漫谈Word2vec之skip-gram模型
https://zhuanlan.zhihu.com/p/30302498

【作者】 刘书龙,现任达观数据技术部工程师,兴趣方向主要为自然语言处理和数据挖掘。
word2vec是Google研究团队的成果之一,它作为一种主流的获取分布式词向量的工具,在自然语言处理、数据挖掘等领域有着广泛的应用。达观数据的文本挖掘业务有些地方就使用了该项技术。本文从以下几个方面简要介绍Word2vec的skip-gram模型:
第一部分对比word2vec词向量和one-hot词向量,引出word2vec词向量的优势所在;第二部分给出skip-gram模型的相关内容;第三部分简单介绍模型求解时优化方面的内容;第四部分通过例子简单给出词向量模型的效果;第五部分作出总结。
1. 优势
word2vec词向量与传统的one-hot词向量相比,主要有以下两个优势。
(1)低维稠密
一般来说分布式词向量的维度设置成100-500就足够使用,而one-hot类型的词向量维度与词表的大小成正比,是一种高维稀疏的表示方法,这种表示方法导致其在计算上具有比较低效率。
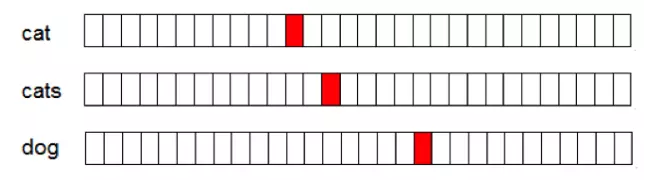 Fig.1. one-hot词向量
Fig.1. one-hot词向量
(2) 蕴含语义信息
one-hot这种表示方式使得每一个词映射到高维空间中都是互相正交的,也就是说one-hot向量空间中词与词之间没有任何关联关系,这显然与实际情况不符合,因为实际中词与词之间有近义、反义等多种关系。Word2vec虽然学习不到反义这种高层次语义信息,但它巧妙的运用了一种思想:“具有相同上下文的词语包含相似的语义”,使得语义相近的词在映射到欧式空间后中具有较高的余弦相似度。
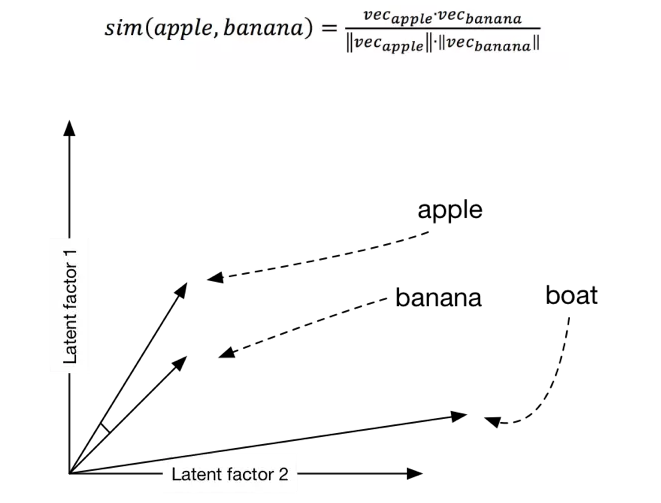 Fig.2. word2vec词向量
Fig.2. word2vec词向量
2. skip-gram模型
(1) 训练样本
怎么把“具有相同上下文的词语包含相似的语义”这种思想融入模型是很关键的一步,在模型中,两个词是否出现在一起是通过判断这两个词在上下文中是否出现在一个窗口内。例如,原始样本“达观数据是一家做人工智能的公司”在送入模型前会经过图3所示处理(这里为了绘图简单假设窗口为2,一般窗口是设置成5)。
如图3所示,skip-gram模型的输入是当前词,输出是当前词的上下文,虽然我们训练模型的时候喂的是一个个分词好的句子,但内部其实是使用一个个word pair来训练。同样是之前的case“达观数据是一家做人工智能的公司”,假如窗口改为5,则(达观数据,人工智能)这个word pair会成为一个训练样本。
