5. Spark Streaming高级解析
5.1 DStreamGraph对象分析
在Spark Streaming中,DStreamGraph是一个非常重要的组件,主要用来:
1. 通过成员inputStreams持有Spark Streaming输入源及接收数据的方式
2. 通过成员outputStreams持有Streaming app的output操作,并记录DStream依赖关系
3. 生成每个batch对应的jobs
下面,通过分析一个简单的例子,结合源码分析来说明DStreamGraph是如何发挥作用的。案例如下:
val sparkConf = new SparkConf().setAppName("HdfsWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
val lines = ssc.textFileStream(args(0))
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
创建DStreamGraph实例
代码 val ssc = new StreamingContext(sparkConf, Seconds(2)) 创建了StreamingContext实例,StreamingContext包含了DStreamGraph类型的成员graph,graph在StreamingContext主构造函数中被创建,如下
private[streaming] val graph: DStreamGraph = {
if (isCheckpointPresent) {
cp_.graph.setContext(this)
cp_.graph.restoreCheckpointData()
cp_.graph
} else {
require(batchDur_ != null, "Batch duration for StreamingContext cannot be null")
val newGraph = new DStreamGraph()
newGraph.setBatchDuration(batchDur_)
newGraph
}
}
可以看到,若当前checkpoint可用,会优先从checkpoint恢复graph,否则新建一个。还可以从这里知道的一点是:graph是运行在driver上的
DStreamGraph记录输入源及如何接收数据
DStreamGraph有和application输入数据相关的成员和方法,如下:
private val inputStreams = new ArrayBuffer[InputDStream[_]]()
def addInputStream(inputStream: InputDStream[_]) {
this.synchronized {
inputStream.setGraph(this)
inputStreams += inputStream
}
}
成员inputStreams为InputDStream类型的数组,InputDStream是所有input streams(数据输入流)的虚基类。该类提供了start()和stop()方法供streaming系统来开始和停止接收数据。那些只需要在driver端接收数据并转成RDD的input streams可以直接继承InputDStream,例如FileInputDStream是InputDStream的子类,它监控一个HDFS目录并将新文件转成RDDs。而那些需要在workers上运行receiver来接收数据的Input DStream,需要继承ReceiverInputDStream,比如KafkaReceiver
来看一下 val lines = ssc.textFileStream(args(0)) 调用,调用流程如下
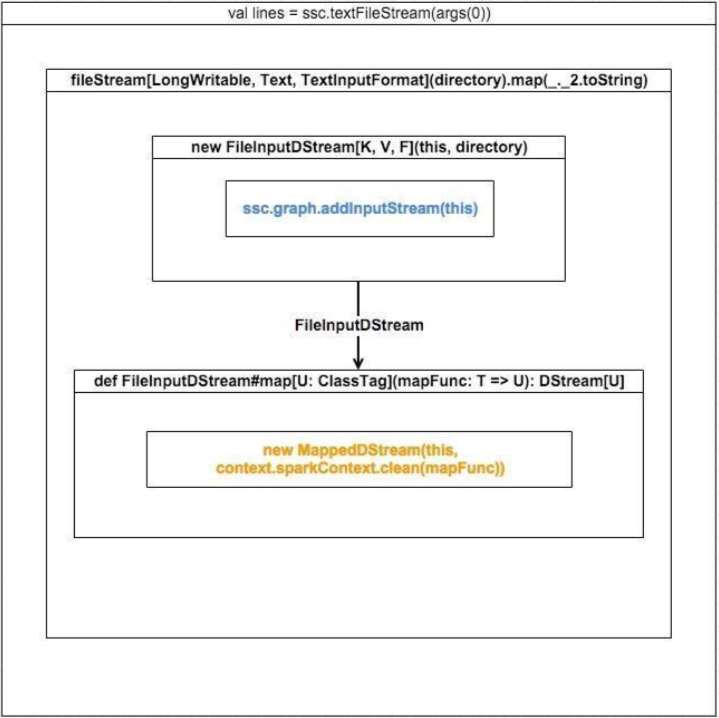
从上面的调用流程图我们可以知道:
1. ssc.textFileStream会触发新建一个FileInputDStream。FileInputDStream继承于InputDStream,其start()方法定义了数据源及如何接收数据
2. 在FileInputDStream构造函数中,会调用ssc.graph.addInputStream(this),将自身添加到DStreamGraph的inputStreams: ArrayBuffer[InputDStream[_]] 中,这样DStreamGraph就知道了这个Streaming App的输入源及如何接收数据。可能你会奇怪为什么inputStreams是数组类型,举个例子,这里再来一个 val lines1 = ssc.textFileStream(args(0)),那么又将生成一个FileInputStream实例添加到inputStreams,所以这里需要集合类型
3. 生成FileInputDStream调用其map方法,将以FileInputDStream本身作为partent来构造新的MappedDStream。对于DStream的transform操作,都将生成一个新的DStream,和RDD transform生成新的RDD类似与MappedDStream不同,所有继承了InputDStream的定义了输入源及接收数据方式的sreams都没有parent,因为它们就是最初的streams
DStream的依赖链
每个DStream的子类都会继承def dependencies: List[DStream[_]] = List()方法,该方法用来返回自己的依赖的父DStream列表。比如,没有父DStream的 InputDStream的dependencies方法返回List()
MappedDStream的实现如下:
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
...
