Python之TensorFlow的(案例)验证码识别-6
一、这里的案例相对比较简单,主要就是通过学习验证码的识别来认识深度学习中我们一般在工作中,需要处理的东西会存在哪些东西。
二、因为我没有数据集,没有关系,这里自己写了一个数据集,来做测试,为了方便我把这个数据集,写成了*.tfrecords格式的文件。
三、生成数据集
1)生成验证码图片
# 生成验证码训练集
def gen_captcha():
captcha_char_list = list("0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ")
font = ImageFont.truetype(font="font/msyh.ttf", size=36)
for n in range(2000):
image = Image.new('RGB', (200, 50), (255, 255, 255))
draw = ImageDraw.Draw(image)
chars = ""
for i in range(5):
captcha_char = captcha_char_list[random.randint(0, 25)]
chars += captcha_char
draw.text((10 + i * 40, 0), captcha_char, (0, 0, 0), font=font)
image.save(open("data/captcha/" + chars + ".png", 'wb'), 'png')
说明:我这里都是采用的白底黑字的方式来写的,字体使用微软的字体。如果需要做干扰,可以自己在网上查找教程
2)写入tfrecords格式文件
# 将图片数据和目标值写到tfrecords文件中
def captcha_data_write():
# 获取图片名称和所有数据
file_names, image_batch = get_image_name_batch() # 获取目标值
target = get_target(file_names) # 写入文件
write_tf_records(image_batch, target) def get_image_name_batch():
# 1、读取图片目录,生成文件名称列表
file_names = os.listdir("data/captcha")
file_list = [os.path.join("data/captcha", file_name) for file_name in file_names]
print(file_list)
# 2、放入队列(shuffle=False,一定要设置,不然会乱序)
file_queue = tf.train.string_input_producer(file_list, shuffle=False)
# 3、读取图片数据
reader = tf.WholeFileReader()
key, value = reader.read(file_queue)
# 4、解码图片数据
image = tf.image.decode_png(value)
# 改变形状(根据具体的图片大小来)
image.set_shape([50, 200, 3])
# 5、获取图片批次
image_batch = tf.train.batch([image], batch_size=2000, num_threads=1, capacity=2000)
return file_names, image_batch def get_target(file_names):
# 6、获取目标值
labels = [file_name.split(".")[0] for file_name in file_names]
print(labels)
# 7、将目标值装换成具体数值
captcha_char = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# 转换成字典,然后反转(0:0, 1:1, ...,z:35)
num_char = dict(enumerate(list(captcha_char)))
char_num = dict(zip(num_char.values(), num_char.keys()))
# 8、构建标签列表
array = []
for label in labels:
nums = []
for char in label:
nums.append(char_num[char])
array.append(nums)
# [[2, 11, 8, 2, 7] ...]
print(array)
# 9、转换为tensor张量,注意这里的类型一定要给出来,这里我踩过坑,如果没有,读数据是存在问题的
target = tf.constant(array, dtype=tf.uint8)
return target def write_tf_records(image_batch, target):
# 10、上面主要准备图片数据和目标值,下面主要是写入到*.tfrecords中
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 运算获取图片批次数据
image_batch = sess.run(image_batch)
# 转换一下数据为uint8
image_batch = tf.cast(image_batch, tf.uint8)
# 写入数据
with tf.python_io.TFRecordWriter("data/tf_records/captcha.tfrecords") as writer:
for i in range(2000):
# 全部使用string保存
image_string = image_batch[i].eval().tostring()
label_string = target[i].eval().tostring()
example = tf.train.Example(features=tf.train.Features(feature={
"image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_string])),
"label": tf.train.Feature(bytes_list=tf.train.BytesList(value=[label_string]))
}))
writer.write(example.SerializeToString())
print("写入第%d数据" % (i + 1))
coord.request_stop()
coord.join(threads)
四、训练和测试
def captcha_train_test(n):
