STL源码剖析——序列式容器#3 Deque
Deque是一种双向开口的连续线性空间。所谓的双向开口,就是能在头尾两端分别做元素的插入和删除,而且是在常数的时间内完成。虽然Vector也可以在首端进行元素的插入和删除(利用insert和erase),但效率奇差(涉及到整个数组的移动),无法被接受。
另外,Deque与Vector间最大的差别就是Deque没有类似于Vector中的容量的概念,因为Deque是以分段连续空间组合而成的,至于什么是分段连续空间,等会会详细讨论。所以Deque不会有像Vector那样“因旧空间不足而重新配置一块更大的空间,然后复制元素,再释放旧空间”这样的操作。
也因为其独特的数据结构,所以对Deque自身进行排序效率不是很高,至少对比于Vector而言确实如此。如果为了最高效率,建议可将Deque先完整复制到一个Vector身上,将Vector排序后(STL Sort算法),再复制回Deque。
Deque的中控器
deque是连续空间?不,这只是假象,是设计者故意设计成其看上去是连续的。其实内部只是局部连续,deque本身由一段一段的定量连续空间构成。一旦有必要在deque的前端或后端增加新空间,便配置一段定量连续空间,串接在整个deque的头端或尾端。deque的最大任务,便是在这些分段的定量连续空间上,维护其整体连续的假象,并提供随机存取的接口。其避开了vector对于空间“重新配置、复制、释放”的轮回,代价则是复杂的迭代器结构。
说到分段连续空间的实现,在我看来,与图的邻接链表或者解决哈希冲突的拉链法相似,当然只是有些许相似。deque采用一块map,这里的map指的是一块连续的空间,其中存储的每个元素(节点)都是指针,指向另一段连续线性空间,称为缓冲区。缓冲区里面才存储真正的内容。deque默认为每个缓冲区分配512byte的空间大小。
template <class T, class Alloc = alloc, size_t BufSiz = >
class deque {
public: // Basic types
typedef T value_type;
typedef value_type* pointer;
...
protected: // Internal typedefs
typedef pointer* map_pointer; //注意,pointer即为T*,而pointer*即为T**
...
protected: // Data members
map_pointer map;
size_type map_size;
...
}
在各种的类型定义别名后,我们发现map就是T**,也就是说它是一个指针,所指之物又是一个指针,指向类型为T的一块空间,如图:

Deque的迭代器
整体连续的假象其实都是deque的迭代器造成的,我们在使用deque的迭代器遍历容器时,都是直接连续自增;我们在使用deque的迭代器随机存取时,都是直接进行迭代器的加减操作。能这么灵活的使用deque的迭代器,就会让使用者觉得deque内部是连续。殊不知,迭代器为了维持这个假象,其实现变得非常复杂。
首先,它必须能够指出分段连续空间在哪(即自己在map的哪个缓冲区里),其次它必须能判断自己是否已经处于其所在缓冲区的边缘,如果是,一旦前进或后退时就必须跳跃至下一个或上一个缓冲区,为了能够正确跳跃,deque必须随时掌握管控map。
template <class T, class Ref, class Ptr, size_t BufSiz>
struct __deque_iterator { //并未继承std::iterator,为了符合STL规范,要对五个相应类型都做定义
typedef __deque_iterator<T, T&, T*, BufSiz> iterator;
typedef __deque_iterator<T, const T&, const T*, BufSiz> const_iterator;
static size_t buffer_size() { return __deque_buf_size(BufSiz, sizeof(T)); } typedef random_access_iterator_tag iterator_category; //
typedef T value_type; //
typedef Ptr pointer; //
typedef Ref reference; //
typedef size_t size_type;
typedef ptrdiff_t difference_type; //
typedef T** map_pointer; typedef __deque_iterator self; //保持与空间的联结
T* cur; //所指是当前缓冲区里的当前元素
T* first; //所指是当前缓冲区里的头元素
T* last; //所指是当前缓冲区里的尾元素的下一位(含备用空间)
map_pointer node; //指向map的头
...
