用caffe进行图片检索
1.图片的处理
输入:将自己的图像转换成caffe需要的格式要求:lmdb 或者 leveldb 格式
这里caffe有自己提供的脚本:create_minst.sh
转换训练图片和验证图片的格式,运行脚本以后生成对应的:***_train_Imdb 文件夹,***_val_Imdb文件夹

在此注意的是 数据的标注:
create_minst.sh里的输入是train.txt 和val.txt (这两个文件分别保存的是:训练train图片的路径以及标签,还有验证val图片的路径和标签 )
格式如下:
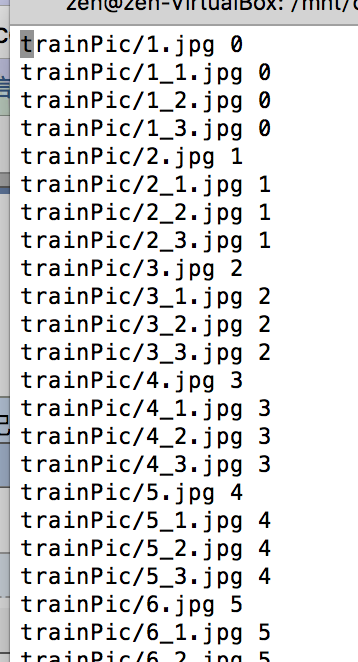
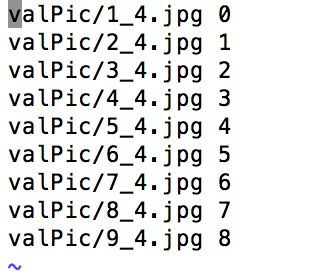
在create_imagenet.sh注意要写好train.txt与val.txt的文件路径
2. 编写配置文件并训练模型
配置文件有两个:1.参数的配置文件solver_**.prototxt(这里可以修改迭代的次数,步率以及其他内容,我只修改了迭代次数)
2.训练网络的配置文件:train_CIFAR10_48.prototxt,test_CIFAR10_48.prototxt
在train_CIFAR10_48.prototxt这里的source 就是我们之前转换好的caffe对应的训练图片的leveldb文件夹,同理test_CIFAR10_48.prototx
在这里需要注意的是meanfile是均值文件,他可以提高你的训练准确率。我这里没有自己生成均值文件,而是用的ilsvrc12库的均值文件~
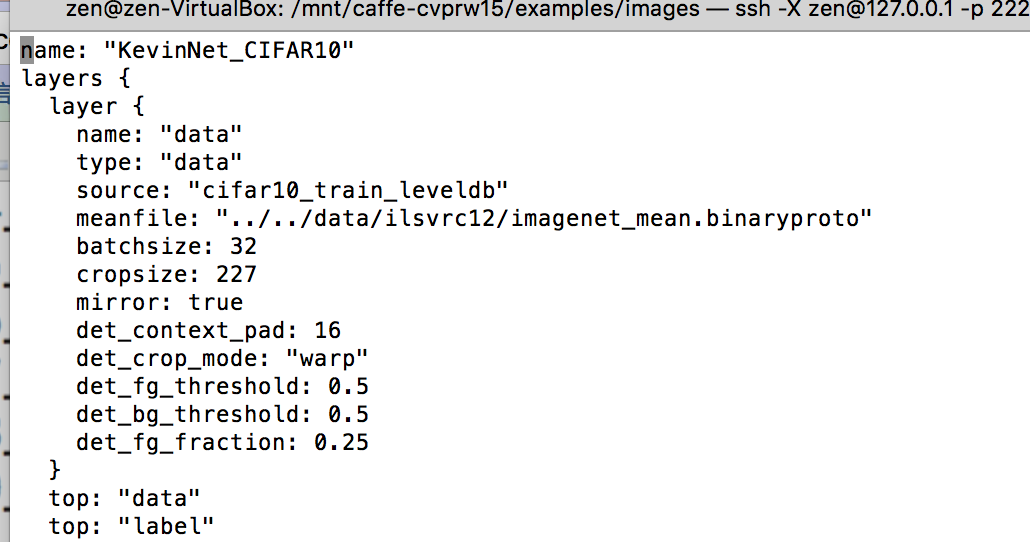
接下来运行训练的脚本:train.sh
