Hibernate-01 入门
学习任务
- Hibernate开发环境的搭建
- 使用Hibernate对单表进行增删改操作
- 使用Hibernate按照数据表主键查询
关于Hibernate
简介
- Hibernate的创始人Gavin King:EJB 3.0专家委员会成员、JBoss核心成员之一、《Hibernate in Action》的作者
- Gavin King 于2003年推出Hibernate
- Hibernate是优秀的Java持久化层解决方案
- Hibernate封装了JDBC访问数据库操作,向上层应用提供了面向对象的访问API
- 是主流的对象-关系映射工具
优点
- 简化了JDBC 繁琐的编码,提高持久化代码开发速度,降低了维护成本
- 对面向对象特性支持良好:vo(领域)驱动面向对象进行程序设计和开发
- 数据库依赖度低,可移植性好
- 框架开源、可以改写代码、定制功能、可扩展性良好
缺点
- 不适合需要使用数据库的特定优化机制的情况和大量存储过程的数据中心
- 不适合处理大规模的插入、修改、删除数据处理
与MyBatis的比较
- Hibernate和MyBatis都是ORM框架,为数据层提供了持久化操作支持
- 相对于MyBatis的“SQL-Mapping”的ORM实现,Hibernate的ORM实现更加完善,提供了对象状态管理、级联操作等功能
- 完全面向对象,语句与数据库无关,开发者无需关注SQL的生成,开发简单,便于修改,数据库移植性好
- 由于直接使用SQL,MyBatis使用自由度较高。在不考虑缓存的情况下,MyBatis的执行效率高于Hibernate。
使用Hibernate的步骤
第一步:下载所需jar文件
Hibernate的官方网站:http://hibernate.org
托管网站:https://sourceforge.net/projects/hibernate/files
下载hibernate并解压
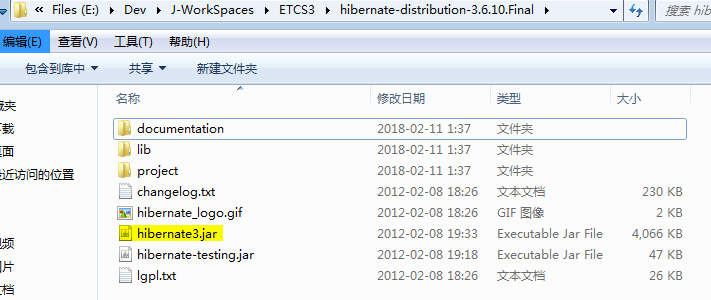
hibernate3所需支持jar,在hibernate目录下
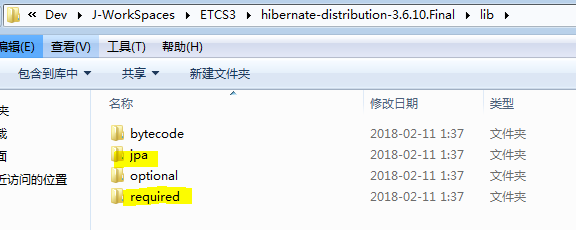
除了需要hibreante,还需要下载log4j,需要log4j日志框架的支持
数据库驱动
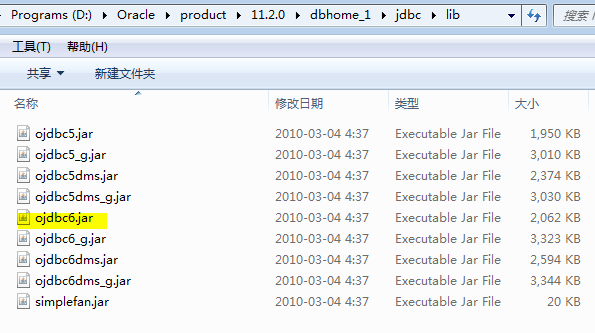
Hibernate课程使用Oracle数据库,需要添加Oracle安装目录下的驱动jar,位置为:
第二步:创建Web项目,在web-inf/lib目录中添加jar
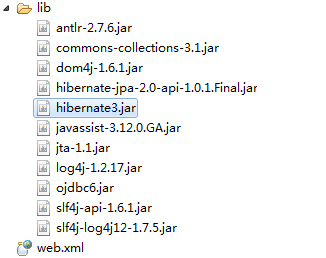
jar包说明
| 名称 | 解释说明 |
| antlr-2.7.6.jar | 语法分析器。分析Hibernate的关联映射,并解析HQL语句,转换为SQL执行数据持久化操作。 |
| commons-collections-3.1.jar | Java集合类和工具类的封装。为Java标准的Collections API提供了相当好的补充。在此基础上对其常用的数据结构操作进行了很好的封装、抽象和补充。保证性能的同时大大简化代码。 |
| dom4j-1.6.1.jar | XML文件解析和访问。 |
| hibernate-jpa-2.0-api-1.0.1.Final.jar | 提供对JPA规范的支持。JPA是Java持久化API,提供了对对象的注解或者XML描述进行持久化的能力。 |
| hibernate3.jar | Hibernate3核心接口和类。 |
| javassist-3.12.0.GA.jar | 分析、编辑和创建Java字节码的jar包。 |
| jta-1.1.jar | Java事务API。JTA事务比JDBC事务更强大。一个JTA事务可以有多个参与者,而一个JDBC事务则被限定在一个单一的数据库连接。Java事务API(JTA:Java Transaction API)和它的同胞Java事务服务(JTS:Java Transaction Service),为J2EE平台提供了分布式事务服务(distributed transaction)。 |
| ojdbc6.jar | Oracle11g数据库JDBC驱动。 |
| log4j-1.2.17.jar | 日志处理框架。 |
| slf4j-api-1.6.1.jar | 将Hibernate的日志信息输出到日志处理框架,例如输出到Log4j中。 |
| slf4j-log4j12-1.7.5.jar | Log4j日志处理框架适配器。链接slf4j-api和log4j的中间适配器。它实现了slf4j-api中StaticLoggerBinder接口,从而使得在编译时绑定的是slf4j-log4j12的getSingleton()方法 |
log4j-1.2.17.jar、slf4j-api-1.6.1.jar和slf4j-log4j12-1.7.5.jar的关系。
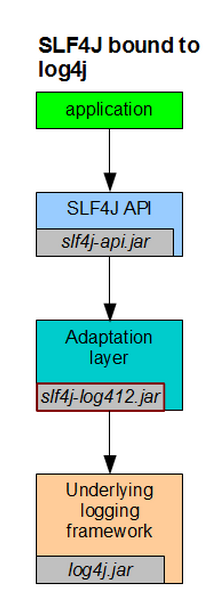
当系统采用log4j作为日志框架实现的调用关系:
1.首先系统包含slf4j-api作为日志接入的接口;
2.在编译阶段,slf4j-api中public final class LoggerFactor类中private final static void bind() 方法会寻找具体的日志实现类绑定,主要通过StaticLoggerBinder.getSingleton()方法调用
3.slf4j-log4j12的作用:链接slf4j-api和log4j中间的适配器。它实现了slf4j-api中StaticLoggerBinder接口,从而使得在编译时绑定的是slf4j-log4j12的getSingleton()方法。