# 读取数据
image_batch, label_batch = tfrecords_read_decode() # 1、建立占位符(数据更具图片和目标数据而定)
with tf.variable_scope("data"):
x = tf.placeholder(dtype=tf.uint8, shape=[None, 50, 200, 3], name="x")
label = tf.placeholder(dtype=tf.uint8, shape=[None, 5], name="label") # 2、建立模型
y_predict = model(x) # y_predict为[None, 5 * 36] label_batch为[None, 5], 因此需要one-hot[None, 5, 36]
y_true = tf.one_hot(label, depth=36, axis=2, on_value=1.0, name="one_hot")
# 需要变形为[None 5 * 36]
y_true_reshape = tf.reshape(y_true, [-1, 5 * 36], name="y_true_reshape") # 4、计算损失值
with tf.variable_scope("loss"):
softmax_cross = tf.nn.softmax_cross_entropy_with_logits(labels=y_true_reshape, logits=y_predict)
loss = tf.reduce_mean(softmax_cross) # 5、训练
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss=loss) # 6、计算准确率
with tf.variable_scope("accuracy"):
# 因为这里的真实值是2维结果,所以需要把y_predict,转化为2位数据
equal_list = tf.equal(tf.argmax(y_true, axis=2), tf.argmax(tf.reshape(y_predict, [-1, 5, 36]), 2))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32)) # 收集数据
tf.add_to_collection("y_predict", y_predict)
if n == 1:
# 7、会话
with tf.Session() as sess:
# 变量初始化
sess.run(tf.global_variables_initializer()) coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord) saver = tf.train.Saver()
# 如果模型存在,则加载模型
if os.path.exists("model/captcha/checkpoint"):
saver.restore(sess, "model/captcha/captcha") for i in range(2000):
# 读取数据
# 训练,记住这里的数据类型为uint8需要转换为tf.float32
image_train, label_train = sess.run([image_batch, label_batch])
sess.run(train_op, feed_dict={x: image_train, label: label_train})
# 保存模型
if (i + 1) % 100 == 0:
saver.save(sess, "model/captcha/captcha")
acc = sess.run(accuracy, feed_dict={x: image_train, label: label_train})
print("第%d次,准确率%f" % ((i + 1), acc)) coord.request_stop()
coord.join(threads)
else:
# 1、读取指定目录下图片数据
file_names_test = os.listdir("data/captcha_test")
file_list_test = [os.path.join("data/captcha_test", file_name) for file_name in file_names_test]
file_queue_test = tf.train.string_input_producer(file_list_test, shuffle=False)
# 2、读取和解码数据
reader = tf.WholeFileReader()
key, value = reader.read(file_queue_test)
image = tf.image.decode_png(value)
image.set_shape([50, 200, 3])
# 3、批处理
image_batch_test = tf.train.batch([tf.cast(image, tf.uint8)], batch_size=len(file_names_test), capacity=len(file_names_test))
# 4、加载模型
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 1、加载模型
saver = tf.train.Saver()
saver.restore(sess, "model/captcha/captcha") # 4、预测[None, 5 * 36]
predict = sess.run(y_predict, feed_dict={x: sess.run(image_batch_test)})
captcha_list = list("0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ")
for i in range(len(file_names_test)):
predict_reshape = tf.reshape(predict, [-1, 5, 36])
captcha = ""
for j in range(5):
captcha += captcha_list[tf.argmax(predict_reshape[i][j], 0).eval()]
print("预测值:%s, 真实值:%s" % (captcha, file_names_test[i].split(".")[0]))
coord.request_stop()
coord.join(threads) def model(x):
