SVM的sklearn.svm.SVC实现与类参数
SVC继承了父类BaseSVC
SVC类主要方法:
★__init__() 主要参数:
C: float参数 默认值为1.0
错误项的惩罚系数。C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率降低。相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。对于训练样本带有噪声的情况,一般采用后者,把训练样本集中错误分类的样本作为噪声。
kernel: str参数 默认为‘rbf’
算法中采用的核函数类型,可选参数有:
‘linear’:线性核函数
‘poly’:多项式核函数
‘rbf’:径像核函数/高斯核
‘sigmod’:sigmod核函数
‘precomputed’:核矩阵
具体这些核函数类型,请参考上一篇博客中的核函数。需要说明的是,precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵。核矩阵为如下形式:
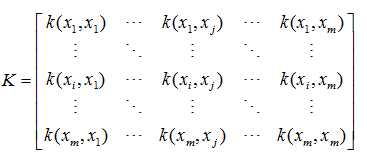
还有一点需要说明,除了上面限定的核函数外,还可以给出自己定义的核函数,其实内部就是用你自己定义的核函数来计算核矩阵。
degree:int型参数 默认为3
这个参数只对多项式核函数有用,是指多项式核函数的阶数n
如果给的核函数参数是其他核函数,则会自动忽略该参数。
gamma:float参数 默认为auto
核函数系数,只对‘rbf’,‘poly’,‘sigmod’有效。
如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features.
coef0:float参数 默认为0.0
核函数中的独立项,只有对‘poly’和‘sigmod’核函数有用,是指其中的参数c
probability:bool参数 默认为False
是否启用概率估计。 这必须在调用fit()之前启用,并且会fit()方法速度变慢。
shrinking:bool参数 默认为True
是否采用启发式收缩方式
tol: float参数 默认为1e^-3
svm停止训练的误差精度
cache_size:float参数 默认为200
指定训练所需要的内存,以MB为单位,默认为200MB。
class_weight:字典类型或者‘balance’字符串。默认为None
给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面参数指出的参数C.
如果给定参数‘balance’,则使用y的值自动调整与输入数据中的类频率成反比的权重。
verbose :bool参数 默认为False
是否启用详细输出。 此设置利用libsvm中的每个进程运行时设置,如果启用,可能无法在多线程上下文中正常工作。一般情况都设为False,不用管它。
max_iter :int参数 默认为-1
最大迭代次数,如果为-1,表示不限制
random_state:int型参数 默认为None
伪随机数发生器的种子,在混洗数据时用于概率估计。
★fit()方法:用于训练SVM,具体参数已经在定义SVC对象的时候给出了,这时候只需要给出数据集X和X对应的标签y即可。
★predict()方法:基于以上的训练,对预测样本T进行类别预测,因此只需要接收一个测试集T,该函数返回一个数组表示个测试样本的类别。
★属性有哪些:
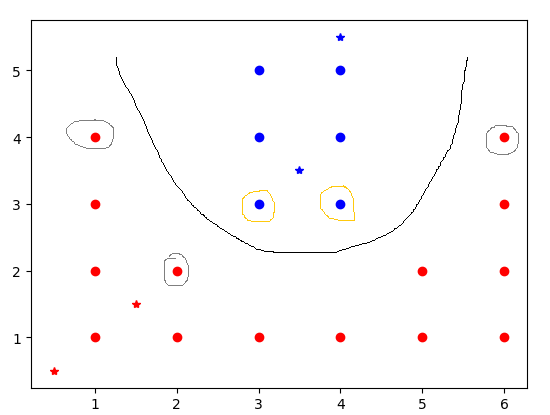
svc.n_support_:各类各有多少个支持向量
svc.support_:各类的支持向量在训练样本中的索引
svc.support_vectors_:各类所有的支持向量
# -*- coding:utf-8 -*-
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
X=np.array([[1,1],[1,2],[1,3],[1,4],[2,1],[2,2],[3,1],[4,1],[5,1],
[5,2],[6,1],[6,2],[6,3],[6,4],[3,3],[3,4],[3,5],[4,3],[4,4],[4,5]])
Y=np.array([1]*14+[-1]*6)
T=np.array([[0.5,0.5],[1.5,1.5],[3.5,3.5],[4,5.5]])
svc=SVC(kernel='poly',degree=2,gamma=1,coef0=0)
svc.fit(X,Y)
pre=svc.predict(T)
print pre
print svc.n_support_
print svc.support_
print svc.support_vectors_
运行结果:
[ 1 1 -1 -1] #预测结果
[2 3] #-1类和+1类分别有2个和3个支持向量
[14 17 3 5 13] #-1类支持向量在元训练集中的索引为14,17,同理-1类支持向量在元训练集中的索引为3,5,13
[[ 3. 3.] #给出各支持向量具体是哪些,前两个是-1类的
[ 4. 3.]
[ 1. 4.] #后3个是+1的支持向量
[ 2. 2.]
[ 6. 4.]]
