restful(1):序列化
restful协议中,一切皆是资源,操作只是请求方式
model_to_dict()方法:
from django.forms.models import model_to_dict
obj = Publish.objects.filter(pk=1).first()
model_to_dict(obj) # model_to_dict(对象)是Django的一个方法:返回一个字典,key是obj 这个对象的字段名,value是字段对应的值
restframework 下的 APIView:
# APIView流程:
1.re_path(r"^book/$",views.BookView.as_view(),name="books"), # 最终执行的是View下的view
2."book/"一旦被访问,view(request)执行 # 此时是旧的 request(原生的) <=======>等同于 view(request)执行的是 APIView这个类下的 dispatch() <=====> 请求方式对应的实例方法 3.dispatch():
# 包含初始化操作 initial() (初始化后的request都是新的request)
构建新的request对象:
self.request = Request(request)
self.request._request # 可得到旧的request
self.request.GET # 获取GET请求数据
self.request.data # 获取POST、PUT请求数据 (不用 self.request.POST的原因:.POST只能获取到 urlencoded 这个类型的请求数据) 4. 做分发:
如 GET请求:--- self.get(self,request)方法 # 此时是新的request # 原生的request(Django提供)支持的操作:
request.body # 请求体里面的原生数据
request.POST
... from rest_framework.views import APIView
# 新的request()支持的操作:
request._request # Django提供的原生的request,可 request._request.POST 等操作
request.data # 所有的请求数据(POST请求);已经反序列化后的结果
request.GET # 新的request也有 .GET的方法,相当于 request._request.GET
serializers.serialize(数据类型,QuerySet):将QuerySet序列化(Django方法)
# serializers是Django提供的一个方法,不属于 restful
from django.core import serializers
publish_list = Publish.objects.all()
ret = serializers.serialize("json",publish_list) # 将 publish_list这个queryset 序列化为 json格式的数据模型
serializers.Serializer (instance=,many=): 为QuerySet和model对象做序列化(REST方法)
# 这是restframework 提供的一个方法:
from rest_framework import serializers
book_list = Book.objects.all() class BookSerializers(serializers.Serializer): # 先创建一个序列化的类;语法 类似于 Form
title = serializers.CharField()
price = serializers.IntegerField() # 列出需要序列化出来的字段
publish = serializers.CharField(source="publish.name") # source="publish.name" 表示 取的是 publish表中的name字段 #(publish是一对多字段)
# authors = serializers.CharField(source="authors.all") # (authors是多对多字段) # 多对多时, source 可以 .all(一个方法)
authors = serializers.SerializerMethodField() # serializers.SerializerMethodField() 专门用于 多对多 字段;下面要有 get_authors方法
def get_authors(self,obj):
temp = []
for i in obj.authors.all():
temp.append(i.name)
return temp # 用上面创建出来的类对 publish_list 这个QuerySet 进行实例化
bs = BookhSerializers(publish_list,many=True) # many=True 表示序列化的是一个QuerySet;其还可以序列化 model对象
bs.data # 获取序列化后的一个列表套字典的形式(QuerySet;model对象就返回一个字典) """
BookhSerializers(instance=publish_list,many=True)序列化的实现原理:
temp = []
for obj in publish_list:
temp.append(
{
"title":obj.title,
"price": obj.price,
"publish": obj.publish.name # 有 source="publish.name" 时的情况 # 没有source="publish.name"时,是:"publish":obj.publish, (即会显示关联表中的 __str__方法)
# "authors": obj.authors.all() # 有 source="authors.all"时,返回的是一个 QuerySet
"authors": get_authors(obj) # SerializerMethodField() 情况下,"authors"字段对应的值 只取决于 get_authors方法的返回值
}
) 如果 obj中有 关联字段,则 "关联字段": str(obj.关联字段) (即 显示关联表中的 __str__方法)
"""
注:django_restframework 的 Serializer 和 ModelSerializer 返回给前端数据时,会在 ImageField 和 FileField 字段的路径前面自动加上 "/media/"(根据settings中的media配置),但 django的 Serializer 返回给前端数据时,不会在 ImageField 和 FileField 的路径前端加上 "/media/",这也是 django_restframework Serializer和ModelSerializer的完善之处。
