【TIDB】1、TiDb简介
一 TiDb简介
TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP(Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。TiDB 具备如下核心特点:
1 高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
2水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
3分布式事务
TiDB 100% 支持标准的 ACID 事务。
4 真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
5 一站式 HTAP 解决方案
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP解决方案,一份存储同时处理OLTP & OLAP(OLAP、OLTP的介绍和比较 )无需传统繁琐的 ETL 过程。
6云原生 SQL 数据库
TiDB 是为云而设计的数据库,同 Kubernetes (十分钟带你理解Kubernetes核心概念 )深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。 TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力.
二 TiDb 整体架构
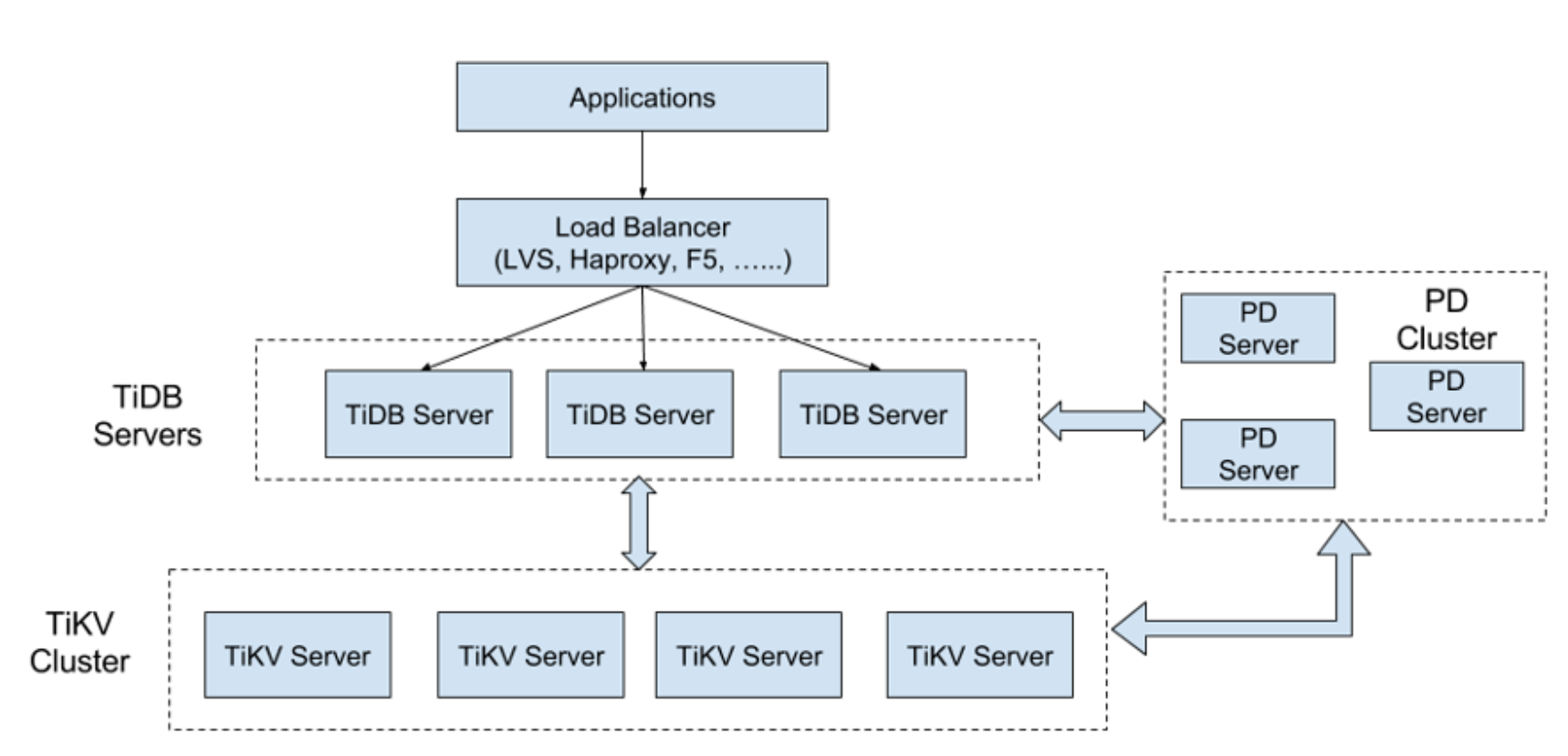
TiDB 集群主要分为三个组件:
1TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或F5)对外提供统一的接入地址。
2PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
3TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 RaftGroup,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
三 核心特性
1 水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
2 高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
TiKV
TiKV 是一个集群,通过 Raft 协议(raft一致性哈算法以及Raft 为什么是更易理解的分布式一致性算法 )保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 30 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
四 TiDb技术内幕
1 保存数据 TiDB 技术内幕 - 说存储
2 计算(很关键如何做sql运算) TiDB 技术内幕 - 说计算
3 调度(Tidb集群管理) TiDB 技术内幕 - 谈调度
五 安装部署
tidb安装部署,可能比较麻烦,一步步照着做,如果公司有专门的运维,这个工作可以由运维来搞,但是大多数的中小公司是没有的,都是开发者兼职运维,所以作为一个开发者,还是了解下比较好。 安装部署
参考:
【TIDB】1、TiDb简介的更多相关文章
- tidb 架构 ~Tidb学习系列(5)
一 简介:今天我们继续学习tidb的增量传输 二 说明: tidb高度兼容mysql,可以仿照mysql的主从同步复制机制实现mysql->tidb的增量传输 三 实验: 1 下载tidb官方工 ...
