数据结构与算法—simhash
引入
随着信息爆炸时代的来临,互联网上充斥着着大量的近重复信息,有效地识别它们是一个很有意义的课题。
例如,对于搜索引擎的爬虫系统来说,收录重复的网页是毫无意义的,只会造成存储和计算资源的浪费;
同时,展示重复的信息对于用户来说也并不是最好的体验。造成网页近重复的可能原因主要包括:
- 镜像网站
- 内容复制
- 嵌入广告
- 计数改变
- 少量修改
一个简化的爬虫系统架构如下图所示:
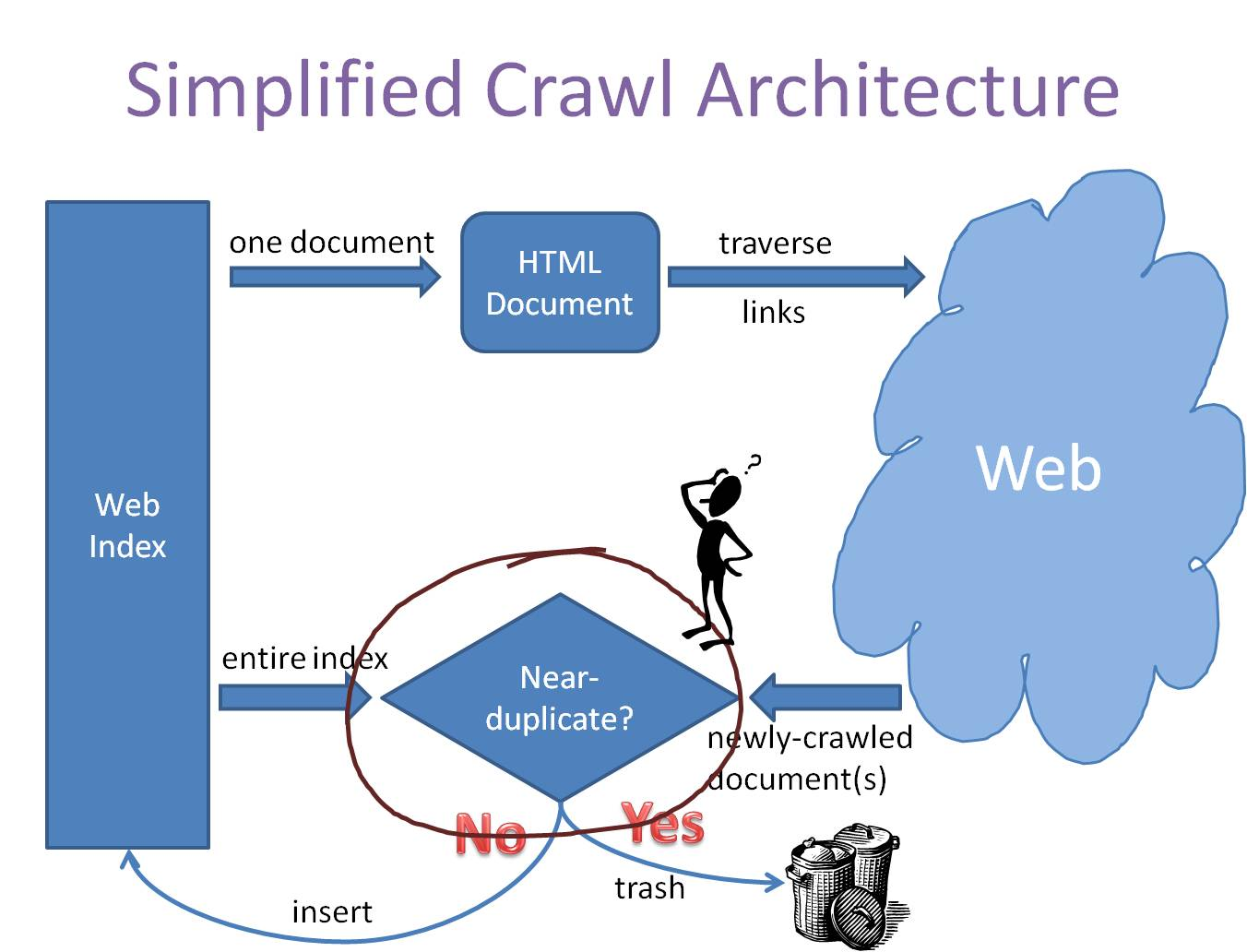
事实上,传统比较两个文本相似性的方法,大多是将文本分词之后,转化为特征向量距离的度量,比如常见的欧氏距离、海明距离或者余弦角度等等。两两比较固然能很好地适应,但这种方法的一个最大的缺点就是,无法将其扩展到海量数据。例如,试想像Google那种收录了数以几十亿互联网信息的大型搜索引擎,每天都会通过爬虫的方式为自己的索引库新增的数百万网页,如果待收录每一条数据都去和网页库里面的每条记录算一下余弦角度,其计算量是相当恐怖的。
我们考虑采用为每一个web文档通过hash的方式生成一个指纹(fingerprint)。传统的加密式hash,比如md5,其设计的目的是为了让整个分布尽可能地均匀,输入内容哪怕只有轻微变化,hash就会发生很大地变化。我们理想当中的哈希函数,需要对几乎相同的输入内容,产生相同或者相近的hashcode,换句话说,hashcode的相似程度要能直接反映输入内容的相似程度。很明显,前面所说的md5等传统hash无法满足我们的需求。
simhash的原理
simhash是locality sensitive hash(局部敏感哈希)的一种,最早由Moses Charikar在《similarity estimation techniques from rounding algorithms》一文中提出。Google就是基于此算法实现网页文件查重的。simhash算法的主要思想是降维,将高维的特征向量映射成一个f-bit的指纹(fingerprint),通过比较两篇文章的f-bit指纹的Hamming Distance来确定文章是否重复或者高度近似。我们假设有以下三段文本:
- the cat sat on the mat
- the cat sat on a mat
- we all scream for ice cream
使用传统hash可能会产生如下的结果:
irb(main):006:0> p1 = 'the cat sat on the mat'
irb(main):005:0> p2 = 'the cat sat on a mat'
irb(main):007:0> p3 = 'we all scream for ice cream'
irb(main):007:0> p1.hash
=> 415542861
irb(main):007:0> p2.hash
=> 668720516
irb(main):007:0> p3.hash
=> 767429688
使用simhash会应该产生类似如下的结果:
irb(main):003:0> p1.simhash
=> 851459198
00110010110000000011110001111110
irb(main):004:0> p2.simhash
=> 847263864
00110010100000000011100001111000
irb(main):002:0> p3.simhash
=> 984968088
00111010101101010110101110011000