4.log4j是具体的日志处理系统。通过slf4j-log4j12初始化Log4j,达到最终日志的输出。
第三步:创建Hibernate配置文件和日志配置文件
myeclipse2014的XMLcatalog中,已经提供了hibernate3.0配置文件和映射文件DTD。
hibernate.cfg.xml文件的编写
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<!--session-factory的name属性值表示JNDI,如果没有配置jndi会报错 -->
<!-- <session-factory name="foo"> -->
<session-factory>
<!-- 取消持久化验证:Hibernate 3.6以上版本在用junit测试时会提示错误 -->
<property name="javax.persistence.validation.mode">none</property>
<!-- 数据库连接url -->
<property name="connection.url">jdbc:oracle:thin:@localhost:1521:orcl</property>
<!-- 数据库用户 -->
<property name="connection.username">scott</property>
<!-- 数据库用户密码 -->
<property name="connection.password">tiger</property>
<!-- 数据库驱动 -->
<property name="connection.driver_class">oracle.jdbc.driver.OracleDriver</property>
<!-- 数据库方言(特性) -->
<property name="dialect">org.hibernate.dialect.Oracle10gDialect</property>
<!-- 指定session范围和上下文 -->
<property name="current_session_context_class">thread</property>
<!-- 是否将运行期间生成的sql输出到日志作为调试信息 -->
<property name="show_sql">true</property>
<!-- 是否格式化显示SQL语句 -->
<property name="format_sql">true</property>
<!-- 配置映射文件 -->
<mapping resource="com/etc/entity/Dept.hbm.xml" />
</session-factory>
</hibernate-configuration>
log4j.properties的编写
### 设置Logger输出级别和输出目的地 ###
#日志记录器输出级别:fatal > error > warn > info >debug#
log4j.rootLogger=debug,stdout,logfile ### 把日志信息输出到控制台 ###
#日志信息输出到控制台#
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
#信息打印到System.err上 #
log4j.appender.stdout.Target=System.err
#指定日志布局类型#
log4j.appender.stdout.layout=org.apache.log4j.SimpleLayout ### 把日志信息输出到文件:etc.log ###
#日志信息写到文件中 #
log4j.appender.logfile=org.apache.log4j.FileAppender
#指定日志输出的文件名#
log4j.appender.logfile.File=${webApp.root}/logs/app.log
#指定转换模式#
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
#指定日志布局类型#
log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH\:mm\:ss} %l %F %p %m%n
第四步:创建持久化类和映射文件
持久化类指其实例状态是需要被hibernate持久化到数据库中的类。持久化类设计为POJO类,必须要有一个public类型的无参构造方法。
持久化类在数据传输过程中,未了确保正确进行序列化和反序列化,通常持久化类需要实现java.io.Serializable接口。
创建持久化类Dept
package com.etc.entity; import java.io.Serializable; /** 部门持久化类 */
public class Dept implements Serializable { private static final long serialVersionUID = 1L; private Byte deptNo;// 部门编号(id属性。在hibernate中,id属性被称为对象标识符---Object Identifier,OID。OID用于唯一标识持久化类Dept的每个实例)
private String deptName;// 部门名称
private String location;// 部门所在地区 public Dept() {
} public Byte getDeptNo() {