假如再过来一个case“Google是一家人工智能公司”,则(Google,人工智能)也会成为一个训练样本。如果用来训练的语料库中会产生多个(达观数据,人工智能)、(Google,人工智能)这种的训练样本,则可以推测“达观数据”和“Google”会有较高的相似度,因为在训练样本中这两个词具有相同的输出,推而广之,也就是说这两个词具有相同的上下文。一言以蔽之“假如两个词具有相同的输出,则可反推出作为输入的两个词之间具有较高相似性”,接下来就是如何使用模型来实现上述目标。
 Fig.3. 训练样本
Fig.3. 训练样本
(2)skip-gram模型
skip-gram模型与自编码器(Autoencoder)类似,唯一的区别在于自编码器的输出等于输入,而skip-gram模型的输出是输入的上下文。那么,作为训练样本的word pair应该以什么样的方式输入给模型? 答案是one-hot向量,为了得到one-hot向量,必须首先知道训练语料中包含了多少词。因此,在训练之前会首先对语料进行统计,得到词表。假设词表长度为10000,词向量为300维,则skip-gram模型可表示为图4。
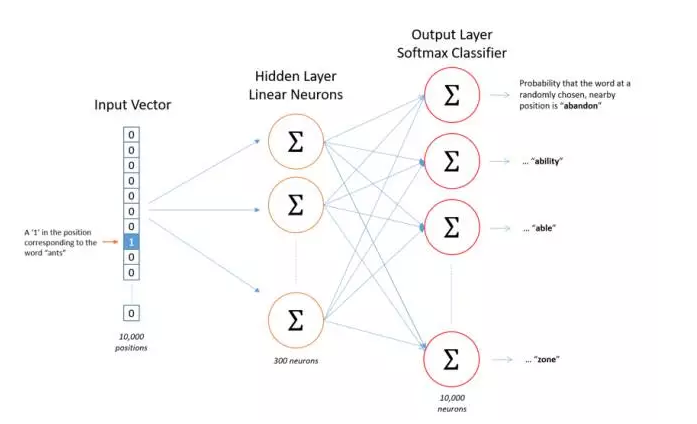 Fig.4. skip-gram 模型
Fig.4. skip-gram 模型
如图4所示,假设输入的word pair为(ants, able),则模型拟合的目标是 ,同时也需要满足
,这里利用的是对数似然函数作为目标函数。上述表述中
可表示为:
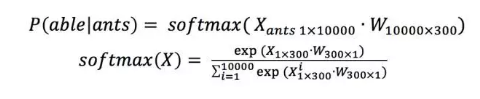
根据 和
,可构建似然函数:
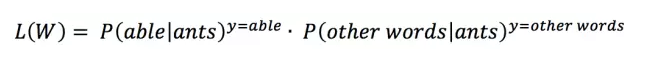
则:

将 代入有:
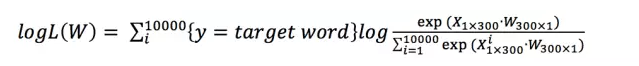
式中{*}表示如果表达式*为true,则{*}=1,否则{*}=0。接下来要做的是最大化似然函数,也即:
要实现上述目标,可利用梯度上升法,首先对参数求偏导:
接下来根据学习率对进行更新:
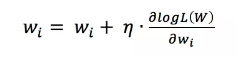
现在问题来了,模型训练完成后词向量在哪呢?隐藏层的参数矩阵 就包含了所有词的词向量,该矩阵的行为词表长度,列为词向量维度,矩阵中的每一行表示一个词的词向量。由于输入层
是one-hot向量,与隐藏层
点乘后其实是选中了该矩阵中的一行,如图5所示,这一行表示的是ants的词向量,而输出层其实是以ants的词向量为特征,以ants的上下文词作为类别来训练softmax分类器。
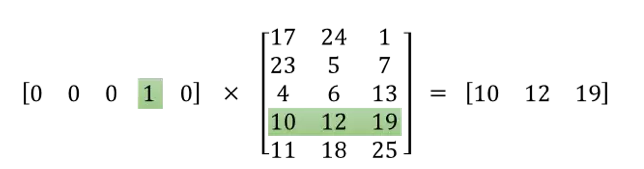 Fig.5.词的one-hot向量点乘隐藏层权值矩阵得到该词的词向量
Fig.5.词的one-hot向量点乘隐藏层权值矩阵得到该词的词向量
