23、CacheManager原理剖析与源码分析
一、图解
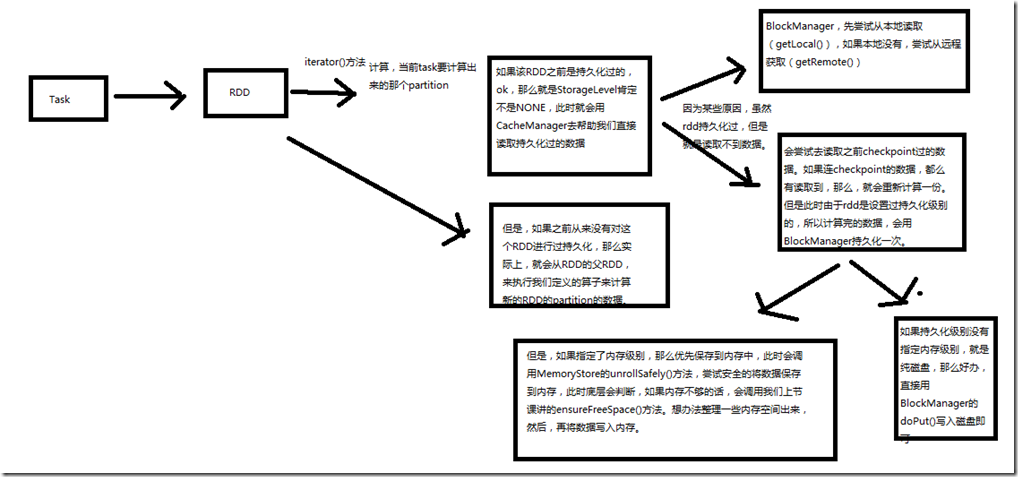
二、源码分析
###org.apache.spark.rdd/RDD.scalal
###入口 final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
// cacheManager相关东西
// 如果storageLevel不为NONE,就是说,我们之前持久化过RDD,那么就不要直接去父RDD执行算子,计算新的RDD的partition了
// 优先尝试使用CacheManager,去获取持久化的数据
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
// 进行rdd partition的计算
computeOrReadCheckpoint(split, context)
}
} ###org.apache.spark/CacheManager.scala def getOrCompute[T](
rdd: RDD[T],
partition: Partition,
context: TaskContext,
storageLevel: StorageLevel): Iterator[T] = { val key = RDDBlockId(rdd.id, partition.index)
logDebug(s"Looking for partition $key")
// 直接用BlockManager来获取数据,如果获取到了,直接返回就好了
blockManager.get(key) match {
case Some(blockResult) =>
// Partition is already materialized, so just return its values
val inputMetrics = blockResult.inputMetrics
val existingMetrics = context.taskMetrics
.getInputMetricsForReadMethod(inputMetrics.readMethod)
existingMetrics.incBytesRead(inputMetrics.bytesRead) val iter = blockResult.data.asInstanceOf[Iterator[T]]
new InterruptibleIterator[T](context, iter) {
override def next(): T = {
existingMetrics.incRecordsRead(1)
delegate.next()
}
}
// 如果从BlockManager获取不到数据,要进行后续的处理
// 虽然RDD持久化过,但是因为未知原因,书籍即不在本地内存或磁盘,也不在远程BlockManager的本地或磁盘
case None =>
// Acquire a lock for loading this partition
// If another thread already holds the lock, wait for it to finish return its results
// 再次调用一次BlockManager的get()方法,去获取数据,如果获取到了,那么直接返回数据,如果还是没有获取数据,那么往后走
val storedValues = acquireLockForPartition[T](key)
if (storedValues.isDefined) {
return new InterruptibleIterator[T](context, storedValues.get)
} // Otherwise, we have to load the partition ourselves
try {
logInfo(s"Partition $key not found, computing it")
// 调用computeOrReadCheckpoint()方法
// 如果rdd之前checkpoint过,那么尝试读取它的checkpoint,如果rdd没有checkpoint过,那么只能重新使用父RDD的数据,执行算子,计算一份
val computedValues = rdd.computeOrReadCheckpoint(partition, context) // If the task is running locally, do not persist the result
if (context.isRunningLocally) {
return computedValues
} // Otherwise, cache the values and keep track of any updates in block statuses
val updatedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]
// 由于走CacheManager,肯定意味着RDD是设置过持久化级别的,只是因为某些原因,持久化数据没有找到,才会到这
// 所以读取了checkpoint的数据,或者是重新计算数据之后,要用putInBlockManager()方法,将数据再BlockManager中持久化一份
val cachedValues = putInBlockManager(key, computedValues, storageLevel, updatedBlocks)
val metrics = context.taskMetrics
val lastUpdatedBlocks = metrics.updatedBlocks.getOrElse(Seq[(BlockId, BlockStatus)]())
metrics.updatedBlocks = Some(lastUpdatedBlocks ++ updatedBlocks.toSeq)
new InterruptibleIterator(context, cachedValues) } finally {
loading.synchronized {
loading.remove(key)
loading.notifyAll()
}
}
}