}
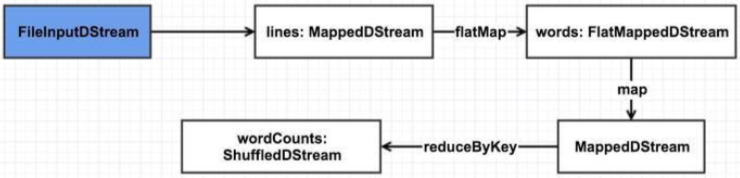
在上例中,构造函数参数列表中的parent即在ssc.textFileStream中new的定义了输入源及数据接收方式的最初的FileInputDStream实例,这里的dependencies方法将返回该FileInputDStream实例,这就构成了第一条依赖。可用如下图表示,这里特地将input streams用蓝色表示,以强调其与普通由transform产生的DStream的不同:

继续来看val words = lines.flatMap(_.split(" ")),flatMap如下:
def flatMap[U: ClassTag](flatMapFunc: T => Traversable[U]): DStream[U] = ssc.withScope {
new FlatMappedDStream(this, context.sparkContext.clean(flatMapFunc))
}
每一个transform操作都将创建一个新的DStream,flatMap操作也不例外,它会创建一个FlatMappedDStream,FlatMappedDStream的实现如下:
class FlatMappedDStream[T: ClassTag, U: ClassTag](
parent: DStream[T],
flatMapFunc: T => Traversable[U]
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
...
}
与MappedDStream相同,FlatMappedDStream#dependencies也返回其依赖的父DStream,及lines,到这里,依赖链就变成了下图:

之后的几步操作不再这样具体分析,到生成wordCounts时,依赖图将变成下面这样:
在DStream中,与transform相对应的是output操作,包括print, saveAsTextFiles,saveAsObjectFiles,saveAsHadoopFiles,foreachRDD。output操作中,会创建 ForEachDStream实例并调用register方法将自身添加到DStreamGraph.outputStreams成员中,该ForEachDStream实例也会持有是调用的哪个output操作。本例的代码调用如下,只需看箭头所指几行代码
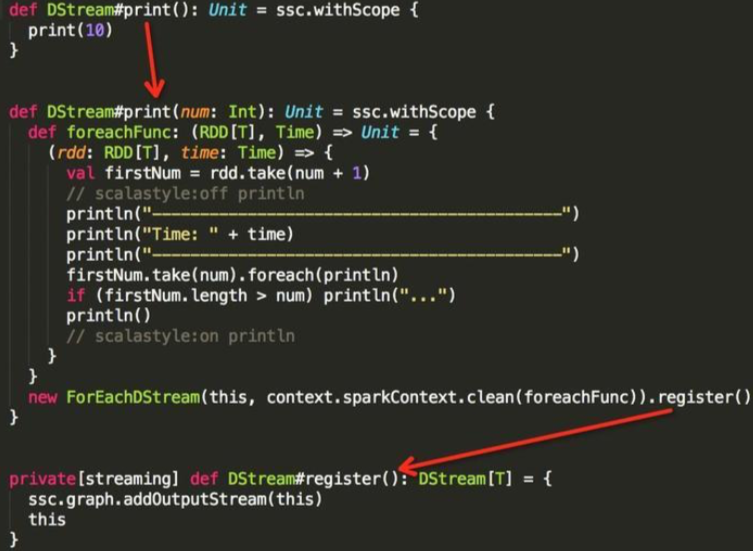
与DStreamtransform操作返回一个新的DStream不同,output操作不会返回任何东西,只会创建一个ForEachDStream作为依赖链的终结
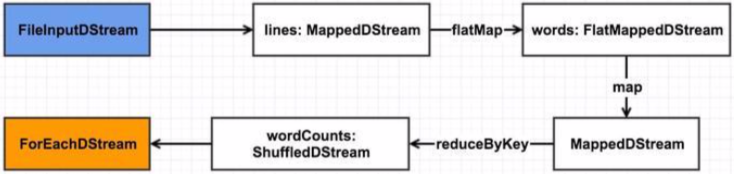
至此,生成了完成的依赖链,也就是DAG,如下图(这里将ForEachDStream标为黄色以显示其与众不同):
5.2 ReceiverTracker与数据导入
Spark Streaming在数据接收与导入方面需要满足有以下三个特点:
1. 兼容众多输入源,包括HDFS, Flume, Kafka, Twitter and ZeroMQ。还可以自定义数据源
2. 要能为每个batch的RDD提供相应的输入数据
3. 为适应 7*24h 不间断运行,要有接收数据挂掉的容错机制
有容乃大,兼容众多数据源
InputDStream是所有input streams(数据输入流)的虚基类。该类提供了start()和stop()方法供streaming系统来开始和停止接收数据。那些只需要在driver端接收数据并转成RDD的input streams可以直接继承InputDStream,例如FileInputDStream是InputDStream的子类,它监控一个HDFS目录并将新文件转成RDDs。而那些需要在 workers上运行receiver来接收数据的Input DStream,需要继承ReceiverInputDStream,比如KafkaReceiver
只需在driver端接收数据的input stream一般比较简单且在生产环境中使用的比较少,本文不作分析,只分析继承了ReceiverInputDStream的input stream是如何导入数据的
ReceiverInputDStream有一个def getReceiver(): Receiver[T]方法,每个继承了ReceiverInputDStream的 input stream都必须实现这个方法。该方法用来获取将要分发到各个worker节点上用来接收数据的receiver(接收器)。不同的ReceiverInputDStream子类都有它们对应的不同的receiver,如KafkaInputDStream对应KafkaReceiver,FlumeInputDStream对应FlumeReceiver,TwitterInputDStream对应TwitterReceiver,如果你要实现自己的数据源,也需要定义相应的receiver
继承ReceiverInputDStream并定义相应的receiver,就是SparkStreaming能兼容众多数据源的原因