脚本内容如下: 这里指定了了参数配置文件solver_CIFAR10_48.prototxt
还有一个值得提一句的是:bvlc_reference_caffenet.caffemodel这是一个与训练模型,需要提前下载好。 gpu -1是用cpu,
../../build/tools/caffe train -solver solver_CIFAR10_48.prototxt -weights ../../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu -1 2>&1 | tee log.txt
运行完以后会生成model文件:例子中我训练500次。

3.利用model来测试
这里有脚本文件:run_*.m
top_K代表匹配出几个相似图片 如果只想要匹配出最最相似的top_k=1
接下来的路径按照自己的路径填写。
强调的是:test_file_list存储的是要进行预测的图片路径,
test_label_list存储的是预测图片的正确答案(因为如果要求准确率,需要这个文件,如果不需要的话就忽略吧注释掉,然后把算精确率的代码注释掉就ok了)
train_file_list就是你的图片集,预测图片在这个图片集里寻找与 它最最匹配的picture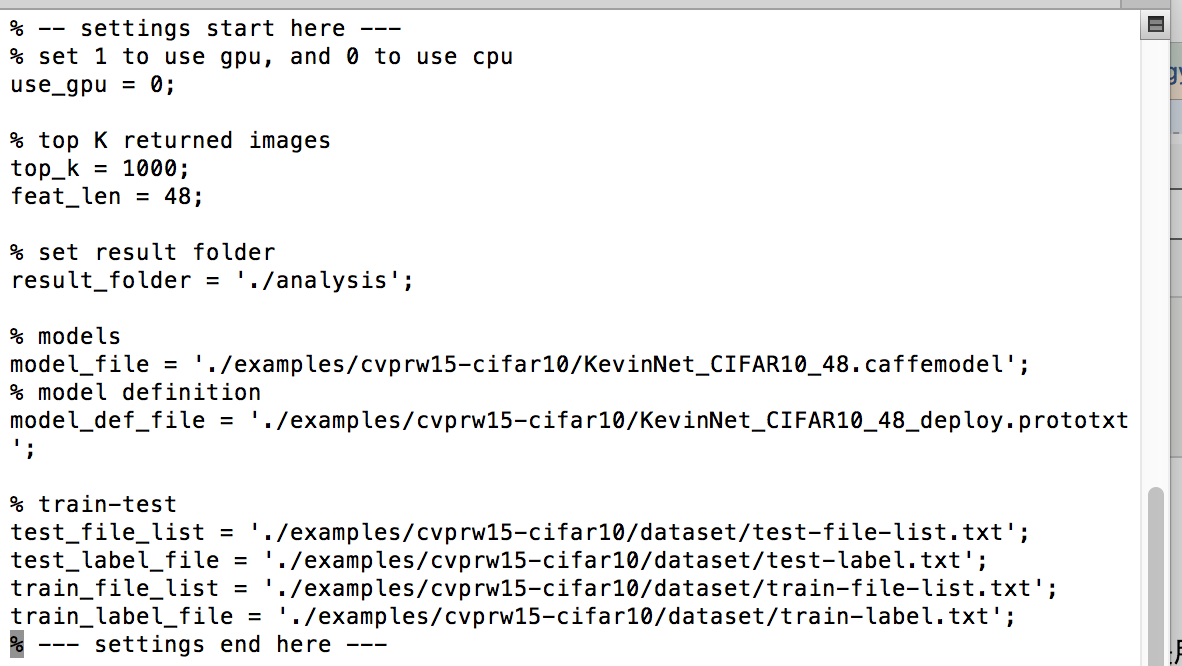
_
-->
用caffe进行图片检索的更多相关文章
- 基于纹理的图片检索及demo(未启动)
基于纹理的图片检索及demo(未启动)
- windows+caffe(二)——图片转换为levedb格式
借鉴于langb2014的 http://blog.csdn.net/langb2014/article/details/50458520 与liukailun09的 http://blog.cs ...
