爬虫 - 请求库之selenium
介绍
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
from selenium import webdriver
browser=webdriver.Chrome() # 谷歌浏览器
browser=webdriver.Firefox() # 火狐浏览器
browser=webdriver.PhantomJS()
browser=webdriver.Safari()
browser=webdriver.Edge()
安装
>: pip3 install selenium
有界面浏览器
下载chromdriver.exe放到python安装路径的scripts目录中即可,注意最新版本是2.38,并非2.9
国内镜像网站地址:http://npm.taobao.org/mirrors/chromedriver/2.38/
最新的版本去官网找:https://sites.google.com/a/chromium.org/chromedriver/downloads #验证安装
C:\Users\Administrator>python3
Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from selenium import webdriver
>>> driver=webdriver.Chrome() #弹出浏览器
>>> driver.get('https://www.baidu.com')
>>> driver.page_source #注意:
selenium3默认支持的webdriver是Firfox,而Firefox需要安装geckodriver
下载链接:https://github.com/mozilla/geckodriver/releases
selenium+chromedriver
推荐将chromdriver.exe放到项目录内
无界面浏览器
下载phantomjs,解压后把phantomjs.exe所在的bin目录放到环境变量
下载链接:http://phantomjs.org/download.html #验证安装
C:\Users\Administrator>phantomjs
phantomjs> console.log('egon gaga')
egon gaga
undefined
phantomjs> ^C
C:\Users\Administrator>python3
Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from selenium import webdriver
>>> driver=webdriver.PhantomJS() #无界面浏览器
>>> driver.get('https://www.baidu.com')
>>> driver.page_source
selenium+phantomjs
注意:phantomjs已经不再更新
selenium+谷歌浏览器headless模式
from selenium import webdriver from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #手动指定使
chrome_options.add_argument('disable-infobars') # 去掉 'chrome正受到自动测试软件的控制' 提示
# chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" #手动指定使
# bro=webdriver.PhantomJS() bro=webdriver.Chrome(chrome_options=chrome_options)
# bro = webdriver.Chrome()
bro.get('https://www.baidu.com') # 打开目标url
print(bro.page_source) # 获取目标页面的代码
bro.close() # 关闭浏览器,回收资源
使用
基本使用
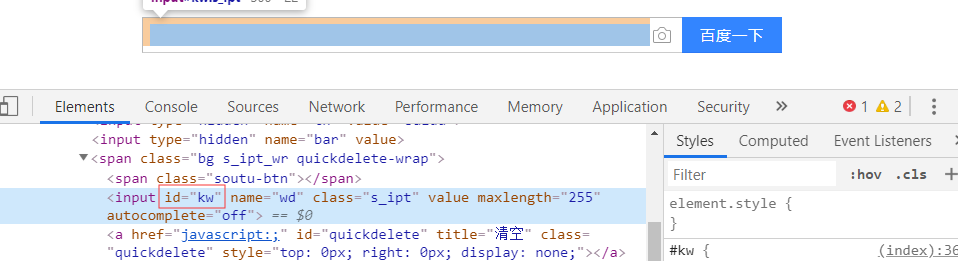
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('disable-infobars') # 去掉 'chrome正受到自动测试软件的控制' 提示 bro=webdriver.Chrome(chrome_options=chrome_options)
bro.get('https://www.baidu.com') # 打开目标url
inp = bro.find_element_by_id('kw') # 获取页面中的input框
inp.send_keys('python') # 向input框内输入内容
inp.send_keys(Keys.ENTER) # 模拟键盘回车操作
print(bro.page_source)
time.sleep(5)
bro.close() # 关闭浏览器
选择器
基本用法
# 1、find_element_by_id 根据标签ID找
# 2、find_element_by_link_text 根据连接名字找(a标签内的文字)
# 3、find_element_by_partial_link_text 根据连接名字找(a标签内的文字)模糊查找
# 4、find_element_by_tag_name 根据标签名找
# 5、find_element_by_class_name 根据类名找
# 6、find_element_by_name 根据属性名找
# 7、find_element_by_css_selector 根据css选择器找
# 8、find_element_by_xpath 根据xpath选择器找
# 强调:
# 1、上述均可以改写成find_element(By.ID,'kw')的形式(显性)
# 2、find_elements_by_xxx的形式是查找到多个元素,结果为列表
from selenium import webdriver import time
bro=webdriver.Chrome()
bro.get("http://www.baidu.com")
bro.implicitly_wait(10) dl_button=bro.find_element_by_link_text("登录") # 找到登录标签
dl_button.click() # 点击登录标签
user_login=bro.find_element_by_id('TANGRAM__PSP_10__footerULoginBtn')
user_login.click()
time.sleep(1)
input_name=bro.find_element_by_name('userName')
input_name.send_keys("30323545@qq.com")
input_password=bro.find_element_by_id("TANGRAM__PSP_10__password")
input_password.send_keys("xxxxxx")
submit_button=bro.find_element_by_id('TANGRAM__PSP_10__submit')
time.sleep(1)
submit_button.click() time.sleep(100) print(bro.get_cookies())
bro.close() #显示等待和隐示等待
#隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
# browser.implicitly_wait(10) 表示等待所有, #显式等待:显式地等待某个元素被加载
# wait=WebDriverWait(browser,10)
# wait.until(EC.presence_of_element_located((By.ID,'content_left')))
xpath
doc='''
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html' a="xxx">Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html' class='li'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html' class='li li-item' name='items'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
