看到了一篇不错的tensorflow文章
http://dataunion.org/28906.html
本文作者 Steven Dufresne,总结了新手学 TensorFlow 需要的核心知识点和实操内容,旨在鼓励更多人借 TensorFlow 迈入深度学习殿堂 。作为基础入门教程,该教程从 TensorFlow 原理简介讲到上手操作,对核心概念逐条解释,非常适合基础薄弱、苦无入门途径的新手。
Steven Dufresne:在90年代我开始写神经网络软件。TensorFlow开源后,一直十分渴望用它搭建一些有趣的东西。
谷歌的人工智能系统是现在的新热点。当TensorFlow可以被安装在树莓派上,操作变得非常容易。在上面我很快就搭建了一个二进制神经网络。这篇文章中,我将把经验分享给大家,帮助其他想要尝试、深入了解神经网络的人更快上手。
TensorFlow是什么?
引用TensorFlow官网的话,TensorFlow是一个“采用数据流图进行数值计算的开源软件库”。其中“数据流图”是什么意思?这是个很酷的东西。在正式回答之前,我们先谈谈一个简单神经网络的结构。
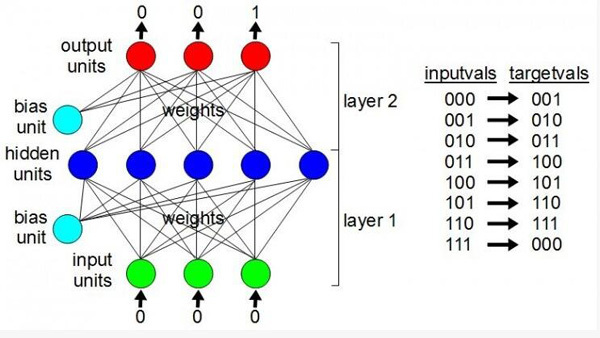
神经网络基础
一个简单神经网络由输入层(input units)、隐层(hidden units)、阈值(bias unit)、输出层(output units)几部分构成。输入层负责接收数据。隐层之所以这么叫是因为从用户的角度来看,它们是隐藏的。输出层输出我们获得的结果。旁边的阈值是用来控制隐含层和输出层的值是否输出(即超过阈值的神经元才能输出)。两两不同神经元之间的连接是权重,只是一些数字,需要靠训练获得。
训练神经网络,就是为了给权重找到最佳的值,这让神经网络一步步变得“智能”。在下面这个例子中,输入神经元的值被设置为二进制数字0,0,0。接下来TensorFlow会完成这之间的所有事情,而输出神经元会神奇得包含数字0,0,1。即便你漏掉了,它也知道二进制中000下面一个数是001,001接下来是010,就这样一直到111.一旦权重被设定了合适的值,它将知道如何去计数。
在运行神经网络中有一个步骤是将每一个权重乘以其对应的输入神经元,然后将乘积结果保存在相应的隐藏神经元。
我们可以将这些神经元和权重看作成数列(array),在Python中也被称为列表(list)。从数学的角度来看,它们都是矩阵。图中我们只绘制出了其中一部分,这里将输入层矩阵和权重矩阵相乘,得到五元素隐藏层矩阵(亦称为列表或数列)。
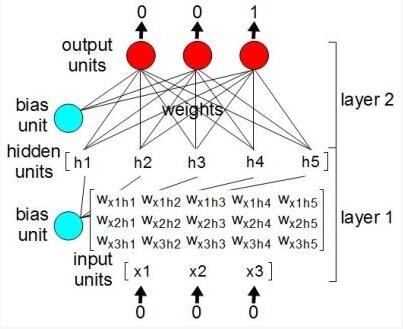
从矩阵到张量
在TensorFlow中,这些列表(lists)被称为张量(tensors)。矩阵相乘被称为操作(operation,也翻译作计算节点或运算),即程序员常说的op,阅读TensorFlow官方文件时会经常遇到。进一步讲,神经网络就是一堆张量、以及操作张量的 op 的集合,它们共同构成了神经网络图(graph)。
以下图片取自《TensorBoard, a tool for visualizing the graph》这篇文章,用于检测训练前后的张量值变化。张量是图中的连线,上面的数字代表张量的维度(dimensions)。连接张量的节点是各种操作(op),双击后可以看到更多的细节,比如后面一张图是双击后展现的第一层(layer 1)的细节。