} ###org.apache.spark.storage/BlockManager.scala // 通过BlockManager获取数据的入口方法,优先从本地获取,如果本地没有,那么从远程获取
def get(blockId: BlockId): Option[BlockResult] = {
val local = getLocal(blockId)
if (local.isDefined) {
logInfo(s"Found block $blockId locally")
return local
}
val remote = getRemote(blockId)
if (remote.isDefined) {
logInfo(s"Found block $blockId remotely")
return remote
}
None
} ###org.apache.spark.rdd/RDD.scalal private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
// Checkpointed相关先忽略
if (isCheckpointed) firstParent[T].iterator(split, context) else compute(split, context)
} ###org.apache.spark/CacheManager.scala private def putInBlockManager[T](
key: BlockId,
values: Iterator[T],
level: StorageLevel,
updatedBlocks: ArrayBuffer[(BlockId, BlockStatus)],
effectiveStorageLevel: Option[StorageLevel] = None): Iterator[T] = { val putLevel = effectiveStorageLevel.getOrElse(level)
// 如果持久化级别,没有指定内存级别,仅仅是纯磁盘的级别
if (!putLevel.useMemory) {
/*
* This RDD is not to be cached in memory, so we can just pass the computed values as an
* iterator directly to the BlockManager rather than first fully unrolling it in memory.
*/
updatedBlocks ++=
// 直接调用blockManager的putIterator()方法,将数据写入磁盘即可
blockManager.putIterator(key, values, level, tellMaster = true, effectiveStorageLevel)
blockManager.get(key) match {
case Some(v) => v.data.asInstanceOf[Iterator[T]]
case None =>
logInfo(s"Failure to store $key")
throw new BlockException(key, s"Block manager failed to return cached value for $key!")
}
}
// 如果指定了内存级别,往下看
else {
/*
* This RDD is to be cached in memory. In this case we cannot pass the computed values
* to the BlockManager as an iterator and expect to read it back later. This is because
* we may end up dropping a partition from memory store before getting it back.
*
* In addition, we must be careful to not unroll the entire partition in memory at once.
* Otherwise, we may cause an OOM exception if the JVM does not have enough space for this
* single partition. Instead, we unroll the values cautiously, potentially aborting and
* dropping the partition to disk if applicable.
*/
// 这里会调用blockManager的unrollSafely()方法,尝试将数据写入内存
// 如果unrollSafely()方法判断数据可以写入内存,那么就将数据写入内存
// 如果unrollSafely()方法判断某些数据无法写入内存,那么只能写入磁盘文件
blockManager.memoryStore.unrollSafely(key, values, updatedBlocks) match {
case Left(arr) =>
// We have successfully unrolled the entire partition, so cache it in memory
updatedBlocks ++=
blockManager.putArray(key, arr, level, tellMaster = true, effectiveStorageLevel)
arr.iterator.asInstanceOf[Iterator[T]]
case Right(it) =>
// There is not enough space to cache this partition in memory
val returnValues = it.asInstanceOf[Iterator[T]]
// 如果有些数据实在无法写入内存,那么就判断,数据是否有磁盘级别
// 如果有的话,那么就使用磁盘级别,将数据写入磁盘文件
if (putLevel.useDisk) {
logWarning(s"Persisting partition $key to disk instead.")