# # 第一层卷积
# with tf.variable_scope("conv_1"):
# # 卷积[None, 50, 200, 3] -> [None, 50, 200, 32]
# w_1 = gen_weight([5, 5, 3, 32])
# b_1 = gen_bias([32])
# # 在进行模型计算的时候需要使用tf.float32数据进行计算
# x_conv_1 = tf.nn.conv2d(tf.cast(x, tf.float32), filter=w_1, strides=[1, 1, 1, 1], padding="SAME") + b_1
# # 激活
# x_relu_1 = tf.nn.relu(x_conv_1)
# # 池化[None, 50, 200, 32] -> [None, 25, 100, 32]
# x_pool_1 = tf.nn.max_pool(x_relu_1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# # 第二层卷积
# with tf.variable_scope("conv_2"):
# # 卷积[None, 25, 100, 32] -> [None, 25, 100, 64]
# w_2 = gen_weight([5, 5, 32, 64])
# b_2 = gen_bias([64])
# x_conv_2 = tf.nn.conv2d(x_pool_1, filter=w_2, strides=[1, 1, 1, 1], padding="SAME") + b_2
# # 激活
# x_relu_2 = tf.nn.relu(x_conv_2)
# # 池化[None, 25, 100, 64] -> [None, 13, 50, 64]
# x_pool_2 = tf.nn.max_pool(x_relu_2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# # 全连接层
# with tf.variable_scope("full_connection"):
# # 生成权重和偏置
# # 为什么是5 * 36主要是我们的字符串个数36个,使用one-hot.每个值为36个值,一个验证码5个值,所以为5 * 36个
# w_fc = gen_weight([13 * 50 * 64, 5 * 36])
# b_fc = gen_bias([5 * 36])
# # 修改数据形状
# x_fc = tf.reshape(x_pool_2, shape=[-1, 13 * 50 * 64])
# # [None, 5 * 36]
# y_predict = tf.matmul(x_fc, w_fc) + b_fc
with tf.variable_scope("model"):
# 生成权重和偏置
# 为什么是5 * 36主要是我们的字符串个数36个,使用one-hot.每个值为36个值,一个验证码5个值,所以为5 * 36个
w_fc = gen_weight([50 * 200 * 3, 5 * 36])
b_fc = gen_bias([5 * 36])
# 修改数据形状
x_fc = tf.reshape(tf.cast(x, tf.float32), shape=[-1, 50 * 200 * 3])
# [None, 5 * 36]
y_predict = tf.matmul(x_fc, w_fc) + b_fc
return y_predict # 生成权重值
def gen_weight(shape):
return tf.Variable(tf.random_normal(shape=shape, mean=0.0, stddev=1.0, dtype=tf.float32)) # 生成偏值
def gen_bias(shape):
return tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=shape)) # 读取数据
def tfrecords_read_decode():
# 将文件加入队列
file_queue = tf.train.string_input_producer(["data/tf_records/captcha.tfrecords"])
# 读取tfrecords文件
reader = tf.TFRecordReader()
key, value = reader.read(file_queue)
# value的格式为example
features = tf.parse_single_example(value, features={
"image": tf.FixedLenFeature([], tf.string),
"label": tf.FixedLenFeature([], tf.string)
})
# 解码
image_data = tf.decode_raw(features["image"], tf.uint8)
label_data = tf.decode_raw(features["label"], tf.uint8)
# 改变形状
image_reshape = tf.reshape(image_data, [50, 200, 3])
label_reshape = tf.reshape(label_data, [5])
# 获取批次数据
image_batch, label_batch = tf.train.batch([image_reshape, label_reshape], batch_size=200, num_threads=1, capacity=200)
return image_batch, label_batch
说明:因为我这里使用的是cpu计算,所以速度上面会很慢,为了看到效果,我这里,使用的全连接层,实际可以使用卷积神经网络测试。
one-hot:中间有一步是进行了数据one-hot处理的,也就是[5, 23, 15, 20]-->[[0,0,0,0,1,...],[0,0,0,...,1,...],[0,0,0,...,1,...],[0,0,0,...,1,...]]这样的形式。为什么要这样做呢?目的是为了计算,在前面的类别我们说明过,计算得出的是概率,这里的5是验证码数据的下标,不是概率。我们为了计算概率就需要得出,预测中得出每一个值的概率,然后选取最大的值。
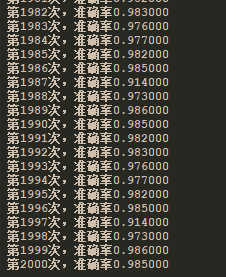
训练结果:
测试结果:
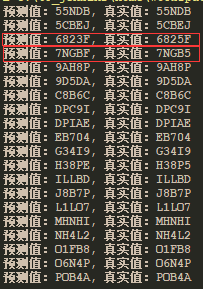
可以看出,测试结果,还是存在错误的情况,不过从准确率上面来说还是很不错了。
Python之TensorFlow的(案例)验证码识别-6的更多相关文章
- 基于TensorFlow的简单验证码识别
TensorFlow 可以用来实现验证码识别的过程,这里识别的验证码是图形验证码,首先用标注好的数据来训练一个模型,然后再用模型来实现这个验证码的识别. 生成验证码 首先生成验证码,这里使用 Pyth ...