}

其中用来决定缓冲区大小的函数buffer_size(),调用__deque_buf_size(),后者是一个全局函数:我觉得决定的是缓冲区能容纳的元素个数
//如果n不为0,就传回n,表示buffer size由用户自定义。
//如果n为0,表示buffer size使用默认值,那么
//如果sz(元素大小,sizeof(T))小于512,就返回512byte能存储该类元素的个数 512/sz
//如果sz不小于512,就返回1
inline size_t __deque_buf_size(size_t n, size_t sz)
{
return n != ? n : (sz < ? size_t( / sz) : size_t());
}
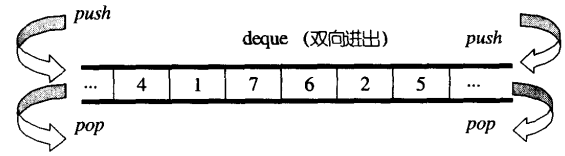
假设我们产生一个类型为int,缓冲区大小为8(即自定义n = 8)的双端队列,经过一系列的操作后,该deque拥有了20个元素,那么其begin()和end()所传回的两个迭代器应该如图所示,这两个迭代器其实是deque内的成员,名为start和finish。

20个元素需要20/8=3个缓冲区,所以map内有3个节点被使用,迭代器start内的cur指针,指向第一个缓冲区的第一个元素 ,迭代器finish内的cur指针,指向最后一个缓冲区的最后一个元素的下一位置。
下面是迭代器几个关键行为,如各种指针运算加、减、前进、后退。如一开始所言,由于其独特的结构,并不是直接加减就完事了。deque定义了一个函数负责缓冲区的跳跃行为:
//如果需要跳跃到某个缓冲区,提供该区在map的地址(即node节点),该函数帮助迭代器进行跳跃,主要是修改迭代器所在缓冲区的头尾指针
void set_node(map_pointer new_node) {
node = new_node;
first = *new_node;
last = first + difference_type(buffer_size());
}
以下重载各个运算子:
reference operator*() const { return *cur; } //取值
#ifndef __SGI_STL_NO_ARROW_OPERATOR
pointer operator->() const { return &(operator*()); } //取址,成员调用
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
self& operator++() { //前缀
++cur;
//往下一缓冲区跳
if (cur == last) {
set_node(node + );
cur = first;
}
return *this;
}
self operator++(int) { //后缀
self tmp = *this;
++*this;
return tmp;
}
self& operator--() {
if (cur == first) {
//往上一缓冲区跳
set_node(node - );
cur = last;
}
--cur;
return *this;
}
self operator--(int) {
self tmp = *this;
--*this;
return tmp;
}
自增、自减相对比较简单,但随机存取就没那么好理解了:
self& operator+=(difference_type n) {
difference_type offset = n + (cur - first);
if (offset >= && offset < difference_type(buffer_size()))
//目标位置仍在当前缓冲区内,直接使用T类型指针(一般为原生指针)的+=
cur += n;
else {
//目标位置不在当前缓冲区,确定要跨越几个缓冲区,确定是往前跳还是往后跳
difference_type node_offset =
offset > ? offset / difference_type(buffer_size())
: -difference_type((-offset - ) / buffer_size()) - ;
//跳,切换至正确的缓冲区
set_node(node + node_offset);
//first已经在set_node中被设置为目标位置所在的缓冲区的开头
//切换至正确的位置,node_offset * difference_type(buffer_size()为跨越缓冲区的元素总数,而offset为 从跳跃前的那个缓冲区的first开始 的要跳跃的所有元素总数
cur = first + (offset - node_offset * difference_type(buffer_size()));
}
return *this;
}
self operator+(difference_type n) const {
self tmp = *this;
return tmp += n;
}
self& operator-=(difference_type n) { return *this += -n; }
self operator-(difference_type n) const {
self tmp = *this;
return tmp -= n;
}
//实现随机访问存取,可见使用的是operator+()函数
reference operator[](difference_type n) const { return *(*this + n); }