为每个batch的RDD提供输入数据
在StreamingContext中,有一个重要的组件叫做 ReceiverTracker,它是Spark Streaming作业调度器JobScheduler的成员,负责启动、管理各个receiver及管理各个receiver接收到的数据
确定receiver要分发到哪些executors上执行
创建ReceiverTracker实例
我们来看StreamingContext#start()方法部分调用实现,如下:
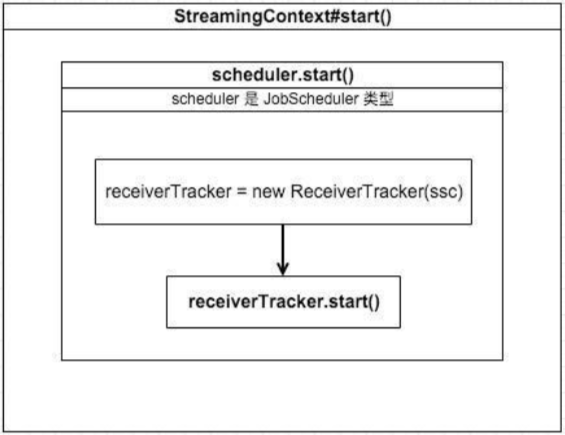
ReceiverTracker#start()
继续跟进ReceiverTracker#start(),如下图,它主要做了两件事:
1. 初始化一个 endpoint: ReceiverTrackerEndpoint,用来接收和处理来自ReceiverTracker 和 receivers 发送的消息
2. 调用launchReceivers来自将各个receivers分发到executors上
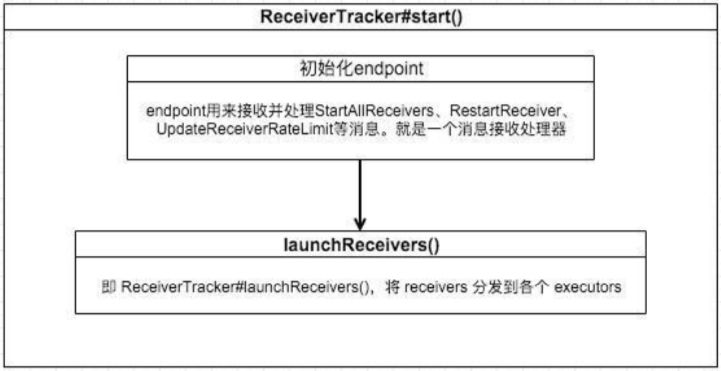
ReceiverTracker#launchReceivers()
继续跟进launchReceivers,它也主要干了两件事:
1. 获取 DStreamGraph.inputStreams 中继承了 ReceiverInputDStream 的input streams 的 receivers。也就是数据接收器
2. 给消息接收处理器endpoint发送StartAllReceivers(receivers)消息。直接返回,不等待消息被处理
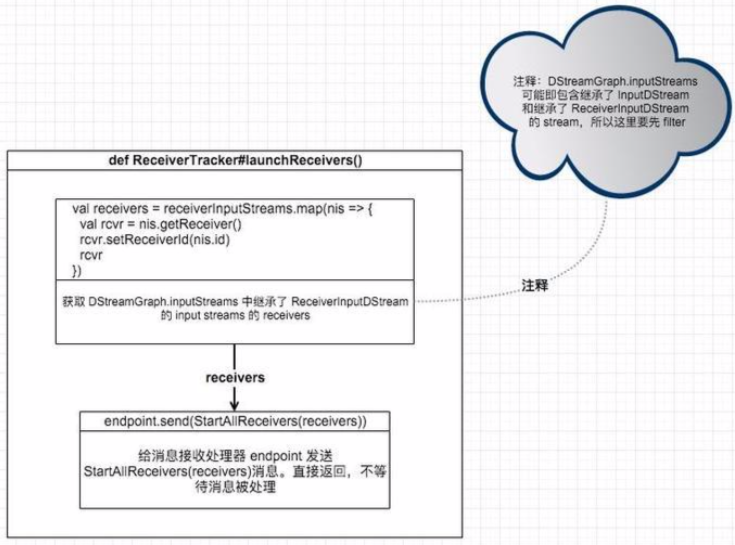
处理StartAllReceivers消息
endpoint在接收到消息后,会先判断消息类型,对不同的消息做不同处理。对于StartAllReceivers消息,处理流程如下:
计算每个receiver要分发的目的executors。遵循两条原则:
1. 将 receiver 分布的尽量均匀
2. 如果receiver的preferredLocation本身不均匀,以preferredLocation为准
遍历每个receiver,根据第 1 步中得到的目的executors调用startReceiver方法
到这里,已经确定了每个receiver要分发到哪些executors上
启动receivers
接上,通过ReceiverTracker#startReceiver(receiver: Receiver[_],scheduledExecutors: Seq[String])来启动receivers,我们来看具体流程:

如上流程图所述,分发和启动receiver的方式不可谓不精彩。其中,startReceiverFunc函数主要实现如下:
val supervisor = new ReceiverSupervisorImpl(receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
supervisor.start()中会调用receiver#onStart后立即返回。receiver#onStart一般自行新建线程或线程池来接收数据,比如在KafkaReceiver中,就新建了线程池,在线程池中接收topics的数据
supervisor.start()返回后,由supervisor.awaitTermination()阻塞住线程,以让这个task一直不退出,从而可以源源不断接收数据
数据流转
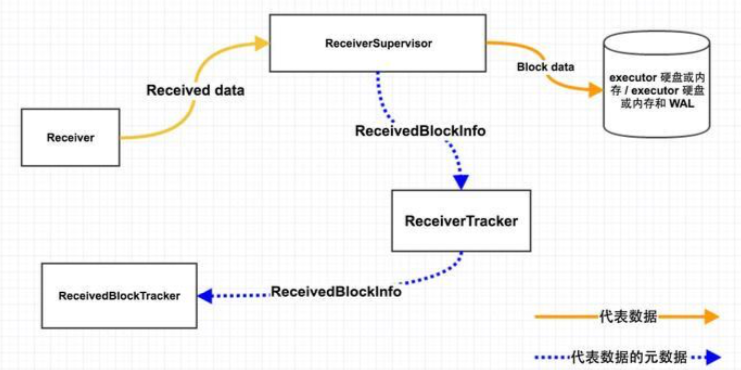
上图为receiver接收到的数据的流转过程,分析如下:
Step1: Receiver -> ReceiverSupervisor
这一步中,Receiver将接收到的数据源源不断地传给ReceiverSupervisor。Receiver调用其store(...)方法,store方法中继续调用supervisor.pushSingle或 supervisor.pushArrayBuffer等方法来传递数据。Receiver#store有多重形式,ReceiverSupervisor也有pushSingle、pushArrayBuffer、pushIterator、pushBytes方法与不同的 store对应
1. pushSingle: 对应单条小数据
2. pushArrayBuffer: 对应数组形式的数据
3. pushIterator: 对应iterator形式数据
4. pushBytes: 对应ByteBuffer形式的块数据
对于细小的数据,存储时需要BlockGenerator聚集多条数据成一块,然后再成块存储;反之就不用聚集,直接成块存储。当然,存储操作并不在Step1中执行,只为说明之后不同的操作逻辑
Step2.1: ReceiverSupervisor -> BlockManager -> disk/memory