val diskOnlyLevel = StorageLevel(useDisk = true, useMemory = false,
useOffHeap = false, deserialized = false, putLevel.replication)
putInBlockManager[T](key, returnValues, level, updatedBlocks, Some(diskOnlyLevel))
} else {
returnValues
}
}
}
} ###org.apache.spark.storage/MemoryStore.scala def unrollSafely(
blockId: BlockId,
values: Iterator[Any],
droppedBlocks: ArrayBuffer[(BlockId, BlockStatus)])
: Either[Array[Any], Iterator[Any]] = { // Number of elements unrolled so far
var elementsUnrolled = 0
// Whether there is still enough memory for us to continue unrolling this block
var keepUnrolling = true
// Initial per-thread memory to request for unrolling blocks (bytes). Exposed for testing.
val initialMemoryThreshold = unrollMemoryThreshold
// How often to check whether we need to request more memory
val memoryCheckPeriod = 16
// Memory currently reserved by this thread for this particular unrolling operation
var memoryThreshold = initialMemoryThreshold
// Memory to request as a multiple of current vector size
val memoryGrowthFactor = 1.5
// Previous unroll memory held by this thread, for releasing later (only at the very end)
val previousMemoryReserved = currentUnrollMemoryForThisThread
// Underlying vector for unrolling the block
var vector = new SizeTrackingVector[Any] // Request enough memory to begin unrolling
keepUnrolling = reserveUnrollMemoryForThisThread(initialMemoryThreshold) if (!keepUnrolling) {
logWarning(s"Failed to reserve initial memory threshold of " +
s"${Utils.bytesToString(initialMemoryThreshold)} for computing block $blockId in memory.")
} // Unroll this block safely, checking whether we have exceeded our threshold periodically
try {
while (values.hasNext && keepUnrolling) {
vector += values.next()
if (elementsUnrolled % memoryCheckPeriod == 0) {
// If our vector's size has exceeded the threshold, request more memory
val currentSize = vector.estimateSize()
if (currentSize >= memoryThreshold) {
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong
// Hold the accounting lock, in case another thread concurrently puts a block that
// takes up the unrolling space we just ensured here
accountingLock.synchronized {
if (!reserveUnrollMemoryForThisThread(amountToRequest)) {
// If the first request is not granted, try again after ensuring free space
// If there is still not enough space, give up and drop the partition
val spaceToEnsure = maxUnrollMemory - currentUnrollMemory
// 反复循环,判断,只要还有数据没有写入内存,而且可以继续尝试往内存中写
// 那么就判断,如果内存大小够不够存放数据,调用ensureFreeSpace()方法,尝试清空一些内存空间
if (spaceToEnsure > 0) {
val result = ensureFreeSpace(blockId, spaceToEnsure)
droppedBlocks ++= result.droppedBlocks
}
keepUnrolling = reserveUnrollMemoryForThisThread(amountToRequest)
}
}
// New threshold is currentSize * memoryGrowthFactor
memoryThreshold += amountToRequest
}
}
elementsUnrolled += 1
} if (keepUnrolling) {
// We successfully unrolled the entirety of this block
Left(vector.toArray)
} else {
// We ran out of space while unrolling the values for this block
logUnrollFailureMessage(blockId, vector.estimateSize())
Right(vector.iterator ++ values)
} } finally {
// If we return an array, the values returned do not depend on the underlying vector and
// we can immediately free up space for other threads. Otherwise, if we return an iterator,
// we release the memory claimed by this thread later on when the task finishes.
if (keepUnrolling) {
val amountToRelease = currentUnrollMemoryForThisThread - previousMemoryReserved
releaseUnrollMemoryForThisThread(amountToRelease)
}
}
}
23、CacheManager原理剖析与源码分析的更多相关文章
- 65、Spark Streaming:数据接收原理剖析与源码分析
一.数据接收原理 二.源码分析 入口包org.apache.spark.streaming.receiver下ReceiverSupervisorImpl类的onStart()方法 ### overr ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- 20、Task原理剖析与源码分析
一.Task原理 1.图解 二.源码分析 1. ###org.apache.spark.executor/Executor.scala /** * 从TaskRunner开始,来看Task的运行的工作 ...