- tidb 架构 ~Tidb学习系列(4)
一 简介:今天我们继续学习tidb 二 集群管理 0 集群配置 验证 4台一组 3个kv 一个pd+server 上线 6台一组 1 动态添加kv服务 nohu ...
- tidb 架构 ~Tidb学习系列(2)
一 简介:咱们今天来学习导入数据篇 二 导入数据测试 1 工具 mysqldumper loader 2 下载tidb企业版工具 wget http://download.ping ...
- tidb 架构~tidb 理论学习(1)
一 简介:介绍新型NEW SQL数据库tidb 二 目的: tidb出现的目的,就是代替mysql+中间件,实现横向水平扩展 三 核心理论观点 1 MySQL 是单机数据库,只能通过 XA 来满足跨数 ...
- tidb 架构 ~Tidb学习系列(1)
一 简介:今天来研究Tidb 二 安装测试: 0 下载Tidb wget http://download.pingcap.org/tidb-latest-linux-amd64.tar.gz 按如 ...
- tidb 架构 ~Tidb学习系列(3)
tidb集群安装测试1 环境 3台机器2 配置 server1 pd服务+tidb-server server2 tidb-kv server3 tidb-kv3 环境配置命令 ser ...
- TiDB
由于目前的项目把mysql换成了TiDb,所以特意来了解下tidb.其实也不能说换,由于tidb和mysql几乎完全兼容,所以我们的程序没有任何改动就完成了数据库从mysql到TiDb的转换,TiDB ...
- 遇见 TiDB
遇见 TiDB 文章来源:企鹅号 - 塔塔驿站 最近TiDB掀起了一波分布式数据库的热潮,公司也在着手准备TiDB的落地工作,前几天也参与了几场公司针对TiDB的分享会,下面我们了解一下关于TiDB. ...
- TiDB入门(四):从入门到“跑路”
前言 前面三章基本把 TiDB 的环境弄好了,也做了一下简单测试,有兴趣的同学可以看一下: TiDB 入门(一):TiDB 简介 TiDB 入门(二):虚拟机搭建 TiDB-Ansible 部署方案 ...
随机推荐
- 初学hash
hash定义: Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值.这种转换是一种 ...
- IIS301重定向:将不带www的域名跳转到带www上
首先你的域名有这两条解析记录 进入服务器IIS,添加2个站点,如下图 第一个正常绑定你的域名:www.baidu.com 第二个绑定不带www的域名:baidu.com 然后点开ncgd-no-www ...
- Java面试题大全(javaSe,HTML,CSS,js,Spring框架等)
目录 1. Java基础部分 7 1.一个".java"源文件中是否可以包括多个类(不是内部类)?有什么限制? 7 2.Java有没有goto? 7 3.说说&和& ...
- 如何相互转换逗号分隔的字符串和List --https://blog.csdn.net/yywusuoweile/article/details/50315377
如何相互转换逗号分隔的字符串和List ---https://blog.csdn.net/yywusuoweile/article/details/50315377 方法 2: 利用Guava的Joi ...
- python 线程进程
一 线程的2种调用方式 直接调用 实例1: import threading import time def sayhi(num): #定义每个线程要运行的函数 print("runni ...
- noip模拟赛 whzzt-Conscience
分析:数据中并不存在无解的情况...... 每个摄像头都要覆盖尽可能多的点,按照y从小到大排序.对于每一列,只用判断第一个没有被观测到的就可以了,这个点必须要放摄像头,因为除了它自己没有其它的摄像头能 ...
- [bzoj1617][Usaco2008 Mar]River Crossing渡河问题_动态规划
River Crossing渡河问题 bzoj-1617 Usaco-2008 Mar 题目大意:题目链接. 注释:略. 想法:zcs0724出考试题的时候并没有发现这题我做过... 先把m求前缀和, ...
- MAPZONE GIS SDK接入Openlayers3之三——瓦片数据集接入
瓦片数据集接入实现思路: 1.构造ol.source.TileImage数据源,构造该数据源需要以下几项: 1)空间参考,通过如下代码构造 2)TileGrid,构造需要以下几项: a)原点 b)分辨 ...
- pga_aggregate_target, sga_target, memory_target
对于这三个参数有一些了解,但是又有一些疑惑. pga_aggregate_target 最初的了解: 这个参数控制着PGA的大小,如果work_area_policy 设置成auto,则oracle采 ...
- memory management in oracle 11G R2
When we talking about memory management in Oracle, we are refering to SGA and PGA. The management me ...