基于hystrix的线程池隔离
hystrix进行资源隔离,其实是提供了一个抽象,叫做command,就是说,你如果要把对某一个依赖服务的所有调用请求,全部隔离在同一份资源池内
对这个依赖服务的所有调用请求,全部走这个资源池内的资源,不会去用其他的资源了,这个就叫做资源隔离
hystrix最最基本的资源隔离的技术,线程池隔离技术
对某一个依赖服务,商品服务,所有的调用请求,全部隔离到一个线程池内,对商品服务的每次调用请求都封装在一个command里面
每个command(每次服务调用请求)都是使用线程池内的一个线程去执行的
所以哪怕是对这个依赖服务,商品服务,现在同时发起的调用量已经到了1000了,但是线程池内就10个线程,最多就只会用这10个线程去执行
不会说,对商品服务的请求,因为接口调用延迟,将tomcat内部所有的线程资源全部耗尽,不会出现了
1.pox
<dependency>
<groupId>com.netflix.hystrix</groupId>
<artifactId>hystrix-core</artifactId>
<version>1.5.12</version>
</dependency>
import rx.Observable;
import rx.Subscriber;
import rx.schedulers.Schedulers; import com.alibaba.fastjson.JSONObject;
import com.netflix.hystrix.HystrixCommandGroupKey;
import com.netflix.hystrix.HystrixObservableCommand;
import com.roncoo.eshop.cache.ha.http.HttpClientUtils;
import com.roncoo.eshop.cache.ha.model.ProductInfo; public class GetProductInfosCommand extends HystrixObservableCommand<ProductInfo> {
private String[] productIds;
public GetProductInfosCommand(String[] productIds) {
super(HystrixCommandGroupKey.Factory.asKey("GetProductInfoGroup"));
this.productIds = productIds;
} @Override
protected Observable<ProductInfo> construct() {
return Observable.create(new Observable.OnSubscribe<ProductInfo>() { public void call(Subscriber<? super ProductInfo> observer) {
try {
for(String productId : productIds) {
String url = "http://127.0.0.1:8082/getProductInfo?productId=" + productId;
String response = HttpClientUtils.sendGetRequest(url);
ProductInfo productInfo = JSONObject.parseObject(response, ProductInfo.class);
observer.onNext(productInfo);
}
observer.onCompleted();
} catch (Exception e) {
observer.onError(e);
}
} }).subscribeOn(Schedulers.io());
} }
import com.alibaba.fastjson.JSONObject;
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey; import com.roncoo.eshop.cache.ha.http.HttpClientUtils;
import com.roncoo.eshop.cache.ha.model.ProductInfo; public class GetProductInfoCommand extends HystrixCommand<ProductInfo> { private Long productId; public GetProductInfoCommand(Long productId) {
super(HystrixCommandGroupKey.Factory.asKey("GetProductInfoGroup"));
this.productId = productId;
} @Override
protected ProductInfo run() throws Exception {
String url = "http://127.0.0.1:8082/getProductInfo?productId=" + productId;
String response = HttpClientUtils.sendGetRequest(url);
return JSONObject.parseObject(response, ProductInfo.class);
} }
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody; import rx.Observable;
import rx.Observer; import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixObservableCommand;
import com.roncoo.eshop.cache.ha.http.HttpClientUtils;
import com.roncoo.eshop.cache.ha.hystrix.command.GetProductInfoCommand;
import com.roncoo.eshop.cache.ha.hystrix.command.GetProductInfosCommand;
import com.roncoo.eshop.cache.ha.model.ProductInfo; @Controller
public class CacheController {
@RequestMapping("/change/product")
@ResponseBody
public String changeProduct(Long productId) {
// 拿到一个商品id
// 调用商品服务的接口,获取商品id对应的商品的最新数据
// 用HttpClient去调用商品服务的http接口
String url = "http://127.0.0.1:8082/getProductInfo?productId=" + productId;
String response = HttpClientUtils.sendGetRequest(url); // Future<ProductInfo> future = getProductInfoCommand.queue();