return deptNo;
} public void setDeptNo(Byte deptNo) {
this.deptNo = deptNo;
} public String getDeptName() {
return deptName;
} public void setDeptName(String deptName) {
this.deptName = deptName;
} public String getLocation() {
return location;
} public void setLocation(String location) {
this.location = location;
} }
创建持久化类的映射文件Dept.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!-- `反单引号:避免表名或者字段名和数据库关键字冲突,以及解决名字之中存在空格等特殊字符 -->
<class name="com.etc.entity.Dept" table="`DEPT`">
<id name="deptNo" type="java.lang.Byte" column="`DEPTNO`">
<generator class="assigned" />
</id>
<property name="deptName" type="java.lang.String" column="`DNAME`" />
<property name="location" type="java.lang.String">
<column name="`LOC`"></column>
</property>
</class>
</hibernate-mapping>
映射文件元素
class:定义一个持久化类的映射信息。
- name表示持久化类的全限定名。
- talble表示持久化类对应的数据库表名。
id:表示持久化类的OID和数据表的主键的映射。
- name表示持久化类的属性的名称,和属性访问器相匹配(符合JavaBean规范的属性,通过访问器获取的属性名称)。
- type表示持久化类属性的类型。
- column表示持久化类属性对应的数据库数据表字段的名称。也可以在子元素column中指定。
generator:id元素的子元素,用于指定主键的生成策略。常用属性及子元素。
- class指定主键生成策略。
- param传递参数。
- 常用主键生成策略如下:
| 策略 | 说明 |
| assigned | 由程序负责指定。Hibernate不参与。没有指定<generator>元素时的默认生成策略。 |
| increment | 对类型为short、int、long类型的主键,hibernate按照主键增量1递增,自动生成主键。 |
| identity | 对SQLServer、DB2、MySQL等支持标识列的数据库。数据库相应字段需要设置为表示列。 |
| sequence |
对Oracle、DB2支持序列的数据库,可以使用序列生成主键自动增长策略。通过子元素param传入数据库序列名称。 例如: <generator class="sequence"> <param name="sequence">序列名</param </generator> |
| native | 有hibernate根据底层数据库自行判断采用哪一种主键生成策略。即由数据库生成主键的值。 |
property:定义持久化类中的属性和数据库表中的字段对应关系。
- name表示持久化类属性的名称,和属性访问器匹配。
- type表示持久化类属性的类型。
- column表示持久化类属性对应的数据库表中的字段的名称,也可以在子元素colmn中指定。
cloumn:用于指定其父元素代表的持久化类属性所对应的数据库表中的字段。
- name:字段名称。
- length:字段长度。
- not-null:设定是否非空。如果为true,则该字段不能为null值。
第五步:在hibernate.cfg.xml配置文件中声明映射文件
<!-- 配置映射文件 -->
<mapping resource="com/etc/entity/Dept.hbm.xml" />
使用Hibernate完成持久化操作
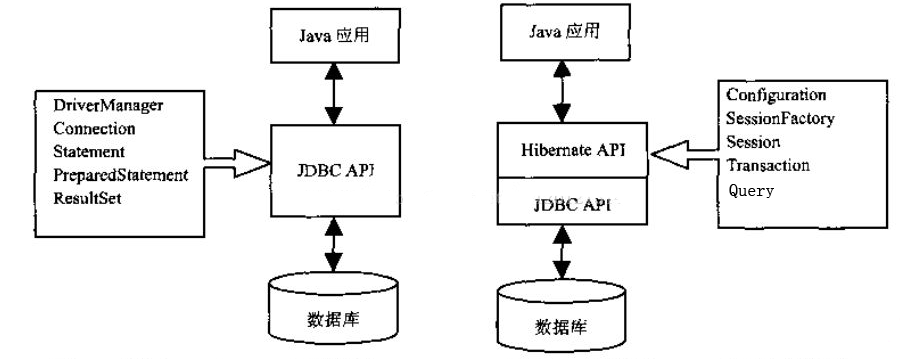
原理
Hiernate内部也是通过JDBC访问数据库。如下图所示
步骤
第一步:读取并解析配置文件和映射文件
Configuration configuratio=new Configuration().configure("hibernate.cfg.xml");
根据默认位置的Hibernate配置文件信息,构建负责管理配置信息的Configuration对象。
第二步:根据配置文件和映射文件信息,创建SessionFactory对象
SessionFactory sessionFactory=configuration.buildSessionFactory();
SessionFactory对象一旦构建完毕,配置信息的变化将不再影响已经创建的SessionFactory对象。
第三步:打开Session
Session session=sessionFactory.getCurrentSession()
或者:
Session session=sessionFactory.openSession();
session是Hibernate持久化操作的基础。提供了save()、delete()、update()、get()、load()等方法完成对象的CURD操作。
第四步:开始一个事务
