c# 获取网页的爬虫程序
转载于:https://www.cnblogs.com/wzk153/p/9145684.html
HtmlAgilityPack相关详解: https://www.cnblogs.com/asxinyu/p/CSharp_HtmlAgilityPack_XPath_Weather_Data.html
这篇文章只是简单展示一个基于HTTP请求如何抓取数据的文章,如觉得简单的朋友,后续我们再慢慢深入研究探讨。
图1:

如图1,我们工作过程中,无论平台网站还是企业官网,总少不了新闻展示。如某天产品经理跟我们说,推广人员想要抓取百度新闻中热点要闻版块提高站点百度排名。要抓取百度的热点要闻版本,首先我们先要了解站点https://news.baidu.com/请求头(Request headers)信息。
为什么要了解请求头(Request headers)信息?
原因是我们可以根据请求头信息某部分报文信息伪装这是一个正常HTTP请求而不是人为爬虫程序躲过站点封杀,而成功获取响应数据(Response data)。
如何查看百度新闻网址请求头信息?
图2:

图3:
如图2,我们可以打开谷歌浏览器或者其他浏览器开发工具(按F12)=》点击刷新 =》 点击请求地址 (news.baidu.com) =》 查看该站点请求头报文信息。从图中可以了解到该百度新闻站点可以接受text/html等数据类型;语言是中文;浏览器版本是Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36等等报文信息,在我们发起一个HTTP请求的时候直接携带该报文信息过去。当然并不是每个报文信息参数都必须携带过去,携带一部分能够请求成功即可。
那什么是响应数据(Response data)?
图3:
如图3,响应数据(Response data)是可以从谷歌浏览器或者其他浏览器中开发工具(按F12)查看到的,响应可以是json数据,可以是DOM树数据,方便我们后续解析数据。
当然您可以学习任意一门开发语言开发爬虫程序:C#、NodeJs、Python、Java、C++。
但这里主要讲述是C#开发爬虫程序。完整代码如下:
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
using System.IO;
using System.IO.Compression;
using System.Linq;
using System.Net;
using System.Text;
using System.Threading.Tasks; namespace ConsolePaCongApp3
{
/// <summary>
/// 自定义传参对象,当然无论传入或者传出的对象都是你们根据自己实际业务需求定义的
/// </summary>
public class RequestOptions
{
/// <summary>
/// 请求方式,GET或POST
/// </summary>
public string Method { get; set; }
/// <summary>
/// URL
/// </summary>
public Uri Uri { get; set; }
/// <summary>
/// 上一级历史记录链接
/// </summary>
public string Referer { get; set; }
/// <summary>
/// 超时时间(毫秒)
/// </summary>
public int Timeout = ;
/// <summary>
/// 启用长连接
/// </summary>
public bool KeepAlive = true;
/// <summary>
/// 禁止自动跳转
/// </summary>
public bool AllowAutoRedirect = false;
/// <summary>
/// 定义最大连接数
/// </summary>
public int ConnectionLimit = int.MaxValue;
/// <summary>
/// 请求次数
/// </summary>
public int RequestNum = ;
/// <summary>
/// 可通过文件上传提交的文件类型
/// </summary>
public string Accept = "*/*";
/// <summary>
/// 内容类型
/// </summary>
public string ContentType = "application/x-www-form-urlencoded";
/// <summary>
/// 实例化头部信息
/// </summary>
private WebHeaderCollection header = new WebHeaderCollection();
/// <summary>
/// 头部信息
/// </summary>
public WebHeaderCollection WebHeader
{
get { return header; }
set { header = value; }
}
/// <summary>
/// 定义请求Cookie字符串
/// </summary>
public string RequestCookies { get; set; }
/// <summary>
/// 异步参数数据
/// </summary>
public string XHRParams { get; set; }
} class Program
{
static void Main(string[] args)
{
var url = new Uri("http://news.baidu.com/");
//获取到网页的数据信息
var simpleCrawlResult = RequestAction(new RequestOptions() { Uri = url ,Method = "Get"}); HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > )
{
for (int i = ; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
HtmlNodeCollection liNodeItems = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectNodes("ul/li");
if (liNodeItems != null && liNodeItems.Count > )
{
for (int i = ; i < liNodeItems.Count; i++)
{
string title = liNodeItems[i].SelectSingleNode("a[1]").InnerText.Trim();
string href = liNodeItems[i].SelectSingleNode("a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
Console.Read();
} /// <summary>
/// 微软为我们提供两个关于HTTP请求HttpWebRequest,HttpWebResponse对象,方便我们发送请求获取数据。C# HTTP请求代码:
/// </summary>
/// <param name="options"></param>
/// <returns></returns>
private static string RequestAction(RequestOptions options)
{
string result = string.Empty;
IWebProxy proxy = GetProxy();
var request = (HttpWebRequest)WebRequest.Create(options.Uri);
request.Accept = options.Accept;
//在使用curl做POST的时候, 当要POST的数据大于1024字节的时候, curl并不会直接就发起POST请求, 而是会分为俩步,
//发送一个请求, 包含一个Expect: 100 -continue, 询问Server使用愿意接受数据
//接收到Server返回的100 - continue应答以后, 才把数据POST给Server
//并不是所有的Server都会正确应答100 -continue, 比如lighttpd, 就会返回417 “Expectation Failed”, 则会造成逻辑出错.
