Centos7安装Hadoop2.7
准备
1、三台Centos7的机器:
| hostname | IP地址 | 部署规划 |
| node1 | 172.20.0.4 | NameNode、DataNode |
| node2 | 172.20.0.5 | DataNode |
| node3 | 172.20.0.6 | DataNode |
在/etc/hosts中都加上主机名解析:
172.20.0.4 node1
172.20.0.5 node2
172.20.0.6 node3
2、配置node1到三台机器的免密登录。
3、全部安装jdk8,配置JAVA_HOME。
4、官网下载安装包:hadoop-2.7.7.tar.gz(推荐去清华大学或中科大的开源镜像站)。
6、三台都创建路径/mydata/,并配置环境变量:
export HADOOP_HOME=/mydata/hadoop-2.7.
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
配置
先在node1上修改hadoop的配置,完成后再统一复制到其他节点,保证配置内容一致。
解压hadoop-2.7.7.tar.gz到/mydata/,进入/mydata/hadoop-2.7.7/etc/hadoop/,进行配置(有些文件需要去掉,template后缀,或拷贝一份重命名):
<!-- 文件名 core-site.xml -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/mydata/data/hadoop-${user.name}</value>
</property>
</configuration>
<!-- 文件名 hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
<!-- 文件名 mapred-site.xml 拷贝自mapred-site.xml.template -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
<!-- 文件名 yarn-site.xml -->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
</configuration>
<!-- 文件名 slaves -->
node1
node2
node3
| 配置项 | 含义 |
| fs.defaultFS | namenode上文件系统的地址 |
| hadoop.tmp.dir | 多个路径的基础,包括namenode和datanode的数据,默认是/tmp/hadoop-${user.name} |
| dfs.replication | 副本数,这里设为2,这样集群中共三份数据,适用日常大部分情况了 |
| yarn.resourcemanager.hostname | yarn资源管理器所在host |
| slaves | 该文件中列出的是作为从节点的datanode,若node1只打算作为namenode则不需要写进去 |
默认日志目录在$HADOOP_HOME/logs,pid文件在/tmp,可以进行修改:
# 文件名 hadoop-env.sh
export HADOOP_PID_DIR="/mydata/data/pid"
export HADOOP_LOG_DIR="/mydata/logs/hadoop"
# 文件名 yarn-env.sh
export YARN_LOG_DIR="/mydata/logs/yarn"
export YARN_PID_DIR="/mydata/data/pid"
配置完成后将hadoop程序文件拷贝到其他两台:
node1> scp -r /mydata/hadoop-2.7.7/ root@node2:/mydata/
node1> scp -r /mydata/hadoop-2.7.7/ root@node3:/mydata/
启动
需要先在node1初始化namenode(只有第一次启动前需要,除非删除了hadoop.tmp.dir下namenode的数据):
node1> hdfs namenode -format
看到 Storage directory /mydata/data/hadoop-root/dfs/name has been successfully formatted. 则表示成功。
下面先启动hdfs,后启动yarn:
node1> start-dfs.sh
node1> start-yarn.sh
| node1上用jps命令验证进程 |
NameNode、SecondaryNameNode、ResourceManager、DataNode、NodeManager |
| node2上用jps命令验证进程 |
DataNode、NodeManager |
| node3上用jps命令验证进程 |
DataNode、NodeManager |
测试
通过浏览器可以访问以下地址:
| namenode的后台 | http://node1:50070 |
| yarn资源管理的后台 | http://node1:8088 |
前者切换到 Datanodes :

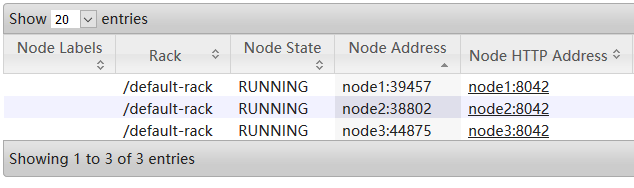
后者进入 Cluster -> Nodes :
下面执行一个官方示例(wordcount),先准备两个文件,内容如下:
# 文件名 1.txt
天空 sky
天空 sky
天空 sky # 文件名 .txt
海洋 ocean
海洋 ocean
将这两个文件上传到hdfs,然后执行任务:
# 创建路径(将root改为自己的用户名)
node1> hdfs dfs -mkdir -p /user/root/input
# 上传文件
node1> hdfs dfs -put *.txt input
# 执行wordcount任务统计文件中每个单词的数量,并等待其执行结束
node1> hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount input output
# 查看结果
node1> hdfs dfs -cat output/*
ocean 2
sky 3
天空 3
海洋 2
# 若要重复执行任务,需要删除output文件夹,或者在命令中换一个输出目录
node1> hdfs dfs -rm -r output
可以在yarn的资源管理平台 Cluster -> Applications 查看到该任务:

启用jobhistory
这个不是必须的,但可以更好的查看job的历史记录和管理job的日志。
# 文件名 mapred-env.sh
export HADOOP_MAPRED_LOG_DIR="/mydata/logs/mapred"
export HADOOP_MAPRED_PID_DIR="/mydata/data/pid"
<!-- 文件名 mapred-site.xml -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:</value>
</property>
<!-- 文件名 yarn-site.xml 日志聚合,开启后job的日志不再存到node本地,而是上传到hdfs -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
停止集群:
node1> stop-yarn.sh
node1> stop-dfs.sh
然后将修改的配置同步更新到其他所有节点,并在启动集群后启动historyserver:
node1> start-dfs.sh
node1> start-yarn.sh
node1> mr-jobhistory-daemon.sh start historyserver
# 通过jps查看进程
node1> jps
...
[pid] JobHistoryServer
...
通过浏览器访问 http://node1:19888 :