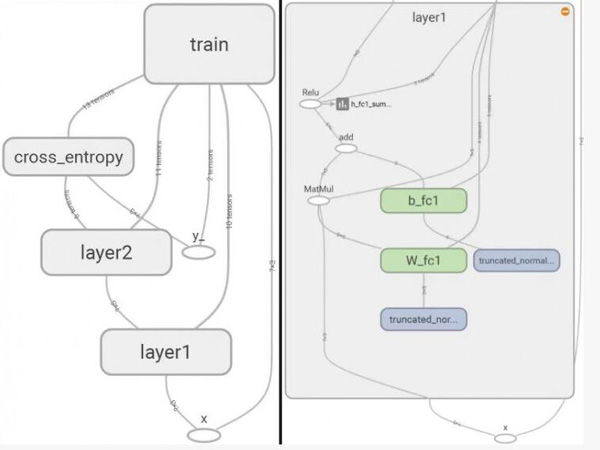
最下面的X,是占位符操作,向输入张量赋值。沿着左边的线向上是输入张量(input tensor)。上面节点标着MatMul操作,使输入张量(input tensor)和权重张量(weight tensor,导向MatMul操作的另一条线)矩阵相乘。
所有这些只是为了更直观的展示出图、张量和操作是什么,让大家更好的理解为什么TensorFlow被称为是“采用数据流图进行数值计算的开源软件库”。但是,我们为什么要创建这些图呢?
为什么创建图?
当前,TensorFlow 只有 Python 的稳定 API,Python 是一门解释型语言。神经网络需要大量的运算,大型神经网络包含数千甚至数百万的权重,通过解释(interpret)每一步来计算的效率极低。
因此,我们通过创建一个由张量和 op 构成的图,包括所有的数学运算甚至变量的初始值,来描述神经网络的结构。只有在创建图之后,才能加载到TensorFlow里的Session。这被称为TensorFlow的“延迟执行”(deferred execution)。 Session通过高效代码来运行计算图。不仅如此,许多运算,例如矩阵相乘,都可以在GPU上完成。此外,TensorFlow也支持多台机器或者GPU同时运行。
创建二进制计数器图
以下是创建二进制计数器神经网络(binary counter neural network)的脚本,完整的代码可以在我的 GitHub 网页上找到。注意,在TensorBoard里还有其他的一些代码保存在其中。
下面我们将从这些代码开始创建张量和 op 组成的图。
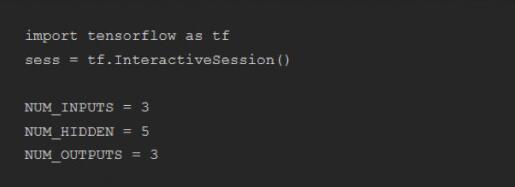
首先导入 “tensorflow” 模块,创建一个 session 随后使用。同时,为了让脚本更容易理解,我们也创建了一些变量,包含了网络中的神经元个数。

然后,我们为输入和输出的神经元创建占位符(placeholders)。占位符是TensorFlow里一个操作,便于后续输入实际的数值。这里X和y_是图中的两个张量,每一个都有相关联的 placeholder 操作。
你可能会觉得奇怪,为什么我们要将占位符shape定义为二维列表[None,NUM_INPUTS]和[None,NUM_OUTPUTS],第一个维度都是”None”?从整体来看,神经网络有点像我们每次输入一个值,训练它生成一个特定输出值。但更有效率的方式是,一次提供多个输入\输出对(pair),这就是 batch 。上面shape中的第一维,是每个 batch 中有几组输入/输出对。创建一个 batch 之前我们并不知道里面有几组。实际上,后续我们将使用同一个图来进行训练、测试以及实际使用,所以 batch 的大小不会每次都相同。因此,我们将第一维的大小设置为 Python 占位符对象 ”None“。

接下来,我们创建神经网络图的第一层:将权重定义为W_fc1,阈值(或偏差)定义为b_fc1,隐层定义为h_fc1。这里”fc”意为“完全连接(fully connected)”的意思,因为权重把每一个输入神经元和每一个隐藏神经元连接起来。