// try {
// Thread.sleep(1000);
// System.out.println(future.get());
// } catch (Exception e) {
// e.printStackTrace();
// }
System.out.println(response); return "success";
} /**
* nginx开始,各级缓存都失效了,nginx发送很多的请求直接到缓存服务要求拉取最原始的数据
*
* @param productId
* @return
*/
@RequestMapping("/getProductInfo")
@ResponseBody
public String getProductInfo(Long productId) {
// 拿到一个商品id
// 调用商品服务的接口,获取商品id对应的商品的最新数据
// 用HttpClient去调用商品服务的http接口
HystrixCommand<ProductInfo> getProductInfoCommand = new GetProductInfoCommand(productId);
ProductInfo productInfo = getProductInfoCommand.execute();
System.out.println(productInfo);
return "success";
} /**
* 一次性批量查询多条商品数据的请求
*/
@RequestMapping("/getProductInfos")
@ResponseBody
public String getProductInfos(String productIds) {
HystrixObservableCommand<ProductInfo> getProductInfosCommand =
new GetProductInfosCommand(productIds.split(","));
Observable<ProductInfo> observable = getProductInfosCommand.observe(); // observable = getProductInfosCommand.toObservable(); // 还没有执行 observable.subscribe(new Observer<ProductInfo>() { // 等到调用subscribe然后才会执行 public void onCompleted() {
System.out.println("获取完了所有的商品数据");
} public void onError(Throwable e) {
e.printStackTrace();
} public void onNext(ProductInfo productInfo) {
System.out.println(productInfo);
} });
return "success";
}
}
command的四种调用方式
同步:new CommandHelloWorld("World").execute(),new ObservableCommandHelloWorld("World").toBlocking().toFuture().get()
如果你认为observable command只会返回一条数据,那么可以调用上面的模式,去同步执行,返回一条数据
异步:new CommandHelloWorld("World").queue(),new ObservableCommandHelloWorld("World").toBlocking().toFuture()
对command调用queue(),仅仅将command放入线程池的一个等待队列,就立即返回,拿到一个Future对象,后面可以做一些其他的事情,然后过一段时间对future调用get()方法获取数据。
1.线程池隔离技术与信号量隔离技术的区别
hystrix里面,核心的一项功能,其实就是所谓的资源隔离,要解决的最最核心的问题,就是将多个依赖服务的调用分别隔离到各自自己的资源池内
避免说对某一个依赖服务的调用,因为依赖服务的接口调用的延迟或者失败,导致服务所有的线程资源全部耗费在这个服务的接口调用上
一旦说某个服务的线程资源全部耗尽的话,可能就导致服务就会崩溃,甚至说这种故障会不断蔓延
hystrix,资源隔离,两种技术,线程池的资源隔离,信号量的资源隔离
信号量,semaphore
信号量:适合,你的访问不是对外部依赖的访问,而是对内部的一些比较复杂的业务逻辑的访问,但是像这种访问,系统内部的代码,其实不涉及任何的网络请求,
那么只要做信号量的普通限流就可以了,因为不需要去捕获timeout类似的问题,算法+数据结构的效率不是太高,
并发量突然太高,因为这里稍微耗时一些,导致很多线程卡在这里的话,不太好,
所以进行一个基本的资源隔离和访问,避免内部复杂的低效率的代码,导致大量的线程被卡住。

一般我们在获取到商品数据之后,都要去获取商品是属于哪个地理位置,省,市,卖家的,可能在自己的纯内存中,比如就一个Map去获取
对于这种直接访问本地内存的逻辑,比较适合用信号量做一下简单的隔离
优点在于,不用自己管理线程池,不用care timeout超时了,信号量做隔离的话,性能会相对来说高一些。
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey;
import com.netflix.hystrix.HystrixCommandProperties;
import com.netflix.hystrix.HystrixCommandProperties.ExecutionIsolationStrategy;
import com.roncoo.eshop.cache.ha.local.LocationCache; public class GetCityNameCommand extends HystrixCommand<String> {
private Long cityId;
public GetCityNameCommand(Long cityId){
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GetCityNameGroup"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.SEMAPHORE)));
this.cityId = cityId;
}
@Override
protected String run() throws Exception {
return LocationCache.getCityName(cityId);
}
}
execution.isolation.strategy:
指定了HystrixCommand.run()的资源隔离策略,THREAD或者SEMAPHORE,一种是基于线程池,一种是信号量
线程池机制,每个command运行在一个线程中,限流是通过线程池的大小来控制的
信号量机制,command是运行在调用线程中,但是通过信号量的容量来进行限流
如何在线程池和信号量之间做选择?
