Spark运行原理【史上最详细】
https://blog.csdn.net/lovechendongxing/article/details/81746988
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。
1、Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等)
2、Cluster manager分配应用程序执行需要的资源,在Worker节点上创建Executor
3、SparkContext 将程序代码(jar包或者python文件)和Task任务发送给Executor执行,并收集结果给Driver。
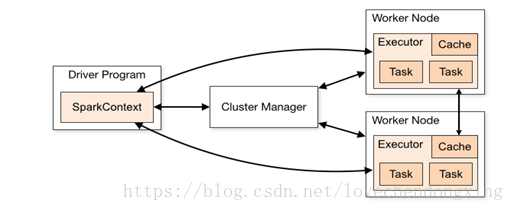
图1 Spark运行原理图
Spark详细运行过程如下图
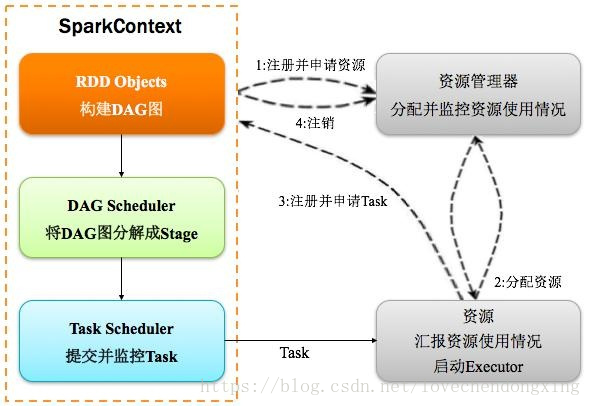
图2 Spark运行详细流程
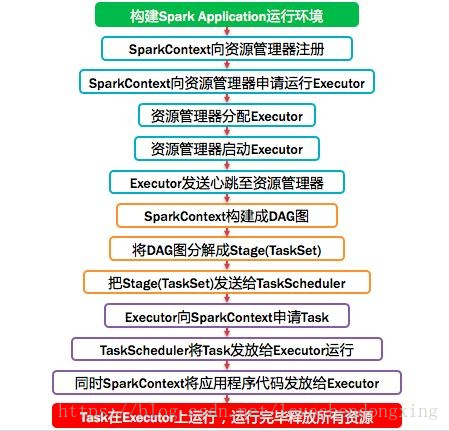
图3 Spark运行流程描述
涉及的几个定义和详细的运行过程如下:
1、Application:Spark应用程序
指的是用户编写的Spark应用程序,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
Spark应用程序,由一个或多个作业JOB组成,如下图所示。
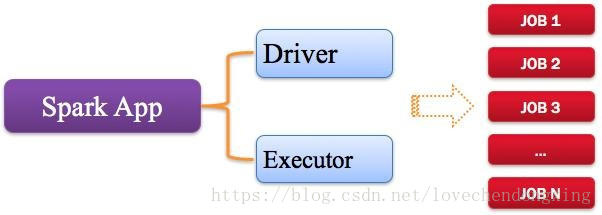
图4 Spark应用程序组成
2、Driver:驱动程序
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示。
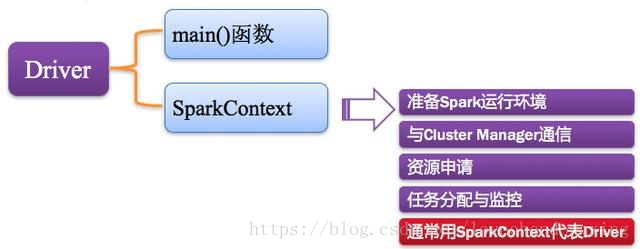
图5 Driver驱动程序组成
3、Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Haddop Yarn,由Yarn中的ResearchManager负责资源的分配;Messos,由Messos中的Messos Master负责资源管理。
4、Executor:执行器
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示。
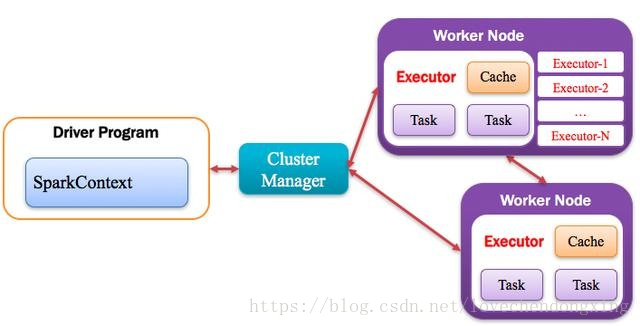
图6 Executor运行原理
5、Worker:计算节点
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示。