tf.truncated_normal 导致了一系列操作和张量,将会把所有权重赋值为标准化的随机数字。
Variable 的操作会给出初始化的值,这里是随机数字,在后面可以多次引用。一旦训练完,也可以很方便的将神经网络保存至文件中。
你可以看到我们用 matmul 操作来执行矩阵乘法的位置。我们插入一个 add 操作来加入偏差权重(bias weights)。其中 relu 运算执行的就是“激活函数”(activation function)。矩阵乘法和加法都是线性运算。神经网络用线性运算能做的事非常少。激活方程提供了一些非线性。这里的relu激活函数,就是将所有小于0的值设置为0,其余值不变。不管你信不信,这为神经网络能够学习的东西打开了一扇全新的大门。

神经网络第二层中的权重和阈值与第一层设置的一样,只是输出层不同。我们再次进行矩阵相乘,这一回乘的是权重和隐层,随后加入偏差权重(bias weights),激活函数被留到下一组代码。

与上面的relu类似,Sigmoid是另一个激活函数,也是非线性的。这里我使用sigmoid函数,一定程度上是因为它能使最终输出值为一个0和1之间,对于二进制计数器而言是一个理想的选择。在我们的例子中,为了表示二进制111,所有的输出神经元都可以有一个很大的值。这和图像分类不同,后者会希望仅仅用一个输出单元来输出一个很大的值。举个例子,比如一张图像里有长颈鹿,我们会希望代表长颈鹿的输出单元输出相当大的值。这种情况下,用softmax函数作为激活函数反倒更适合。
仔细看下前面的代码,会发现似乎有些重复,我们插入了两次sigmoid。实际是我们创建了两次不同的、并行的输出。其中cross_entropy张量将被用来训练神经网络。而 results 张量则是后续用来执行训练过的神经网络,不管它被训练出来作何目的。这是目前我能想到的最好的方法。

最后一件事就是训练(training)。也就是基于训练数据调整所有的权重。记住,在这里我们仍然只是创建一个图。真正的“训练”发生在我们开始运行这个图的时候。
运行过程中供选择的优化器很多,这里我选取了 tf.train.RMSPropOptimizer。因为就像sigmoid一样,它比较适合所有输出值都可能较大的情况。而针对分类的情形,例如图像分类,用tf.train.GradientDescentOptimizer效果可能更好。
训练和使用二进制计数器
在完成创建图之后,就可以开始训练了。

首先,要准备一些训练数据:包括输入变量 inputvals 和目标变量 targetvals 。其中 inputvals 包含输入值,后者的每一个都有对应的 targetvals 目标值。例如,inputvals[0]即[0, 0, 0] ,对应的输出或目标值为targetvals[0] ,也就是 [0, 0, 1] 。

do_training和save_trained都可以硬编码,每次都可以进行更改,或者使用命令行参数进行设置。
首先使所有 Variable 操作对张量初始化;然后,将之前创建的图从底部到 train_step执行最多不超过 10001 遍;这是最后一个添加到图中的东西。我们将 inputvals和targetvals通过RMSPropOptimizer导入train_step操作。这就是通过调整权重,在给定输入值的情况下,让输出值不断接近目标值的步骤。只要输出值和目标值之间的误差足够小,小到某个能承受的范围,这个循环就会停止。