bool operator==(const self& x) const { return cur == x.cur; }
bool operator!=(const self& x) const { return !(*this == x); }
bool operator<(const self& x) const {
return (node == x.node) ? (cur < x.cur) : (node < x.node);
}
可以看到,对于各种随机存取操作,其实现都来自于operator+=,而operator+=如何实现,注释里已有解释。唯二一个运算子有自己真正的实现的是operator-(),注意,与上面operator-()不同的是,不是迭代器与difference_type类型变量相减,而是两个迭代器之间相减:
difference_type operator-(const self& x) const {
//调用者作为被减数,参数作为减数,其意义为从参数位置x处到达调用者的位置需要经过多少个元素
//如果x的位置在调用者的前面,那么(cur - first) + (x.last - x.cur);这段就容易理解了;如果不在,那结果会变为负数
return difference_type(buffer_size()) * (node - x.node - ) +
(cur - first) + (x.last - x.cur);
}
Deque的数据结构
deque除了维护一个先前说过的指向map的指针外,也维护start和finish两个迭代器,分别指向第一缓冲区的第一个元素和最后缓冲区的最后一个元素的下一位置。此外,还要记住当前map的大小,当map所提供的节点不足,就必须重新配置更大的一块map。
template <class T, class Alloc = alloc, size_t BufSiz = >
class deque {
public: // Basic types
typedef T value_type;
typedef value_type* pointer;
typedef size_t size_type; public: // Iterators
typedef __deque_iterator<T, T&, T*, BufSiz> iterator; protected: // Internal typedefs
typedef pointer* map_pointer; //注意,pointer即为T*,而pointer*即为T** protected: // Data members
iterator start;
iterator finish; map_pointer map;
size_type map_size;
...
}
在有了这两个迭代器之后,下面几个函数便可轻易实现:
public: // Basic accessors
iterator begin() { return start; }
iterator end() { return finish; } reference operator[](size_type n) { return start[difference_type(n)]; } //从start开始跳到n reference front() { return *start; }
reference back() {
iterator tmp = finish;
--tmp;
return *tmp;
}
size_type size() const { return finish - start;; }
size_type max_size() const { return size_type(-); } //-1转为无符号整数就是整数最大值
bool empty() const { return finish == start; }
Deque的构造与内存管理
- 构造函数
我们可以以某一个版本的构造函数来开始研究deque的构造,其中一个较为常用的版本是:
deque<int, alloc, > x(, );
从Deque的中控器这一小节中我们就已经知道,设置缓冲区大小的模版参数是第三个,所以如果要想自定义缓冲区大小,就必须先将前两个参数都指明出来,因此必须明确指定alloc为空间配置器。
deque自行定义来了两个专属 的空间配置器,一个是负责配置一个元素的大小,另一个是负责配置一个缓冲区的大小:
protected: // Internal typedefs
typedef simple_alloc<value_type, Alloc> data_allocator; //每次配置一个元素大小
typedef simple_alloc<pointer, Alloc> map_allocator; //每次配置一个指针大小
上述用到的构造函数版本源码为:
deque(size_type n, const value_type& value)
: start(), finish(), map(), map_size()
{
fill_initialize(n, value);
}
其中所调用的fill_initialize()负责产生并安排好deque的结构,并将元素的初值设置妥当:
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::fill_initialize(size_type n,
const value_type& value) {
//产生并安排deque结构的另有其人,本函数只是负责将初值设置妥当。
create_map_and_nodes(n);
map_pointer cur;