REST 的 Serializer 需要自己写 create() 和 update() 方法。
serializers.ModelSerializer: # 语法类似于ModelForm # 可以直接对接数据库
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = "__all__" # 在mixins.CreateModelMixin中,ModelSerializer校验完成后,会拿着 fields 中的字段做序列化(序列化的目的是返回给前端);如果 fields中的某个字段不需要序列化(如 该字段也已经被你删除了),则可以把该字段设置为 write_only=True # 多对多字段序列化时,默认得到的是一个列表,列表中是 所有对象的pk值 # 自定制关联字段的序列化
# one2one/fk/choice字段:
publish = serializers.CharField(source="publish.name") # m2m字段:
authors = serializers.SerializerMethodField() # 自定义字段名要用在下面的 get_自定义字段() 这个方面中
def get_authors(self,obj): # get_m2m自定义字段()
temp = []
for i in obj.authors.all():
temp.append(i.name)
return temp
"""
如果没有自定制,默认用 ModelSerializer 自己的;
如果想 跨表 获取 choices 字段(假如为:city)的中文信息,可利用自定义字段的方式如: city = serializers.CharField(source="publish.get_city_display") # source 中的 publish.get_city_display 后面不用加 ();
非跨表的 choices 字段, 直接是 source="get_xx_display"
""" """
restframework下的序列类 ModelSerializer:
1.将QuerySet或者 一个model对象序列化成Json数据
2.做数据校验
3.json数据 转成 QuerySet/model对象,如:
def post(self,request):
bs = BookModelSerializer(data=request.data)
if bs.is_valid(): # 做校验
bs.save() # .save() 就是 create()方法 # 此时 json数据---> queryset/model对象 ---> 数据库中的一条记录
return Response(bs.data) """
mixins.CreateModelMixin代码:
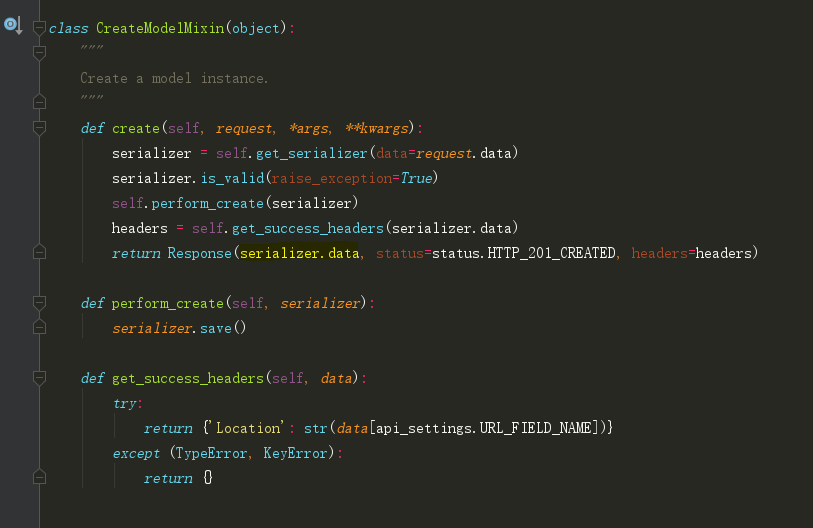
Response() 中的 serializer.data 会按照 fields 中的字段序列化
补充:
request.query_params # 获取到 GET请求数据;request是后来封装好的request
ModelSerializer.initial_data # Django DRF 的 Serializer 和 ModelSerializer 有一个属性 initial_data,前端传过来的数据都放在 initial_data 里面(字典的形式);调用 validate() 之前的数据(字段校验之前的数据) # 在 view 中,可以去 self 中取 request,如:self.request;但在 Serializer 中不能从 self 中取 request,而是要这样取 request : self.context["request"]
序列化示例
开发我们的Web API的第一件事是为我们的Web API提供一种将代码片段实例序列化和反序列化为诸如json之类的表示形式的方式。我们可以通过声明与Django forms非常相似的序列化器(serializers)来实现。
models部分:
from django.db import models # Create your models here. class Book(models.Model):
title=models.CharField(max_length=32)
price=models.IntegerField()
pub_date=models.DateField()
publish=models.ForeignKey("Publish")
authors=models.ManyToManyField("Author")
def __str__(self):
return self.title class Publish(models.Model):
name=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
def __str__(self):
return self.name
views部分:
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import *
from django.shortcuts import HttpResponse
from django.core import serializers # django的 Serializer from rest_framework import serializers # rest_framework 的 Serializer class BookSerializers(serializers.Serializer): # 该示例中 django 和 rest_framework 的 Serializer同时用这一种形式
title=serializers.CharField(max_length=32)
price=serializers.IntegerField()
pub_date=serializers.DateField()
publish=serializers.CharField(source="publish.name")
#authors=serializers.CharField(source="authors.all")
authors=serializers.SerializerMethodField()
def get_authors(self,obj):
temp=[]
for author in obj.authors.all():
temp.append(author.name)
return temp class BookViewSet(APIView): def get(self,request,*args,**kwargs):
book_list=Book.objects.all()