Transaction tx = session().beginTransaction();
第五步:数据库操作
session.save(dept);//保持部门对象
第六步:结束事务
tx.commit();//提交事务
或者
tx.rollback();//回滚事务
第七步:如果是通过SessionFactory的openSession()方法获取Session对象,则需要关闭session。
session.close();//关闭session
如果在hibernate配置文件中的参数设置为:
<!-- 指定session范围和上下文 -->
<property name="current_session_context_class">thread</property>
并且采用getCurrentSession()方法获得session对象,则无需执行session.close()方法。session会在关联的事务结束时(提交或者回滚)自动关闭。
Hibernate API使用模板
根据Hibernate API使用的步骤,持久化操作模板如下代码所示:
Configuration conf = null;
SessionFactory sf = null;
Session session = null;
Transaction tx = null;
try {
conf = new Configuration().configure();
sf = conf.buildSessionFactory();
session = sf.getCurrentSession();
tx = session.beginTransaction();
Dept dept = new Dept();
……
session.save(dept);
tx.commit();
} catch (HibernateException e) {
e.printStackTrace();
tx.rollback();
}
Hibernate持久化工具类
根据Hibernate API持久化操作模板,并结合session线程安全考虑,定义工具类来管理SessionFactory和Session。
package com.etc.util; import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration; /** Hibernate工具类 */
public class HibernateUtil {
private static Configuration configuration;
private final static SessionFactory sessionFactory; /** 私有构造方法 */
private HibernateUtil() {
} // 初始化Configuration和SessionFactory
static {
try {
configuration = new Configuration().configure("hibernate.cfg.xml");
sessionFactory = configuration.buildSessionFactory();
} catch (HibernateException e) {
e.printStackTrace();
throw new ExceptionInInitializerError(e);
}
} /** 获取Session对象 */
public static Session currentSession() {
return sessionFactory.getCurrentSession();
}
}
该工具类结合Hibernate的配置<property name="current_session_context_class">thread</property>,可以在多线程环境中获得线程安全的session。线程初次获取session时,通过getCurrentSession()方法获得session,后期线程再次需要获取session,则只会返回和该线程绑定过的session对象,从而确保每个线程拥有独立的session对象。getCurrentSession()获得的session会在关联事务结束后自动关闭session对象。
查询操作
在进行修改或者删除操作时,应该先加载对象,然后再执行修改或者删除操作。
Hibernate提供了两种方法按照主键加载对象:
|
方 法 |
区别一 |
区别二 |
|
Object get( Class clazz, Serializable id ) |
若数据不存在,返回null |
返回实体数据。 |
|
Object load( Class clazz, Serializable id ) |
若数据不存在,使用时抛出ObjectNotFoundException |
如果类为延迟加载(默认),则返回实体数据的代理实例。否则,和get方法的用法一致。 |
示例:
1.定义BaseDao简化HibernateUtil工具类的使用
public class BaseDao {
public Session getSession(){
return HibernateUtil.currentSession();
}
}
2.数据访问层关键代码
/**get方法加载对象*/
public Dept getDept(Serializable id) throws Exception {
return (Dept) this.getSession().get(Dept.class, id);
} /**load方法加载对象*/