默认的策略就是线程池
而使用信号量的场景,通常是针对超大并发量的场景下,每个服务实例每秒都几百的QPS,那么此时你用线程池的话,线程一般不会太多,
可能撑不住那么高的并发,如果要撑住,可能要耗费大量的线程资源,那么就是用信号量,来进行限流保护
一般用信号量常见于那种基于纯内存的一些业务逻辑服务,而不涉及到任何网络访问请求
netflix有100+的command运行在40+的线程池中,只有少数command是不运行在线程池中的,就是从纯内存中获取一些元数据,或者是对多个command包装起来的facacde command,是用信号量限流的.
// to use thread isolation
HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.THREAD)
// to use semaphore isolation
HystrixCommandProperties.Setter()
.withExecutionIsolationStrategy(ExecutionIsolationStrategy.SEMAPHORE)
2、command名称和command组
每个command,都可以设置一个自己的名称,同时可以设置一个自己的组.
command group,是一个非常重要的概念,默认情况下,因为就是通过command group来定义一个线程池的,而且还会通过command group来聚合一些监控和报警信息
同一个command group中的请求,都会进入同一个线程池中
3、command线程池
threadpool key代表了一个HystrixThreadPool,用来进行统一监控,统计,缓存
默认的threadpool key就是command group名称
每个command都会跟它的threadpool key对应的thread pool绑定在一起
如果不想直接用command group,也可以手动设置thread pool name
public CommandHelloWorld(String name) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("HelloWorld"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("HelloWorldPool")));
this.name = name;
}
command threadpool -> command group -> command key
command key,代表了一类command,一般来说,代表了底层的依赖服务的一个接口
command group,代表了某一个底层的依赖服务,合理,一个依赖服务可能会暴露出来多个接口,每个接口就是一个command key
command group,在逻辑上去组织起来一堆command key的调用,统计信息,成功次数,timeout超时次数,失败次数,可以看到某一个服务整体的一些访问情况
command group,一般来说,推荐是根据一个服务去划分出一个线程池,command key默认都是属于同一个线程池的
command group,对应了一个服务,但是这个服务暴露出来的几个接口,访问量很不一样,差异非常之大
你可能就希望在这个服务command group内部,包含的对应多个接口的command key,做一些细粒度的资源隔离
对同一个服务的不同接口,都使用不同的线程池.
逻辑上来说,多个command key属于一个command group,在做统计的时候,会放在一起统计
每个command key有自己的线程池,每个接口有自己的线程池,去做资源隔离和限流
但是对于thread pool资源隔离来说,可能是希望能够拆分的更加一致一些,比如在一个功能模块内,对不同的请求可以使用不同的thread pool
command group一般来说,可以是对应一个服务,多个command key对应这个服务的多个接口,多个接口的调用共享同一个线程池
如果说你的command key,要用自己的线程池,可以定义自己的threadpool key.
