HBase 系列(一)—— HBase 简介
一、Hadoop的局限
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
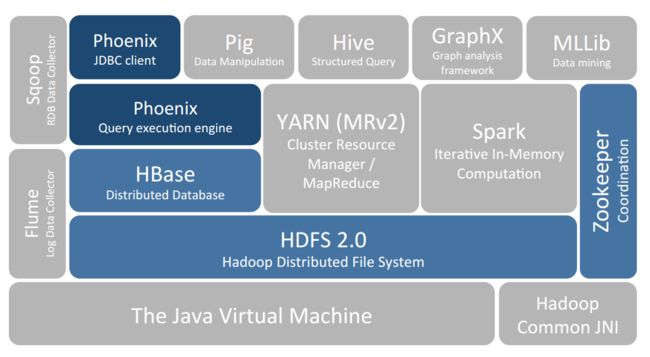
要想明白为什么产生 HBase,就需要先了解一下 Hadoop 存在的限制?Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。
但是 Hadoop 的缺陷在于它只能执行批处理,并且只能以顺序方式访问数据,这意味着即使是最简单的工作,也必须搜索整个数据集,无法实现对数据的随机访问。实现数据的随机访问是传统的关系型数据库所擅长的,但它们却不能用于海量数据的存储。在这种情况下,必须有一种新的方案来解决海量数据存储和随机访问的问题,HBase 就是其中之一 (HBase,Cassandra,couchDB,Dynamo 和 MongoDB 都能存储海量数据并支持随机访问)。
注:数据结构分类:
- 结构化数据:即以关系型数据库表形式管理的数据;
- 半结构化数据:非关系模型的,有基本固定结构模式的数据,例如日志文件、XML 文档、JSON 文档、Email 等;
- 非结构化数据:没有固定模式的数据,如 WORD、PDF、PPT、EXL,各种格式的图片、视频等。
二、HBase简介
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
HBase 是一种类似于 Google’s Big Table 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。它具有以下特性:
- 不支持复杂的事务,只支持行级事务,即单行数据的读写都是原子性的;
- 由于是采用 HDFS 作为底层存储,所以和 HDFS 一样,支持结构化、半结构化和非结构化的存储;
- 支持通过增加机器进行横向扩展;
- 支持数据分片;
- 支持 RegionServers 之间的自动故障转移;
- 易于使用的 Java 客户端 API;
- 支持 BlockCache 和布隆过滤器;
- 过滤器支持谓词下推。
三、HBase Table
HBase 是一个面向 列 的数据库管理系统,这里更为确切的而说,HBase 是一个面向 列族 的数据库管理系统。表 schema 仅定义列族,表具有多个列族,每个列族可以包含任意数量的列,列由多个单元格(cell )组成,单元格可以存储多个版本的数据,多个版本数据以时间戳进行区分。
下图为 HBase 中一张表的:
- RowKey 为行的唯一标识,所有行按照 RowKey 的字典序进行排序;
- 该表具有两个列族,分别是 personal 和 office;
- 其中列族 personal 拥有 name、city、phone 三个列,列族 office 拥有 tel、addres 两个列。
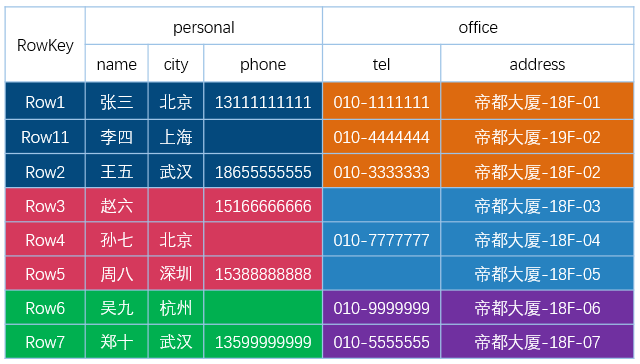
图片引用自 : HBase 是列式存储数据库吗 https://www.iteblog.com/archives/2498.html
Hbase 的表具有以下特点:
容量大:一个表可以有数十亿行,上百万列;
面向列:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了系统的 I/O 负担;
稀疏性:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
数据多版本:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
存储类型:所有数据的底层存储格式都是字节数组 (byte[])。
四、Phoenix
Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
HBase 系列(一)—— HBase 简介的更多相关文章
- Hbase系列文章
Hbase系列文章 HBase(一): c#访问hbase组件开发 HBase(二): c#访问HBase之股票行情Demo HBase(三): Azure HDInsigt HBase表数据导入本地 ...