public Dept loadDept(Serializable id) throws Exception {
return (Dept) this.getSession().load(Dept.class, id);
}
3.业务逻辑层关键代码:
public Dept findDeptById(Byte id) {
Transaction tx = null;
Dept dept = null;
try {
tx = deptDao.getSession().beginTransaction();
// 使用get方法加载对象,如果找不到,get方法返回一个null,导致读取数据报NullPointerException
// dept = deptDao.getDept(id);
// 使用load方法加载对象,如果找不到,报ObjectNotFoundException
dept = deptDao.loadDept(id);
System.out.println(dept.getDeptName());
tx.commit();
} catch (Exception e) {
e.printStackTrace();
if (tx != null) {
tx.rollback();
}
}
return dept;
}
4.测试类代码
@Test
public void testGetAndLoad(){
new DeptBiz().findDeptById(Byte.valueOf("50"));
}
添加、删除、修改操作
添加操作
DAO层关键代码:
/**保存对象 */
public void save(Dept dept) throws Exception {
this.getSession().save(dept);
}
业务层关键代码:
public void addNewDept(Dept dept) {
Transaction tx = null;
try {
tx = deptDao.getSession().beginTransaction();
deptDao.save(dept);
System.out.println("添加部门信息成功");
tx.commit();
} catch (Exception e) {
e.printStackTrace();
if (tx != null) {
tx.rollback();
}
}
}
测试方法中关键代码:
public void testAdd(){
Dept dept=new Dept();
dept.setDeptNo(new Byte("70"));
dept.setDeptName("开发部");
dept.setLocation("米兰");
//保存部门信息
new DeptBiz().addNewDept(dept);
}
需改操作
DAO关键代码:
/**load方法加载对象*/
public Dept loadDept(Serializable id) throws Exception {
return (Dept) this.getSession().load(Dept.class, id);
}
业务层关键代码:
public void updateDept(Dept dept) {
Transaction tx = null;
try {
tx = deptDao.getSession().beginTransaction();
Dept deptToUpdate=deptDao.loadDept(dept.getDeptNo());
//更新部门数据
deptToUpdate.setDeptName(dept.getDeptName());
deptToUpdate.setLocation(dept.getLocation());
System.out.println("修改部门信息成功");
tx.commit();
} catch (Exception e) {
e.printStackTrace();
if (tx != null) {
tx.rollback();
}
}
}
测试方法关键代码:
//加载对象,提交事务即可完成信息的修改
public void testUpdate(){
Dept dept=new Dept();
dept.setDeptNo(new Byte("70"));
dept.setDeptName("开发部2");
dept.setLocation("北京");
//更新部门信息
new DeptBiz().updateDept(dept);
}
删除操作
DAO关键代码:
/**load方法加载对象*/
public Dept loadDept(Serializable id) throws Exception {
return (Dept) this.getSession().load(Dept.class, id);
} /**删除对象*/
public void delete(Dept dept) throws Exception {
this.getSession().delete(dept);
}
业务层关键代码:
public void deleteDept(Byte id) {
Transaction tx = null;
try {
tx = deptDao.getSession().beginTransaction();
Dept dept=deptDao.loadDept(id);
//删除部门信息
deptDao.delete(dept);
System.out.println("删除部门信息成功");
tx.commit();
} catch (Exception e) {