<a href='image6.html' name='items'><span><h5>test</h5></span>Name: My image 6 <br /><img src='image6_thumb.jpg' /></a>
</div>
</body>
</html>
'''
from lxml import etree html=etree.HTML(doc)
# html=etree.parse('search.html',etree.HTMLParser())
# 1 所有节点
a=html.xpath('//*') #匹配所有标签
# 2 指定节点(结果为列表)
# a=html.xpath('//head')
# 3 子节点,子孙节点
a=html.xpath('//div/a')
a=html.xpath('//body/a') #无数据
a=html.xpath('//body//a')
# 4 父节点
# a=html.xpath('//body//a[@href="image1.html"]/..')
a=html.xpath('//body//a[1]/..') #从1开始
# 也可以这样
a=html.xpath('//body//a[1]/parent::*')
# 5 属性匹配
a=html.xpath('//body//a[@href="image1.html"]') # 6 文本获取
a=html.xpath('//body//a[@href="image1.html"]/text()')
a=html.xpath('//body//a/text()') # 7 属性获取
# a=html.xpath('//body//a/@href')
# # 注意从1 开始取(不是从0)
a=html.xpath('//body//a[2]/@href')
# 8 属性多值匹配
# a 标签有多个class类,直接匹配就不可以了,需要用contains
# a=html.xpath('//body//a[@class="li"]')
a=html.xpath('//body//a[contains(@class,"li")]/text()')
# a=html.xpath('//body//a[contains(@class,"li")]/text()')
# 9 多属性匹配
a=html.xpath('//body//a[contains(@class,"li") or @name="items"]')
a=html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()')
a=html.xpath('//body//a[contains(@class,"li")]/text()')
# 10 按序选择
a=html.xpath('//a[2]/text()')
a=html.xpath('//a[2]/@href')
# 取最后一个
a=html.xpath('//a[last()]/@href')
# 位置小于3的
a=html.xpath('//a[position()<3]/@href')
# 倒数第二个
a=html.xpath('//a[last()-2]/@href')
# 11 节点轴选择
# ancestor:祖先节点
# 使用了* 获取所有祖先节点
a=html.xpath('//a/ancestor::*')
# # 获取祖先节点中的div
a=html.xpath('//a/ancestor::div')
# attribute:属性值
a=html.xpath('//a[1]/attribute::*')
# child:直接子节点
a=html.xpath('//a[1]/child::*')
# descendant:所有子孙节点
a=html.xpath('//a[6]/descendant::*')
# following:当前节点之后所有节点
a=html.xpath('//a[1]/following::*')
a=html.xpath('//a[1]/following::*[1]/@href')
# following-sibling:当前节点之后同级节点
a=html.xpath('//a[1]/following-sibling::*')
a=html.xpath('//a[1]/following-sibling::a')
a=html.xpath('//a[1]/following-sibling::*[2]/text()')
a=html.xpath('//a[1]/following-sibling::*[2]/@href') print(a)
#官网链接:http://selenium-python.readthedocs.io/locating-elements.html
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
import time driver=webdriver.PhantomJS()
driver.get('https://doc.scrapy.org/en/latest/_static/selectors-sample1.html')
# wait=WebDriverWait(driver,3)
driver.implicitly_wait(3) #使用隐式等待 try:
# find_element_by_xpath
#//与/
# driver.find_element_by_xpath('//body/a') # 开头的//代表从整篇文档中寻找,body之后的/代表body的儿子,这一行找不到就会报错了 driver.find_element_by_xpath('//body//a') # 开头的//代表从整篇文档中寻找,body之后的//代表body的子子孙孙
driver.find_element_by_css_selector('body a') ```
#取第n个
res1=driver.find_elements_by_xpath('//body//a[1]') #取第一个a标签
print(res1[0].text) #按照属性查找,下述三者查找效果一样
res1=driver.find_element_by_xpath('//a[5]')
res2=driver.find_element_by_xpath('//a[@href="image5.html"]')
res3=driver.find_element_by_xpath('//a[contains(@href,"image5")]') #模糊查找
print('==>', res1.text)
print('==>',res2.text)
print('==>',res3.text)
``` ```
#其他
res1=driver.find_element_by_xpath('/html/body/div/a')
print(res1.text) res2=driver.find_element_by_xpath('//a[img/@src="data:image3_thumb.jpg"]') #找到子标签img的src属性为image3_thumb.jpg的a标签
print(res2.tag_name,res2.text) res3 = driver.find_element_by_xpath("//input[@name='continue'][@type='button']") #查看属性name为continue且属性type为button的input标签
res4 = driver.find_element_by_xpath("//*[@name='continue'][@type='button']") #查看属性name为continue且属性type为button的所有标签
``` ```
time.sleep(5)
``` finally:
driver.close()
等待元素被加载
1、selenium只是模拟浏览器的行为,而浏览器解析页面是需要时间的(执行css,js),一些元素可能需要过一段时间才能加载出来,为了保证能查找到元素,必须等待
2、等待的方式分两种:
隐式等待:在browser.get('xxx')前就设置,针对所有元素有效
