爬虫多次爬取时候cookie的存储用于登入
一.用requests模块自动保存(保存缓存中)
构建一个session对象session = requests.session()
用构建的session代替requests进行访问他就会自动存啦
import requests
session = requests.session()
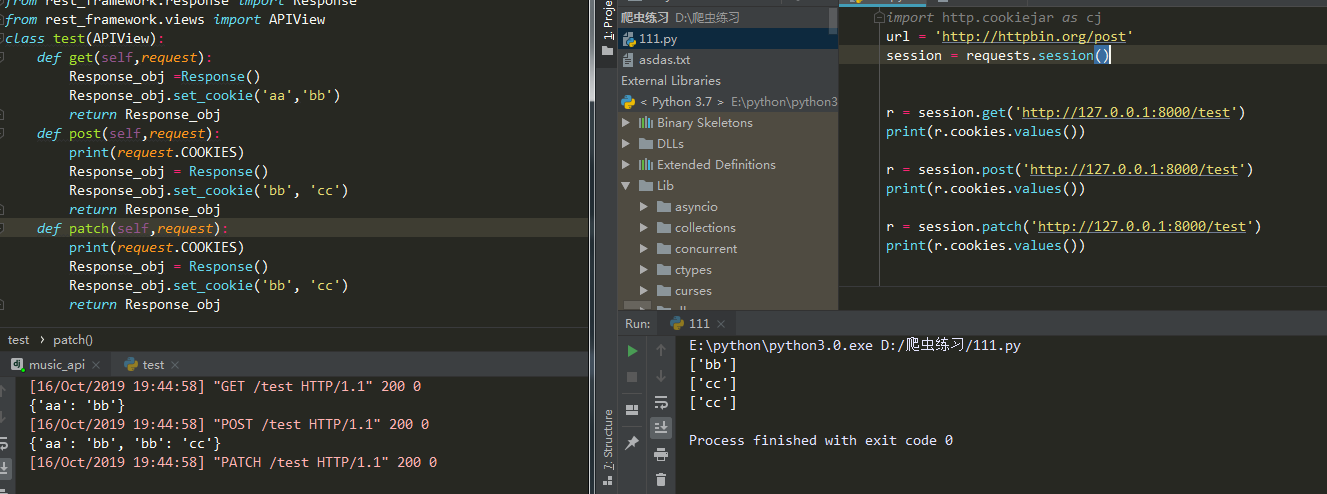
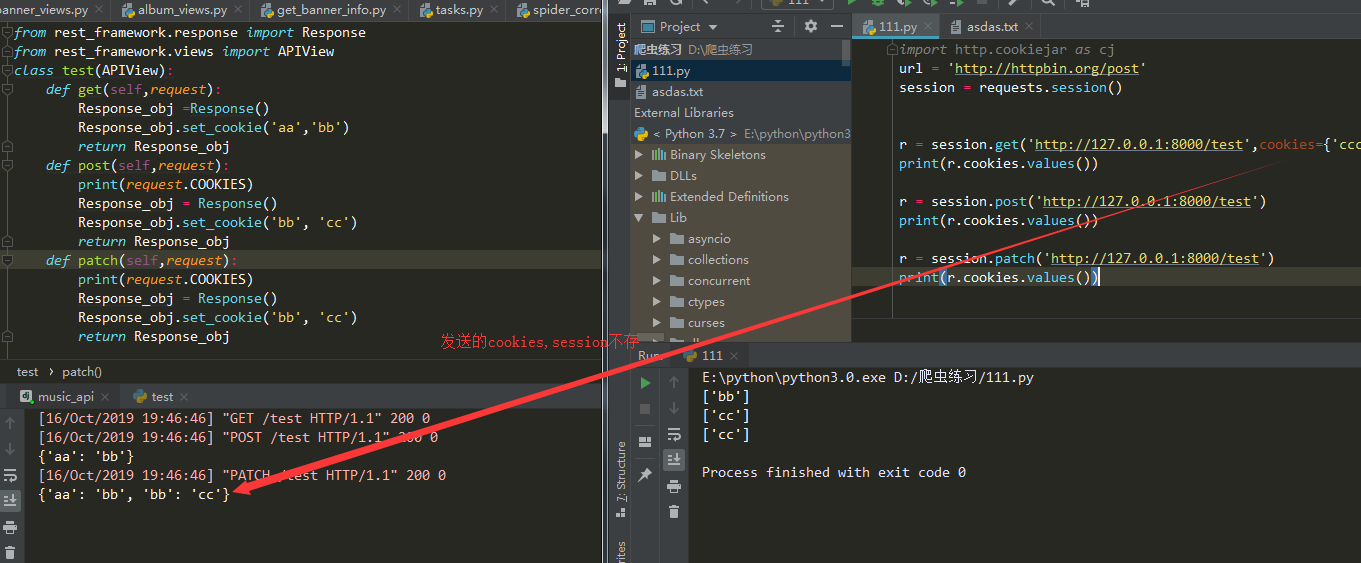
r = session.get(......) #他会存返回的cookies不会存发送的cookies
r = session.post(......) #在请求同一url他会把存的cookies发送过去
注意点
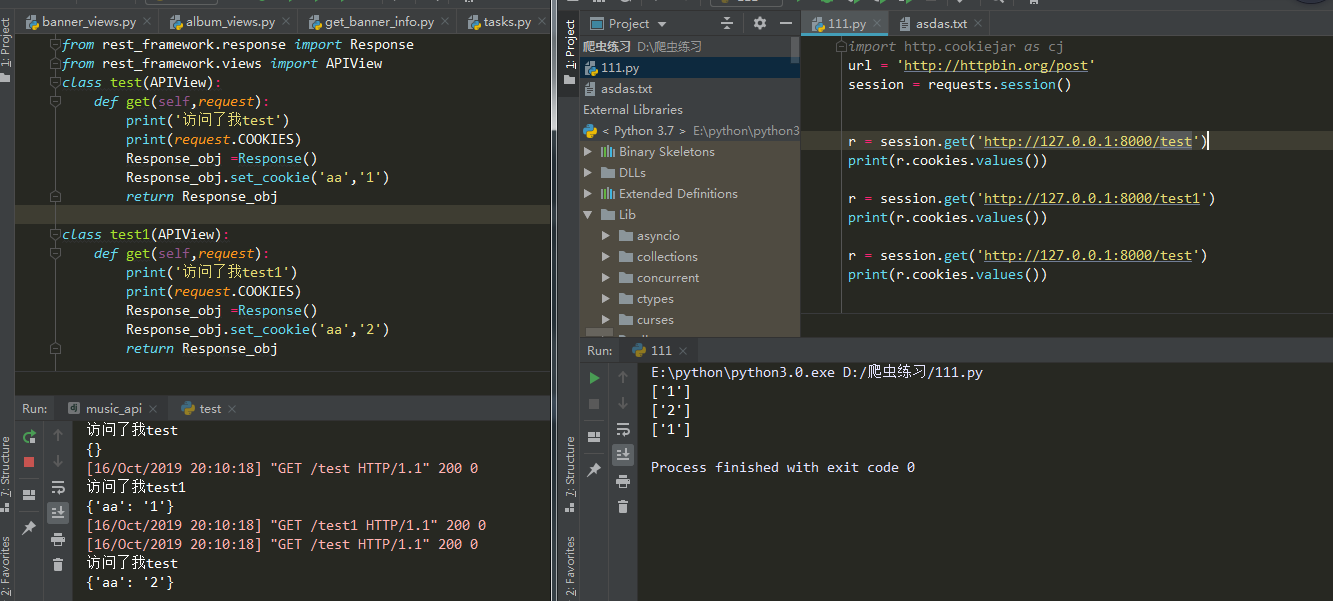
- 只存响应的cookie
- 不存发送请求时候带的cookie
- 不同url没有影响
- cookie名字一样会覆盖掉
原因自己看下面自己看哈,有问题可以私聊我

二.将cookie存本地
1.基于session(推荐使用代码少哈哈)
import requests
from http import cookiejar
session =requests.session()
session.cookies = cookiejar.LWPCookieJar() #MozillaCookieJar或LWPCookieJar。
session.cookies.save(filename='1.txt') //存cookie
session.cookies.load(filename='1.txt') //读cookie
2.普通请求把cookies存本地
这个参照https://www.cnblogs.com/fu-yong/p/9032902.html
第一次访问
from urllib import request,parse
from http import cookiejar
# 创建filecookiejar实例对象
# 它需要一个参数,既cookie保存的位置
filename = 'cookie.txt'
cookie = cookiejar.FileCookieJar(filename)
# 根据创建的cookie生成cookie的管理器
cookie_handle = request.HTTPCookieProcessor(cookie)
# 创建http请求管理器
http_handle = request.HTTPHandler()
# 创建https管理器
https_handle = request.HTTPSHandler()