e.printStackTrace();
if (tx != null) {
tx.rollback();
}
}
}
测试方法关键代码:
public void testDelete(){
//删除部门信息
new DeptBiz().deleteDept(new Byte("50"));
}
Hibernate中Java对象的三种状态
Hibernate通过session来管理Java对象的状态,在对象的持久化生命周期中,存在三种状态。
三种状态
瞬时状态(Transient)
- 又称为临时状态,Java对象和数据库中的数据没有任何关联,并且session对象无法管理和感知该Java对象。
- 当瞬时状态的对象如果没有被引用,则被垃圾回收机制处理。
持久状态(Persistent)
- 对象和session关联,被session管理,此时的对象就处于持久状态。持久状态的对象具有数据库标识(实体数据的主键,OID)。
- 对象和session关联的时机:1、通过get和load方法从数据库加载数据到session缓存;2、对瞬时状态对象进行save()、saveOrUpdate()等方法调用,在保存数据的同时,Java对象也和session发生了关联。
- 对于处在持久状态的对象,session会持续跟踪和管理他们,如果对象的内部状态发生了变化,Hibernate会在合适的时机(提交事务、刷新缓存)将变更同步到数据库。
游离状态(Detached)
- 又称为脱管状态。处在持久状态的对象,脱离了和它关联的Session的管理后,对象就处于游离状态。
- 处于游离态的对象,Hibernate无法确保该对象所包含的数据和数据库中的记录一致。
- session提供的update()、saveOrUpdate()等方法,可以将游离状态的对象的数据以更新的方式同步到数据库中,并将该对象和session关联,这是对象从游离态变更为持久状态。
三种状态间的转换
Hibernate对象状态机图如下图所示:
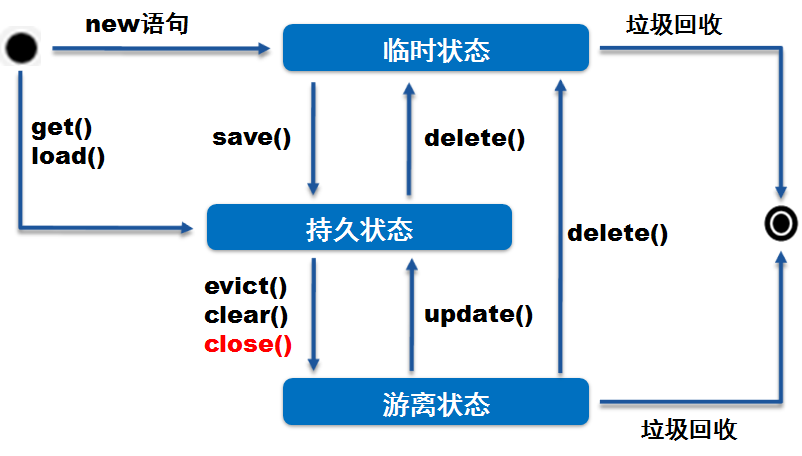
备注:
- session.evict(object) :把缓存中指定对象清除。
- session.clear() :清除缓冲区内的全部对象,但不包括Hibernate操作中的对象。
- 处于瞬时状态或者游离状态的对象,如果没有被其他对象引用,则会被Java垃圾回收机制处理。
脏检查和刷新缓存机制
Session是Hibernate用来持久化数据的主要接口,它提供了CRUD和加载对象的基本方法。Session对象具有一个缓存,可以用来管理和跟踪所有持久化对象。在特定的时间点,Session会根据缓存中对象的变化来执行相关SQL语句,将对象发生的变化同步到数据库中。也就是将数据库同步为与session缓存一致,这一过程称为刷新缓存。
脏检查
在hibernate中,数据前后发生变化的对象,称为脏对象。例如代码:
tx = deptDao.getSession().beginTransaction();
//获取部门对象,dept为持久状态
Dept dept=deptDao.loadDept(dept.getDeptNo());
//更新部门数据,此时dept为脏对象
dept.setDeptName("质管部");
tx.commit();
当上述代码的dept对象被加入session缓存时,session会为dept对象值类型的属性复制一份快照。操作中,deptName属性发生改变,dept对象即成为脏对象。如下图所示:
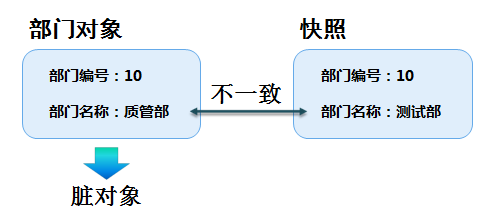
注意:
- Hibernate不会在对象属性发生变化时立即执行SQL语句。
- 当刷新缓存(调用Session的flush()方法)时,Hiberante会对Session中持久状态的对象进行检测,判断对象的数据是否发生了改变。
- commit()方法会首先刷新缓存。
刷新缓存
当Session缓存中对象的属性发生变化时,Session并不会立即执行脏检查和执行相关的SQL语句,而是在特定的时间点,即刷新缓存时オ执行。这样做的好处在于,使得Session能够把多次变化并为一条或者一批SQL语句,减少了访问数据库的次数,从而提高应用程序的数据访问性能。
Session会在以下时间点刷新缓存:
1.调用Session的flush()方法。
Session的flush()方法进行刷新缓存的操作,会触发脏检查,视情况执行相关的SQL语句。
2.调用Transaction的commit()方法。
commit()方法会先调用session的刷新缓存方法flush(),然后向数据库提交事务。在提交事务时执行刷新缓存的动作,可以减少访问数据库的频率,尽可能缩短当前事务对数据库中相关资源的锁定时间。
更新数据方法
Hibernate中的Session提供了多种更新数据的方法,如update()、saveOrUpdate()、merge()方法。
- update()方法,用于将游离状态的对象恢复为持久状态,同时进行数据库更新操作。当参数对象的OID为NULL时会报异常。
- saveOrUpdate()方法, 同时包含了save()与update()方法的功能。如果入参是瞬时状态的对象,就调用save()方法。如果入参是游离状态的对象,则调用update()方法。
- merge()方法能够把作为参数传入的游离状态对象的属性复制到一个拥有相同OID的持久状态对象中,通过对持久状态对象的脏检查实现更新操作,并返回该持久状态对象。如果无法从Session缓存或数据库中加载到相应的持久状态对象,即传入的是瞬时对象,则创建其副本执行插入操作,并返回这一新的持久状态对象。所以无论何种情况,传入的对象状态都不受影响。