回到上文,为什么说(达观数据,人工智能)、(Google,人工智能)这种样本多了之后会得出达观数据和Google的相似度会比较高?当时解释的是因为这两个词有相同的输出,更深一步讲是因为输出层参数矩阵 是所有词向量共享的。具体来说,模型训练完成后会达到类似下面的效果:
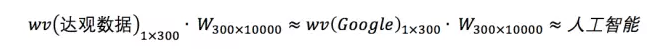
由上面可直接看出来 ,其中
表示*的词向量,约等于是指两个向量所指的方向在空间中比较接近。
3. 模型优化
(1)欠采样 subsample
图3中的例子中“是”、“的”这种词在任何场景中都可能出现,它们并不包含多少语义,而且出现的频率特别高,如果不加处理会影响词向量的效果。欠采样就是为了应对这种现象,它的主要思想是对每个词都计算一个采样概率,根据概率值来判断一个词是否应该保留。概率计算方法为:
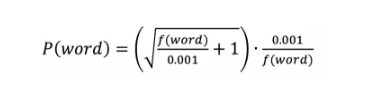
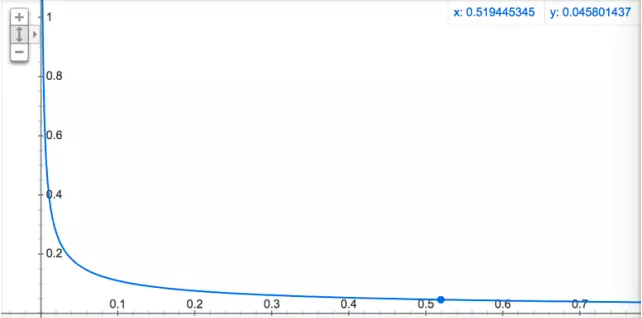
其中f(*)表示*出现的概率,0.001为默认值,具体函数走势如图6所示,可以看出,词语出现的概率越高,其被采样到的概率就越低。这里有一点IDF的味道,不同的是IDF是为了降低词的特征权重,欠采样是为了降低词的采样概率。
(2) 负采样 negative sample
以图4所示的模型为例,对每一个训练样本需要更新的参数个数有三百万(准确的说是三百万零三百,由于输入是one-hot,隐藏层每次只需要更新输入词语的词向量),这还是假设词表只有一万的情况下,实际情况会有五十万甚至更多,这时候参数就达到了亿级。训练过程中要对每个参数计算偏导,然后进行更新,这需要很大的计算资源。
负采样是加快训练速度的一种方法,这里的负可以理解为负样本。针对训练样本(ants, able),able这个词是正样本,词表中除able外的所有词都是负样本。负采样是对负样本进行采样,不进行负采样时,对每一个训练样本模型需要拟合一个正样本和九千九百九十九个负样本。加入负采样后,只需要从这九千九百九十九个负样本中挑出来几个进行拟合,大大节省了计算资源。那么应该挑几个负样本,根据什么进行挑呢?Google给出的建议是挑5-20个,怎么挑是根据词在语料中出现的概率,概率越大越有可能被选中,具体计算公式为:
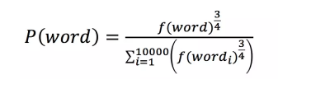
其中f(*)表示*出现的概率。
(3)层次softmax
层次softmax的目的和负采样一样,也是为了加快训练速度,但它相对复杂,没有负采样这种来的简单粗暴。具体来说,使用层次softmax时图4中的模型输出层不再是使用one-hot加softmax回归,而是使用Huffman树加softmax回归。在模型训练的时候首先统计语料中词语的词频,然后根据词频来构建Huffman树,如图7所示,树的根节点可理解为输入词的词向量,叶子节点表示词表中的词,其它节点没有什么实际含义,仅起到辅助作用。