# 创建求求管理器,将上面3个管理器作为参数属性
# 有了opener,就可以替代urlopen来获取请求了
opener = request.build_opener(cookie_handle,http_handle,https_handle)
# 登录url,需要从登录form的action属性中获取
url = 'xxxxxxxxxxxxxx'
# 登录所需要的数据,数据为字典形式,
# 此键值需要从form扁担中对应的input的name属性中获取
data = {
'email':'xxxx',
'password':'xxxxx'
}
# 将数据解析成urlencode格式
data = parse.urlencode(data)
req = request.Request(url,data=data)
# 正常是用request.urlopen(),这里用opener.open()发起请求
response = opener.open(req)
# 保存cookie文件
cookie.save()
第二次访问
from urllib import request,parse
from http import cookiejar
# 创建cookiejar实例对象
cookie = cookiejar.FileCookieJar()
# 读取已经保存的cookie文件
# 读取之后,就无需登录,直接访问主页即可
cookie.load('cookie.txt')
# 根据创建的cookie生成cookie的管理器
cookie_handle = request.HTTPCookieProcessor(cookie)
# 创建http请求管理器
http_handle = request.HTTPHandler()
# 创建https管理器
https_handle = request.HTTPSHandler()
# 创建求求管理器,将上面3个管理器作为参数属性
# 有了opener,就可以替代urlopen来获取请求了
opener = request.build_opener(cookie_handle,http_handle,https_handle)
url = 'http://xxxxxx'
res = opener.open(url)
html = res.read().decode()
with open('renren.html','w') as f:
f.write(html)
爬虫多次爬取时候cookie的存储用于登入的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- ubuntu之路——day19.1 深度CNN的探究