request.ServicePoint.Expect100Continue = false;
request.ServicePoint.UseNagleAlgorithm = false;//禁止Nagle算法加快载入速度
if (!string.IsNullOrEmpty(options.XHRParams)) { request.AllowWriteStreamBuffering = true; } else { request.AllowWriteStreamBuffering = false; }; //禁止缓冲加快载入速度
request.Headers.Add(HttpRequestHeader.AcceptEncoding, "gzip,deflate");//定义gzip压缩页面支持
request.ContentType = options.ContentType;//定义文档类型及编码
request.AllowAutoRedirect = options.AllowAutoRedirect;//禁止自动跳转
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36";//设置User-Agent,伪装成Google Chrome浏览器
request.Timeout = options.Timeout;//定义请求超时时间为5秒
request.KeepAlive = options.KeepAlive;//启用长连接
if (!string.IsNullOrEmpty(options.Referer)) request.Referer = options.Referer;//返回上一级历史链接
request.Method = options.Method;//定义请求方式为GET
if (proxy != null) request.Proxy = proxy;//设置代理服务器IP,伪装请求地址
if (!string.IsNullOrEmpty(options.RequestCookies)) request.Headers[HttpRequestHeader.Cookie] = options.RequestCookies;
request.ServicePoint.ConnectionLimit = options.ConnectionLimit;//定义最大连接数
if (options.WebHeader != null && options.WebHeader.Count > ) request.Headers.Add(options.WebHeader);//添加头部信息
if (!string.IsNullOrEmpty(options.XHRParams))//如果是POST请求,加入POST数据
{
byte[] buffer = Encoding.UTF8.GetBytes(options.XHRParams);
if (buffer != null)
{
request.ContentLength = buffer.Length;
request.GetRequestStream().Write(buffer, , buffer.Length);
}
}
using (var response = (HttpWebResponse)request.GetResponse())
{
////获取请求响应
//foreach (Cookie cookie in response.Cookies)
// options.CookiesContainer.Add(cookie);//将Cookie加入容器,保存登录状态
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
}
}
}
request.Abort();
return result;
} /// <summary>
/// 微软NET框架也为了我们提供一个使用代理IP 的System.Net.WebProxy对象
/// </summary>
/// <returns></returns>
private static System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = ""; // 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx"; // 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
}
}
根据展示的代码,我们可以发现HttpWebRequest对象里面都封装了很多Request headers报文参数,我们可以根据该网站的Request headers信息在微软提供的HttpWebRequest对象里设置(看代码报文参数注释,都有写相关参数说明,如果理解错误,望告之,谢谢),然后发送请求获取Response data解析数据。
还有补充一点,爬虫程序能够使用代理IP最好使用代理IP,这样降低被封杀机率,提高抓取效率。但是代理IP也分质量等级,对于某一些HTTPS站点,可能对应需要质量等级更加好的代理IP才能穿透,这里暂不跑题,后续我会写一篇关于代理IP质量等级文章详说我的见解。
C#代码如何使用代理IP?
