kafka学习笔记(一)——概述
1、kafka是什么?
官方说明是:
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
提到了两个概念:
- 发布/订阅模式
- 消息队列
下边来理解一下这两个名词。
2、消息队列(Message Queue)
2.1 什么是消息队列?
两个单词简写一下就是MQ,抛开消息不看,那就只剩队列了。
队列:是一种先进先出(FIFO)的数据结构。数据结构课程中有涉及这个概念~
消息队列可以简单理解为:把要传输的数据放在队列中。
我们把放消息的叫做:生产者;取消息的叫做:消费者。
2.2、为什么使用消息队列?
1)解耦
例如:我们的系统中有一个A模块,B、C模块需要使用A模块提供的功能。如果A把提供的服务写入到消息队列中(生产者),B、C需要的时候就去队列里获取这个服务(消费者)。这样,三者的代码互相不浸入,完美实现了解耦合的需求。如果再来一个D模块,也要使用A的服务,它也只需去消息队列中取就ok了。如果B\C\D不需要A的服务了,直接不取消息就行了,减少了频繁改动代码的恶习。
总结一下就是:
A只负责提供服务,谁来消费,关我毛事?~
谁需要服务,谁就自己来拿,不需要就不拿。
2)异步
以一个注册的例子来理解同步与异步的差异之处
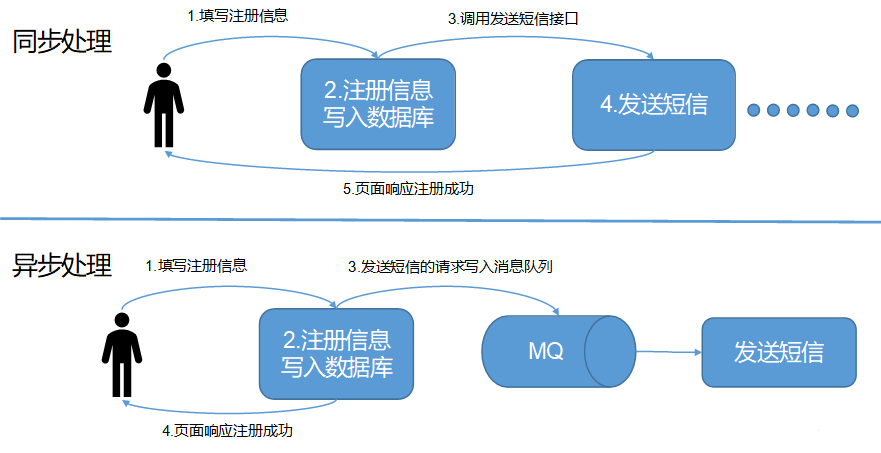
- 同步处理:走完整条业务代码线,再返回给用户注册成功的消息
- 异步处理:将用户的注册请求放入消息队列后就返回注册成功的消息,将写入数据库等等其它的业务将由后续代码接着执行
举个栗子:修手表,边修边等,这是同步模式;修好来取,这是异步模式。
节省了用户等待的时间,换句话就是减少了系统的响应时间~
3)削峰/限流
这两个东西讲的是一个概念,可类比于在计算机网络课程中学习的数据链路层的流量控制功能。
例如:
系统的访问量特变大,假设每秒有3000个请求,而后台有两个服务器在同时工作,他们的工作能力是每秒处理1000个请求。那么可想而知,充分利用机器的情况下,也会出现剩余1000个请求无法处理的问题。
这1000个请求难道要丢弃掉?当然不阔以辽~ 这时候,消息队列又可以排上用场了:我们将收到的3000个请求全部放进消息队列,后边两台服务器来队列中取数据进行处理,也就缓解了整个系统的鸭梨~
3、消息队列的两种模式
1)点对点模式
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
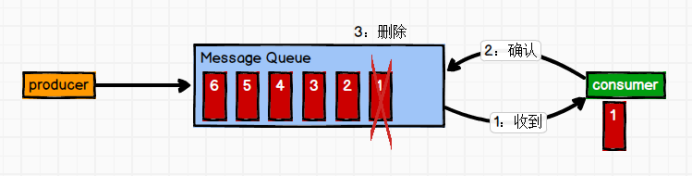
这是一种一对一的、消费者主动拉取数据的模式,消息被消费之后,就被从队列里清除,这种消费模式功能比较单一。
2)发布/订阅模式
消息生产者(发布)将消息发布到Topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到Topic的消息会被所有订阅者消费。
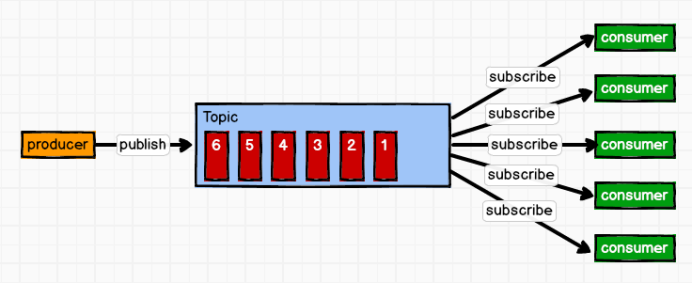
小总结:
基于这种模式,一条消息可以发给多个消费者;
发布订阅模式有两种:一种是队列推送消息,一种是消费者拉取数据;
造成的问题:推送消息的速度由队列决定,消费者的处理能力不一定,例如:生产100条/s,消费50条/s ,所以kafka采取的是消费者拉取的模式。当然拉取模式也有缺点:消费者需要频繁询问是否有消息等待消费[维护着一个长轮询] 。
4、kafka的基础架构
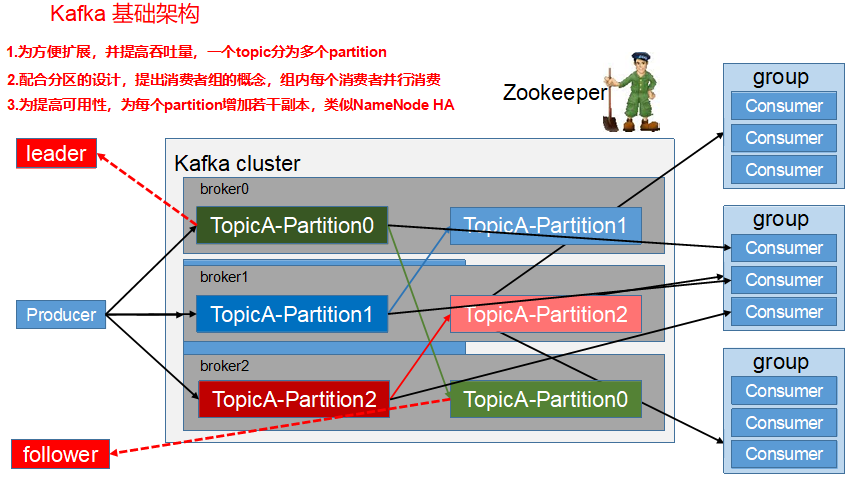
- Producer :消息生产者,就是向kafka broker发消息的客户端;
- Consumer :消息消费者,向kafka broker取消息的客户端;
- Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
- Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic;
- Partition:为了实现扩展性,一个大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
- leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
- follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower。
注意哦:
(1)生产者和消费者都是去找leader,follower 只是个备份数据;
(2)同一个消费者组里的消费者不能消费同一个分区的数据,例如:同一个主题内只有2个数据分区,消费者组有3个消费者,那么第三个消费者只能空占资源,没有消费;
(3)kafka把消息存放在磁盘上,默认保留7天;