海明距离的定义,为两个二进制串中不同位的数量。上述三个文本的simhash结果,其两两之间的海明距离为(p1,p2)=4,(p1,p3)=16以及(p2,p3)=12。事实上,这正好符合文本之间的相似度,p1和p2间的相似度要远大于与p3的。
如何实现这种hash算法呢?图解如下:

算法过程大概如下(5个步骤:分词、hash、加权、合并、降维):
- 将Doc进行关键词抽取(其中包括分词和计算权重),抽取出n个(关键词,权重)对, 即图中的
(feature, weight)们。 记为feature_weight_pairs = [fw1, fw2 … fwn],其中fwn = (feature_n,weight_n)。 hash_weight_pairs = [ (hash(feature), weight) for feature, weight in feature_weight_pairs ]生成图中的(hash,weight)们, 此时假设hash生成的位数bits_count = 6(如图);- 然后对
hash_weight_pairs进行位的纵向累加,如果该位是1,则+weight,如果是0,则-weight,最后生成bits_count个数字,如图所示是[13, 108, -22, -5, -32, 55], 这里产生的值和hash函数所用的算法相关。 [13,108,-22,-5,-32,55] -> 110001这个就很简单啦,正1负0。
海明距离
当我们算出所有doc的simhash值之后,需要计算doc A和doc B之间是否相似的条件是:A和B的海明距离是否小于等于n,这个n值根据经验一般取值为3,
那海明距离怎么计算呢?二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
举例如下:
A = 100111;
B = 101010;
hamming_distance(A, B) = count_1(A xor B) = count_1(001101) = 3;
simhash本质上是局部敏感性的hash,和md5之类的不一样。 正因为它的局部敏感性,所以我们可以使用海明距离来衡量simhash值的相似度。
参考&推荐:
1、http://www.lanceyan.com/tag/simhash
2、https://blog.csdn.net/lengye7/article/details/79789206
3、http://yanyiwu.com/work/2014/01/30/simhash-shi-xian-xiang-jie.html
4、https://blog.csdn.net/heiyeshuwu/article/details/44117473
数据结构与算法—simhash的更多相关文章
- 开启基本数据结构和算法之路--初识Graphviz
在我的Linux刀耕开荒阶段,就想开始重拾C,利用C实现常用的基本数据结构和算法,而数据结构和算法的掌握的熟练程度正是程序的初学者与职业程序员的分水岭. 那么怎么开启这一段历程呢? 按照软件工程的思想 ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- 数据结构与算法JavaScript (一) 栈
序 数据结构与算法JavaScript这本书算是讲解得比较浅显的,优点就是用javascript语言把常用的数据结构给描述了下,书中很多例子来源于常见的一些面试题目,算是与时俱进,业余看了下就顺便记录 ...