例如,修改60号部门的信息:
DEPT数据表中60号部门的信息为
| deptNo:60 | deptName:研发部 | deptLoc:厦门 |
将该部门的信息修改为
| deptNo:60 | deptName:开发部 | deptLoc:厦门 |
使用merge()方法实现,实现步骤如下:
1.修改持久化类Dept属性deptNo为Short类型,主键生成策略修改为increment。
private Short deptNo;
2.修改映射文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!-- dynamic-update的作用:只修改发生变化的属性 -->
<class name="com.etc.entity.Dept" table="`DEPT`" schema="scott"
dynamic-update="true">
<id name="deptNo" type="java.lang.Short" column="`DEPTNO`">
<!-- 主键生成器替换为increment,hibernate负责增长主键 -->
<!-- <generator class="assigned" /> -->
<generator class="increment"></generator>
</id>
<property name="deptName" type="java.lang.String" column="`DNAME`" />
<property name="location" type="java.lang.String">
<column name="`LOC`"></column>
</property>
</class>
</hibernate-mapping>
3.DAO关键代码
public Dept merge(Dept dept) throws Exception {
return (Dept) this.getSession().merge(dept);
}
4.业务逻辑层关键代码
ublic Dept mergeDept(Dept dept) {
Transaction tx = null;
Dept deptPersistent = null;
try {
tx = deptDao.getSession().beginTransaction();
// 合并dept数据(或者称为保持dept副本),返回持久态对象deptPersistent
deptPersistent = deptDao.merge(dept);
System.out.println("merge保存部门信息成功");
tx.commit();
} catch (Exception e) {
e.printStackTrace();
if (tx != null) {
tx.rollback();
}
}
return deptPersistent;
}
5.测试方法关键代码
/** merge方法测试 */
@Test
public void testMerge() {
Dept dept = new Dept();
//dept.setDeptNo(new Short("60"));// dept游离状态;去掉本行,dept为瞬时状态
dept.setDeptName("开发部");
Dept dept2 = new DeptBiz().mergeDept(dept);
//new DeptBiz().updateDept(dept);
System.out.println("新增部门编号:" + dept2.getDeptNo()); }
在该例子中,如果为瞬时状态的dept对象(session缓存和数据库中没有该对象OID,或者OID为null),Hibernate则通过merge()执行添加数据操作,主键由hibernate生成。
如果dept对象为游离态(OID有对应数据表主键),则hibernate会先从数据库加载持久态dept对象,对该对象执行持久化操作。
因此,如果当前Session缓存中没有包含具有相同OID的持久化对象(如打开Session后的首次操作),可以使用update()或saveOrUpdate()方法;如果想随时合并对象的修改而不考虑Session缓存中对象的状态,可以使用merge()方法。
对merge()方法的理解:
- 在一个session中存在两个不同的实体却有着相同的OID是会报错的,想要避免这种错误可以使用Hibernate中的merge方法。
- new一个对象并设置ID时,这个对象会被当作游离态处理,在使用merge时,如果在数据库中不能能找到这条记录,则使用insert将数据插入;如果在数据库中找到这条记录,则使用update将数据更新。
- new一个对象没有设置ID时,这个对象会被当作瞬态处理,在使用merge时会根据实体类的主键生成策略保存这条数据。
- 使用merge存储到数据库的对象,其本身不会转变为持久态对象。
Hibernate-01 入门的更多相关文章
- Python学习--01入门
Python学习--01入门 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.和PHP一样,它是后端开发语言. 如果有C语言.PHP语言.JAVA语言等其中一种语言的基础,学习Py ...
- Hibernate从入门到精通(十一)多对多双向关联映射
上次我们在中Hibernate从入门到精通(十)多对多单向关联映射讲解了一下多对多单向关联映射,这次我们讲解一下七种映射中的最后一种多对多双向关联映射. 多对多双向关联映射 按照我们之前的惯例,先看一 ...