# 序列化方式1:
# from django.forms.models import model_to_dict
# import json
# data=[]
# for obj in book_list:
# data.append(model_to_dict(obj))
# print(data)
# return HttpResponse("ok") # 序列化方式2:
# data=serializers.serialize("json",book_list)
# return HttpResponse(data) # 序列化方式3:
bs=BookSerializers(instance=book_list,many=True)
return Response(bs.data) # 序列化后都要把 bs.data 的数据返回
ModelSerializer
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
提交的POST请求
def post(self,request,*args,**kwargs):
bs=BookSerializers(data=request.data,many=False)
if bs.is_valid(): # 做校验
# print(bs.validated_data)
bs.save() # 把数据保存到数据库中(会有反序列化操作) # .save()中有 create()方法,即 save()会调用 create() 方法
return Response(bs.data)
else:
return HttpResponse(bs.errors) # bs.errors 表示 错误信息
重写save()中的create()方法
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
# exclude = ['authors',]
# depth=1
# 添加多对多字段时需要重写 save()中的 create()方法
def create(self, validated_data):
authors = validated_data.pop('authors') # 返回 authors(多对多字段) 并返回
obj = Book.objects.create(**validated_data) # 添加非多对多字段
obj.authors.add(*authors) # 在第三张表中添加authors
return obj
单条数据的GET和PUT请求
class BookDetailViewSet(APIView):
def get(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj) # 把查到的 记录obj 序列化后返回给用户
return Response(bs.data)
def put(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,data=request.data) # Serializer(要修改的记录对象,data=需要更新的数据) # 更新操作
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
超链接API:Hyperlinked
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__" # 让 publish 字段获取到的值为其对应的一个 url
publish= serializers.HyperlinkedIdentityField(
view_name='publish_detail', # 别名是“publish_detail”的url
lookup_field="publish_id", # 需要查询的字段
lookup_url_kwarg="pk") # url中为“pk”的有名分组 # 有 HyperlinkedIdentityField 时, 需要在 序列化类实例化时 添加 "context={'request',request}"
urls部分:
urlpatterns = [
url(r'^books/$', views.BookViewSet.as_view(),name="book_list"),
url(r'^books/(?P<pk>\d+)$', views.BookDetailViewSet.as_view(),name="book_detail"),
url(r'^publishers/$', views.PublishViewSet.as_view(),name="publish_list"),
url(r'^publishers/(?P<pk>\d+)$', views.PublishDetailViewSet.as_view(),name="publish_detail"),
]
rest_framework 的 Serializer 和 ModelSerialzer 可参考: https://blog.csdn.net/FightFightFight/article/details/80059024
HiddenField字段:
class UserFavSerializer(serializers.ModelSerializer):
user = serializers.HiddenField(
default=serializers.CurrentUserDefault()
) # HiddenField 的值不需要用户自己post数据过来,也不会显示返回给用户;配合 CurrentUserDefault() 可以实现自动获取到当前用户 class Meta:
model = UserFav
fields = ("user","goods","id") # 如果此处还需要一个删除功能,则 fields 里面还需要加上 "id",从而创建之后也把 id 返回给前端
DRF Serializer 详细用法可参考:https://blog.csdn.net/l_vip/article/details/79156113
DRF Serializer 的 验证
1.字段级别的验证
你可以通过向你的Serializer子类中添加 .validate_<field_name> 方法来指定自定义字段级别的验证。这些类似于Django表单中的.clean_<field_name>方法。
这些方法采用单个参数,即需要验证的字段值。
你的validate_<field_name>方法应该返回 一个验证过的数据 或者 抛出一个serializers.ValidationError异常。例如:
from rest_framework import serializers class BlogPostSerializer(serializers.Serializer):
title = serializers.CharField(max_length=100)
content = serializers.CharField() def validate_title(self, value):
"""
Check that the blog post is about Django.
