyan.baidu.com/album/b24f6c8207f09886bee5da4a.html?picindex=2 归根结底就是通过点击文件夹的属性,在安全选项处,修改操 ...
- mathtype使用方法
1:使mathtype中的公式左对齐 双击你的公式,进入mathtype编辑状态.用鼠标选中花括号右边的三行公式,不包括花括号本身,然后点format---matrix---change matrix ...
- mac shell终端编辑命令行快捷键
Ctrl + d 删除一个字符,相当于通常的Delete键(命令行若无所有字符,则相当于exit:处理多行标准输入时也表示eof) Ctrl + h 退格删除一个字符,相当 ...
- [LeetCode] 182. Duplicate Emails_Easy tag: SQL
Write a SQL query to find all duplicate emails in a table named Person. +----+---------+ | Id | Emai ...
- Twitter OA prepare: Two Operations
准备T家OA,网上看的面经 最直接的方法,从target降到1,如果是奇数就减一,偶数就除2 public static void main(String[] args) { int a = shor ...
- php端口号设置和查看
- Python: 去掉字符串开头、结尾或者中间不想要的字符
①Strip()方法用于删除开始或结尾的字符.lstrip()|rstirp()分别从左右执行删除操作.默认情况下会删除空白或者换行符,也可以指定其他字符. ②如果想处理中间的空格,需要求助其他技术 ...
- eclipse启动 报错,错误信息为 return exit code=13
打不开的报错如下图: 解决方法:手工配置Eclipse使用的JDK,在Eclipse的安装目录中找到eclipse.ini文件,增加正确的JDK安装目录,如图 在plugins/ 下一行,增加 -vm ...
- Python2 和Python3 的差异总结
一.基本语法差异 1.1 核心类差异 Python3对Unicode字符的原生支持 Python2中使用 ASCII 码作为默认编码方式导致string有两种类型str和unicode,Python3 ...
- python中的对象(三)
一.python对象 python使用对象模型来存储数据.构造任何类型的值都是一个对象. 所有python对象都拥有三个特性:身份.类型.值 身份:每个对象都有一个唯一的身份标识自己,任何对象的身份可 ...