如果你有成百上千的输入/输出组,你可以一次训练一个子集,也就是前面提到的一批(batch)。但这里我们一共只有8组,所以每次都全放进去。
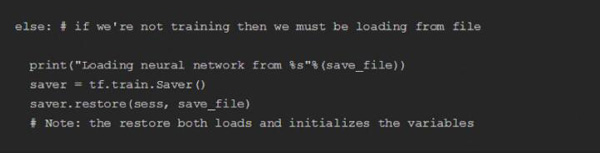
我们也可以将训练好的神经网络保存在一个文件(file)中,下次就不用再训练了。下次可以直接导入一个已经训练过的神经网络文件,文件中只包含进行过变量运算后的张量的值,而不包含整个图的结构。所以即便是执行已经训练好的图,我们仍然需要脚本来创建图形。MetaGraphs可以进行文件保存和导入图,但这里我们不这么做。
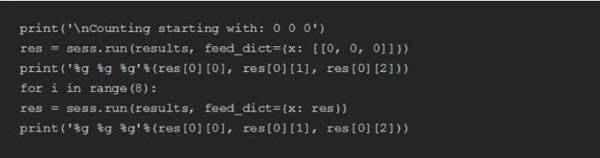
请注意,我们是从图形底部运行至结果张量(results tensor),在训练网络中不断重复的创建结果。
我们输入000,希望它返回一个接近001的值。然后将返回的值重复输入再次执行。这样总共运行9次,保证从000数到111有足够的次数,之后再次回到000。
以下就是成功训练后的输出结果。在循环中被训练了200次(steps)。在实际中,训练了10001次仍没有有效降低训练误差的情况非常罕见。一旦训练成功,训练多少次并不重要。
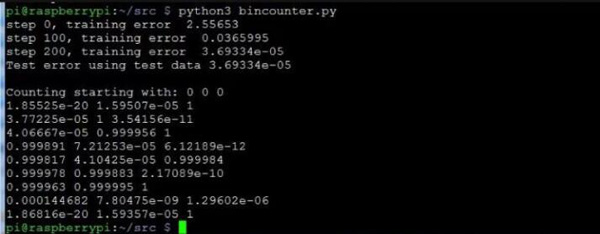
运行二进制计数器
下一步
前面说过,这里讲的二进制计数神经网络代码可以在我的Github主页上找到。你可以根据这些代码开始学习,或者观看TensorFlow官网上的其他入门教程。下一步,根据机器人识别物体上获取的灵感,我想通过它做一些硬件方面的研究。
看到了一篇不错的tensorflow文章的更多相关文章
- 《转载-两篇很好的文章整合》Android中自定义控件
两篇很好的文章,有相互借鉴的地方,整合到一起收藏 分别转载自:http://blog.csdn.net/xu_fu/article/details/7829721 http://www.cnblogs ...
- 给B公司的一些建议(又一篇烂尾的文章)
感慨:太多太多的悲伤故事,发生在自己身上,发生在自己的身边.因此,为了避免总是走"弯路",走"错误"的道路,最近一直在完善自己的理论模型. 烂尾说明:本文是一篇 ...
- 小鹏汽车技术中台实践 :微服务篇 InfoQ 今天 以下文章来源于InfoQ Pro
小鹏汽车技术中台实践 :微服务篇 InfoQ 今天 以下文章来源于InfoQ Pro
- 一篇不错的Gibbs Sampling解释文章,通俗易懂
http://cos.name/2013/01/lda-math-mcmc-and-gibbs-sampling/ 直接原文的链接了.原文写的不错,是中文博客中说的比较明白的了. 但为了保留文章,随 ...
- 一篇不错的讲解Java异常的文章(转载)原作者已没法考证
六种异常处理的陋习 你觉得自己是一个Java专家吗?是否肯定自己已经全面掌握了Java的异常处理机制?在下面这段代码中,你能够迅速找出异常处理的六个问题吗? 1 OutputStreamWriter ...