"""
if 'django' not in value.lower():
raise serializers.ValidationError("Blog post is not about Django")
return value
注意: 如果你在序列化器中声明<field_name>的时候带有required=False参数,字段不被包含的时候这个验证步骤就不会执行。
2. 对象级别的验证
要执行需要访问多个字段的任何其他验证,请添加一个 .validate() 方法到你的Serializer子类中。这个方法采用字段值字典的单个参数,如果需要应该抛出一个 ValidationError异常,或者知识返回经过验证的值。例如
from rest_framework import serializers class EventSerializer(serializers.Serializer):
description = serializers.CharField(max_length=100)
start = serializers.DateTimeField()
finish = serializers.DateTimeField() def validate(self, data):
"""
Check that the start is before the stop.
"""
if data['start'] > data['finish']:
raise serializers.ValidationError("finish must occur after start")
return data
DRF ModelSerializer 保存密码的方法:
# ModelSerializer 在 保存前端传过来的数据时(.save()方法),是直接把这些数据保存到数据库的;这时保存到数据库的密码也是明文的,为了将密码保存为密文的,则需要重构 .save()方法 调用的 create() 方法 from rest_framework import serializers
from rest_framework.validators import UniqueValidator # 验证字段的值唯一 class UserRegSerializer(serializers.ModelSerializer):
"""用户注册"""
code = serializers.CharField(required=True, write_only=True, max_length=4, min_length=4, label="验证码",
error_messages={
"blank": "请输入验证码",
"max_length": "验证码格式错误",
"min_length": "验证码格式错误"
},
help_text="验证码") # write_only=True 表示 只写模式,即只能反序列化,不能序列化、发送给前端
username = serializers.CharField(label="用户名",required=True,allow_blank=False,help_text="用户名",
validators=[UniqueValidator(queryset=UserInfo.objects.all(),message="用户已经存在")]) # validators 表示验证器;UniqueValidator 用于验证字段的值唯一 password = serializers.CharField(
style={"input_type":"password"},help_text="密码",label="密码",write_only=True
) # style={"input_type":"password"} 用于说明该字段是 password 的类型(前端输入的时候会隐藏);write_only=True 不能返回给前端 # 重构 create() 方法,让密码以密文保存
def create(self, validated_data):
user = super(UserRegSerializer, self).create(validated_data)
user.set_password(validated_data["password"]) # 重置密码
user.save()
return user class Meta:
model = UserInfo
fields = ("username","code","mobile","password") # code 和 password 这两个字段不会发送给前端(由于 write_only )
restful(1):序列化的更多相关文章
- Restful 3 -- 序列化组件(GET/PUT/DELETE接口设计)、视图优化组件
一.序列化组件 基于上篇随笔的表结构,通过序列化组件的ModelSerializer设计如下三个接口: GET 127.0.0.1:8000/books/{id} # 获取一条数据,返回值:{} PU ...
- SrpingMVC/SpringBoot中restful接口序列化json的时候使用Jackson将空字段,空字符串不传递给前端
笔者的JSON如下: { "code": 10001, "message": "成功", "nextUrl": null ...