- 数据结构与算法 Big O 备忘录与现实
不论今天的计算机技术变化,新技术的出现,所有都是来自数据结构与算法基础.我们需要温故而知新. 算法.架构.策略.机器学习之间的关系.在过往和技术人员交流时,很多人对算法和架构之间的关系感 ...
- 《java数据结构和算法》读书笔记
大学时并不是读计算机专业的, 之前并没有看过数据结构和算法,这是我第一次看. 从数据结构方面来说: 数组:最简单,遍历.查找很快:但是大小固定,不利于扩展 ...
- MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- javascript数据结构与算法--高级排序算法
javascript数据结构与算法--高级排序算法 高级排序算法是处理大型数据集的最高效排序算法,它是处理的数据集可以达到上百万个元素,而不仅仅是几百个或者几千个.现在我们来学习下2种高级排序算法-- ...
随机推荐
- html--前端基本标签内容讲解
body里面分为两类标签:块级标签和内联标签. 1.块级标签:<p><h1><table><ol><ul><form><d ...
- time、datetime
目录 time() datetime() time() python的时间模块 时间戳: 给电脑看的.1970-01-01 00:00:00到当前时间,按秒计算 格式化时间(Format String ...
- [PHP] 一个免费、开源的基于tp5+layui2.1.5开发的快速开发框架
推荐 一个免费.开源的基于tp5+layui2.1.5开发的快速开发框架,既可以用来学习,也可以用来实际项目的快速开发: 码云下载:https://gitee.com/eduaskcms/eduask ...
- TCP、UDP和HTTP区别详解
http:是用于www浏览的一个协议.tcp:是机器之间建立连接用的到的一个协议. 1.TCP/IP是个协议组,可分为三个层次:网络层.传输层和应用层.在网络层有IP协议.ICMP协议.ARP协议.R ...
- LOJ3124 CTS2019 氪金手游 概率、容斥、树形DP
传送门 D2T3签到题可真是IQ Decrease,概率独立没想到然后就20pts滚粗了 注意题目是先对于所有点rand一个权值\(w\)然后再抽卡. 先考虑给出的关系是一棵外向树的情况.那么我们要求 ...
- 搭建 Docker Swarm 集群
准备三台主机 A:192.168.1.5 B:192.168.1.7 C:192.168.1.10 Docker Swarm集群中的节点主机开放以下三个端口 2377端口, 用于集群管理通信 ...
- 在spring管理的类的要注意问题
特别时写框架的时候, 注意依赖引用,类的成员变量不要随便new,看spring容器中是否管理过,new出来的时其他的对象了
- ubuntu更改源为aliyun的源;ROS改为新加坡源
在修改source.list前,最好先备份一份 sudo cp /etc/apt/sources.list /etc/apt/sources.list.old 执行命令打开source.list文件 ...
- [转帖]深入理解latch: cache buffers chains
深入理解latch: cache buffers chains http://blog.itpub.net/12679300/viewspace-1244578/ 原创 Oracle 作者:wzq60 ...
- c++11多线程记录0
两种并发编程模型 多进程 进程间通信常用的几种方式: 文件 管道 消息队列 多线程 一个进程中存在的多个线程,通常通过共享内存来通信,(说的非常非常粗俗,就是通过类似"全局变量"的 ...