- DDD:两篇不错的文章
文章列表 Coding for Domain-Driven Design: Tips for Data-Focused Devs. Strengthening your domain: Aggrega ...
- 一篇不错的讲解Java异常的文章(转载)
http://www.blogjava.net/freeman1984/archive/2007/09/27/148850.html 六种异常处理的陋习 你觉得自己是一个Java专家吗?是否肯定自己已 ...
- 一篇不错的关于分析MVC的文章
1 简介 英文原文:MVC vs. MVP vs. MVVM 三者的目的都是分离关注,使得UI更容易变换(从Winform变为Webform),使得UI更容易进行单元测试. 2 MVC/MVP 2.1 ...
- 一篇不错的讲解Java异常的文章(转载)----感觉很不错,读了以后很有启发
六种异常处理的陋习 你觉得自己是一个Java专家吗?是否肯定自己已经全面掌握了Java的异常处理机制?在下面这段代码中,你能够迅速找出异常处理的六个问题吗? OutputStreamWriter ou ...
随机推荐
- Oracle 表的创建 及相关參数
1. 创建表完整语法 CREATE TABLE [schema.]table (column datatype [, column datatype] - ) [TABLESPACE tablespa ...
- UVA11324 The Largest Clique —— 强连通分量 + 缩点 + DP
题目链接:https://vjudge.net/problem/UVA-11324 题解: 题意:给出一张有向图,求一个结点数最大的结点集,使得任意两个结点u.v,要么u能到达v, 要么v能到达u(u ...
- YTU 2597: 编程题B-选拔飞行员
2597: 编程题B-选拔飞行员 时间限制: 1 Sec 内存限制: 128 MB 提交: 131 解决: 35 题目描述 2100年空军选拔高中生飞行学员基本条件要求如下,年龄范围:16-19周 ...
- python名片管理系统V2
主程序: #! /usr/bin env python3 # -*- coding: utf-8 -*- # 项目三: # 1.要求:编写一个名片管理系统,功能如下: # 用户输入相对应的指令,实现对 ...
- 《The Unreasonable Effectiveness of Recurrent Neural Networks》阅读笔记
李飞飞徒弟Karpathy的著名博文The Unreasonable Effectiveness of Recurrent Neural Networks阐述了RNN(LSTM)的各种magic之处, ...
- 机器学习--DIY笔记与感悟--①K-临近算法
##“计算机出身要紧跟潮流” 机器学习作为如今发展的趋势需要被我们所掌握.而今我也需要开始learn机器学习,并将之后的所作所想记录在此. 今天我开始第一课--K临近算法. 一.k-临近的基础概念理解 ...
- php pdo操作数据库
POD扩展是在PHP5中加入,该扩展提供PHP内置类 PDO来对数据库进行访问,不同数据库使用相同的方法名,解决数据库连接不统一的问题. PDO的特点: 性能.PDO 从一开始就吸取了现有数据库扩展成 ...
- Linux 常用命令十三 kill
一.kill命令 kill命令用来删除执行中的程序或工作.kill可将指定的信息送至程序.预设的信息为SIGTERM(15),可将指定程序终止.若仍无法终止该程序,可使用SIGKILL(9)信息尝试强 ...
- bzoj 4517: [Sdoi2016]排列计数【容斥原理+组合数学】
第一个一眼就A的容斥题! 这个显然是容斥的经典问题------错排,首先考虑没有固定的情况,设\( D_n \)为\( n \)个数字的错排方案数. \[ D_n=n!-\sum_{t=1}^{n}( ...
- 前缀和小结 By cellur925
这篇主要是来介绍前缀和的QAQ. 前缀和有一维的和二维的,一维的很容易理解,高中数学必修5第二章数列给出了前n项和的概念,就是前缀和.一维的我们在这里简单说一句. 一维前缀和 预处理:在输入一个数列的 ...