在这一步中,主要将从receiver收到的数据以block(数据块)的形式存储存储block的是receivedBlockHandler: ReceivedBlockHandler,根据参数spark.streaming.receiver.writeAheadLog.enable配置的不同,默认为false,receivedBlockHandler对象对应的类也不同,如下:
private val receivedBlockHandler: ReceivedBlockHandler = {
if (WriteAheadLogUtils.enableReceiverLog(env.conf)) {
//< 先写 WAL,再存储到 executor 的内存或硬盘
new WriteAheadLogBasedBlockHandler(env.blockManager, receiver.streamId, receiver.storageLevel, env.conf, hadoopConf, checkpointDirOption.get)
} else {
//< 直接存到 executor 的内存或硬盘
new BlockManagerBasedBlockHandler(env.blockManager, receiver.storageLevel)
}
}
// 启动 WAL 的好处就是在 application 挂掉之后,可以恢复数据。
// < 调用 receivedBlockHandler.storeBlock 方法存储 block,并得到一个 blockStoreResult
val blockStoreResult = receivedBlockHandler.storeBlock(blockId, receivedBlock)
//< 使用 blockStoreResult 初始化一个 ReceivedBlockInfo 实例
val blockInfo = ReceivedBlockInfo(streamId, numRecords, metadataOption, blockStoreResult)
//< 发送消息通知 ReceiverTracker 新增并存储了 block
trackerEndpoint.askWithRetry[Boolean](AddBlock(blockInfo))
不管是WriteAheadLogBasedBlockHandler还是BlockManagerBasedBlockHandler最终都是通过BlockManager将block数据存储execuor内存或磁盘或还有 WAL方式存入
这里需要说明的是streamId,每个InputDStream都有它自己唯一的id,即streamId,blockInfo包含streamId是为了区分block是哪个InputDStream的数据。之后为batch分配blocks时,需要知道每个InputDStream都有哪些未分配的blocks
Step2.2: ReceiverSupervisor -> ReceiverTracker
将block存储之后,获得block描述信息blockInfo: ReceivedBlockInfo,这里面包含:streamId、数据位置、数据条数、数据size等信息。之后,封装以block作为参数的AddBlock(blockInfo)消息并发送给ReceiverTracker以通知其有新增block数据块
Step3: ReceiverTracker -> ReceivedBlockTracker
ReceiverTracker收到ReceiverSupervisor发来的AddBlock(blockInfo)消息后,直接调用以下代码将block信息传给ReceivedBlockTracker:
receivedBlockTracker.addBlock中,如果启用了WAL,会将新增的block信息以WAL方式保存
无论WAL是否启用,都会将新增的block信息保存到streamIdToUnallocatedBlockQueues: mutable.HashMap[Int, ReceivedBlockQueue]中,该变量key为 InputDStream的唯一id,value为已存储未分配的block信息。之后为batch分配blocks,会访问该结构来获取每个InputDStream对应的未消费的blocks
5.3 动态生成JOB
JobScheduler有两个重要成员,一是ReceiverTracker,负责分发receivers及源源不断地接收数据;二是JobGenerator,负责定时的生成jobs并checkpoint
定时逻辑
在JobScheduler的主构造函数中,会创建JobGenerator对象。在JobGenerator的主构造函数中,会创建一个定时器:
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
该定时器每隔ssc.graph.batchDuration.milliseconds会执行一次eventLoop.post(GenerateJobs(new Time(longTime)))向eventLoop发送GenerateJobs(new Time(longTime))消息,eventLoop收到消息后会进行这个batch对应的jobs的生成及提交执行,eventLoop是一个消息接收处理器