__STL_TRY{
//将每一个节点指向的缓冲区都设定为初值
for (cur = start.node; cur < finish.node; ++cur)
uninitialized_fill(*cur, *cur + buffer_size(), value);
//最后一个节点需要额外处理,因为尾端可能有备用空间,不必设初值
uninitialized_fill(finish.first, finish.cur, value);
}
# ifdef __STL_USE_EXCEPTIONS
catch (...) {
for (map_pointer n = start.node; n < cur; ++n)
destroy(*n, *n + buffer_size());
destroy_map_and_nodes();
throw;
}
# endif /* __STL_USE_EXCEPTIONS */
}
create_map_nodes()才是负责产生并安排好deque的结构:
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::create_map_and_nodes(size_type num_elements) {
//需要的节点数 = (元素个数/每个缓冲区可以容纳的元素个数)+1
//如果刚好整除,会多配一个节点
size_type num_nodes = num_elements / buffer_size() + ; //计算一个map的节点数,至少8个,最多是“所需节点数加2”,
map_size = max(initial_map_size(), num_nodes + ); //static size_type initial_map_size() { return 8; }
map = map_allocator::allocate(map_size); //分配出一个具有map_size个节点的map //令nstart和nfinish指向map所拥有的全部节点的最中央区域
//保持在最中央,可使头尾两端的扩充空间一样大,每个节点对应一个缓冲区
map_pointer nstart = map + (map_size - num_nodes) / ;
map_pointer nfinish = nstart + num_nodes - ; map_pointer cur;
__STL_TRY{
//为每个现用节点配置缓冲区
for (cur = nstart; cur <= nfinish; ++cur)
*cur = allocate_node(); //pointer allocate_node() { return data_allocator::allocate(buffer_size()); }
}
# ifdef __STL_USE_EXCEPTIONS
catch (...) {
for (map_pointer n = nstart; n < cur; ++n)
deallocate_node(*n);
map_allocator::deallocate(map, map_size);
throw;
}
# endif /* __STL_USE_EXCEPTIONS */
//为deque的两个迭代器start和finish设置到正确的位置上
start.set_node(nstart);
finish.set_node(nfinish);
start.cur = start.first;
//如果元素个数是缓冲区可容纳个数的整数倍,会分配多一个缓冲区,此时就应吧finish的cur指向这多配的一个节点的起始处
finish.cur = finish.first + num_elements % buffer_size();
}
- 末端插入push_back()
void push_back(const value_type& t) {
//如果当前插入的位置不是缓冲区的最后一位时,正常插入
if (finish.cur != finish.last - ) {
construct(finish.cur, t);
++finish.cur;
}
//如果当前插入位置是缓冲区的最后一位,那么就要配置另外一块缓冲区
else
push_back_aux(t);
}
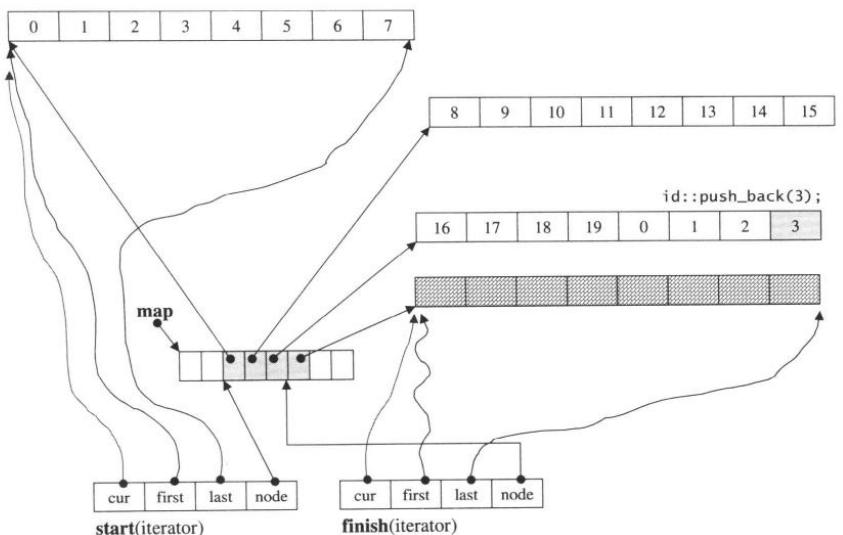
如果尾端只剩一个元素的备用空间,那么push_back就会请求push_back_aux来帮忙负责配置一块新的缓冲区,然后再改变finish迭代器的指向:
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::push_back_aux(const value_type& t) {
value_type t_copy = t;
//如果map尾端备用节点不足,则需要重新换一个map
reserve_map_at_back();
//为finish的下一节点分配缓冲区
*(finish.node + ) = allocate_node();
__STL_TRY{
construct(finish.cur, t_copy); //先把finish当前指向的缓冲区的最后一个元素填充完毕
finish.set_node(finish.node + ); //再把finish指向下一刚开辟的缓冲区
finish.cur = finish.first;
}
- 首端插入push_front()
为尾端插入同样的处理方式,不再赘述:
void push_front(const value_type& t) {
if (start.cur != start.first) {