- Pyhthon爬虫其之验证码识别
背景 现在的登录系统几乎都是带验证手段的,至于验证的手段也是五花八门,当然用的最多的还是验证码.不过纯粹验证码识已经是很落后的东西了,现在比较多见的是滑动验证,滑动拼图验证(这个还能往里面加广告).点 ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
- tensorflow实现验证码识别案例
1.知识点 """ 验证码分析: 对图片进行分析: 1.分割识别 2.整体识别 输出:[3,5,7] -->softmax转为概率[0.04,0.16,0.8] - ...
- Python实现各类验证码识别
项目地址: https://github.com/kerlomz/captcha_trainer 编译版下载地址: https://github.com/kerlomz/captcha_trainer ...
- 字符型图片验证码识别完整过程及Python实现
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- 基于tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的人工智能技术的发展 ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- TensorFlow验证码识别
本节我们来用 TensorFlow 来实现一个深度学习模型,用来实现验证码识别的过程,这里我们识别的验证码是图形验证码,首先我们会用标注好的数据来训练一个模型,然后再用模型来实现这个验证码的识别. 验 ...
- 使用TensorFlow 来实现一个简单的验证码识别过程
本文我们来用 TensorFlow 来实现一个深度学习模型,用来实现验证码识别的过程,这里识别的验证码是图形验证码,首先我们会用标注好的数据来训练一个模型,然后再用模型来实现这个验证码的识别. 1.验 ...
随机推荐
- uiautomator2使用教程
一.要求 python 3.6+ android 4.4+ 二.介绍 uiautomator2 是一个可以使用Python对Android设备进行UI自动化的库.其底层基于Google uiaut ...
- socket http tcp ip 区别联系
功能是实现继承复用.刚才做了一个简要的概述,里面有一些常用的概念,这里做个简短的概念普及介绍:(1),TCP/IP------TPC/IP协议是传输层协议,主要解决数据如何在网络中传输.(2),Soc ...
- 刷题记录:[CISCN2019 东北赛区 Day2 Web3]Point System
目录 刷题记录:[CISCN2019 东北赛区 Day2 Web3]Point System 知识点 1.padding-oracle attack 2.cbc字节翻转攻击 3.FFMpeg文件读取漏 ...
- TTA 方法
可将准确率提高若干个百分点,它就是测试时增强(test time augmentation, TTA). 这里会为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中: 然 ...
- jmeter BeanShell断言(四)
Bean Shell常用内置变量 JMeter在它的BeanShell中内置了变量,用户可以通过这些变量与JMeter进行交互,其中主要的变量及其使用方法如下: log:写入信息到jmeber.log ...
- EOS测试链智能合约部署调用
ETH与EOS两者智能合约进行简单的对比. 1.编译智能合约(合约编译成.wasm与.abi格式后即可部署到区块链) [root@C03-12U-26 testcontract]# cat testc ...
- python带参数的类装饰器
# -*- coding: utf-8 -*- # author:baoshan # 带参数的类装饰器(和不带参数的类装饰器有很大的不同) # 类装饰器的实现,必须实现__call__和__init_ ...
- mysql 某表某列支持 emoji
ALTER TABLE `customer_user` MODIFY COLUMN `UserName` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8 ...
- matlab学习笔记10 一般运算符
一起来学matlab-matlab学习笔记10 10_1一般运算符 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考书籍 <matlab 程序设计与综合应用>张德丰等著 感谢张 ...
- accept 和 content-Type区别
accept表示 客服端(浏览器)支持的类型,也是希望服务器响应发送回来的的数据类型. 例如:Accept:text/xml; ,也就是希望服务器响应发送回来的是xml文本格式的内容 区别: 1.Ac ...