需要注意的是,timer在创建之后并不会马上启动,将在StreamingContext#start()启动Streaming Application时间接调用到
timer.start(restartTime.milliseconds)才启动
为batch生成jobs
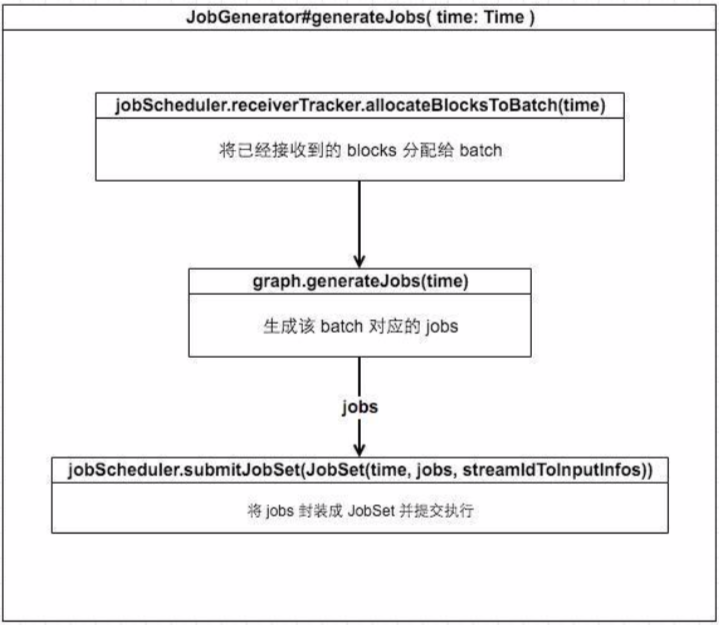
eventLoop在接收到GenerateJobs(new Time(longTime))消息后的主要处理流程有以上图中三步:
1. 将已接收到的blocks分配给batch
2. 生成该batch对应的jobs
3. 将jobs封装成JobSet并提交执行
将这三步展开进行分析
上图是根据源码画出的为batch分配blocks的流程图,这里对『获得batchTime各个InputDStream未分配的blocks』作进一步说明:
我们知道了各个ReceiverInputDStream对应的receivers接收并保存的blocks信息会保存在ReceivedBlockTracker#streamIdToUnallocatedBlockQueues,该成员key为streamId,value为该streamId对应的InputDStream已接收保存但尚未分配的 blocks 信息。
所以获取某 InputDStream 未分配的 blocks 只要以该 InputDStream 的streamId 来从 streamIdToUnallocatedBlockQueues 来 get 就好。获取之后, 会清楚该 streamId 对应的 value,以保证 block 不会被重复分配。
在实际调用中,为batchTime分配blocks时,会从streamIdToUnallocatedBlockQueues取出未分配的blocks塞进timeToAllocatedBlocks: mutable.HashMap[Time, AllocatedBlocks] 中,以在之后作为该batchTime对应的RDD的输入数据。
通过以上步骤,就可以为batch的所有InputDStream分配blocks。也就是为batch分配了blocks
生成该batch对应的jobs

eventLoop在接收到GenerateJobs(new Time(longTime))消息后的主要处理流程有以上图中三步:
1. 将已接收到的blocks分配给batch
2. 生成该batch对应的jobs
3. 将jobs封装成JobSet并提交执行
将这三步进行分析
将已接收到的blocks分配给batch

上图是根据源码画出的为batch分配blocks的流程图,这里对『获得batchTime各个InputDStream未分配的blocks』作进一步说明:
我们知道了各个ReceiverInputDStream对应的receivers接收并保存的blocks信息会保存在ReceivedBlockTracker#streamIdToUnallocatedBlockQueues,该成员key为streamId,value为该streamId对应的InputDStream已接收保存但尚未分配的blocks信息。所以获取某InputDStream未分配的blocks只要以该InputDStream的streamId来从streamIdToUnallocatedBlockQueues来get就好。获取之后,会清楚该streamId对应的value,以保证block不会被重复分配。在实际调用中,为batchTime分配 blocks时,会从streamIdToUnallocatedBlockQueues取出未分配的blocks塞进timeToAllocatedBlocks: mutable.HashMap[Time, AllocatedBlocks]中,以在之后作为该 batchTime对应的RDD的输入数据。通过以上步骤,就可以为batch的所有InputDStream分配blocks。也就是为batch分配了blocks
生成该 batch 对应的 jobs
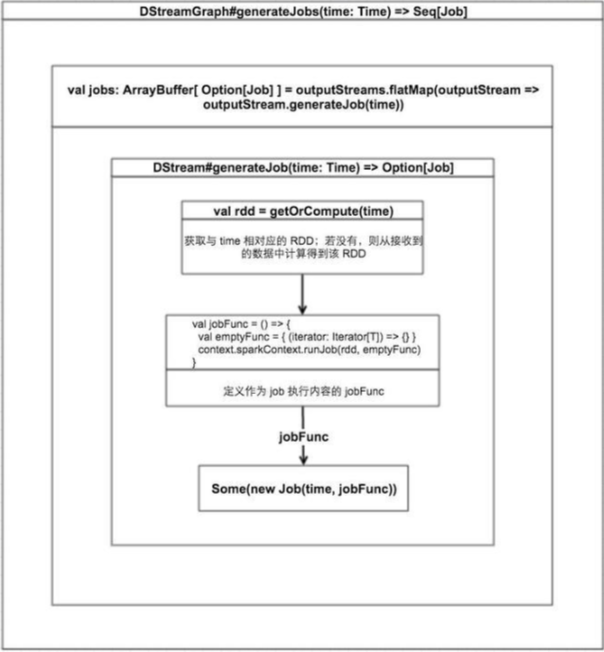
为指定batchTime生成jobs的逻辑如上图所示。你可能会疑惑,为什么DStreamGraph#generateJobs(time: Time)为什么返回Seq[Job],而不是单个job。这是因为,在一个batch内,可能会有多个OutputStream执行了多次output操作,每次output操作都将产生一个Job,最终就会产生多个Jobs
我们结合上图对执行流程进一步分析:
在DStreamGraph#generateJobs(time: Time)中,对于DStreamGraph成员ArrayBuffer[DStream[_]]的每一项,调用DStream#generateJob(time: Time)来生成这个outputStream在该batchTime的job。该生成过程主要有三步:
Step1: 获取该outputStream在该batchTime对应的RDD
每个DStream实例都有一个generatedRDDs: HashMap[Time, RDD[T]]成员,用来保存该DStream在每个batchTime生成的RDD,当DStream#getOrCompute(time: Time)调用时
首先会查看generatedRDDs中是否已经有该time对应的RDD,若有则直接返回
若无,则调用compute(validTime: Time)来生成RDD,这一步根据每个InputDStream继承compute的实现不同而不同。例如,对于FileInputDStream,其compute实现逻辑如下:
1. 先通过一个findNewFiles()方法,找到多个新file
2. 对每个新file,都将其作为参数调用sc.newAPIHadoopFile(file),生成一个RDD实例
3. 将2中的多个新file对应的多个RDD实例进行union,返回一个union后的UnionRDD
Step2: 根据Step1中得到的RDD生成最终job要执行的函数jobFunc
jobFunc 定义如下:
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
可以看到,每个outputStream的output操作生成的Job其实与RDD action一样,最终调用SparkContext#runJob来提交RDD DAG定义的任务
Step3: 根据Step2中得到的jobFunc生成最终要执行的Job并返回
Step2 中得到了定义 Job 要干嘛的函数-jobFunc,这里便以 jobFunc 及batchTime 生成 Job 实例:
Some(new Job(time, jobFunc))
该Job实例将最终封装在JobHandler中被执行
至此,我们搞明白了JobScheduler是如何通过一步步调用来动态生成每个batchTime的jobs。下文我们将分析这些动态生成的jobs如何被分发及如何执行
5.4 job的提交与执行
我们分析了JobScheduler是如何动态为每个batch生成jobs,那么生成的jobs是如何被提交的
在JobScheduler生成某个batch对应的Seq[Job]之后,会将batch及Seq[Job]封装成一个JobSet对象,JobSet持有某个batch内所有的jobs,并记录各个job的运行状态
之后,调用JobScheduler#submitJobSet(jobSet: JobSet)来提交jobs,在该函数中,除了一些状态更新,主要任务就是执行
jobSet.jobs.foreach(job => jobExecutor.execute(new JobHandler(job)))
即,对于jobSet中的每一个job,执行jobExecutor.execute(new JobHandler(job)),要搞懂这行代码干了什么,就必须了解JobHandler及jobExecutor
JobHandler
JobHandler继承了Runnable,为了说明与job的关系,其精简后的实现如下:
private class JobHandler(job: Job) extends Runnable with Logging {
import JobScheduler._
def run() {
_eventLoop.post(JobStarted(job))
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
job.run()
}
_eventLoop = eventLoop
if (_eventLoop != null) {
_eventLoop.post(JobCompleted(job))
}
}
}
JobHandler#run方法主要执行了job.run(),该方法最终将调用到『生成该batch对应的jobs的Step2定义的jobFunc』, jonFunc将提交对应RDD DAG定义的job
JobExecutor
知道了JobHandler是用来执行job的,那么JobHandler将在哪里执行job 呢?答案是
jobExecutor,jobExecutor为JobScheduler成员,是一个线程池,在JobScheduler主构造函数中创建,如下:
private val numConcurrentJobs = ssc.conf.getInt("spark.streaming.concurrentJobs", 1)
private val jobExecutor = ThreadUtils.newDaemonFixedThreadPool(numConcurrentJobs, "streaming-job- executor")
JobHandler将最终在线程池jobExecutor的线程中被调用,jobExecutor的线程数可通过spark.streaming.concurrentJobs配置,默认为1。若配置多个线程,就能让多个job同时运行,若只有一个线程,那么同一时刻只能有一 个job运行
以上,即jobs被执行的逻辑
5.5 Block的生成与存储
