mysql的innodb数据存储结构
数据库磁盘读取与系统磁盘读取
1,系统从磁盘中读取数据到内存时是以磁盘块(block)为基本单位,位于同一个磁盘块中的数据会被一次性读取出来。
2,innodb存储引擎中有页(Page)的概念,页是数据库管理磁盘的最小单位,innodb存储引擎中默认每个页的大小为16kb,每次读取磁盘时都将页载入内存中。
3,系统一个磁盘块的大小空间往往没有16kb这么大,因此innodb每次io操作时都会将若干个地址连续的磁盘块的数据读入内存,从而实现整页读入内存
问题:数据库的数据结构时怎样的?B树和B+树有什么区别,为什么选择B+树作为存储数据的结构,而不是B树?
B树和B+树
Btree
一个M阶的B-tree有如下特点
1,每个节点最多有m个孩子(分叉),
2,除了根节点和叶子节点外,其他每个节点至少有ceil(m/2)个孩子
3,若根节点不是叶子节点,则至少有两个孩子
4,所有叶子节点都再同一层,且不包含其他关键字信息
5,每个非终端节点包含n个关键字信息,关键字的个数n满足ceil(m/2)-1<=n<= m-1 其中m为阶数
6,ki(i=1,…n)为关键字,且关键字(主键primary key)升序排序。
7,. Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1);
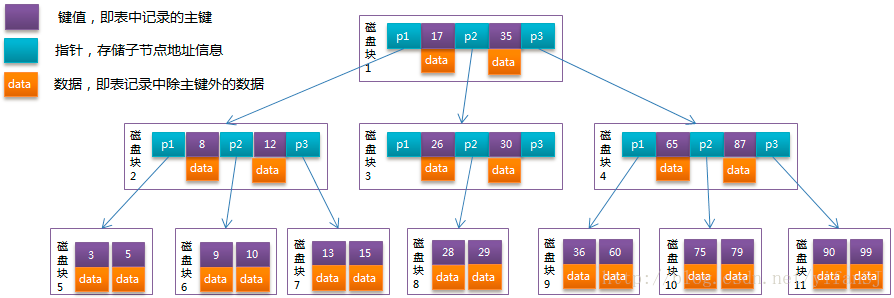
B-tree每个节点都包含指针,key以及data,每个节点含有三个指向子节点的指针和两个升序排序的关键字(key)
模拟查找关键字29的过程:
1. 根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
2. 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
3. 根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
4. 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
5. 根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
6. 在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。
B树上大部分的操作(插入、删除、查询)所需要的磁盘存取次数和B树的高度是成正比的,并且B树是尽量多的在节点上存储信息,保证导数尽量少,在B树中可以检查多个子结点,由于在一棵树中检查任意一个结点都需要一次磁盘访问,所以B树避免了大量的磁盘访问,减少了磁盘I/O。
B+tree
毫无疑问,减少树的高度是有效减少IO次数提高效率的方式,b-tree结构每个节点不仅包含key值,还有data值,每一个页的存储(16kb)是有限的,每个节点可容纳的指针和keydata是有,如果data数据含量大,那么一个页保存的指针和key的数量就会减少,从而增页节点的数量,这就增加btree的深度,增加读取磁盘的次数,进而影响查询效率
而在b+tree中,一个节点记录的都是key值和指针(排除了data值),这样就可以记录更多的key值,其key值是升序排序,

B+tree和b-tree有如下不同点
1,非叶子节点只存储键值信息(key信息)
2,所有叶子节点之间都有一个链指针,数据都存放再叶子节点中
推算
innodb存储引擎一页的大小为16kb,一般主键类型为int占4个字节,或bigint占8个字节,指针类型页一般4个或8个字节,也就是说一个页中大概存储16*1024/16=1024个key,深度为3的B+tree索引(三页)可以维护1024*1024*1024=10亿条记录,实际情况每个节点不可能填满,B+tree的高度一般为2-4曾,mysql的innodb存储引擎将根节点常驻内存,也就是查找某一键值的行记录最多需要1-3次磁盘IO操作
页的概念,
页是innodb读取磁盘的最小单位,整页整页的读取
页分为,数据页(BTreeNode),Undo页(undo Log page),系统页(Systempage),事务数据页(Transaction SystemPage)每个数数据页的大小为16kb,每个page使用一个32位int值来表示,
一个page的基本结构
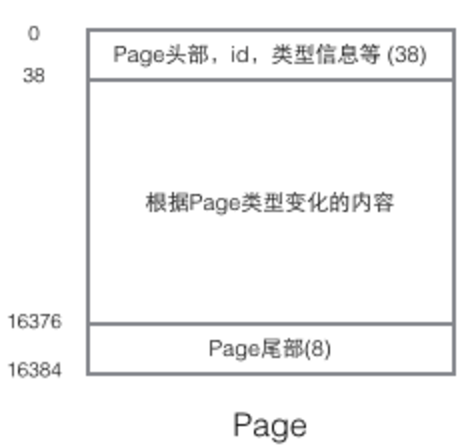
1,0-38:page头部,id,类型信息等占38个字节,头部保存两个指针分别指向前一个page和后一个page,page是一个双向列表
2,38-16376:不同的类型页所含的数据不同,这部分空间包含系统记录(SystemRecord)和用户记录(UserRecord),我们表中的一条条记录就放在UserRecord部分,UserRecord存放的内容可以是以下内容
a,主键索引树非叶子节点,B+tree索引,和指针
b,主键索引树叶子节点,key和data(就是记录本身)
c,辅助键索引树非叶子节点,B+tree辅助索引
d,辅助键索引树叶子节点,key和data(这里的data是主键)
页可以装很多种数据信息,有的页是B+树的所有主键索引,有的页是B+树的叶子节点也就是数据记录本身,有的页是我们创建的二级索引,
16376-16384:page尾部
页和节点的关系
页和节点没有强相关关系
由页组成的链表,页之间是双向列表,页里面的数据是单向链表,这种结构组成了主键索引B+树,组成了叶子节点数据。
定位一条记录的过程,select * from table where id = 29
系统经过解析sql语句,首先读取装有非叶子节点page页,遍历非叶子节点,这个过程随着节点的遍历会将一个或多个page页加载到内存,直到定位到这条记录的叶子节点,然后遍历找出该条记录。
如果使用了二级索引则先读取二级索引page遍历这个二级索引,找到装有主键信息叶子节点page页,遍历找到该主键。然后再根据主键索引寻找到该条记录

mysql的innodb数据存储结构的更多相关文章
- InnoDB数据存储结构
MySQL服务器上 存储引擎 负责对表中数据的读取和写入工作,不同存储引擎中 存放的格式 一般是不同的,甚至有的存储引擎(Memory)不用磁盘来存储数据. 页 (Page) 是磁盘和内存之间交互的基 ...