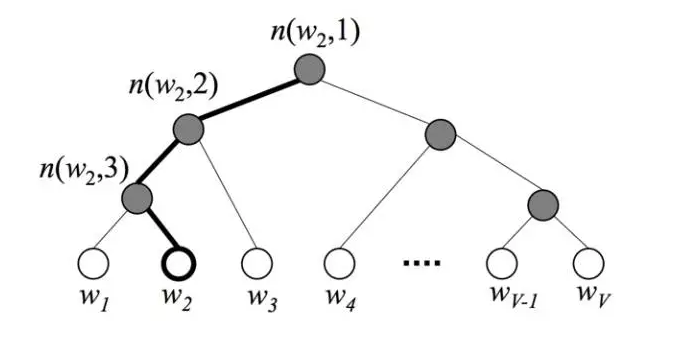 Fig.7.Huffman树
Fig.7.Huffman树
为什么使用Huffman树可以加快训练速度?答案是输出层不使用one-hot来表示,softmax回归就不需要对那么多0(也即负样本)进行拟合,仅仅只需要拟合输出值在Huffman树中的一条路径。假设词表大小为N,一条路径上节点的个数可以用来估计,就是说只需要拟合次,这给计算量带来了指数级的减少。此外,由于Huffman编码是不等长编码,频率越高的词越接近根节点,这也使计算量有所降低。
怎么对树中的节点进行拟合呢?如图7所示,假设训练样本的输出词是 ,则从根节点走到
经过了
这两个节点。由于Huffman树是二叉树,这意味着只需要判断向左还是向右就可以从根节点走到
,判断向左还是向右其实就是进行二分类。图7中的例子,“root(input)->left->left->right()”这条路径的概率可表示为:
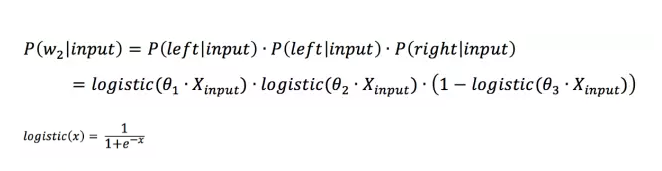
其中 表示路径中第i个节点的权值向量。注意一点,softmax regression 做二分类的时候就退化为了logistic regression,因此虽然叫层次softmax但公式中其实用的是logistic function。根据上述公式就可构建根据Huffman树来进行softmax回归的cost function,进而根据梯度下降对模型进行训练求解。
4. word2vec应用
Google开源了word2vec源码,可以很方便的训练词向量,这里不再赘述。简单看个例子:

可以看出,当输入北京这个词时,与之相似的词语有“上海、广州、杭州、深圳…”,模型几乎学习到了一线城市的概念,效果还是可以的。
达观应用案例
特征降维:特征维度过高的时候,很容易出现特征之间具有较高的相关性。这种情况下可以利用词向量工具对特征进行聚类,将相关的特征归到一个维度里面。
特征扩展:针对短文本处理时,一个case往往提不出很多表意较强的特征,导致类别间区分度不强。这种情况下可以利用词向量工具对主要特征进行扩展,在不损失精度的前提下提高召回。
5. 总结
本文从例子出发,简单介绍了Word2vec的skip-gram模型,只作抛砖引玉。文中若有不当之处,欢迎指正。
漫谈Word2vec之skip-gram模型的更多相关文章
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- RNN、LSTM、Seq2Seq、Attention、Teacher forcing、Skip thought模型总结
RNN RNN的发源: 单层的神经网络(只有一个细胞,f(wx+b),只有输入,没有输出和hidden state) 多个神经细胞(增加细胞个数和hidden state,hidden是f(wx+b) ...