1.经典的CNN LeNet-5 1998的CNN鼻祖 以前用的sigmoid和tanh 下图给的是relu和softmax AlexNet ImageNet2012的冠军 VGG-16 ImageN ...
- sqlserver cdc用法
SELECT top(10) * from (SELECT sys.fn_cdc_map_lsn_to_time([__$start_lsn]) 'addtime',* FROM cdc.dbo ...
- 面试突击(六)——JVM如何实现JAVA代码一次编写到处运行的?
声明:本文图片均来自网络,我只是进行了选择,利用一图胜千言的力量来帮助自己快速的回忆相关的知识点 JVM是 JAVA Virtual Machine 三个英文单词的首字母缩写,翻译成中文就是Java虚 ...
- postgre查询一段时间内的数据
select * from zaiko where createtime between (now() - interval '3 Days') and now() ; select * from z ...
- ES技巧
2, 统计字段b的不同值的数量 {"size":0,"aggs":{"distinct_colors":{"cardinality ...
- Ubuntu 16.04 Roboware Turtlesim 测试
博客参考:https://www.jianshu.com/p/5509c8ba522b?utm_campaign 利用Turtlesim,编写简单的消息发布器和订阅器 1. Twist消息,它的Top ...
- mac环境更新node版本
执行命令: 清除node的cache(清除node的缓存) sudo npm cache clean -f 安装"n"版本管理工具,管理node(没有错,就是n) sudo npm ...
- kerberos相关
1.kerberos认证覆盖问题 先显示指定KRB5CCNAME存储的路径 export KRB5CCNAME=/tmp/krb5cc_xxx kinit -kt /home/xxx.keytab x ...
- Python模块学习filecmp文件比较
Python模块学习filecmp文件比较 filecmp模块用于比较文件及文件夹的内容,它是一个轻量级的工具,使用非常简单.python标准库还提供了difflib模块用于比较文件的内容.关于dif ...
- Spring MVC -- 单元测试和集成测试
测试在软件开发中的重要性不言而喻.测试的主要目的是尽早发现错误,最好是在代码开发的同时.逻辑上认为,错误发现的越早,修复的成本越低.如果在编程中发现错误,可以立即更改代码:如果软件发布后,客户发现错误 ...