construct(start.cur - , t);
--start.cur;
}
else
push_front_aux(t);
}
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::push_front_aux(const value_type& t) {
value_type t_copy = t;
reserve_map_at_front();
*(start.node - ) = allocate_node();
__STL_TRY{
start.set_node(start.node - );
start.cur = start.last - ;
construct(start.cur, t_copy);
}
我们在这push_back_aux函数中看到其内部调用了reserve_map_at_back(),而在push_front_aux函数中看到其内部调用了reserve_map_at_front()。这两个函数又是什么来头呢?我在注释中标明了它的用处,当map的首端或尾端节点不足时,这个函数就负责重新换一个map,那么如何更换和迁移map呢?我们来看看这两个函数的实现:
void reserve_map_at_back(size_type nodes_to_add = ) {
//如果map尾端的节点备用空间不足
if (nodes_to_add + > map_size - (finish.node - map))
reallocate_map(nodes_to_add, false); //必须重新换一个map,配置更大的,拷贝原来的,释放原来的
}
void reserve_map_at_front(size_type nodes_to_add = ) {
//如果map首端的节点备用空间不足
if (nodes_to_add > start.node - map)
reallocate_map(nodes_to_add, true); //必须重新换一个map,配置更大的,拷贝原来的,释放原来的
}
//nodes_to_add:应该增加多少个节点
//add_at_front:是首端需要扩充还是尾端需要扩充
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::reallocate_map(size_type nodes_to_add,
bool add_at_front) {
size_type old_num_nodes = finish.node - start.node + ; //现用节点个数
size_type new_num_nodes = old_num_nodes + nodes_to_add; //扩充后的节点个数 map_pointer new_nstart;
if (map_size > * new_num_nodes) { //如果map的总节点数比扩充后的节点数两倍多还有余,说明某端满了,而另一端还有很多备用节点
new_nstart = map + (map_size - new_num_nodes) / //试图把现用节点区间重新放置回map的中央,使两端的备用节点数约等
+ (add_at_front ? nodes_to_add : );
if (new_nstart < start.node) //新起点比原起点小,说明把现用节点区间往前移,一般是尾端满了的情况
copy(start.node, finish.node + , new_nstart);
else //新起点比原起点大,说明把现用节点区间往后移,一般是首端满了的情况
copy_backward(start.node, finish.node + , new_nstart + old_num_nodes);
}
else { //如果不是,说明map的可用节点数已经不多,需要配置一块空间,准备给新map使用
size_type new_map_size = map_size + max(map_size, nodes_to_add) + ; //如果所需扩充的节点数比原map的节点个数还要大,那就按前者来扩充,否则就两倍map节点个数 //分配空间部分与构造部分类似
map_pointer new_map = map_allocator::allocate(new_map_size);
new_nstart = new_map + (new_map_size - new_num_nodes) / //居中
+ (add_at_front ? nodes_to_add : );
//把原map内容拷贝过来
copy(start.node, finish.node + , new_nstart);
//释放原map
map_allocator::deallocate(map, map_size); //设定新map的起始地址与大小
map = new_map;
map_size = new_map_size;
}
//重新设定迭代器start和finish
start.set_node(new_nstart);
finish.set_node(new_nstart + old_num_nodes - );
}
Deque的元素操作
- pop_back —— 弹出最尾端的元素
与push类似,在执行弹出操作时,如果最后一个缓冲区的cur指针已经指向first指针时,说明缓冲区已空,需要另外的函数来负责缓冲区的释放。因为cur指向的是最后一个元素的下一位置。
void pop_back() {
//最后缓冲区有一个或多个元素
if (finish.cur != finish.first) {