4、coreSize
设置线程池的大小,默认是10
HystrixThreadPoolProperties.Setter()
.withCoreSize(int value)
一般来说,用这个默认的10个线程大小就够了
5、queueSizeRejectionThreshold
控制queue满后reject的threshold,因为maxQueueSize不允许热修改,因此提供这个参数可以热修改,控制队列的最大大小
HystrixCommand在提交到线程池之前,其实会先进入一个队列中,这个队列满了之后,才会reject
默认值是5
HystrixThreadPoolProperties.Setter()
.withQueueSizeRejectionThreshold(int value)
6、execution.isolation.semaphore.maxConcurrentRequests
设置使用SEMAPHORE隔离策略的时候,允许访问的最大并发量,超过这个最大并发量,请求直接被reject
这个并发量的设置,跟线程池大小的设置,应该是类似的,但是基于信号量的话,性能会好很多,而且hystrix框架本身的开销会小很多
默认值是10,设置的小一些,否则因为信号量是基于调用线程去执行command的,而且不能从timeout中抽离,因此一旦设置的太大,而且有延时发生,可能瞬间导致tomcat本身的线程资源本占满
HystrixCommandProperties.Setter()
.withExecutionIsolationSemaphoreMaxConcurrentRequests(int value)
创建command,执行这个command,配置这个command对应的group和线程池,以及线程池/信号量的容量和大小
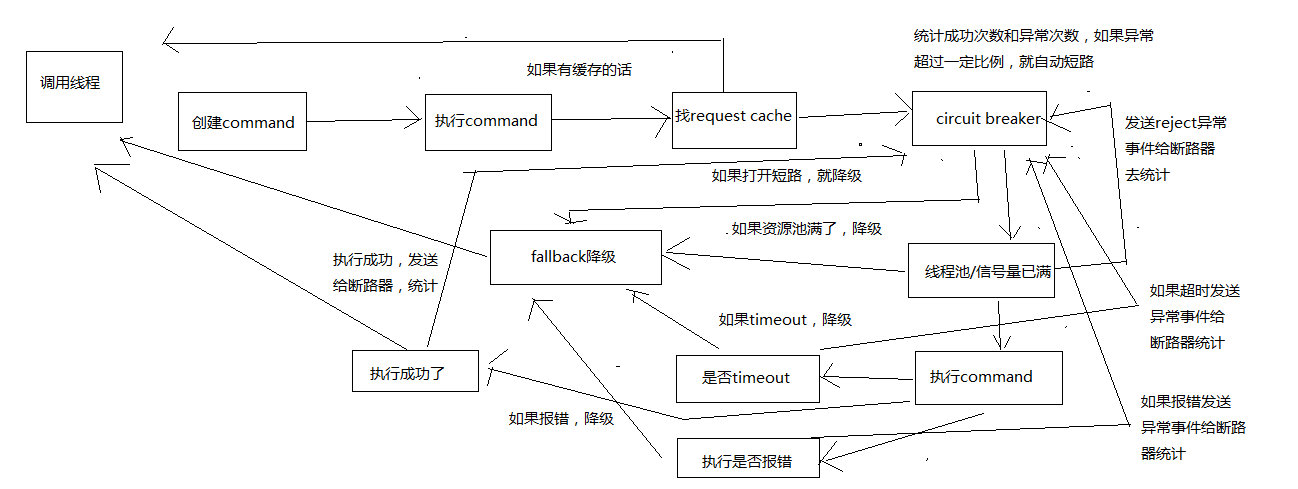
画图分析整个8大步骤的流程,然后再对每个步骤进行细致的讲解
1、构建一个HystrixCommand或者HystrixObservableCommand
一个HystrixCommand或一个HystrixObservableCommand对象,代表了对某个依赖服务发起的一次请求或者调用
构造的时候,可以在构造函数中传入任何需要的参数
HystrixCommand主要用于仅仅会返回一个结果的调用
HystrixObservableCommand主要用于可能会返回多条结果的调用
HystrixCommand command = new HystrixCommand(arg1, arg2);
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
2、调用command的执行方法
执行Command就可以发起一次对依赖服务的调用
要执行Command,需要在4个方法中选择其中的一个:execute(),queue(),observe(),toObservable()
其中execute()和queue()仅仅对HystrixCommand适用
execute():调用后直接block住,属于同步调用,直到依赖服务返回单条结果,或者抛出异常
queue():返回一个Future,属于异步调用,后面可以通过Future获取单条结果
observe():订阅一个Observable对象,Observable代表的是依赖服务返回的结果,获取到一个那个代表结果的Observable对象的拷贝对象
toObservable():返回一个Observable对象,如果我们订阅这个对象,就会执行command并且获取返回结果
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe();
Observable<K> ocValue = command.toObservable();
execute()实际上会调用queue().get().queue(),接着会调用toObservable().toBlocking().toFuture()
也就是说,无论是哪种执行command的方式,最终都是依赖toObservable()去执行的
3、检查是否开启缓存
如果这个command开启了请求缓存,request cache,而且这个调用的结果在缓存中存在,那么直接从缓存中返回结果
4、检查是否开启了短路器
检查这个command对应的依赖服务是否开启了短路器
如果断路器被打开了,那么hystrix就不会执行这个command,而是直接去执行fallback降级机制
5、检查线程池/队列/semaphore是否已经满了
如果command对应的线程池/队列/semaphore已经满了,那么也不会执行command,而是直接去调用fallback降级机制
6、执行command
