FTRL (Follow-the-regularized-Leader)算法
Online gradient descent(OGD) produces excellent prediction accuracy with a minimum of computing resources.However, in practice another key consideration is the size of the final model;Since models can be stored sparsely, the number of non-zero coefficients in W is the determining factor of memory usage.
Without regularization , FTRL-Proximal is identical to standard online gradient descent, but because it uses an alternative lazy representation of the model coefficients w, L1 regularization can be implemented much more effectively.
Given a sequence of gradients $g_t$, OGD performs the update $W_{t+1} = W_t - \eta_tg_t$ , where $\eta_t$ is a non-increasing learning-rate schedule,e.g.$\eta_t = 1 / \sqrt{t}$.
The FTRL-Proximal algorithm uses the update $W_{t+1} = arg_wmin(g_{1:t}.w + 1/2 \sum_{s=1}^t\sigma_s ||w - w_s||_2^2 + \lambda_1||w||_1)$, $\sigma_{1:t} = 1 / \eta_t$
when we take $\lambda_1 = 0$, they produce an identical sequence of coefficient vectors. However, the FTRL-Proximal update with $\lambda_1 > 0$ does an excellent job of inducing sparsity.

其中,

式中第一项是对损失函数的贡献的一个估计,第二项是控制w(也就是model)在每次迭代中变化不要太大,第三项代表L1正则(获得稀疏解),
学习速率可以通过超参数自适应学习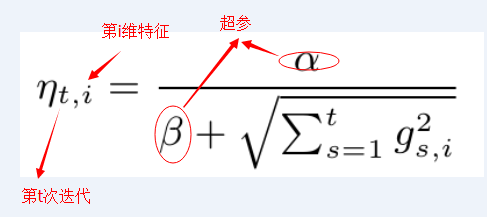
we can re-write the update as the argmin over w of
$(g_{1:t} - \sum_{s=1}^t\sigma_sw_s) . w + (1 / \eta_t) ||w||^2_2 + \lambda_1||w||_1 + const$ (左式第二项少了个1/2)
Let $z_{t-1} = g_{1:t-1} - \sum_{s=1}^{t-1}\sigma_sw_s$, so $z_t = z_{t-1} + g_t - (1/\eta_t - 1/ (\eta_{t-1}))W_t$ and solve for $W_{t+1}$ in closed form on a percoordinate bases by

Note that when $\eta_t$ is a constant value $\eta$ and $\lambda_1 = 0$, it is easy to see the equivalence to online gradient descent, since we have $W_{t+1} = -\etaZ_t =-\eta \sum^t_{s=1}g_s$