--finish.cur;
destroy(finish.cur);
}
else //最后缓冲区没有元素(cur == first代表缓冲区为空)
pop_back_aux();
}
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::pop_back_aux() {
/* void deallocate_node(pointer n) {
data_allocator::deallocate(n, buffer_size());
}*/
deallocate_node(finish.first); //释放最后一个缓冲区
finish.set_node(finish.node - ); //调整finish的位置,使其指向上一个缓冲区
finish.cur = finish.last - ; //调整该迭代器的cur指针,指向上一个缓冲区的最后一个元素
destroy(finish.cur); //将该元素析构
}
- pop_front —— 弹出最前端元素
最前端缓冲区的cur与最尾端缓冲区的cur不同,其指向的是该缓冲区第一个元素:
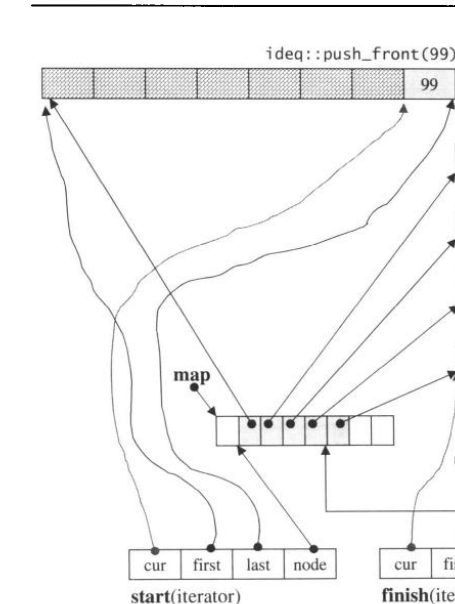
所以它的顺序是先析构再调整cur指针:
void pop_front() {
//第一缓冲区有两个或以上的元素
if (start.cur != start.last - ) {
destroy(start.cur);
++start.cur;
}
else //第一缓冲区仅有一个元素
pop_front_aux();
}
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::pop_front_aux() {
//先把第一元素析构
destroy(start.cur);
deallocate_node(start.first); //释放第一缓冲区
start.set_node(start.node + ); //调整start的位置,使其指向第二缓冲区
start.cur = start.first; //下一个缓冲区的第一个元素
}
- clear —— 清除整个deque。要注意的是,deque会保留一个缓冲区,即使其没有任何元素时。
template <class T, class Alloc, size_t BufSize>
void deque<T, Alloc, BufSize>::clear() {
//从第二缓冲区开始直到倒二缓冲区,把其中的元素析构,空间释放
for (map_pointer node = start.node + ; node < finish.node; ++node) {
destroy(*node, *node + buffer_size());
data_allocator::deallocate(*node, buffer_size());
}
//如果有头尾两个缓冲区
if (start.node != finish.node) {
destroy(start.cur, start.last); //将第一缓冲区的所有元素析构
destroy(finish.first, finish.cur); //将尾缓冲区所有元素析构
data_allocator::deallocate(finish.first, buffer_size()); //将尾缓冲区的空间释放,保留第一缓冲区
}
else //如果只有一个缓冲区
destroy(start.cur, finish.cur); //将此唯一缓冲区的所有元素析构,但并不释放空间 finish = start;
}
- erase(iterator pos) —— 清除某个元素
iterator erase(iterator pos) {
iterator next = pos;
++next;
//计算当前位置与第一缓冲区第一元素的距离
difference_type index = pos - start;
//距离小于元素总和的一半,意味着清除点之前的元素较少
if (index < (size() >> )) {
copy_backward(start, pos, next); //就把清除点之前的元素[start, pos)全部往后移动一格
pop_front(); //移动完毕,第一元素冗余,弹出
}
else { //意味着清除点之后的元素较少
copy(next, finish, pos); //就把清除点之后的元素[next, finish)全部往前移动一格
pop_back(); //移动完毕,最后一个元素冗余,弹出
}
return start + index; //指向移除前的前一元素
}
- erase(iterator firsst, iterator last) —— 清除一段区间的所有元素
template <class T, class Alloc, size_t BufSize>
deque<T, Alloc, BufSize>::iterator
deque<T, Alloc, BufSize>::erase(iterator first, iterator last) {
//区间为整个deque,可以直接clear
if (first == start && last == finish) {
clear();
return finish;
}
else {
difference_type n = last - first; //计算两迭代器之间的距离
difference_type elems_before = first - start; //清除区间前面的元素个数