(4)zookeeper:首先kafka集群正常工作需要安装ZK,协助管理集群。只需要使得多个broker公用一个ZK,就能使得它们组成集群工作。其次,消费者的消费偏移量(offset)保存在ZK里面;(0.9版本之前存在ZK,0.9版本之后存放在kafka系统维护的一个topic中)。
kafka学习笔记(一)——概述的更多相关文章
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer
Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer: 启动Zookeeper 启动Kafka0.11 创建一个新的Topic: ./kafk ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- 【大数据】Kafka学习笔记
第1章 Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- Struts2 学习笔记(概述)
Struts2 学习笔记 2015年3月7日11:02:55 MVC思想 Strust2的MVC对应关系如下: 在MVC三个模块当中,struts2对应关系如下: Model: 负责封装应用的状态,并 ...
- kafka学习笔记(七)kafka的状态机模块
概述 这一篇随笔介绍kafka的状态机模块,Kafka 源码中有很多状态机和管理器,比如之前我们学过的 Controller 通道管理器 ControllerChannelManager.处理 Con ...
- kafka学习笔记(六)kafka的controller模块
概述 今天我们主要看一下kafka的controller的代码,controller代码是kafka的非常重要的代码,需要我们深入学习.从某种意义上来说,它是kafka最核心的组件,一方面,他要为集群 ...
随机推荐
- Linux:搭建GitLab
0.写在前面 GitLab官方明确要求最低配置2核4G,如果配置过低,会出现502错误. 1.安装SSH #安装ssh sudo yum install -y curl policycoreutils ...
- Windows版:Nginx部署React项目并访问Spring Boot后台数据
一, 打包react项目 1,在工作空间目录下create-react-app test-arrange 创建项目test-arrange 2,在新建的项目中写好请求与页面 3,打包, 在项目目录下 ...
- abp中使用同步方法调用异步方法
var result= AsyncHelper.RunSync(()=>{ return _service.GetUserAsync(); });
- sshfs+overlayfs实现一个共享只读资源被多个主机挂载成可写目录
sshfs+overlayfs实现一个共享只读资源被多个主机挂载成可写目录 1.sshfs -o ssh_command='sshpass -p '"${passwd}"' ssh ...
- Multitenancy
Multitenancy https://www.gartner.com/en/information-technology/glossary/multitenancy 公用一套物理环境,划分出不同的 ...
- nginx安装和命令
1. nginx安装 1.1 mac上安装 brew search nginx brew install nginx 1.2 windows上安装 下载nginx.zip,解压到D盘,发送快捷方式到桌 ...
- Nginx请求转发
1.比如说我要将127.0.0.1/topics上的所有请求转发到xxx:xxx/上 修改 sudo vim /etc/nginx/nginx.conf server { listen 80; ser ...
- PAT 甲级 1020 Tree Traversals (25分)(后序中序链表建树,求层序)***重点复习
1020 Tree Traversals (25分) Suppose that all the keys in a binary tree are distinct positive intege ...
- iOS - NSURLConnection finished with error - code -1002
网络请求会异常,比如报错:Error domain: 在回调的地方打一个断点,然后用命令行查看下什么错误: po error 当错误是:**[Error Domain=NSURLErrorDomain ...
- C++ 右值引用与move
C++ 右值引用与move 右值引用 C++中所有的值都必然属于左值.右值二者之一.左值是指表达式结束后依然存在的持久化对象,右值是指表达式结束时就不再存在的临时对象. 所有的具名变量或者对象都是左值 ...