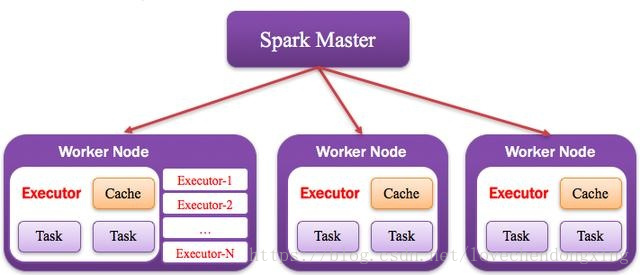
图7 Worker运行原理
6、DAGScheduler:有向无环图调度器
基于DAG划分Stage 并以TaskSet的形势提交Stage给TaskScheduler;负责将作业拆分成不同阶段的具有依赖关系的多批任务;最重要的任务之一就是:计算作业和任务的依赖关系,制定调度逻辑。在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler。
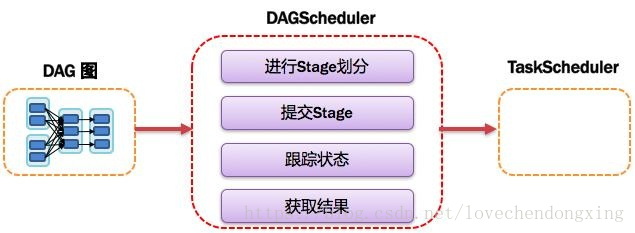
图8 DAGScheduler图解
7、TaskScheduler:任务调度器
将Taskset提交给worker(集群)运行并回报结果;负责每个具体任务的实际物理调度。如图所示。
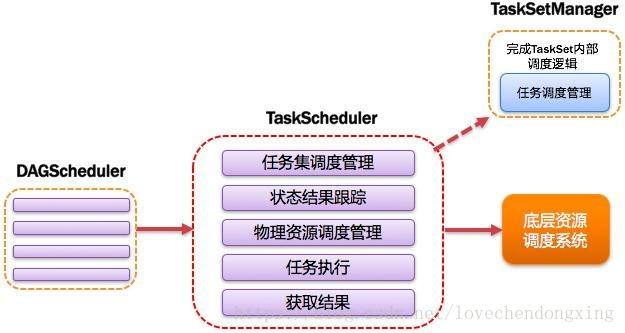
图9 TaskScheduler图解
8、Job:作业
由一个或多个调度阶段所组成的一次计算作业;包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation。如图所示。
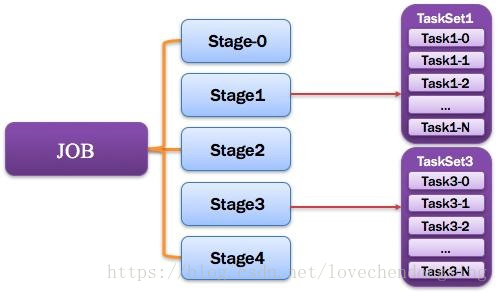
图10 Job图解
9、Stage:调度阶段
一个任务集对应的调度阶段;每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;Stage分成两种类型ShuffleMapStage、ResultStage。如图所示。
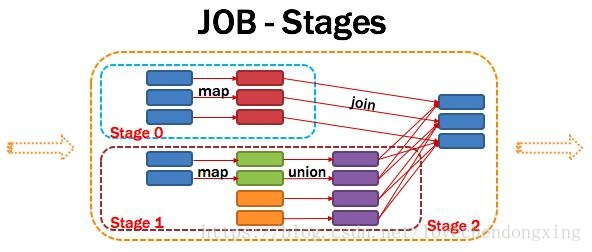
图11 Stage图解
Application多个job多个Stage:Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:Stage划分的依据就是宽依赖,何时产生宽依赖,reduceByKey, groupByKey等算子,会导致宽依赖的产生。
核心算法:从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。Spark内核会从触发Action操作的那个RDD开始从后往前推,首先会为最后一个RDD创建一个stage,然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。然后依次类推,继续继续倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