if (elems_before < (size() - n) / ) { //清除区间前方元素较少
copy_backward(start, first, last); //将前方元素往后移,全都移动last-first格
iterator new_start = start + n; //标记deque新起点
destroy(start, new_start); //新旧起点间为冗余元素,析构之
for (map_pointer cur = start.node; cur < new_start.node; ++cur)
data_allocator::deallocate(*cur, buffer_size()); //释放冗余元素空间,只释放到新起点的所在节点的前一节点
start = new_start;
}
else {//清除区间后方元素较少
copy(last, finish, first); //将后方元素往前移,全都移动last-first格
iterator new_finish = finish - n; //标记deque新尾点,后面同理
destroy(new_finish, finish);
for (map_pointer cur = new_finish.node + ; cur <= finish.node; ++cur)
data_allocator::deallocate(*cur, buffer_size());
finish = new_finish;
}
return start + elems_before;
}
}
- insert(iterator position, const value_type& x) —— 在position处插入一个元素,其值为x
iterator insert(iterator position, const value_type& x) {
//如果要插入的位置就是在第一元素的前面
if (position.cur == start.cur) {
push_front(x);
return start;
}//如果要插入的位置就是在最后一个元素的下一位置的前面
else if (position.cur == finish.cur) {
push_back(x);
iterator tmp = finish;
--tmp;
return tmp; //返回插入元素的位置
}
else {
//如果都不是,交给insert_aux完成
return insert_aux(position, x);
}
}
template <class T, class Alloc, size_t BufSize>
typename deque<T, Alloc, BufSize>::iterator
deque<T, Alloc, BufSize>::insert_aux(iterator pos, const value_type& x) {
//获取插入点之前的元素个数
difference_type index = pos - start;
value_type x_copy = x;
if (index < size() / ) { //插入点之前的元素较少
push_front(front()); //在最前端加入与第一元素值一样的元素
iterator front1 = start;
++front1; //该迭代器指向第一元素的下一元素,用于表示复制的输出区间的起始
iterator front2 = front1;
++front2; //该迭代器指向第一元素的下下元素,用于表示复制的输入区间的起始
pos = start + index; //原本pos表示的是在pos之前插入x,现在pos指向正要插入的位置(注意start因为push_front(front())而已经往前移动了)
iterator pos1 = pos;
++pos1; //该迭代器指向插入位置的下一位置,即原本pos指向的元素,用于表示复制的输入区间的末尾 即[front2, pos1)
copy(front2, pos1, front1);
}
else { //插入点之后的元素较少,处理与上类似
push_back(back());
iterator back1 = finish;
--back1;
iterator back2 = back1;
--back2;
pos = start + index;
copy_backward(pos, back2, back1);
}
*pos = x_copy; //因为pos已经指向正要插入的位置,所以直接设其值就好了
return pos;
}
STL源码剖析——序列式容器#3 Deque的更多相关文章
- STL源码剖析——序列式容器#1 Vector
在学完了Allocator.Iterator和Traits编程之后,我们终于可以进入STL的容器内部一探究竟了.STL的容器分为序列式容器和关联式容器,何为序列式容器呢?就是容器内的元素是可序的,但未 ...
- STL源码剖析——序列式容器#4 Stack & Queue
Stack stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口,元素的新增.删除.最顶端访问都在该出口进行,没有其他位置和方法可以存取stack的元素. ...
- STL源码剖析——序列式容器#2 List
list就是链表的实现,链表是什么,我就不再解释了.list的好处就是每次插入或删除一个元素,都是常数的时空复杂度.但遍历或访问就需要O(n)的时间. List本身其实不难理解,难点在于某些功能函数的 ...
