Mysql 优化,慢查询
最近项目上遇到点问题,服务器出现连接超时。上次也是超时,问题定位到mongodb上,那次我修改好了,这次发现应该不是这个的问题了。
初步怀疑是mysql这边出问题了,写的sql没经过压力测试,导致用户量多的时候,出现拥堵。
好,那就来看看mysql方便的慢查询吧,来看看具体的哪些sql查询慢,从这里开始来优化下。
一:开启慢查询
先来看看慢查询日志设置的时间长度:
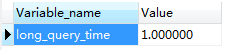
show VARIABLES LIKE 'long%'
返回,long_query_time 指定了慢查询的阈值,即如果执行语句的时间超过该阈值则为慢查询语句,默认值为10秒。这里设置的为1s
慢查询日志开启情况:
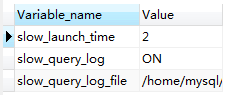
SHOW VARIABLES LIKE 'slow%'
返回:slow_query_log的值为ON为开启慢查询日志,OFF则为关闭慢查询日志。
slow_query_log_file 的值是记录的慢查询日志到文件中(注意:默认名为主机名.log,慢查询日志是否写入指定文件中,需要指定慢查询的输出日志格式为文件,相关命令为:show variables like ‘%log_output%’;去查看输出的格式)
通过以上命令,确定慢查询已经打开了。然后去看慢查询日志就行。
由于这里用的是阿里云的数据库,所以提供了后台可以很方便的查询到日志和下载日志。

这里点击下载即可将慢查询的日志下载下来。
二:分析慢查询日志
1. 截取一段慢查询日志:
# Time: 180918 19:06:21
# User@Host: proxy[proxy] @ [192.168.0.16] Id: 6707197
# Query_time: 1.015429 Lock_time: 0.000116 Rows_sent: 1 Rows_examined: 44438
SET timestamp=1537268781;
select
id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag,
nodisturb_mode, nodisturb_start_time,
nodisturb_end_time, binding_time, device_os_type, app_type, state
from app_mobile_device
where user_id = '78436'
and app_type = 'YGY'
order by binding_time desc;
# User@Host: proxy[proxy] @ [192.168.0.16] Id: 6707236
# Query_time: 1.021662 Lock_time: 0.000083 Rows_sent: 1 Rows_examined: 44438
SET timestamp=1537268781;
select
id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag,
nodisturb_mode, nodisturb_start_time,
nodisturb_end_time, binding_time, device_os_type, app_type, state
from app_mobile_device
where user_id = '14433'
and app_type = 'YGY'
order by binding_time desc;
这里可以看到:
Query_time (慢查询语句的查询时间) 都超过了设置的 1s,
Rows_sent (慢查询返回记录) 这里只返回了 1 条
Rows_examined (慢查询扫描过的行数) 44438 -> 通过这里大概可以看出问题很大
2.现在将这个SQL语句放到数据库去执行,并使用EXPLAIN分析 看下执行计划。
EXPLAIN
select
id, user_id, device_uuid, bd_client_id, bd_user_id, bd_tag,
nodisturb_mode, nodisturb_start_time,
nodisturb_end_time, binding_time, device_os_type, app_type, state
from app_mobile_device
where user_id = '78436'
and app_type = 'YGY'
order by binding_time desc;
查询结果是:

解释下参数:
| SELECT识别符。这是SELECT的查询序列号 | |
| select_type |
SELECT类型,可以为以下任何一种:
|
| table |
输出的行所引用的表 |
| type |
联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:
|
| possible_keys |
指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。 |
| key_len | 显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。 |
| ref | 显示使用哪个列或常数与key一起从表中选择行。 |
| rows | 显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数。 |
| filtered | 显示了通过条件过滤出的行数的百分比估计值。 |
| Extra |
该列包含MySQL解决查询的详细信息
|
这里可以发现:rows 为查询的行数,查询了4w多行,那慢是肯定的了。
因为这里是好几个条件,并且没有使用一个索引,那就只能给添加索引了,
这里给选择添加普通多列索引,因为这个表在最开始设计出问题了,导致有重复的数据,不能设置唯一索引了。
ALTER TABLE app_mobile_device ADD INDEX user_app_type_only ( `user_id` ,`app_type` )
索引设置了,再看下刚的SQL的执行计划。