将DAG划分为Stage剖析:如上图,从HDFS中读入数据生成3个不同的RDD,通过一系列transformation操作后再将计算结果保存回HDFS。可以看到这个DAG中只有join操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage. 同时我们可以注意到,在图中Stage2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,通过map操作生成的partition可以不用等待整个RDD计算结束,而是继续进行union操作,这样大大提高了计算的效率。
10、TaskSet:任务集
由一组关联的,但相互之间没有Shuffle依赖关系的任务所组成的任务集。如图所示。
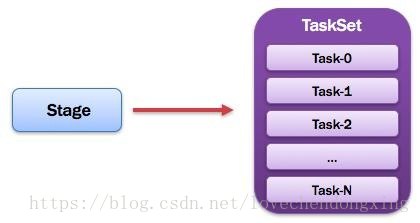
图12 Stage图解
提示:
1)一个Stage创建一个TaskSet;
2)为Stage的每个Rdd分区创建一个Task,多个Task封装成TaskSet
11、Task:任务
被送到某个Executor上的工作任务;单个分区数据集上的最小处理流程单元(单个stage内部根据操作数据的分区数划分成多个task)。如图所示。
图13 Task图解
总体如图所示:
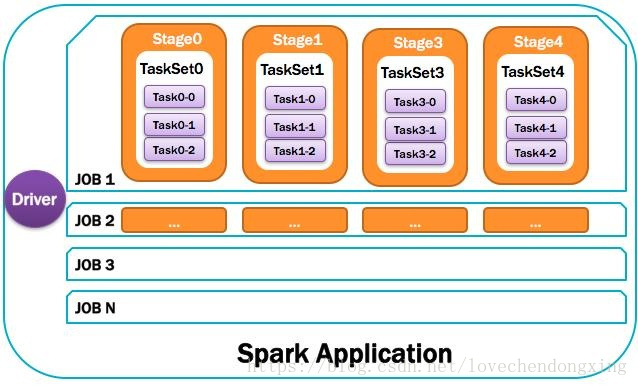
图14 汇总图解
Spark运行原理【史上最详细】的更多相关文章
- 转 史上最详细的Hadoop环境搭建
GitChat 作者:鸣宇淳 原文:史上最详细的Hadoop环境搭建 关注公众号:GitChat 技术杂谈,一本正经的讲技术 [不要错过文末活动哦] 前言 Hadoop在大数据技术体系中的地位至关重要 ...
- 史上最详细Windows版本搭建安装React Native环境配置 转载,比官网的靠谱亲测可用
史上最详细Windows版本搭建安装React Native环境配置 2016/01/29 | React Native技术文章 | Sky丶清| 95条评论 | 33530 views ...
- 史上最详细的Android Studio系列教程一--下载和安装
链接地址:http://segmentfault.com/a/1190000002401964#articleHeader4 原文链接:http://stormzhang.com/devtools/2 ...
- Spark核心技术原理透视一(Spark运行原理)
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位. Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势.无论是性能,还是方案的统一 ...