FTRL综合考虑了FOBOS和RDA对于正则项和W限制的区别,其特征权重的更新公式为:
公式(3)
注意,公式(3)中出现了L2正则项,在论文[2]的公式中并没有这一项,但是在其2013年发表的FTRL工程化实现的论文[3]却使用到了L2正则项。事实上该项的引入并不影响FRTL的稀疏性,后面的推导过程会显示这一点。L2正则项的引入仅仅相当于对最优化过程多了一个约束,使得结果求解结果更加“平滑”。
公式(3)看上去很复杂,更新特征权重貌似非常困难的样子。不妨将其进行改写,将最后一项展开,等价于求下面这样一个最优化问题:
上式中最后一项相对于来说是一个常数项,并且令
,上式等价于:
针对特征权重的各个维度将其拆解成N个独立的标量最小化问题:
到这里,我们遇到了与上一篇RDA中类似的优化问题,用相同的分析方法可以得到:
公式(4)
从公式(4)可以看出,引入L2正则化并没有对FTRL结果的稀疏性产生任何影响。公式4可以用软阈值分析求解,但是怎么和$sgn(z_i^{(t)})$联系起来?
前面介绍了FTRL的基本推导,但是这里还有一个问题是一直没有被讨论到的:关于学习率的选择和计算。事实上在FTRL中,每个维度上的学习率都是单独考虑的(Per-Coordinate Learning Rates)。
在一个标准的OGD里面使用的是一个全局的学习率策略,这个策略保证了学习率是一个正的非增长序列,对于每一个特征维度都是一样的。
考虑特征维度的变化率:如果特征1比特征2的变化更快,那么在维度1上的学习率应该下降得更快。我们很容易就可以想到可以用某个维度上梯度分量来反映这种变化率。在FTRL中,维度i上的学习率是这样计算的:
公式(5)
由于,所以公式(4)中有
,这里的
和
是需要输入的参数,公式(4)中学习率写成累加的形式,是为了方便理解后面FTRL的迭代计算逻辑。
参考:
http://blog.csdn.net/wenzishou/article/details/73558017
RDA优化: http://www.cnblogs.com/luctw/p/4757943.html
http://blog.csdn.net/a819825294/article/details/51227265
FTRL (Follow-the-regularized-Leader)算法的更多相关文章
- FTRL(Follow The Regularized Leader)学习总结
摘要: 1.算法概述 2.算法要点与推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 FTRL是一种适用于处理超大规模数据的,含大量稀疏特征的在线学习的 ...
- Alink漫谈(十二) :在线学习算法FTRL 之 整体设计
Alink漫谈(十二) :在线学习算法FTRL 之 整体设计 目录 Alink漫谈(十二) :在线学习算法FTRL 之 整体设计 0x00 摘要 0x01概念 1.1 逻辑回归 1.1.1 推导过程 ...
- Alink漫谈(十三) :在线学习算法FTRL 之 具体实现
Alink漫谈(十三) :在线学习算法FTRL 之 具体实现 目录 Alink漫谈(十三) :在线学习算法FTRL 之 具体实现 0x00 摘要 0x01 回顾 0x02 在线训练 2.1 预置模型 ...
- 在线最优化求解(Online Optimization)之一:预备篇
在线最优化求解(Online Optimization)之一:预备篇 动机与目的 在实际工作中,无论是工程师.项目经理.产品同学都会经常讨论一类话题:“从线上对比的效果来看,某某特征或因素对xx产品的 ...
- 在线机器学习FTRL(Follow-the-regularized-Leader)算法介绍
看到好文章,坚决转载!哈哈,学术目的~~ 最近几个同事在做推荐平台的项目,都问到怎么实现FTRL算法,要求协助帮忙实现FTRL的算法模块.今天也是有空,赶紧来做个整理.明天还要去上海参加天善智能组织的 ...
- 在线优化算法 FTRL 的原理与实现
在线学习想要解决的问题 在线学习 ( \(\it{Online \;Learning}\) ) 代表了一系列机器学习算法,特点是每来一个样本就能训练,能够根据线上反馈数据,实时快速地进行模型调整,使得 ...
- 在线最优化求解(Online Optimization)之五:FTRL
在线最优化求解(Online Optimization)之五:FTRL 在上一篇博文中中我们从原理上定性比较了L1-FOBOS和L1-RDA在稀疏性上的表现.有实验证明,L1-FOBOS这一类基于梯度 ...
- Learning to rank基本算法
搜索排序相关的方法,包括 Learning to rank 基本方法 Learning to rank 指标介绍 LambdaMART 模型原理 FTRL 模型原理 Learning to rank ...
- 在线学习--online learning
在线学习 online learning Online learning并不是一种模型,而是模型的训练方法.能够根据线上反馈数据,实时快速的进行模型调优,使得模型能够及时反映线上的变化,提高线上预测的 ...
- Raft协议实战之Redis Sentinel的选举Leader源码解析
这可能是我看过的写的最详细的关于redis 选举的文章了, 原文链接 Raft协议是用来解决分布式系统一致性问题的协议,在很长一段时间,Paxos被认为是解决分布式系统一致性的代名词.但是Paxos难 ...
随机推荐
- emacs - GNU Emacs
总览 (SYNOPSIS) emacs [ command-line switches ] [ files ... ] 描述 (DESCRIPTION) GNU Emacs 是 Emacs 的 一个 ...
- 1-1 编程基础 GCC程序编译
GCC简介 Linux系统下的gcc是GNU推出的强大.性能优越的多平台编译器,是GNU的代表作之一.gcc可以在多种硬体平台上编译出可执行程序,其执行效率与一般的编译器相比平局效率要高20 ...
- 油猴 tamperMonkey 在百度首页 添加自己的自定义链接
发现 GM_addStyle 函数不能用了,从写加载css函数. 剩下找个定位 添加内容 就很简单了. // ==UserScript== // @name helloWorld // @namesp ...
- clone对象或数组
function clone(obj) { var o; if (typeof obj == "object") { if (obj === null) { o = null; } ...
- vue获取v-model数据类型boolean改变成string
问题描述 今天产品问我一线上bug,怎么radio类型改不了 问题分析 看代码,之前的哥们儿是怎么写的 //页面 <div class="ui-form-box"> & ...
- find指令使用手册
find 目录 条件 选项 find . –print find . –print0 .指明在当前目录中查找 -print 打印匹配文件的文件名,使用‘\n’作为分隔文件的定位符 -print0 打印 ...
- 不同子系统采用不同MySQL编码LATIN1和UTF8的兼容
程序处理 这是一个历史遗留系统, 旧的系统是C++开发的, 插入数据的时候, 没有统一MYSQL各个层次(服务器, 数据库, 表, 列)的编码, 这个情况基本上是MYSQL的默认安装导致的, 实际的数 ...
- Python爬虫-Scrapy-CrawlSpider与ItemLoader
一.CrawlSpider 根据官方文档可以了解到, 虽然对于特定的网页来说不一定是最好的选择, 但是 CrwalSpider 是爬取规整的网页时最常用的 spider, 而且有很好的可塑性. 除了继 ...
- django的基本操作流程
pip install django cd Desktop/课上代码02/ #进入到创建项目的目录 django-admin startproject 项目的名称 #创建项目 __ini ...
- C++实现顺序栈类求解中缀表达式的计算
控制台第一行打印的数值为使用形如以下方式得到的结果: cout << +*(+)*/- << endl; 即第一个待求解表达式由C++表达式计算所得结果,以用于与实现得出的结果 ...