- STL源码剖析——序列式容器#5 heap
准确来讲,heap并不属于STL容器,但它是其中一个容器priority queue必不可少的一部分.顾名思义,priority queue就是优先级队列,允许用户以任何次序将任何元素加入容器内,但取 ...
- STL源码剖析:算法
启 算法,问题之解法也 算法好坏的衡量标准:时间和空间,单位是对数.一次.二次.三次等 算法中处理的数据,输入方式都是左闭又开,类型就迭代器, 如:[first, last) STL中提供了很多算法, ...
- STL源码剖析之序列式容器
最近由于找工作需要,准备深入学习一下STL源码,我看的是侯捷所著的<STL源码剖析>.之所以看这本书主要是由于我过去曾经接触过一些台湾人,我一直觉得台湾人非常不错(这里不涉及任何政治,仅限 ...
- STL"源码"剖析-重点知识总结
STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点略多 :) 1.STL概述 STL提供六大组件,彼此可以组合 ...
- 【转载】STL"源码"剖析-重点知识总结
原文:STL"源码"剖析-重点知识总结 STL是C++重要的组件之一,大学时看过<STL源码剖析>这本书,这几天复习了一下,总结出以下LZ认为比较重要的知识点,内容有点 ...
- STL源码剖析读书笔记之vector
STL源码剖析读书笔记之vector 1.vector概述 vector是一种序列式容器,我的理解是vector就像数组.但是数组有一个很大的问题就是当我们分配 一个一定大小的数组的时候,起初也许我们 ...
随机推荐
- 洛谷 P2577 [ZJOI2005]午餐 题解
每日一题 day56 打卡 Analysis 算法:贪心+dp 容易想到贪心:吃饭慢的先打饭节约时间, 所以先将人按吃饭时间从大到小排序. 然后就是dp了: 首先,应该想到f[i][j][k]:前i个 ...
- MongoDB主从
环境示例: 系统:Centos6.6x64 安装目录:/opt/ 主:172.16.15.101 从:172.16.15.102 1.下载安装: # wget https://fastdl.mongo ...
- Ubuntu使用小结(主要为后面部署K8s集群做基础铺垫)
包管理 dpkg -L libxml2 #查看libxml2安装了些什么文件 dpkg -s /usr/bin/ls #查看ls是那个包提供的 dpkg -c abc.deb #查看abc. ...
- pytest以函数形式形成测试用例
#coding=utf- from __future__ import print_function #开始执行该文件时,该函数执行 def setup_module(module): print(' ...
- springboot 调用webservice
参考:https://www.liangzl.com/get-article-detail-12711.html https://www.cnblogs.com/e206842/p/9047294.h ...
- linux运维 技能 2018
1.监控与日志 prometheus.grafana.zabbix ELK(elasticsearch logstash filebeat kibana) 2.容器类 harbor映像管理 docke ...
- [技术博客]JSCover+selenium获得js代码覆盖率
本文档讲解了我们是如何使用JSCover来获得Selenium的测试样例的js代码文件的执行覆盖率的. 事实上网上有挺多博客讲这玩意儿了,不过完全按照网上已有的教程去弄的的话,并无法满足我们的需要. ...
- Java编程思想之二 一切都是对象
2.1 用引用操作对象 每种编程语言都有自己的操作内存中元素的方式. 在Java中,一切都可以视为对象,因此可以采用单一的固定语法. 2.2 必须由你创建所有对象 一旦创建一个引用,就希望它能与一个新 ...
- 【深入学习linux】CentOS 7 最小化安装后程序必须安装的组件
centos平台编译环境使用如下指令 安装make: yum -y install gcc automake autoconf libtool make 安装g++: yum install gcc ...
- CentOS7 增加回环地址
添加回环地址的命令和说明如下: #添加一个回环地址到lo网卡,添加多个可以改lo:后边的序号 [要添加的地址] netmask 255.255.255.255 broadcast [要添加的地址] # ...