YOLO V3论文理解
YOLO3主要的改进有:调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax。
1.Darknet-53 network
在论文中虽然有给网络的图,但我还是简单说一下。这个网络主要是由一系列的1x1和3x3的卷积层组成(每个卷积层后都会跟一个BN层和一个LeakyReLU)层,作者说因为网络中有53个convolutional layers,所以叫做Darknet-53(我数了下,作者说的53包括了全连接层但不包括Residual层)。下图就是Darknet-53的结构图,在右侧标注了一些信息方便理解。(卷积的strides默认为(1,1),padding默认为same,当strides为(2,2)时padding为valid)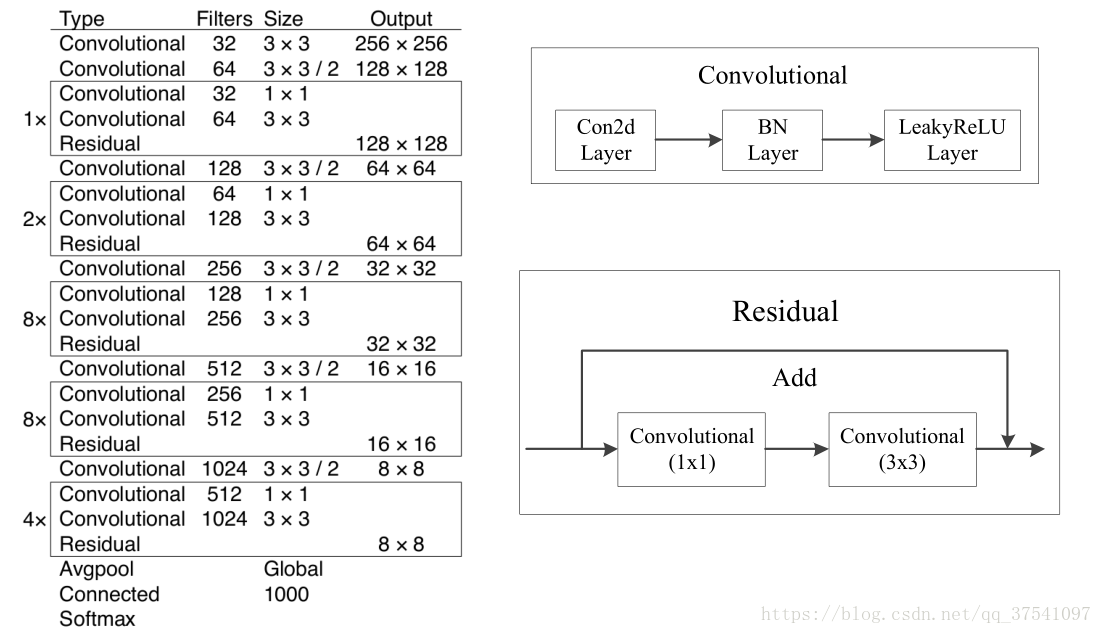
看完上图应该就能自己搭建出Darknet-53的网络结构了,上图是以输入图像256 x 256进行预训练来进行介绍的,常用的尺寸是416 x 416,都是32的倍数。下面我们再来分析下YOLOv3的特征提取器,看看究竟是在哪几层Features上做的预测。

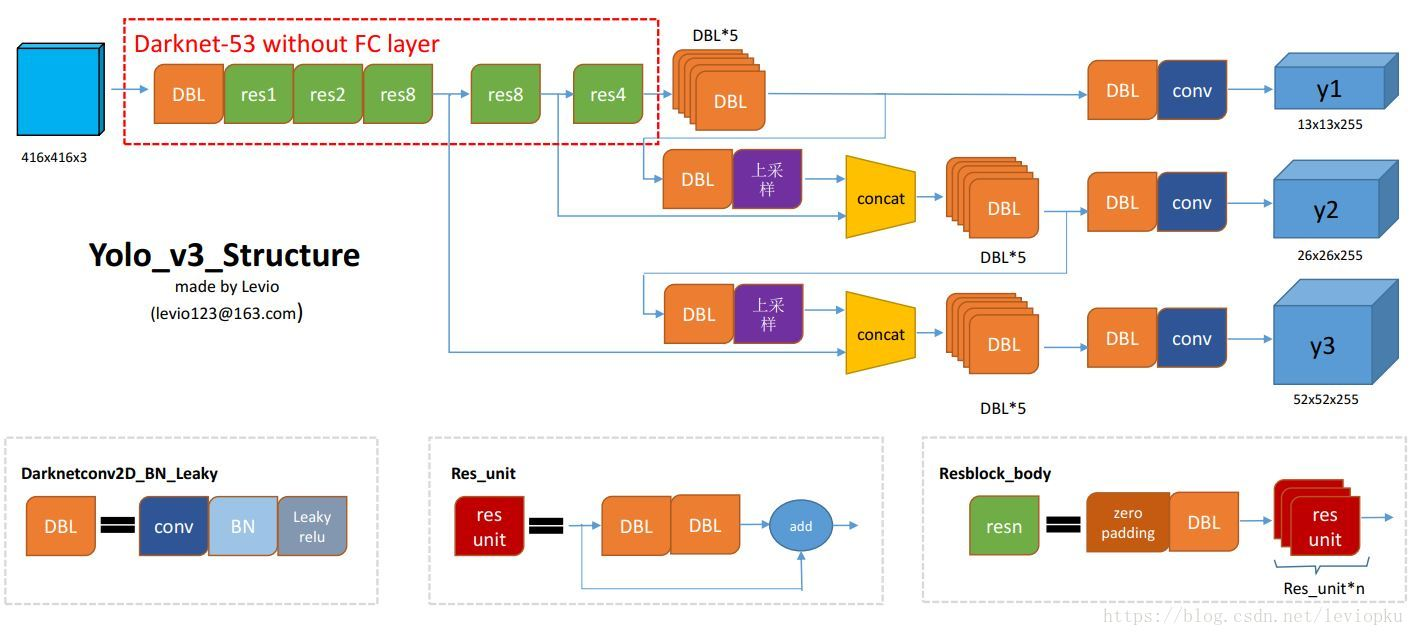
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1/32。输入为416x416,则输出为13x13(416/32=13)。
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。
yolo_v3并没有那么追求速度,而是在保证实时性(fps>60)的基础上追求performance。不过还有一个tiny-darknet作为backbone可以替代darknet-53,在官方代码里用一行代码就可以实现切换backbone。搭用tiny-darknet的yolo,也就是tiny-yolo在轻量和高速两个特点上,显然是state of the art级别。
2.利用多尺度特征进行对象检测
结合上图看,卷积网络在79层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。相比输入图像,这里用于检测的特征图有32倍的下采样。比如输入是416*416的话,这里的特征图就是13*13了。由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的对象。
为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(Concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的对象。
最后,第91层特征图再次上采样,并与第36层特征图融合(Concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的对象。
随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLO2已经开始采用K-means聚类得到先验框的尺寸,YOLO3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。

感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

4.对象分类softmax改成logistic
预测对象类别时不使用softmax,改成使用logistic的输出进行预测。这样能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。
输入映射到输出

不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
我们看一下YOLO3共进行了多少个预测。对于一个416*416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
对比一下,YOLO2采用13*13*5 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。
YOLO V3论文理解的更多相关文章
- YOLO V2论文理解
概述 YOLO(You Only Look Once: Unified, Real-Time Object Detection)从v1版本进化到了v2版本,作者在darknet主页先行一步放出源代码, ...
- YOLO V1论文理解
摘要 作者提出了一种新的物体检测方法YOLO.YOLO之前的物体检测方法主要是通过region proposal产生大量的可能包含待检测物体的 potential bounding box,再用分类器 ...
- Pytorch从0开始实现YOLO V3指南 part1——理解YOLO的工作
本教程翻译自https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/ 视频展示:https://w ...