- 总结一下用caffe跑图片数据的研究流程
近期在用caffe玩一些数据集,这些数据集是从淘宝爬下来的图片.主要是想研究一下对女性衣服的分类. 以下是一些详细的操作流程,这里总结一下. 1 爬取数据.写爬虫从淘宝爬取自己须要的数据. 2 数据预 ...
- 基于内容的图片检索CBIR(Content Based Image Retrieval)简介
传统的图像检索过程,先通过人工对图像进行文字标注,再利用关键字来检索图像,这种依据图像描述的字符匹配程度提供检索结果的方法,简称“以字找图”,既耗时又主观多义.基于内容的图像检索客服“以字找图”方式的 ...
- 基于内容的图片检索CBIR简介
原文地址:http://blog.csdn.net/davebobo/article/details/53171311 传统的图像检索过程,先通过人工对图像进行文字标注,再利用关键字来检索图像,这种依 ...
- caffe学习--使用caffe中的imagenet对自己的图片进行分类训练(超级详细版) -----linux
http://blog.csdn.net/u011244794/article/details/51565786 标签: caffeimagenet 2016-06-02 12:57 9385人阅读 ...
- ios 工程图片清理shell
#!/bin/shecho "随意删除@2x图片可能会引起错误 因为ios工程会更加前缀和分辨率自己找到@2x的图片 所以删除@2x图片时要慎重"read -n1 -p &quo ...
- caffe特征层可视化
#参考1:https://blog.csdn.net/sushiqian/article/details/78614133#参考2:https://blog.csdn.net/thy_2014/art ...
- 神经网络:caffe特征可视化的代码例子
caffe特征可视化的代码例子 不少读者看了我前面两篇文章 总结一下用caffe跑图片数据的研究流程 deep learning实践经验总结2--准确率再次提升,到达0.8.再来总结一下 之后.想知道 ...
随机推荐
- vue-preview使用
1.安装 npm i vue-preview -S2.如果使用vue-cli生成的项目,需要修改webpack.base.conf.js文件中的loaders,添加一个loader{ test:/vu ...
- windows使用git时出现:warning: LF will be replaced by CRLF的解决办法
在Windows环境下使用git进行add的时候,会提示如下warning: “warning:LF will be replacee by CRLF”. 这是因为在Windows中的换行符为CRLF ...
- html05
1.js中的对象-内置对象-外部对象-自定义对象 2.常见的内置对象有哪些?-String对象-Number对象-Boolean对象-Array对象-Math对象-Date对象-RegExp正则对象- ...
- Echarts使用及动态加载图表数据 折线图X轴数据动态加载
Echarts简介 echarts,缩写来自Enterprise Charts,商业级数据图表,一个纯JavaScript的图表库,来自百度...我想应该够简洁了 使用Echarts 目前,就官网的文 ...
- toFixed()与toPrecision()
toFixed(n): 返回一个字符串,代表一个以定点表示法表示的数字. n在0~20之间 var g=1.023; var f=g.toFixed(2); f的值为:1.02, typeof ...
- C#:文件、byte[]、Stream相互转换
一.byte[] 和 Stream /// <summary> /// byte[]转换成Stream /// </summary> /// <param name=&q ...
- 通俗理解RxJS(一)
自学 Rx 快有一个周了, 它非常适合处理复杂的异步场景.结合自己所学,决定写系列教程. 我认为, Rx 中强大的地方在于两处 管道思想,通过管道,我们订阅了数据的来源,并在数据源更新时响应 . 强大 ...
- uva11865 朱刘算法+二分
这题说的需要最多花费cost元来搭建一个比赛网络,网络中有n台机器,编号为0 - n-1其中机器0 为服务器,给了n条线有向的和他们的花费以及带宽 计算,使得n台连接在一起,最大化网络中的最小带宽, ...
- 全文搜索引擎ElasticSearch学习记录:mac下安装
最近开发组培训了ElasticSearch,准备开展新项目,我也去凑了下热闹,下面把学习过程记录一下. 一.安装 1.环境需要jdk1.8; 2.下载:http://www.elastic.co/do ...
- appium记录
npm uninstall appium -g npm install -g cnpm --registry=https://registry.npm.taobao.org cnpm install ...