微软NET框架也为了我们提供一个使用代理IP 的System.Net.WebProxy对象,关于使用代码如下:
/// <summary>
/// 微软NET框架也为了我们提供一个使用代理IP 的System.Net.WebProxy对象
/// </summary>
/// <returns></returns>
private static System.Net.WebProxy GetProxy()
{
System.Net.WebProxy webProxy = null;
try
{
// 代理链接地址加端口
string proxyHost = "192.168.1.1";
string proxyPort = ""; // 代理身份验证的帐号跟密码
//string proxyUser = "xxx";
//string proxyPass = "xxx"; // 设置代理服务器
webProxy = new System.Net.WebProxy();
// 设置代理地址加端口
webProxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
// 如果只是设置代理IP加端口,例如192.168.1.1:80,这里直接注释该段代码,则不需要设置提交给代理服务器进行身份验证的帐号跟密码。
//webProxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
}
catch (Exception ex)
{
Console.WriteLine("获取代理信息异常", DateTime.Now.ToString(), ex.Message);
}
return webProxy;
}
关于 System.Net.WebProxy对象参数说明,我在代码里面也做了解释。
如果获取到Response data数据是json,xml等格式数据,这类型解析数据方法我们这里就不详细说了,请自行百度。这里主要讲的是DOM树 HTML数据解析,对于这类型数据有人会用正则表达式来解析,也有人用组件。当然只要能获取到自己想要数据,怎么解析都是可以。这里主要讲我经常用到解析组件 HtmlAgilityPack,引用DLL为(using HtmlAgilityPack)。解析代码如下:
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(simpleCrawlResult);
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
if (liNodes != null && liNodes.Count > )
{
for (int i = ; i < liNodes.Count; i++)
{
string title = liNodes[i].SelectSingleNode("strong[1]/a[1]").InnerText.Trim();
string href = liNodes[i].SelectSingleNode("strong[1]/a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
HtmlNodeCollection liNodeItems = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectNodes("ul/li");
if (liNodeItems != null && liNodeItems.Count > )
{
for (int i = ; i < liNodeItems.Count; i++)
{
string title = liNodeItems[i].SelectSingleNode("a[1]").InnerText.Trim();
string href = liNodeItems[i].SelectSingleNode("a[1]").GetAttributeValue("href", "").Trim();
Console.WriteLine("新闻标题:" + title + ",链接:" + href);
}
}
Console.Read();
添加引用 =》项目右键 =》管理NuGet程序包 =》搜索HtmlAgilityPack 进行安装

另外附上HtmlAgilityPack学习链接 http://www.cnblogs.com/asxinyu/p/CSharp_HtmlAgilityPack_XPath_Weather_Data.html
执行结果:
这里来分析下这行代码:
HtmlNodeCollection liNodes = htmlDoc.DocumentNode.SelectSingleNode("//div[@id='pane-news']").SelectSingleNode("div[1]/ul[1]").SelectNodes("li");
我们先分析下数据:
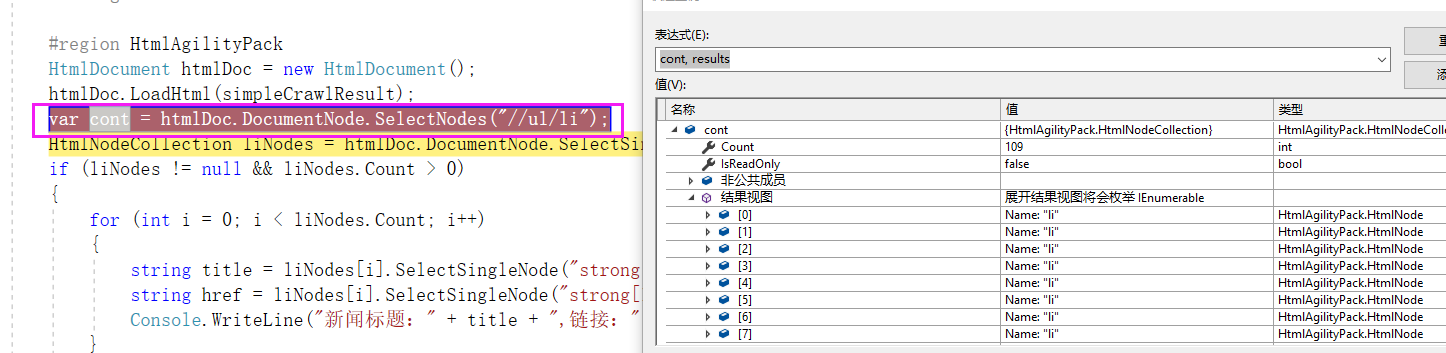
1:SelectSingleNode("//div[@id='pane-news']") ===》获取id='pane-news'的div 内容 (紫色框部分)
2:SelectSingleNode("div[1]/ul[1]") ===》获取 1中的第一个div标签下的第一个ul内容 (绿色框部分)
3:SelectNodes("li") ===》获取2中的所有li对象 (6个蓝色框部分)
如果XPath的开头是一个斜线(/)代表这是绝对路径。如果开头是两个斜线(//)表示文件中所有符合模式的元素都会被选出来,即使是处于树中不同的层级也会被选出来。以下的语法会选出文件中所有叫做cd的元素(在树中的任何层级都会被选出来)://cd
htmlDoc.DocumentNode.SelectNodes("//ul/li"); (会把所有的ul下的li获取出来)
如图:
c# 获取网页的爬虫程序的更多相关文章
- Java 网络爬虫获取网页源代码原理及实现
Java 网络爬虫获取网页源代码原理及实现 1.网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL ...