调用HystrixObservableCommand.construct()或HystrixCommand.run()来实际执行这个command
HystrixCommand.run()是返回一个单条结果,或者抛出一个异常
HystrixObservableCommand.construct()是返回一个Observable对象,可以获取多条结果
如果HystrixCommand.run()或HystrixObservableCommand.construct()的执行,超过了timeout时长的话,那么command所在的线程就会抛出一个TimeoutException
如果timeout了,也会去执行fallback降级机制,而且就不会管run()或construct()返回的值了
这里要注意的一点是,我们是不可能终止掉一个调用严重延迟的依赖服务的线程的,只能说给你抛出来一个TimeoutException,但是还是可能会因为严重延迟的调用线程占满整个线程池的
即使这个时候新来的流量都被限流了。。。
如果没有timeout的话,那么就会拿到一些调用依赖服务获取到的结果,然后hystrix会做一些logging记录和metric统计
7、短路健康检查
Hystrix会将每一个依赖服务的调用成功,失败,拒绝,超时,等事件,都会发送给circuit breaker断路器
短路器就会对调用成功/失败/拒绝/超时等事件的次数进行统计
短路器会根据这些统计次数来决定,是否要进行短路,如果打开了短路器,那么在一段时间内就会直接短路,然后如果在之后第一次检查发现调用成功了,就关闭断路器
8、调用fallback降级机制
在以下几种情况中,hystrix会调用fallback降级机制:run()或construct()抛出一个异常,短路器打开,线程池/队列/semaphore满了,command执行超时了
一般在降级机制中,都建议给出一些默认的返回值,比如静态的一些代码逻辑,或者从内存中的缓存中提取一些数据,尽量在这里不要再进行网络请求了
即使在降级中,一定要进行网络调用,也应该将那个调用放在一个HystrixCommand中,进行隔离
在HystrixCommand中,上线getFallback()方法,可以提供降级机制
在HystirxObservableCommand中,实现一个resumeWithFallback()方法,返回一个Observable对象,可以提供降级结果
如果fallback返回了结果,那么hystrix就会返回这个结果
对于HystrixCommand,会返回一个Observable对象,其中会发返回对应的结果
对于HystrixObservableCommand,会返回一个原始的Observable对象
如果没有实现fallback,或者是fallback抛出了异常,Hystrix会返回一个Observable,但是不会返回任何数据
不同的command执行方式,其fallback为空或者异常时的返回结果不同
对于execute(),直接抛出异常
对于queue(),返回一个Future,调用get()时抛出异常
对于observe(),返回一个Observable对象,但是调用subscribe()方法订阅它时,理解抛出调用者的onError方法
对于toObservable(),返回一个Observable对象,但是调用subscribe()方法订阅它时,理解抛出调用者的onError方法
9、不同的执行方式
execute(),获取一个Future.get(),然后拿到单个结果
queue(),返回一个Future
observer(),立即订阅Observable,然后启动8大执行步骤,返回一个拷贝的Observable,订阅时理解回调给你结果
toObservable(),返回一个原始的Observable,必须手动订阅才会去执行8大步骤
基于hystrix的线程池隔离的更多相关文章
- Hystrix入门与分析(二):依赖隔离之线程池隔离
1.依赖隔离概述 依赖隔离是Hystrix的核心目的.依赖隔离其实就是资源隔离,把对依赖使用的资源隔离起来,统一控制和调度.那为什么需要把资源隔离起来呢?主要有以下几点: 1.合理分配资源,把给资源分 ...
- hystrix线程池隔离的原理与验证
引子 幸福很简单: 今天项目半年规划被通过,终于可以早点下班.先坐公交,全程开着灯,买了了几天的书竟然有时间看了.半小时后,公交到站,换乘大巴车.车还等着上人的功夫,有昏暗的灯光,可以继续看会儿书.过 ...
- 开源项目SMSS开发指南(二)——基于libevent的线程池
libevent是一套轻量级的网络库,基于事件驱动开发.能够实现多线程的多路复用和注册事件响应.本文将介绍libevent的基本功能以及如何利用libevent开发一个线程池. 一. 使用指南 监听服 ...