- Hbase系列-Hbase简介
自1970年以来,关系数据库用于数据存储和维护有关问题的解决方案.大数据的出现后,好多公司实现处理大数据并从中受益,并开始选择像 Hadoop 的解决方案.Hadoop使用分布式文件系统,用于存储大数 ...
- hbase系列之:独立模式部署hbase
一.概述 在上一篇博文中,我简要介绍了hbase的部分基础概念,如果想初步了解hbase的理论,可以参看上一篇博文 hbase系列之:初识hbase .本博文主要介绍独立模式下部署hbase及hbas ...
- HBase 系列(三)HBase Shell
HBase 系列(三)HBase Shell ./hbase shell # 进入 hbase 命令行 (1) HBase 命令帮助 help # 查看 HBase 所有的命令 create # 或 ...
- HBase 系列(二)安装部署
HBase 系列(二)安装部署 本节以 Hadoop-2.7.6,HBase-1.4.5 为例安装 HBase 环境.HBase 也有三种模式:本地模式.伪分布模式.分布模式. 一.环境准备 (1) ...
- Hbase 系列(一)基本概念
Hbase 系列(一)基本概念 HBase 是 Apache 旗下一个高可靠性.高性能.面向列.可伸缩的分布式存储系统.利用 HBase 技术可在廉价 PC 服务器上搭建起大规模的存储化集群.使用 H ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase 系列(二)—— HBase 系统架构及数据结构
一.基本概念 一个典型的 Hbase Table 表如下: 1.1 Row Key (行键) Row Key 是用来检索记录的主键.想要访问 HBase Table 中的数据,只有以下三种方式: 通过 ...
- HBase 系列(五)——HBase 常用 Shell 命令
一.基本命令 打开 Hbase Shell: # hbase shell 1.1 获取帮助 # 获取帮助 help # 获取命令的详细信息 help 'status' 1.2 查看服务器状态 stat ...
- HBase 系列(八)——HBase 协处理器
一.简述 在使用 HBase 时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求.在这种情况下,协处理 ...
随机推荐
- 菜鸟网络Java面试-社招-一面(2019/11)
个人情况 2017年毕业,普通本科,计算机科学与技术专业,毕业后在一个二三线小城市从事Java开发,2年Java开发经验.做过分布式开发,没有高并发的处理经验,平时做To G的项目居多.写下面经是希望 ...
- 东芝300D粉盒清零
东芝300D粉盒清零 1:打开前盖 2:按"OK"键3秒,等 显示 "更换硒鼓"(注:不用选 是/否,直接进入第3步) 3:按"启用"键 4 ...
- ansible-playbook-常用
创建软链:file: - name: create link hosts: "{{hosts_ip}}" tasks: - name: create link file: src= ...
- ping某域名的整个流程
实验环境:主机A,B(可不再同一网段),主机B有域名假设为www.baidu.com首先:1. 本地主机A在命令行下执行"ipconfig/flushdns"命令来清空本地DNS高 ...
- ASP.NET Core 的 Dependency Injection
ASP.NET Core使用了大量的DI(Dependency Injection)设计,有用过Autofac或类似的DI Framework对此应该不陌生.本篇将介绍ASP.NET Core的依赖注 ...
- 认真分析mmap:是什么 为什么 怎么用(转)
阅读目录 mmap基础概念 mmap内存映射原理 mmap和常规文件操作的区别 mmap优点总结 mmap相关函数 mmap使用细节 回到顶部 mmap基础概念 mmap是一种内存映射文件的方法,即将 ...
- annotation processor 为啥没有被调用?
Android Studio 3.5 使用@AutoService(Processor.class)注册annotation processor Android Plugin for Gradle: ...
- nodejs相关框架
sails https://sailsjs.com/documentation/concepts koa koa 是由 Express 原班人马打造的,致力于成为一个更小.更富有表现力.更健壮的 ...
- Python统计数据库中的数据量【含MySQL、Oracle】
Python程序文件如下: # -*- coding: utf-8 # File : start.py # Author : baoshan import json import pymysql im ...
- Android设置顶部banner背景透明度时影响全局背景问题
项目中用到滑动界面使顶部title栏背景渐隐渐现的效果,即初始不滑动时的透明度为0,用了bannerle.getBackground().setAlpha(0); 但使用这个方法设置透明度是管用,返回 ...