显式等待:在browser.get('xxx')之后设置,只针对某个元素有效
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() #隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
browser.implicitly_wait(10) browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER) contents=browser.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错
print(contents) browser.close() 隐式等待
隐式等待
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome()
browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER) #显式等待:显式地等待某个元素被加载
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left'))) contents=browser.find_element(By.CSS_SELECTOR,'#content_left')
print(contents) browser.close() 显式等待
显式等待
元素交互操作
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome()
browser.get('https://www.amazon.cn/')
wait=WebDriverWait(browser,10) input_tag=wait.until(EC.presence_of_element_located((By.ID,'twotabsearchtextbox')))
input_tag.send_keys('iphone 8')
button=browser.find_element_by_css_selector('#nav-search > form > div.nav-right > div > input')
button.click() import time
time.sleep(3) input_tag=browser.find_element_by_id('twotabsearchtextbox')
input_tag.clear() #清空输入框
input_tag.send_keys('iphone7plus')
button=browser.find_element_by_css_selector('#nav-search > form > div.nav-right > div > input')
button.click() # browser.close() 点击,清空
点击 清空
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time driver = webdriver.Chrome()
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
wait=WebDriverWait(driver,3)
# driver.implicitly_wait(3) # 使用隐式等待 try:
driver.switch_to.frame('iframeResult') ##切换到iframeResult
sourse=driver.find_element_by_id('draggable')
target=driver.find_element_by_id('droppable') ```
#方式一:基于同一个动作链串行执行
# actions=ActionChains(driver) #拿到动作链对象
# actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
# actions.perform() #方式二:不同的动作链,每次移动的位移都不同
``` ActionChains(driver).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x'] ```
track=0
while track < distance:
ActionChains(driver).move_by_offset(xoffset=2,yoffset=0).perform()
track+=2 ActionChains(driver).release().perform() time.sleep(10)
``` finally:
driver.close() Action Chains
ActionChains
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 try:
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('alert("hello world")') #打印警告
finally:
browser.close() 在交互动作比较难实现的时候可以自己写JS(万能方法)
execute_script
#模拟浏览器的前进后退
import time
from selenium import webdriver browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.get('https://www.taobao.com')
browser.get('http://www.sina.com.cn/') browser.back()
time.sleep(10)
browser.forward()
browser.close() 模拟浏览器的前进后退
模拟浏览器的前进后退
#cookies
from selenium import webdriver browser=webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'k1':'xxx','k2':'yyy'})
print(browser.get_cookies()) # browser.delete_all_cookies() cookies
get_cookies
#选项卡管理:切换选项卡,有js的方式windows.open,有windows快捷键:ctrl+t等,最通用的就是js的方式
import time
from selenium import webdriver browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()') print(browser.window_handles) #获取所有的选项卡
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(10)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.sina.com.cn')
browser.close() 选项卡管理
选项卡管理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException try:
browser=webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframssseResult') except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
browser.close() 异常处理
异常处理
练习
from selenium import webdriver
from selenium.webdriver.common.keys import Keys #键盘按键操作
import time
bro=webdriver.Chrome()
bro.get("https://www.xx.com")
bro.implicitly_wait(10) def get_goods(bro):
print("------------------------------------")