- 在django restful framework中设置django model的property
众所周知,在django的model中,可以某些字段设置@property和setter deleter getter,这样就可以在存入数据的时候进行一些操作,具体原理请参见廖雪峰大神的博客https ...
- django restful framework 一对多方向更新数据库
目录 django restful framework 序列化 一 . 数据模型: models 二. 序列化: serializers 三, 视图: views 四, 路由: urls 五. 测试 ...
- rest-framwork官方文档教程(一)
该项目是按照官网quickstart进行的,具体也可查看rest-framework官网: https://www.django-rest-framework.org/tutorial/quickst ...
- Django编写RESTful API(一):序列化
欢迎访问我的个人网站:www.comingnext.cn 关于RESTful API 现在,在开发的过程中,我们经常会听到前后端分离这个技术名词,顾名思义,就是前台的开发和后台的开发分离开.这个技术方 ...
- python 全栈开发,Day95(RESTful API介绍,基于Django实现RESTful API,DRF 序列化)
昨日内容回顾 1. rest framework serializer(序列化)的简单使用 QuerySet([ obj, obj, obj]) --> JSON格式数据 0. 安装和导入: p ...
- rest-framework 序列化格式Restful API设计规范
理解RESTful架构 Restful API设计指南 理解RESTful架构 越来越多的人开始意识到,网站即软件,而且是一种新型的软件. 这种"互联网软件"采用客户端/服务器模式 ...
- RESTful API终极版序列化封装
urls: from django.conf.urls import url from app01 import views urlpatterns = [ # url(r"comment/ ...
随机推荐
- jmeter(十)JMeter 命令行(非GUI)模式
前文 讲述了JMeter分布式运行脚本,以更好的达到预设的性能测试(并发)场景.同时,在前文的第一章节中也提到了 JMeter 命令行(非GUI)模式,那么此文就继续前文,针对 JMeter 的命令行 ...
- VMware虚拟机中涉及的3种常见网络模式
桥接模式.这种模式下,虚拟机和物理机连的是同一个网络,虚拟机和物理机是并列关系,地位是相当的.比如你家如果有用路由器,那么你的电脑和你的手机同时连接这个路由器提供的Wi-Fi,那么它们的关系就是这种模 ...
- 10.3 Implementing pointers and objects and 10.4 Representing rooted trees
Algorithms 10.3 Implementing pointers and objects and 10.4 Representing rooted trees Allocating an ...
- vscode增加xdebug扩展
首先确保php增加了xdebug扩展,方法很多,可参考 https://www.cnblogs.com/wanghaokun/p/9084188.html.可通过phpinfo()查看是否已开启支持. ...
- Farseer.net轻量级开源框架说明及链接索引
Farseer.net是什么? 基于.net framework 4 开发的一系列解决方案. 完全开源在GitHub中托管.并发布到NuGet中. Farseer.Net由最初的关系数据库ORM框架后 ...
- Spring Boot(15)——自动配置Validation
自动配置Validation当应用中的Classpath下存在javax.validation的实现时,Spring Boot的org.springframework.boot.autoconfigu ...
- Java 类执行顺序
1.如果父类有静态成员赋值或者静态初始化块,执行静态成员赋值和静态初始化块2.如果类有静态成员赋值或者静态初始化块,执行静态成员赋值和静态初始化块3.将类的成员赋予初值(原始类型的成员的值为规定值,例 ...
- 10 Steps To be a senior programmer
What 软件工程师的职业生涯要历经以下几个阶段:初级.中级,最后才是高级.这篇文章主要是讲如何通过 10 个步骤助你成为一名高级软件工程师. Why 得到更多的报酬!因为你的薪水会随着你水平的提高而 ...
- Poi 写入图片进入excel
public static void cacheWritePicture(BufferedImage bufferImg, Sheet sheet, Workbook wb, int width, i ...
- Oracle数据库自定义函数练习20181031
--测试函数3 CREATE OR REPLACE FUNCTION FN_TEST3 (NUM IN VARCHAR2) RETURN VARCHAR2 IS TYPE VARCHAR2_ARR ) ...