- 测试思想-测试设计 史上最详细测试用例设计实践总结 Part2
史上最详细测试用例设计实践总结 by:授客 QQ:1033553122 -------------------------接 Part1-------------------------- 方法:这里 ...
- 史上最详细的C语言和Python的插入排序算法
史上最详细的C语言和Python的插入排序算法插入排序原理:所谓插入排序,就像我们在打牌(斗地主)时,整理我们自己手中自己的牌一样,就像是2,1,3,9,J,K,5,4,这四张牌.我们要把它其中的几张 ...
- 史上最详细的XGBoost实战
史上最详细的XGBoost实战 0. 环境介绍 Python 版 本: 3.6.2 操作系统 : Windows 集成开发环境: PyCharm 1. 安装Python环境 安装Python 首先,我 ...
- 史上最详细mac安装Qt教程
史上最详细mac安装Qt教程,小白看过来! 这是一篇非常适合Qt入门小白的的安装Qt教程,因为这学期我们小组的一个关于高速救援的项目要用到Qt与web进行交互式展现相关的图像,由于没有MSVC这个插件 ...
- 史上最详细“截图”搭建Hexo博客并部署到Github
http://jingyan.baidu.com/article/d8072ac47aca0fec95cefd2d.html 大家也搭建过博客,很多时候,按着教程来做就可以了,但是我当时为了搭建Hex ...
- 史上最详细“截图”搭建Hexo博客——For Windows
http://angelen.me/2015/01/23/2015-01-23-%E5%8F%B2%E4%B8%8A%E6%9C%80%E8%AF%A6%E7%BB%86%E2%80%9C%E6%88 ...
随机推荐
- [E2E_L9]GOMFCTemplate的融合进阶
在前面出现的融合方法中,最突出的问题就是每次运算,都需要将整个推断的过程全部操作一遍,这样肯定是费时间的--所以我们需要将能够独立的地方独立出来,但是这个过中非常容易出现溢出的错误--经过一段时间的尝 ...
- leetcode 10. Regular Expression Matching 、44. Wildcard Matching
10. Regular Expression Matching https://www.cnblogs.com/grandyang/p/4461713.html class Solution { pu ...
- 【转载】 tensorflow的单层静态与动态RNN比较
原文地址: https://www.jianshu.com/p/1b1ea45fab47 yanghedada -------------------------------------------- ...
- linux列出当前目录下的所有的目录?
### 列出当前目录下的所有目录: [root@localhost ~]# ls -ld * #列出所有的文件 drwxr-xr-x. root root Nov : elasticsearch d ...
- nodejs 开发时,学用的热更新工具 nodemon
开发用最多的是重启再刷新页面,那热更新少不了, 工具有很多常用唯 nodemon 了, 安装: npm install -g nodemon // 建议全局安装,开发时用的工具 使用: nodemon ...
- Python的传递引用
在研究神经网络的反向传播的时候,不解一点,就是修改的是神经网络的paramets,为什么影响内部的神经元(层),比如Affine层:因为除了创建的时候,使用params作为Affine层的构造函数参数 ...
- Samba通过ad域进行认证并限制空间大小
最近正在做单位电脑的AD域管理. 为漫游用户文件,研究配置Samba通过ad域进行认证并限制空间大小. 参考了很多资料,现总结如下: DC:windows server 2016(配置安装域控制器)略 ...
- MongoDB的局域网连接问题
问题前两天在本机连接虚拟机的MongoDB,总是连接拒绝 上网百度了一堆,找到一些看似解释,实则不一定管用的玩意. 自己找到一个解法是改etc/mongodb.conf文件,把bindIp的127.0 ...
- LeetCode Top Interview Questions
LeetCode Top Interview Questions https://leetcode.com/problemset/top-interview-questions/ # No. Titl ...
- [转帖]中兴GoldenDB数据库开始了第一轮中信银行核心业务系统迁移落地
中兴GoldenDB数据库开始了第一轮中信银行核心业务系统迁移落地 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https:// ...