可以发现rows 的检查行数,很明显的下降了。
到此,慢查询的使用和优化就基本完成了。
Mysql 优化,慢查询的更多相关文章
- MySQL——优化嵌套查询和分页查询
优化嵌套查询 嵌套查询(子查询)可以使用SELECT语句来创建一个单列的查询结果,然后把这个结果作为过滤条件用在另一个查询中.嵌套查询写起来简单,也容易理解.但是,有时候可以被更有效率的连接(JOIN ...
- mysql优化-》查询缓存
使用MySql查询缓存(query_cache_size) 在MySql中查询缓存的原理: 其实是MySql创建了一个临时的空间叫Qcache(这个空间生成在MySql的编译器内存中),这个空间的大小 ...
- MySQL优化COUNT()查询
COUNT()聚合函数,以及如何优化使用了该函数的查询,很可能是最容易被人们误解的知识点之一 COUNT()的作用 COUNT()是一个特殊的函数,有两种非常不同的作用: 统计某个列值的数量 统计行数 ...
- MySQL优化总结-查询总条数
1.COUNT(*)和COUNT(COL) COUNT(*)通常是对主键进行索引扫描,而COUNT(COL)就不一定了,另外前者是统计表中的所有符合的纪录总数,而后者是计算表中所有符合的COL的纪录数 ...
- MySql优化子查询
用子查询语句来影响子查询中产生结果rows的数量和顺序. For example: SELECT * FROM t1 WHERE t1.column1 IN (SELECT column1 FROM ...
- Mysql优化--慢查询日志
Mysql 系列文章主页 =============== 默认没有开启慢查询日志功能.如果不是调优需要的话,一般不建议开启. 查看是否开启慢查询日志: SHOW VARIABLES LIKE '%sl ...
- mysql 优化之查询缓存(mysql8已经废弃这个功能)
对于缓存,一般人想到的是 redis.memcache 这些内存型的缓存. 但是实际上 mysql 也提供了缓存,mysql 里面的缓存是查询缓存,可以把我们查询过的语句缓存下来,下一次查询的时候有可 ...
- mysql优化 慢查询(一)
1.显示慢查询的一些参数的命令:show variables like '%slow%';结果如图
- mysql 优化like查询
1. like %keyword 索引失效,使用全表扫描.但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描. 2. like keyword% 索引有 ...
- MySQL优化、锁
1. MySQL优化-查看执行记录 MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化. 使用ex ...
随机推荐
- 【JQuery】jQuery中的常用方法小结
1.层级选择器 后代选择器 "父元素 后代元素" 比如:$("div p") 选取div元素下所有的p元素 子元素选择器 "父元 ...
- Cal Cat for Mac(猫咪控日历工具)安装
1.软件简介 Cal Cat 是 macOS 系统上一款猫咪控日历工具,可以将系统内置的日历工具美化成猫咪风格的日历,超级可爱的猫咪可是猫咪控的最爱了,喜欢的朋友快快用上吧. 加州猫是一个桌面集 ...
- PreparedStatement的用法及优点
jdbc(java database connectivity,java数据库连接)的api中的主要的四个类之一的java.sql.statement要求开发者付出大量的时间和精力.在使用statem ...
- 打开Word时出现“The setup controller has encountered a problem during install. Please ...”什么意思
解决办法:找到C:\Program Files\Common Files\Microsoft Shared\OFFICE12\Office Setup Controller,将这个文件夹删除或改名,就 ...
- php-fpm进程关闭与重启脚本详解
先来理解一下什么是php-fpm PHP-FPM是一个PHP FastCGI管理器,是只用于PHP的. PHP-FPM其实是PHP源代码的一个补丁,旨在将FastCGI进程管理整合进PHP包中.必须将 ...
- VB的一些项目中常用的通用方法-一般用于验证类
1.VB的一些项目中常用的通用方法: ' 设置校验键盘输入值,数字 Public Function kyd(key As Integer) As Integer Dim mychar mychar = ...
- 使用C#和Thrift来访问Hbase实例
今天试着用C#和Thrift来访问Hbase,主要参考了博客园上的这篇文章.查了Thrift,Hbase的资料,结合博客园的这篇文章,终于搞好了.期间经历了不少弯路,下面我尽量详细的记录下来,免得大家 ...
- django -- 用包来组织数据库模型
默认情况下一个django app的所有模型都保存在一个叫models.py的文件中.这样事实是不方便管理的: 通过包来组织模型是比较方便的. 一.第一步:删除models.py: rm -rf mo ...
- debian linux 下设置开机自启动
懒得写了,一张图简单明了.其实很简单,一开始没有加上nohup有点问题.现在问题已解决.
- wifiphisher 钓鱼工具的使用
wifiphisher 钓鱼工具的使用一.简介 Wifiphisher是一个安全工具,具有安装快速.自动化搭建的优点,利用它搭建起来的网络钓鱼攻击WiFi可以轻松获得密码和其他凭证.与其它(网络钓鱼) ...