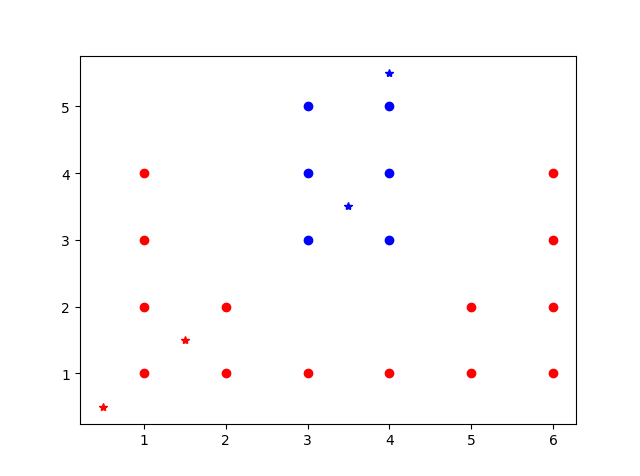
结果如图所示。
#参数的网格扫描
##############################################################################
# Train a SVM classification model print("Fitting the classifier to the training set")
t0 = time()
param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_pca, y_train)
print("done in %0.3fs" % (time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
SVM的sklearn.svm.SVC实现与类参数的更多相关文章
- sklearn.svm.SVC 参数说明
原文地址:sklearn.svm.SVC 参数说明 ============================== 资源: sklearn官网+DOC 库下载GitHub =============== ...
- sklearn.svm.SVC参数说明
摘自:https://blog.csdn.net/szlcw1/article/details/52336824 本身这个函数也是基于libsvm实现的,所以在参数设置上有很多相似的地方.(PS: l ...
- sklearn系列之 sklearn.svm.SVC详解
首先我们应该对SVM的参数有一个详细的认知: sklearn.svm.SVC 参数说明: 本身这个函数也是基于libsvm实现的,所以在参数设置上有很多相似的地方.(PS: libsvm中的二次规划问 ...
- 机器学习之sklearn——SVM
sklearn包对于SVM可输出支持向量,以及其系数和数目: print '支持向量的数目: ', clf.n_support_ print '支持向量的系数: ', clf.dual_coef_ p ...
- SVM的sklearn实现
转载:豆-Metcalf 1)SVM-LinearSVC.ipynb-线性分类SVM,iris数据集分类,正确率100% """ 功能:实现线性分类支持向量机 说明:可以 ...
- sklearn svm基本使用
SVM基本使用 SVM在解决分类问题具有良好的效果,出名的软件包有libsvm(支持多种核函数),liblinear.此外python机器学习库scikit-learn也有svm相关算法,sklear ...
- sklearn.svm.LinearSVC文档学习
https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html#sklearn.svm.LinearSVC 1 ...
- [Example of Sklearn] - SVM usge
reference : http://www.csdn.net/article/2012-12-28/2813275-Support-Vector-Machine SVM是什么? SVM是一种训练机器 ...
- sklearn之SVC
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability= ...
随机推荐
- iOS开发UI之Quartz2D使用(绘制基本图形)
iOS开发UI篇—Quartz2D使用(绘制基本图形) 一.简单说明 图形上下文(Graphics Context):是一个CGContextRef类型的数据 图形上下文的作用:保存绘图信息.绘图状态 ...
- SWIFT模糊效果
首先创建一个模糊效果 let blurEffect = UIBlurEffect(style: UIBlurEffectStyle.Light) 接着创建一个承载模糊效果的视图let blurView ...
- 在vmware中实现Ubuntu与win7(主机)之间同步实现共享文件
作为linux的热衷者和初学者,我们在学习的过程中难免会碰到不少的问题,下面简单的介绍和总结一下,我是如何通过以下两种方法解决在vmware中实现Ubuntu与win7(主机)之间同步实现共享文件的. ...
- squeeze()
一.说明 B = squeeze(A),B与A有相同的元素,但所有只有一行或一列的维度(a singleton dimension)被去除掉了.A singleton dimension的特征是siz ...
- hdu1428 记忆化搜索(BFS预处理最短路径和+DP+DFS)
题意:有一块 n * n 大小的方形区域,要从左上角 (1,1)走到右下角(n,n),每个格子都有通过所需的时间,并且每次所走的下一格到终点的最短时间必须比当前格子走到重点的最短时间短,问一共有多少种 ...
- Tomcat7 catalina.out 日志分割
Tomcat7 catalina.out 日志分割 安装过程如下: 1.下载(最新版本) cronolog-1.6.2.tar.gz 2.解压缩 # tar zxvf cronolog-1. ...
- coffeescript学习
test2.coffeestdin = process.openStdin()stdin.setEncoding 'utf8' stdin.on 'data', (input) -> n ...
- js 各种循环遍历
js 各种循环遍历(表格比较) 遍历方法 能否遍历数组 能否遍历对象 备注 for 能 不能 for in 能(有诸多缺点) 能 为遍历对象而设计的,不适用于遍历数组 forEach 能 不能 bre ...
- 三个php加密解密算法
三个功能强大的php加密解密函数 //加密函数 function lock_url($txt,$key='www.fyunw.com') { $chars = "ABCDEFGHIJKLMN ...
- JVM内存模型(二)
JVM为什么要区分为栈和堆? 栈代表的操作逻辑存储,堆代表的是数据逻辑存储,这样来划分更加清晰: JVM的内存在宏观上面来讲分为私有内存和共享内存:所谓共享内存(堆)寓意就是各个私有的栈(每个线程私有 ...