- 计算机网络漫谈:OSI七层模型与TCP/IP四层(参考)模型
提纲.png 一.七层?四层? OSI模型(Open System Interconnection Reference Model,缩写为OSI),全名“开放式系统互联通信参考模型”,是一个试图使各种 ...
- word2vec:CBOW和skip-gram模型
1.CBOW模型 之前已经解释过,无论是CBOW模型还是skip-gram模型,都是以Huffman树作为基础的.值得注意的是,Huffman树中非叶节点存储的中间向量的初始化值是零向量,而叶节点对应 ...
- Tensorflow 的Word2vec demo解析
简单demo的代码路径在tensorflow\tensorflow\g3doc\tutorials\word2vec\word2vec_basic.py Sikp gram方式的model思路 htt ...
- word2vec的Java源码【转】
一.核心代码 word2vec.java package com.ansj.vec; import java.io.*; import java.lang.reflect.Array; import ...
- 利用 TensorFlow 入门 Word2Vec
利用 TensorFlow 入门 Word2Vec 原创 2017-10-14 chen_h coderpai 博客地址:http://www.jianshu.com/p/4e16ae0aad25 或 ...
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树
Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 目录 Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 0x00 摘要 0x01 背景概念 1.1 词向量基础 ...
随机推荐
- C#文件读写参考
string s = ""; string[] files = Directory.GetFiles(@"E:\u3d_warcraft\logic\logic\Batt ...
- SCUT - 249 - A piece of Cake - 组合数学
https://scut.online/contest/25/I 由结论:d维物体切n刀分成的部分=sum(C(n,0)~C(n,d)),直接算就行了.
- POJ2488【DFS】
阿西吧,搞清楚谁是行,谁是列啊!!! #include <stdio.h> #include <string.h> #include <math.h> #inclu ...
- ErrorObject OpenAsync(Action<ErrorObject>arg_fnRet)
ErrorObject OpenAsync(Action<ErrorObject>arg_fnRet) public static ErrorObject Open(this ReadWr ...
- 关于国债的一些计算: 理论TF价格2(缴款日前有付息)
计算 ExpectedTFPrice 是一个比较复杂的计算,我们这里讨论复杂的一种情况. 给定一只可交割国债bond(一般为CTD),一个国债期货tf, 在t日(表示tf的一个交易日期,我们通过bon ...
- EasyUI设置Layout自适应浏览器宽度和高度
//设置自适应浏览器宽度和高度 function setLayoutHeight() { var height = $(window).height() - 20; $("#main_lay ...
- Luogu P1552 [APIO2012]派遣【左偏树】By cellur925
题目传送门 $Chat$ 哈哈哈我xj用dfs序乱搞竟然炸出了66分....(其实还是数据水,逃) $Sol$ 首先我们应该知道,一个人他自己的满意度与他子树所有节点的领导力是无关的,一个人的满意度受 ...
- nginx缓存过期
1 原理 在默认下,请求过的内容会接受304,而从本地缓存调用.这是通过client向server发送请求,给出ETag,server确认ETag未变,则不返回内容,client调用本地缓存. 而ex ...
- hbuilder 中文乱码
这是因为HBuilder默认文件编码是UTF-8,你可以在工具-选项-常规-工作空间选项中设置默认字符编码
- EJB Timer Service is not available. Timers for application with id 95795415990861824 will not be deleted
delete follows:glassfish\domains\domain1\applications\ejb-timer-service-appglassfish\domains\domain1 ...