- Python爬虫学习之获取网页源码
偶然的机会,在知乎上看到一个有关爬虫的话题<利用爬虫技术能做到哪些很酷很有趣很有用的事情?>,因为强烈的好奇心和觉得会写爬虫是一件高大上的事情,所以就对爬虫产生了兴趣. 关于网络爬虫的定义 ...
- 爬虫程序获取登录Cookie信息时遇到302,怎么处理
最近要做个爬虫程序爬爬东西,先搞定登录授权这块,没得源代码,所以只能自行搞定了,按平时的直接发起HttpWebRequest(req)请求,带上用户名密码,好了,然后 HttpWebResponse ...
- 我的第一个爬虫程序:利用Python抓取网页上的信息
题外话 我第一次听说Python是在大二的时候,那个时候C语言都没有学好,于是就没有心思学其他的编程语言.现在,我的毕业设计要用到爬虫技术,在网上搜索了一下,Python语言在爬虫技术这方面获得一致好 ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...
- C语言之socket获取网页源码
写爬虫也许你用的是python,类似urlopen(url).read()即可获得普通的网页的源码,或者用的java的网络库加上流操作,或者其他高级语言.但你有没有想过使用C语言来实现呢?我曾经以为用 ...
- python爬虫__第一个爬虫程序
前言 机缘巧合,最近在学习机器学习实战, 本来要用python来做实验和开发环境 得到一个需求,要爬取大众点评中的一些商户信息, 于是开启了我的第一个爬虫的编写,里面有好多心酸,主要是第一次. 我的文 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
随机推荐
- x64内核强删文件.
目录 x64内核中强删文件的实现 一丶简介 1.步骤 2.Nt驱动代码 x64内核中强删文件的实现 一丶简介 说道删除文件.有各种各样的方法. 有ring3 也有ring0. 而且也有许多对抗的方法. ...
- httpd.exe你的电脑中缺失msvcr110.dll怎么办(WIN2008服务器环境装WAMP2.5出现的问题)
httpd.exe你的电脑中缺失msvcr110.dll怎么办 去微软官方下载相应的文件 1 打开上面说的网址 Download and install, if you not have it alr ...
- Vue简单归纳
目录 Vue.JS Vue.JS介绍 概述 MVVM模式 示例图 快速入门 事件绑定 什么是事件 单击事件绑定 键盘事件 按键修饰符 鼠标事件 事件修饰符 数据绑定 插值 v-text v-bind ...
- mysql死锁(锁与事务)
线上某服务时不时报出如下异常(大约一天二十多次):“Deadlock found when trying to get lock;”. Oh, My God! 是死锁问题.尽管报错不多,对性能目前看来 ...
- Comparator中返回0导致数据丢失的大坑
今天对一列数据进行排序,因为存储的是Map结构,要实现排序,马上就想到了TreeMap,于是查到API,这样新建TreeMap就能实现添加的时候就自动排序. new TreeMap<>(n ...
- opencv yuvNV21转RGB
void yuv420Torgb() { FILE *fp = fopen("D:\\1.yuv","rb"); ; ; uchar *yuvdata = / ...
- EIGENSTRAT计算PCA的显著性
之前我写过一篇文章群体遗传分析分层校正,该选用多少个PCA?,里面提到可以通过EIGENSTRAT软件确定显著的主成分,后续就可以将显著的主成分加入协变量中. 这篇文章主要是讲如何通过EIGENSTR ...
- 离线安装pycharm数据库驱动
这个数据库驱动,不是python的链接包 而是打开pycharm pro版后的数据库浏览器驱动. 也就是专业版比社区版方便的一个地方,可以直接边写代码,边看数据库结构,还可以拖动一些变量. 在线安装挺 ...
- [LeetCode] 133. Clone Graph 克隆无向图
Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. OJ's ...
- webpack 4.0改版问题
4.0之后的打包方式: webpack --mode development src/index.js --output-filename app.js --output-path dist