goods_li = bro.find_elements_by_class_name('gl-item')
for good in goods_li:
img_url = good.find_element_by_css_selector('.p-img a img').get_attribute('src')
if not img_url:
img_url = 'https:' + good.find_element_by_css_selector('.p-img a img').get_attribute('data-lazy-img')
url = good.find_element_by_css_selector('.p-img a').get_attribute('href')
price = good.find_element_by_css_selector('.p-price i').text
name = good.find_element_by_css_selector('.p-name em').text.replace('\n', '')
commit = good.find_element_by_css_selector('.p-commit a').text
print('''
商品链接:%s
商品图片:%s
商品名字:%s
商品价格:%s
商品评论数:%s ''' % (url, img_url, name, price, commit)) next_page = bro.find_element_by_partial_link_text("下一页")
time.sleep(1)
next_page.click()
time.sleep(1)
get_goods(bro)
input_search=bro.find_element_by_id('key')
input_search.send_keys("性感内衣")
input_search.send_keys(Keys.ENTER) #进入了另一个页面
try:
get_goods(bro)
except Exception as e:
print("结束")
finally:
bro.close()
爬取商城产品信息
#破解知乎登录
from requests_html import HTMLSession #请求解析库
import base64 #base64解密加密库
from PIL import Image #图片处理库
import hmac #加密库
from hashlib import sha1 #加密库
import time
from urllib.parse import urlencode #url编码库
import execjs #python调用node.js
from http import cookiejar class Spider():
def __init__(self):
self.session = HTMLSession()
self.session.cookies = cookiejar.LWPCookieJar() #使cookie可以调用save和load方法
self.login_page_url = 'https://www.zhihu.com/signin?next=%2F'
self.login_api = 'https://www.zhihu.com/api/v3/oauth/sign_in'
self.captcha_api = 'https://www.zhihu.com/api/v3/oauth/captcha?lang=en'
self.headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER',
} self.captcha ='' #存验证码
self.signature = '' #存签名 # 首次请求获取cookie
def get_base_cookie(self):
self.session.get(url=self.login_page_url, headers=self.headers) # 处理验证码
def deal_captcha(self):
r = self.session.get(url=self.captcha_api, headers=self.headers)
r = r.json()
if r.get('show_captcha'):
while True:
r = self.session.put(url=self.captcha_api, headers=self.headers)
img_base64 = r.json().get('img_base64')
with open('captcha.png', 'wb') as f:
f.write(base64.b64decode(img_base64))
captcha_img = Image.open('captcha.png')
captcha_img.show()
self.captcha = input('输入验证码:')
r = self.session.post(url=self.captcha_api, data={'input_text': self.captcha},
headers=self.headers)
if r.json().get('success'):
break def get_signature(self):
# 生成加密签名
a = hmac.new(b'd1b964811afb40118a12068ff74a12f4', digestmod=sha1)
a.update(b'password')
a.update(b'c3cef7c66a1843f8b3a9e6a1e3160e20')
a.update(b'com.zhihu.web')
a.update(str(int(time.time() * 1000)).encode('utf-8'))
self.signature = a.hexdigest() def post_login_data(self):
data = {
'client_id': 'c3cef7c66a1843f8b3a9e6a1e3160e20',
'grant_type': 'password',
'timestamp': str(int(time.time() * 1000)),
'source': 'com.zhihu.web',
'signature': self.signature,
'username': '',
'password': '',
'captcha': self.captcha,
'lang': 'en',
'utm_source': '',
'ref_source': 'other_https://www.zhihu.com/signin?next=%2F',
} headers = {
'x-zse-83': '3_2.0',
'content-type': 'application/x-www-form-urlencoded',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER',
} data = urlencode(data)
with open('ttt.js', 'rt', encoding='utf-8') as f:
js = execjs.compile(f.read())
data = js.call('b', data)
print(data) r = self.session.post(url=self.login_api, headers=headers, data=data)
if r.status_code == 201:
self.session.cookies.save('mycookie')
print('登录成功')
else:
print('登录失败')
def login(self):
self.get_base_cookie()
self.deal_captcha()
self.get_signature()
self.post_login_data() if __name__ == '__main__':
zhihu_spider = Spider()
zhihu_spider.login()
爬虫 - 请求库之selenium的更多相关文章
- python爬虫请求库之selenium模块
一 介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器 ...
