spark集成kerberos
1、生成票据
1.1、创建认证用户
登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作:
# kadmin.local -q “addprinc -randkey spark/yjt”
1.2、生成密钥文件
生成spark密钥文件
# kadmin.local -q “xst -norankey -k /etc/spark.keytab spark/yjt”
拷贝sparkkeytab到所有的spark集群节点的conf目录下
1.3、修改权限
# chmod 404 /data1/hadoop/spark/conf/spark.keytab
# chown hduser:hduser /data1/hadoop/spark/conf/spark.keytab
2、集群内部测试
2.1、获取票据
# klint -it /data1/hadoop/spark/conf/spark.keytab spark/yjt
(1)、本地机器测试
# spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.0.jar 10
(2) 、提交到yarn, 模式是client
spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
查看8088信息:

(3) 、提交到yarn集群,模式是cluster
# spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.0.jar 10
查看8088信息:

3、客户端测试
3.1、hduser用户测试
安装spark或者从集群拷贝一份到客户端
客户端测试用户使用hduser
获取票据
# kinit -kt /data1/hadoop/spark/conf/spark.keytab spark/yjt

(1) 、提交到本地集群
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master spark://192.168.0.230:7077 examples/jars/spark-examples_2.11-2.4.0.jar 10
注意:使用这种方式提交需要在集群里面的hosts文件配置客户端的主机域名映射关系。
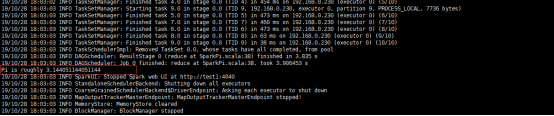
(2) 、提交到yarn,模式client
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
注:这种方式也需要在集群内部设置客户端主机名映射关系
(3) 、提交到yarn,模式cluster
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.0.jar 10

3.2、其他用户测试
(1)、创建用户yujt
# useradd -s /bin/bash -m -d /home/yujt -G hduser yujt
# echo “Your Password” | passwd --stdin yujt
(2)、修改spark.keytab权限
# chmod 404 /data1/hadoop/spark/conf/spark.keytab
注: 以上操作root或者sudo,需要root权限
# su - yujt
(3)、修改yujt这个用户的环境变量
修改用户的~/.bashrc文件,添加如下信息:(当然最好是直接修改/etc/profile,这样在创建用户的时候就不需要为每个用户添加环境变量信息)
export JAVA_HOME=/data1/hadoop/jdk
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/data1/hadoop/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
(4) 、测试本地standlone模式
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master spark://192.168.0.230:7077 examples/jars/spark-examples_2.11-2.4.0.jar 10
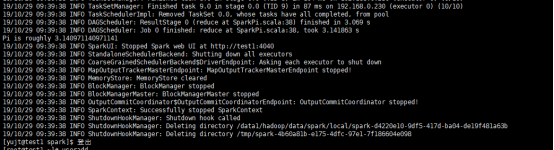
如上述,执行成功。
(5) 、测试yarn, 部署模式client
# $ ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
执行结果如下:

Web界面如下:

(6) 、测试yarn, 部署模式cluster

注:上述在执行任务的时候,我们使用了--principal 和--keytab参数,其实,如果使用kinit -kt /data1/hadoop/spark/conf/spark.keytab spark/yjt获取了票据以后,可以省略这两个参数。
spark集成kerberos的更多相关文章
- Spark:利用Eclipse构建Spark集成开发环境
前一篇文章“Apache Spark学习:将Spark部署到Hadoop 2.2.0上”介绍了如何使用Maven编译生成可直接运行在Hadoop 2.2.0上的Spark jar包,而本文则在此基础上 ...
- spark集成hive遭遇mysql check失败的问题
问题: spark集成hive,启动spark-shell或者spark-sql的时候,报错: INFO MetaStoreDirectSql: MySQL check failed, assumin ...
- Ambari集成Kerberos报错汇总
Ambari集成Kerberos报错汇总 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看报错的配置信息步骤 1>.点击Test Kerberos Client,查看相 ...
- HDP安全之集成kerberos/LDAP、ranger(knox自带LDAP)
----------------------目录导航见左上角------------------------------- 环境 HDP 3.0.1.0 (已有) JDK 1.8.0_91 (已有 ...
- Spark集成
一.Spark 架构与优化器 1.Spark架构 (重点) 2.Spark优化器 二.Spark+SQL的API (重点) 1.DataSet简介 2.DataFrame简介 3.RDD与DF/DS的 ...
- 机器学习 - pycharm, pyspark, spark集成篇
AS WE ALL KNOW,学机器学习的一般都是从python+sklearn开始学,适用于数据量不大的场景(这里就别计较“不大”具体指标是啥了,哈哈) 数据量大了,就需要用到其他技术了,如:spa ...
- 挖坑:hive集成kerberos
集成hive+kerberos前,hadoop已经支持kerberos,所以基础安装略去: https://www.cnblogs.com/garfieldcgf/p/10077331.html 直接 ...
- 机器学习 - 开发环境安装pycharm + pyspark + spark集成篇
AS WE ALL KNOW,学机器学习的一般都是从python+sklearn开始学,适用于数据量不大的场景(这里就别计较“不大”具体指标是啥了,哈哈) 数据量大了,就需要用到其他技术了,如:spa ...
- hive集成kerberos
1.票据的生成 kdc服务器操作,生成用于hive身份验证的principal 1.1.创建principal # kadmin.local -q “addprinc -randkey hive/yj ...
随机推荐
- for循环优化
转自:https://blog.csdn.net/lfc18606951877/article/details/78592823 1:多个for循环时,遵循外小内大(从外至里,循环对象size要从小到 ...
- PHP微信商户支付企业付款到零钱功能
一 开通条件,就是首先要在微信平台设置好. 以下微信文档里有的,我这里大概掠几项比较重要的. 付款资金 企业付款到零钱资金使用商户号余额资金. 根据商户号的账户开通情况,实际出款账户有做区别: ◆ 默 ...
- mysql表的创建、查看、修改、删除
一.创建表 创建表前先使用use 数据库名进入某一个数据库,创建表语句的格式如下: create table 表名称 ( 列名1 列的数据类型 [约束], 列名2 列的数据类型 [约束], 列名2 列 ...
- option触发及获取当前选中的option值
#标签 #<select id="city" class="select"> #JavaScript #$("#city").c ...
- 线程中的join方法,与synchronized和wait()和notify()的关系
什么时候要用join()方法? 1,join方法是Thread类中的方法,主线程执行完start()方法,线程就进入就绪状态,虚拟机最终会执行run方法进入运行状态.此时.主线程跳出start方法往下 ...
- Linux虚拟机安装(rhel 7.4)
Linux虚拟机安装(rhel 7.4) linux 1. 创建虚拟机 1.1. 新建虚拟机 1.2. 启动虚拟机 附录:部分配置 1. 创建虚拟机 1.1. 新建虚拟机 新建虚拟机 典型虚拟机 稍后 ...
- Jenkins - 扯淡篇
目录 什么是持续集成 持续集成的概念 持续交付 持续部署 流程 当没有Jenkins的时候... 什么是Jenkins 返回Jenkins目录 什么是持续集成 由于懒得写,所以本段摘自阮一峰老师的博客 ...
- onreadystatechange和onload区别分析
onreadystatechange和onload区别分析 script加载 IE的script 元素只支持onreadystatechange事件,不支持onload事件. FireFox,Op ...
- UVALive - 4097:Yungom(逼近 贪心)(DP)
pro:有D个字母,每个字母有自己的权值,现状需要用它们拼出N个单词,使得这些单词互相不为另外一个的前缀. 且单词的权值和最小.D<=200; N<=200; sol:如果建立字典树,那个 ...
- Topcoder10566 IncreasingNumber
IncreasingNumber 一个数是Increasing当且仅当它的十进制表示是不降的,\(1123579\). 求 \(n\) 位不降十进制数中被 \(d\) 整除的有多少个. \(n\leq ...