- 18、TaskScheduler原理剖析与源码分析
一.源码分析 ###入口 ###org.apache.spark.scheduler/DAGScheduler.scala // 最后,针对stage的task,创建TaskSet对象,调用taskS ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- 22、BlockManager原理剖析与源码分析
一.原理 1.图解 Driver上,有BlockManagerMaster,它的功能,就是负责对各个节点上的BlockManager内部管理的数据的元数据进行维护, 比如Block的增删改等操作,都会 ...
- 21、Shuffle原理剖析与源码分析
一.普通shuffle原理 1.图解 假设有一个节点上面运行了4个 ShuffleMapTask,然后这个节点上只有2个 cpu core.假如有另外一台节点,上面也运行了4个ResultTask,现 ...
- 19、Executor原理剖析与源码分析
一.原理图解 二.源码分析 1.Executor注册机制 worker中为Application启动的executor,实际上是启动了这个CoarseGrainedExecutorBackend进程: ...
- 16、job触发流程原理剖析与源码分析
一.以Wordcount为例来分析 1.Wordcount val lines = sc.textFile() val words = lines.flatMap(line => line.sp ...
随机推荐
- git 学习笔记 ---安装
Git是什么? Git是目前世界上最先进的分布式版本控制系统(没有之一). 安装Git 在Linux上安装Git 首先,你可以试着输入git,看看系统有没有安装Git: $ git The progr ...
- CCF 2016-04-2 俄罗斯方块
CCF 2016-04-2 俄罗斯方块 题目 问题描述 俄罗斯方块是俄罗斯人阿列克谢·帕基特诺夫发明的一款休闲游戏. 游戏在一个15行10列的方格图上进行,方格图上的每一个格子可能已经放置了方块,或者 ...
- Windows10如何卸载OneDrive
Windows10如何卸载OneDrive 来源 https://zhuanlan.zhihu.com/p/23985905 1) 禁止onedrive自启动简单的就是在任务管理器的启动中禁用oned ...
- Unity3d与iOS交互开发
一.Unity3d To iOS: 最近要做一个商品和人体模型T台秀相关的功能,要用到Unity3D,搜集了一些资料先保存下来. 1.创建一个C#文件 SdkToIOS.cs 这是调用iOS函数的 ...
- 【转载】C#中List集合使用Last方法获取最后一个元素
在C#的List集合操作过程中,如果要获取List集合中的最后一个元素对象,则一般会先通过获取到list集合的个数Count属性,然后再使用索引的方式获取到该集合的最后一个位置的元素信息.其实在Lis ...
- DataPipeline的增量数据支持回滚功能
DataPipeline的增量数据支持回滚功能 第一步:数据任务有增量数据时,回滚按钮激活,允许用户使用该功能进行数据回滚. 第二步:点击回滚按钮,允许用户选择回滚时间或者回滚位置进行数据回滚.选择按 ...
- navicat for mysql 链接时报错:1251-Client does not support authentication protocol requested by server
客户端使用navicat for mysql.本地安装了mysql 8.0.但是在链接的时候提示: 主要原因是mysql服务器要求的认证插件版本与客户端不一致造成的. 打开mysql命令行输入如下命令 ...
- Git-fatal:remote error:You can't push to git://github.com/username/*.git use https:
注意不是git://github.com/cs942651107/TestCode.git 一个:一个@协议不一样,:的不能push 关联远程库git remote add origin git ...
- php实现人员权限管理(管理员界面)
控制人员权限用的最多的应该是OA办公自动化系统和像ERP,CRM,CMS这样的管理系统,就是通过控制用户的权限来控制其拥有的角色和功能,比如管理员可以拥有所有权限和功能,前台只能拥有登记和通报信息等. ...
- Linux命令——dmesg
参考:Linux kernel buffer ring Linux dmesg Command Tutorial for Beginners (5 Examples) 7 ‘dmesg’ Comman ...