- 爬虫请求库之selenium
一.介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作, ...
- 爬虫——请求库之selenium模块
阅读目录 一 介绍 二 安装 三 基本使用 四 选择器 五 等待元素被加载 六 元素交互操作 七 其他 八 项目练习 一 介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解 ...
- 爬虫请求库之selenium模块
一 安装 #安装:selenium+chromedriver pip3 install selenium 下载chromdriver.exe放到python安装路径的scripts目录中即可,注意最新 ...
- 爬虫请求库——requests
请求库,即可以模仿浏览器对网站发起请求的模块(库). requests模块 使用requests可以模拟浏览器的请求,requests模块的本质是封装了urllib3模块的功能,比起之前用到的urll ...
- 爬虫----爬虫请求库selenium
一 介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作, ...
- 爬虫请求库——selenium
selenium模块 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题.selenium的缺点是效率会变得很慢. sel ...
- 爬虫请求库 requests
requests模块 阅读目录 一 介绍 二 基于GET请求 三 基于POST请求 四 响应Response 五 高级用法 一 介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到 ...
- 爬虫基础库之Selenium
1.简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作, ...
随机推荐
- Java后台使用httpclient入门HttpPost请求(form表单提交,File文件上传和传输Json数据)
一.HttpClient 简介 HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的.最新的.功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 ...
- [转帖]我花了10个小时,写出了这篇K8S架构解析
我花了10个小时,写出了这篇K8S架构解析 https://www.toutiao.com/i6759071724785893891/ 每个微服务通过 Docker 进行发布,随着业务的发展,系统 ...
- 23 Collection集合常用方法讲解
本文讲讲几个Collection的常用方法,这些方法在它的子类中也是很常用的,因此这里先拿出来单独讲解,以后它的子类中的这些方法就不再重复讲解. 几个常用方法: add() 添加一个元素 size() ...
- 简单的爬虫程序以及使用PYQT进行界面设计(包含源码解析)
由于这个是毕业设计的内容,而且还是跨专业的.爬虫程序肯定是很简单的,就是调用Yahoo的API进行爬取图片.这篇博客主要讲的是基础的界面设计. 放上源码,然后分部解析一下重要的地方.注:flickra ...
- Python使用队列实现Josephus问题
Josephus问题,在这个古老的问题中,N个深陷绝境的人一致同意通过以下方式减少生存的人数.他们围坐一圈(位置记为0~N-1)并从第一个人报数,报到M的人会被杀死, 知道最后一个人留下来.传说中Jo ...
- go 指针 通过指针修改int类型的值
指针的定义 :var p *int 取指针的值 :*p ------------------------------------------------------------------------ ...
- delphi xe10 FMX 启动参数
关于 Delphi Xe10 FMX 启动参数 需要在启动窗口前来调用 也就是在bar文件修改 如果参数多可以用json来 uses system.SysUtils; var param: stri ...
- Geoserver发布强制显示标签处理
TextSymbolizer 增加如下配置: <!-- 标签重叠也显示 --> <VendorOption name="conflictResolution" ...
- [Atcoder AGC030C]Coloring Torus
题目大意:有$k$种颜色,要求构造出一个$n\times n$的矩阵,填入这$k$种颜色,满足对于每一种颜色,其中填充这种颜色的每一个方格,满足其相连的四个格子的颜色的个数和种类相同(对于每一种颜色而 ...
- angular复习笔记1-开篇
前言 学习和使用angular已经有一段时间了.这段时间利用angular做了一个系统,算是对angular有了一个全面的认识,趁着现在有一些时间,把angular的一些知识记录一下. 安装angul ...