ReceiverSupervisorImpl共提供了4个将从receiver传递过来的数据转换成block并存储的方法,分别是:
pushSingle: 处理单条数据
pushArrayBuffer: 处理数组形式数据
pushIterator: 处理iterator形式处理
pushBytes: 处理ByteBuffer形式数据
其中,pushArrayBuffer、pushIterator、pushBytes最终调用pushAndReportBlock;而pushSingle将调用defaultBlockGenerator.addData(data),我分别就这两种形式做说明
pushAndReportBlock
我针对存储block简化pushAndReportBlock后的代码如下:
def pushAndReportBlock(
receivedBlock: ReceivedBlock,
metadataOption: Option[Any],
blockIdOption: Option[StreamBlockId]
){
...
val blockId = blockIdOption.getOrElse(nextBlockId)
receivedBlockHandler.storeBlock(blockId, receivedBlock)
...
}
首先获取一个新的blockId,之后调用receivedBlockHandler.storeBlock, receivedBlockHandler在ReceiverSupervisorImpl构造函数中初始化。当启用了checkpoint且 spark.streaming.receiver.writeAheadLog.enable为true时,receivedBlockHandler被初始化为WriteAheadLogBasedBlockHandler类型;否则将初始化为BlockManagerBasedBlockHandler 类型
WriteAheadLogBasedBlockHandler#storeBlock将ArrayBuffer, iterator, bytes类型的数据序列化后得到的serializedBlock
1. 交由BlockManager根据设置的StorageLevel存入executor的内存或磁盘中
2. 通过WAL再存储一份
而BlockManagerBasedBlockHandler#storeBlock将ArrayBuffer, iterator, bytes类型的数据交由BlockManager根据设置的StorageLevel存入executor的内存或磁盘中,并不再通过WAL存储一份pushSingle
pushSingle将调用BlockGenerator#addData(data: Any)通过积攒的方式来存储数据。接下来对BlockGenerator是如何积攒一条一条数据最后写入block的逻辑

上图为BlockGenerator的各个成员,首选对各个成员做介绍:
currentBuffer
变长数组,当receiver接收的一条一条的数据将会添加到该变长数组的尾部
可能会有一个receiver的多个线程同时进行添加数据,这里是同步操作
添加前,会由rateLimiter检查一下速率,是否加入的速度过快。如果过快的话就需要block住,等到下一秒再开始添加。最高频率由spark.streaming.receiver.maxRate控制,默认值为Long.MaxValue,具体含义是单个Receiver每秒钟允许添加的条数
blockIntervalTimer&blockIntervalMs
分别是定时器和时间间隔。blockIntervalTimer中有一个线程,每隔blockIntervalMs会执行以下操作:
将currentBuffer赋值给newBlockBuffer
将currentBuffer指向新的空的ArrayBuffer对象
将newBlockBuffer封装成newBlock
将newBlock添加到blocksForPushing队列中blockIntervalMs由spark.streaming.blockInterval控制,默认是200ms
blockPushingThread&blocksForPushing&blockQueueSize
blocksForPushing是一个定长数组,长度由blockQueueSize决定,默认为10,可通过spark.streaming.blockQueueSize改变。上面分析到,blockIntervalTimer中的线程会定时将block塞入该队列
还有另一条线程不断送该队列中取出block,然后调用ReceiverSupervisorImpl.pushArrayBuffer(...)来将 block 存储,这条线程就是blockPushingThread
PS: blocksForPushing为ArrayBlockingQueue类型。ArrayBlockingQueue是一个阻塞队列,能够自定义队列大小,当插入时,如果队列已经没有空闲位置,那么新的插入线程将阻塞到该队列,一旦该队列有空闲位置,那么阻塞的线程将执行插入