- 深度学习笔记(十三)YOLO V3 (Tensorflow)
[代码剖析] 推荐阅读! SSD 学习笔记 之前看了一遍 YOLO V3 的论文,写的挺有意思的,尴尬的是,我这鱼的记忆,看完就忘了 于是只能借助于代码,再看一遍细节了. 源码目录总览 tens ...
- 一文看懂YOLO v3
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf论文:YOLOv3: An Incremental Improvement YOLO系列的 ...
- yolo类检测算法解析——yolo v3
每当听到有人问“如何入门计算机视觉”这个问题时,其实我内心是拒绝的,为什么呢?因为我们说的计算机视觉的发展史可谓很长了,它的分支很多,而且理论那是错综复杂交相辉映,就好像数学一样,如何学习数学?这问题 ...
- YOLO系列:YOLO v3解析
本文好多内容转载自 https://blog.csdn.net/leviopku/article/details/82660381 yolo_v3 提供替换backbone.要想性能牛叉,backbo ...
- yolov1, yolo v2 和yolo v3系列
目标检测模型主要分为two-stage和one-stage, one-stage的代表主要是yolo系列和ssd.简单记录下学习yolo系列的笔记. 1 yolo V1 yolo v1是2015年的论 ...
- Yolo V3整体思路流程详解!
结合开源项目tensorflow-yolov3(https://link.zhihu.com/?target=https%3A//github.com/YunYang1994/tensorflow-y ...
随机推荐
- http 同步异步请求
在用户交互模式下,当你改变表单中某个组件的值时, 譬如你填写名字.修改性别.选择爱好的时候,浏览器和服 务器至今没有发生任何交互,只有当你点击submit的时候, 浏览器才会把你的参数,也就是form ...
- STA分析(六) cross talk and noise
在深亚微米技术(deep submicron)中,关于crosstalk和noise对design的signal integrate的影响越来越大.主要表现在glitch和对delay的影响. 1)m ...
- python 爬取文章
这里我们利用强大的python爬虫来爬取一篇文章.仅仅做一个示范,更高级的用法还要大家自己实践. 好了,这里就不啰嗦了,找到一篇文章的url地址:http://www.duanwenxue.com/a ...
- 混合使用ForkJoin+Actor+Future实现一千万个不重复整数的排序(Scala示例)
目标 实现一千万个不重复整数的排序,可以一次性加载到 2G 的内存里. 本文适合于想要了解新语言 Scala 并发异步编程框架 Akka, Future 的筒鞋. 读完本文后,将了解如何综 ...
- JSP禁用缓存常用方法
内容主要转自:http://www.cnblogs.com/linjiqin/archive/2011/07/20/2111627.html jsp页面禁止缓存设置 1.客户端缓存要在<head ...
- Adobe Illustrator CS6 界面文字按钮太小,高分屏win10PS/AI等软件界面字太小解决方法
Adobe Illustrator CS6 界面文字按钮太小,高分屏win10PS/AI等软件界面字太小解决方法 Adobe App Scaling on High DPI Displays (FIX ...
- linux测试带宽命令,Linux服务器网络带宽测试iperf
linux测试带宽命令,Linux服务器网络带宽测试iperf必须先运行iperf serveriperf -s -i 2客户端iperf -c 服务端IP地址 iperf原理解析 iperf工具可以 ...
- MockWebServer--环境
MockWebServer是一个可脚本化的用于测试HTTP客户端的Web服务器.主要用于测试你的应用在进行HTTP.HTTPS请求时是否按照预期的行为动作.使用该工具,你可以验证应用的请求是否符合预期 ...
- [省选模拟]Rhyme
考的时候脑子各种短路,用个SAM瞎搞了半天没搞出来,最后中午火急火燎的打了个SPFA才混了点分. 其实这个可以把每个模式串长度为$K-1$的字符串看作一个状态,这个用字符串Hash实现,然后我们发现这 ...
- SPOJ Prime or Not - 快速乘 - 快速幂
Given the number, you are to answer the question: "Is it prime?" Solutions to this problem ...