- Hibernate从入门到精通(十)多对多单向关联映射
上一篇文章Hibernate从入门到精通(九)一对多双向关联映射中我们讲解了一下关于一对多关联映射的相关内容,这次我们继续多对多单向关联映射. 多对多单向关联映射 在讲解多对多单向关联映射之前,首先看 ...
- Hibernate从入门到精通(九)一对多双向关联映射
上次的博文Hibernate从入门到精通(八)一对多单向关联映射中,我们讲解了一下一对多单向映射的相关内容,这次我们讲解一下一对多双向映射的相关内容. 一对多双向关联映射 一对多双向关联映射,即在一的 ...
- Hibernate从入门到精通(八)一对多单向关联映射
上次的博文Hibernate从入门到精通(七)多对一单向关联映射我们主要讲解了一下多对一单向关联映射,这次我们继续讲解一下一对多单向映射. 一对多单向关联映射 在讲解一对多单向关联之前,按照我们的惯例 ...
- Hibernate从入门到精通(七)多对一单向关联映射
上次的博文Hibernate从入门到精通(六)一对一双向关联映射中我们介绍了一下一对一双向关联映射,本次博文我们讲解一下多对一关联映射 多对一单向关联映射 多对一关联映射与一对一关联映射类似,只是在多 ...
- Hibernate从入门到精通(六)一对一双向关联映射
在上次的博文Hibernate从入门到精通(五)一对一单向关联映射中我们讲解了一下一对一单向关联映射,这次我们继续讲解一下与之对应的一对一双向关联映射. 一对一双向关联 与一对一单向关联映射所不同的的 ...
- Hibernate从入门到精通(五)一对一单向关联映射
上次的博文中Hibernate从入门到精通(四)基本映射我们已经讲解了一下基本映射和相关概念,接下来我们会讲稍微复杂点的映射——关系映射. 关系映射分类 关系映射即在基本映射的基础上处理多个相关对象和 ...
- Hibernate从入门到精通(四)基本映射
映射的概念 在上次的博文Hibernate从入门到精通(三)Hibernate配置文件我们已经讲解了一下Hibernate中的两种配置文件,其中提到了两种配置文件的主要区别就是XML可以配置映射.这里 ...
- Hibernate从入门到精通(三)Hibernate配置文件
在上次的博文Hibernate从入门到精通(二)Hibernate实例演示我们已经通过一个实例的演示对Hibernate的基本使用有了一个简单的认识,这里我们在此简单回顾一下Hibernate框架的使 ...
随机推荐
- (转)ORA-01245错误 (2013-04-13 18:37:01)
转自:http://blog.sina.com.cn/s/blog_56359cc90101crx2.html 数据库rman restore database 之后,执行recover databa ...
- NYOJ3——多边形重心问题
多边形重心问题 时间限制:3000 ms | 内存限制:65535 KB 难度:5 描述:在某个多边形上,取n个点,这n个点顺序给出,按照给出顺序将相邻的点用直线连接, (第一个和最后一个连接) ...
- c# dynamic 无法创建 泛型变量的问题
IMyClass<T> FunctionA<T>( object arg_obj) { dynamic dyObj = arg_obj; return new MyClass& ...
- python中用代码实现99乘法表
第一种:使用for遍历循环嵌套 ,): ,x+): print("%s*%s=%s" % (y,x,x*y),end=" ") print("&quo ...
- 进程与线程(3)- python实现多线程
参考链接: https://www.jianshu.com/p/415976668b97?utm_campaign=maleskine&utm_content=note&utm_med ...
- port 22: Connection refused
issue: os>ssh 196.168.27.90ssh: connect to host 196.168.27.90 port 22: Connection refused solutio ...
- Mysql读写分离操作之mysql-proxy
常见的读写方式 基于程序代码内部实现 在代码中根据select.insert进行选择分类:这类方法也是生产常用的,效率最高,但是对开发人员比较麻烦.架构不能灵活调整 基于中间件的读写分离: mysql ...
- 【前端】html5获取经纬度,百度api获取街区名,并使用JS保存进cookie
引用js<script type="text/javascript" src="http://api.map.baidu.com/api?v=2.0&ak= ...
- 拦截@RequestBody的请求数据
要拦截首先想到的是拦截器,@RequestBody只能以流的方式读取,流被读过一次后,就不在存在了,会导致会续无法处理,因此不能直接读流 为了解决这个问题,思路如下: 1.读取流前先把流保存一下 2. ...
- 启动hadoop时报root@localhost's password: localhost: Permission denied, please try again.错误。
背景:在装完hadoop及jdk之后,在执行start-all.sh的时候出现root@localhost's password:localhost:permission denied,please ...