- MySQL之InnoDB数据页结构(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做数据页. 一个数据页可以被大致划分为7个部分,分别是 File Header,表示页的一些通用信息,占固定的38字节. Pag ...
- mysql之innodb存储引擎---数据存储结构
一.背景 1.1文件组织架构 首先看一下mysql数据系统涉及到的文件组织架构,如下图所示: msyql文件组织架构图 从图看出: 1.日志文件:slow.log(慢日志),error.log(错误日 ...
- MySQL InnoDB 逻辑存储结构
MySQL InnoDB 逻辑存储结构 从InnoDB存储引擎的逻辑结构看,所有数据都被逻辑地存放在一个空间内,称为表空间,而表空间由段(sengment).区(extent).页(page)组成.p ...
- MYSQL Innodb逻辑存储结构
转载于网络 这几天在读<MySQL技术内幕 InnoDB存储引擎>,对 Innodb逻辑存储结构有了些了解,顺便也记录一下: 从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放 ...
- Mysql+innodb数据存储逻辑
Mysql+innodb数据存储逻辑. 表空间由段,区,页组成 ibdata1:共享表空间.即所有的数据都存放在这个表空间内.如果用户启用了innodb_file_per_table,则每张表内的数据 ...
- InnoDB 逻辑存储结构
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/80 如果创建表时没有显示的定义主键,mysql会按如下方式创建主 ...
- Innodb页面存储结构-2
上一篇<Innodb页面存储结构-1>介绍了Innodb页面存储的总体结构,本文会介绍页面的详细内容,主要包括页头.页尾和记录的详细格式. 学习数据结构时都说程序等于数据结构+算法,而在i ...
- InnoDB逻辑存储结构
从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace).表空间又由段(segment).区(extent).页(page)组成.页在一些文档中 ...
随机推荐
- Python线程池及其原理和使用(超级详细)
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互.在这种情形下,使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池. 线程池在系统启动时即 ...
- 【Spring Cloud学习之三】负载均衡
环境 eclipse 4.7 jdk 1.8 Spring Boot 1.5.2 Spring Cloud 1.2 主流的负载均衡技术有nginx.LVS.HAproxy.F5,Spring Clou ...
- 【整理】【docker】【Linux】整理笔记
1.Linux安装docker 参考文章:https://blog.csdn.net/yanpenglei/article/details/78944553 Docker 要求系统的内核版本高于 3. ...
- 推荐一款好用的json导出execl格式的文件的js工具-JsonExportExcel
<html> <head> <meta charset="utf-8"> <title>json导出Excel</title& ...
- js中常见的创建对象的方法(1)
工厂模式:抽象了创建具体对象的过程 function createPerson(name, age, job){ var obj = new Object(); obj.name = name; ob ...
- Python输出菱形
最近准备熟悉下Python的基础语法,准备练习下输出菱形.刚好作为自己blog的开篇~~ n =10 #控制菱形的大小 for i in range(1, n): for j in range(int ...
- ETCD服务
ETCD 简介 ETCD是一个开源的.分布式的键值对数据存储系统,由Go语言实现,用于存储key-value键值对,同时不仅仅是存储,主要用途是提供共享配置及服务发现,使用Raft一致性算法来管理高度 ...
- Go基础编程实践(三)—— 日期和时间
日期和时间 package main import ( "fmt" "time" ) func main() { // 获取当前时间 current := ti ...
- Js的iframe相关问题,如何判断当前是否在iframe中,iframe和它的父窗口如何通信
一.前言: 在web中,为了丰富我们的内容,往往需要引用其它HTML文件,这时候就需要用到 iframe 标签,本文就主要记录一下使用iframe所需要注意的问题 iframe 所使用的环境(笔者所遇 ...
- mongoDB对没有字段的记录新增字段
db.getCollection('ClassRecordOneDetail').updateMany({'synState':{'$exists':false}},{'$set':{'synStat ...