- spring boot:使用多个线程池实现实现任务的线程池隔离(spring boot 2.3.2)
一,为什么要使用多个线程池? 使用多个线程池,把相同的任务放到同一个线程池中,可以起到隔离的作用,避免有线程出错时影响到其他线程池,例如只有一个线程池时,有两种任务,下单,处理图片,如果线程池被处理图 ...
- 基于linux与线程池实现文件管理
项目要求 1.基本 用线程池实现一个大文件夹的拷贝,大文件夹嵌套很多小文件:实现复制到指定文件夹的全部文件夹. 2.扩充功能 显示进度条:拷贝耗时统计:类似linux的tree,不能直接用system ...
- 基于C++11线程池
1.包装线程对象 class task : public std::tr1::enable_shared_from_this<task> { public: task():exit_(fa ...
- Hystrix线程隔离技术解析-线程池(转)
认识Hystrix Hystrix是Netflix开源的一款容错框架,包含常用的容错方法:线程隔离.信号量隔离.降级策略.熔断技术. 在高并发访问下,系统所依赖的服务的稳定性对系统的影响非常大,依赖有 ...
- 危险的Hystrix线程池
本文介绍Hystrix线程池的工作原理和参数配置,指出存在的问题并提供规避方案,阅读本文需要对Hystrix有一定的了解. 文本讨论的内容,基于hystrix 1.5.18: <dependen ...
- SpringCloud Hystrix熔断之线程池
服务熔断 雪崩效应:是一种因服务提供者的不可用导致服务调用者的不可用,并导致服务雪崩的过程. 服务熔断:当服务提供者无法调用时,会通过断路器向调用方直接返回一个错误响应,而不是长时间的等待,避免服务雪 ...
随机推荐
- nginx 日志之 access_log
web服务器的访问日志是非常重要的,我们可以通过访问日志来分析用户的访问情况, 也可以通过访问日志发现一些异常访问,比如cc攻击. 格式: access_log /path/to/logfile fo ...
- Java Array二维数组使用
二维数组:元素为一维数组的数组 package myArray.arrayarray; /* *二维数组:元素为一维数组的数组 * * 定义格式: * A:数组类型[][] 数组名: (推荐用法) * ...
- 区间dp专题练习
区间dp专题练习 题意 1.Equal Sum Partitions ? 这嘛东西,\(n^2\)自己写去 \[\ \] \[\ \] 2.You Are the One 感觉自己智力被吊打 \(dp ...
- 定时任务、js定时任务
intervalID =setInterval("getIsCookie()",1000); //开始任务 clearInterval(intervalID);//停止任务
- Java 字符集编码
一.字符编码实例1.NioTest13_In.txt文件内容拷贝到NioTest13_Out.txt文件中 public class NioTest13 { public static void ma ...
- git 执行 git reset HEAD 报 Unstaged changes after reset
Unstaged changes after reset 解决的办法如下2中办法: 1. git add . git reset --hard 2. git stash git stash dro ...
- (转)LoadRunner之录制你的第一个脚本
LoadRunner安装完成之后,肯定就迫不及待的想要上手试用了.下面就是讲一下LR脚本录制的流程和基本的设置. 1.先放一张脚本录制以及运行的流程图 2.脚本录制步骤 1)以管理员身份打开LR软件, ...
- [转]import xxx from 和 import {xxx} from的区别
原文地址:https://www.cnblogs.com/Abner5/p/7256043.html 1.vue import FunName from ‘../xxx’ 1.js export de ...
- 运维笔记--Docker文件占用磁盘空间异常处理
场景描述: 1. 服务器运行一段时间后,发现系统盘磁盘空间在不断增加,一开始的时候,不会影响系统,随着时间的推移,磁盘空间在不断增加,直到有一天你会发现系统盘剩余空间即将使用完,值得庆幸的是,如果您使 ...
- EV录屏 --- 免费无水印,集视频录制与直播功能于一身的桌面录屏软件, 支持录屏涂鸦、实时按键显示、视频体积压缩等实用功能
https://www.ieway.cn/index.html 免费无水印,集视频录制与直播功能于一身的桌面录屏软件,支持录屏涂鸦.实时按键显示.视频体积压缩等实用功能 EVCapture 3.9.7 ...