以上,通过分析各个成员,也说明了BlockGenerator是如何存储单条数据的
5. Spark Streaming高级解析的更多相关文章
- Spark Streaming高级特性在NDCG计算实践
从storm到spark streaming,再到flink,流式计算得到长足发展, 依托于spark平台的spark streaming走出了一条自己的路,其借鉴了spark批处理架构,通过批处理方 ...
- 1.Spark Streaming另类实验与 Spark Streaming本质解析
1 Spark源码定制选择从Spark Streaming入手 我们从第一课就选择Spark子框架中的SparkStreaming. 那么,我们为什么要选择从SparkStreaming入手开始我们 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- Spark Streaming揭秘 Day34 解析UI监听模式
Spark Streaming揭秘 Day34 解析UI监听模式 今天分享下SparkStreaming中的UI部分,和所有的UI系统一样,SparkStreaming中的UI系统使用的是监听器模式. ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/bGXhC9hvDj4lzK7wYYHGDg 目前,我们使用Filebeat监控日志产生的目录,收集产生的日志,打到logstash集群,接入ka ...
- spark streaming 使用geoIP解析IP
1.首先将GEOIP放到服务器上,如,/opt/db/geo/GeoLite2-City.mmdb 2.新建scala sbt工程,测试是否可以顺利解析 import java.io.Fileimpo ...
- 16.Spark Streaming源码解读之数据清理机制解析
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 本期内容: 一.Spark Streaming 数据清理总览 二.Spark Streami ...
随机推荐
- JWT了解与实战
最近在使用JWT做一个单点登录与接口鉴权的功能,正好可以对JWT有深一步的了解. 一.JWT使用场景: 1. 授权:用户登录后,每个请求都包含JWT,允许用户访问该令牌允许的路由.服务和资源.单点登录 ...
- 【Beta】“北航社团帮”发布声明——小程序v2.0与网页端v1.0
目录 Beta版本新功能 小程序v2.0新功能 新功能列表 功能详情图 新功能动图展示 网页端v1.0功能 登录方式 社团信息的修改 新闻的录入和修改 活动的录入和修改 这一版修复的缺陷 Beta版本 ...
- nginx 日志打印响应时间 request_time 和 upstream_response_time
设置log_format,添加request_time,$upstream_response_time,位置随意 og_format main '"$request_time" ...
- Cesium中导入三维模型方法(dae到glft/bgltf)[转]
Cesium中导入三维模型方法(dae到glft/bgltf) Cesium中目前支持gltf和bgltf两种格式.“gltf是khronos组织(起草OpenGL标准的那家)定义的一种交换格式,用于 ...
- Token 安全登陆防止窃取
HTTP 协议是无状态的 在web中使用cookie+session的技术来保持用户登陆的状态 移动端使用token来保持用户登陆状态由于token在网络中传输,很容易被 中间人获取,进而模拟用户进行 ...
- java判断是excel2003还是2007以上
public static Workbook create(InputStream in) throws IOException,InvalidFormatException { if (!in.ma ...
- linux查看实时日志命令
tail -f localhost_access_log.2018-12-11.txt(当前时间)今天的实时日志,操作一下系统,就会报出相应的日志
- nginx 分离配置文件 conf.d和default.conf
1. 在 nginx.conf 文件中引用 conf.d 下的所有配置文件 #在http配置节的末尾添加配置引用 http { ... #gzip on; include /etc/nginx/con ...
- getBrandWCPayRequest 和 chooseWXPay 的区别
getBrandWCPayRequest 和 chooseWXPay 都是发起微信支付请求,chooseWXPay 依赖 http://res.wx.qq.com/open/js/jweixin-1. ...
- Docker 运行ES和Kibana
1. docker pull image docker pull elasticsearch:6.7.2 docker pull mobz/elasticsearch-head:5 docker pu ...