默认情况下,日志会分散在各个工作的datanode,查看非常麻烦;配置了日志聚合后则会上传到hdfs,各节点本地的会被删除,可以点击上图的 Job ID ,然后 ApplicationMaster -> logs 即可看到聚合后的日志:

在yarn的资源管理后台 http://node1:8088/cluster/apps ,点击 application 后面的 History 就可以跳转到 jobhistory:

另外,还可以通过命令行查看聚合日志:
shell> yarn logs -applicationId [application id]
yarn的资源管理后台 http://node1:8088/cluster/apps 直接就能看到 application id,而在 jobhistory 中只要将 Job ID 的job前缀替换为application即可。
over
Centos7安装Hadoop2.7的更多相关文章
- CentOS7安装Hadoop2.7完整流程
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs.mapreduce等主从关系. 1.环境,3台CentOS7,64位,Hadoo ...
- CentOS7安装Hadoop2.7完整步骤
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs.mapreduce等主从关系. 1.环境,3台CentOS7,64位,Hadoo ...
- CentOS7安装Hadoop2.7流程
准备3个虚拟机节点 其实这一步骤非常简单,如果你已经完成了第2步,此时你已经准备好了第一个虚拟节点,那第二个和第三个虚拟机节点如何准备?可能你已经想明白了,你可以按第2步的方法,再分别安装两遍lin ...
- centos7安装hadoop2.6.1,详细教程
1.我搭建的是三台centos7的环境 首先准备三个centos7(文中出现的所有的链接都是我自己的) centos7下载地址(也可以上官网自行下载):https://pan.baidu.com/s/ ...
- centos7 安装Hadoop-2.6.0-cdh5.16.1.tar.gz
准备Hadoop-2.6.0-cdh5.16.1.tar.gz 下载网址 http://archive.cloudera.com/cdh5/cdh/5/Hadoop-2.6.0-cdh5.16.1.t ...
- centos7安装hadoop2.7.7
下载hadoop-2.7.7 网址如下 https://www-eu.apache.org/dist/hadoop/core/ 移动到/opt 路径下 在/opt下新建一个文件夹,名为app mkdi ...
- 原创centos7安装hadoop2.7(转载请注明出处)
启用ip vi /etc/sysconfig/network-scripts/ifcfg-ONBOOT=yes 编辑DNS /etc/resolv.conf nameserver 114.114.11 ...
- centos7 安装hadoop2.7.6(分布式)
本文只做简单介绍,具体步骤操作请参考centos6.5 安装hadoop1.2.1亲测版 本篇只简单介绍安装步骤 1.安装目录 /usr/local/hadoop (HADOOP_HOME) 2,创建 ...
- Centos7安装Spark2.4
准备 1.hadoop已部署(若没有可以参考:Centos7安装Hadoop2.7),集群情况如下(IP地址与之前文章有变动): hostname IP地址 部署规划 node1 172.20.0.2 ...
随机推荐
- vue中methods、computed、watch区别
vue中methods.computed.watch区别methods:事件调用的钩子 computed:{ // 计算属性是根据他依赖的值计算的,当依赖值发生变化,其跟着改变 // 计算属性是依赖缓 ...
- [转帖]70亿!以色列间谍产品公司NSO要被卖掉了
70亿!以色列间谍产品公司NSO要被卖掉了 2017-06-14 11:11 https://www.sohu.com/a/148739327_257305 E安全6月14日讯以色列的网络能力处于世界 ...
- python学习-30 总结
小结 1.map函数: 处理序列中的每个元素,得到结果是一个‘列表’,该‘列表’元素个数及位置与原来一样 2.filter:遍历序列中的每个元素,判断每个元素得到的布尔值,如果是True则留下来,例如 ...
- robotframework_百度登陆
** Settings *** Library Selenium2Library *** Test Cases *** login Open Browser https://www.baidu.com ...
- Sqlserver 总结(2) 存储过程
目录 写在前面 什么是存储过程 存储过程的优点 存储过程的分类 1.只返回单一记录集的存储过程 2.没有输入输出的存储过程 3.有返回值的存储过程 4.有输入参数和输出参数的存储过程 5.同时具有返回 ...
- mybatis中参数为list集合时使用 mybatis in查询
mybatis中参数为list集合时使用 mybatis in查询 一.问题描述mybatis sql查询时,若遇到多个条件匹配一个字段,sql 如: select * from user where ...
- 如何在linux中重置Mysql访问密码
目录 跳过密码认证 重启MySQL: 用sql来修改root的密码 去掉'跳过密码'代码 假设我们使用的是root账户. 跳过密码认证 重置密码的第一步就是跳过MySQL的密码认证过程,方法如下: # ...
- onActivityResult方法的使用
转发自:https://blog.csdn.net/hacker_crazy/article/details/78345450 在进行界面间的跳转和传递数据的时候,我们有的时候要获得跳转之后界面传递回 ...
- js事件(十二)
一.事件三要素1.事件目标[谁触发的该事件(引起该事件触发的源头:target)]2.事件处理程序[处理相应事件的函数]3.事件对象[触发事件产生的携带事件信息的对象] 二.事件流[从页面中接受事件的 ...
- react diff
传统diff 通过循环递归对节点的依次对比,复杂度是O(n3) react diff react对传统diff进行了优化,将复杂度降为O(n) react基于这几个前提对diff进行了优化: 忽略跨层 ...