Python基础第七天
一、内容
二、练习
练习1
题目:编写函数,函数执行的时间是随机的
图示:
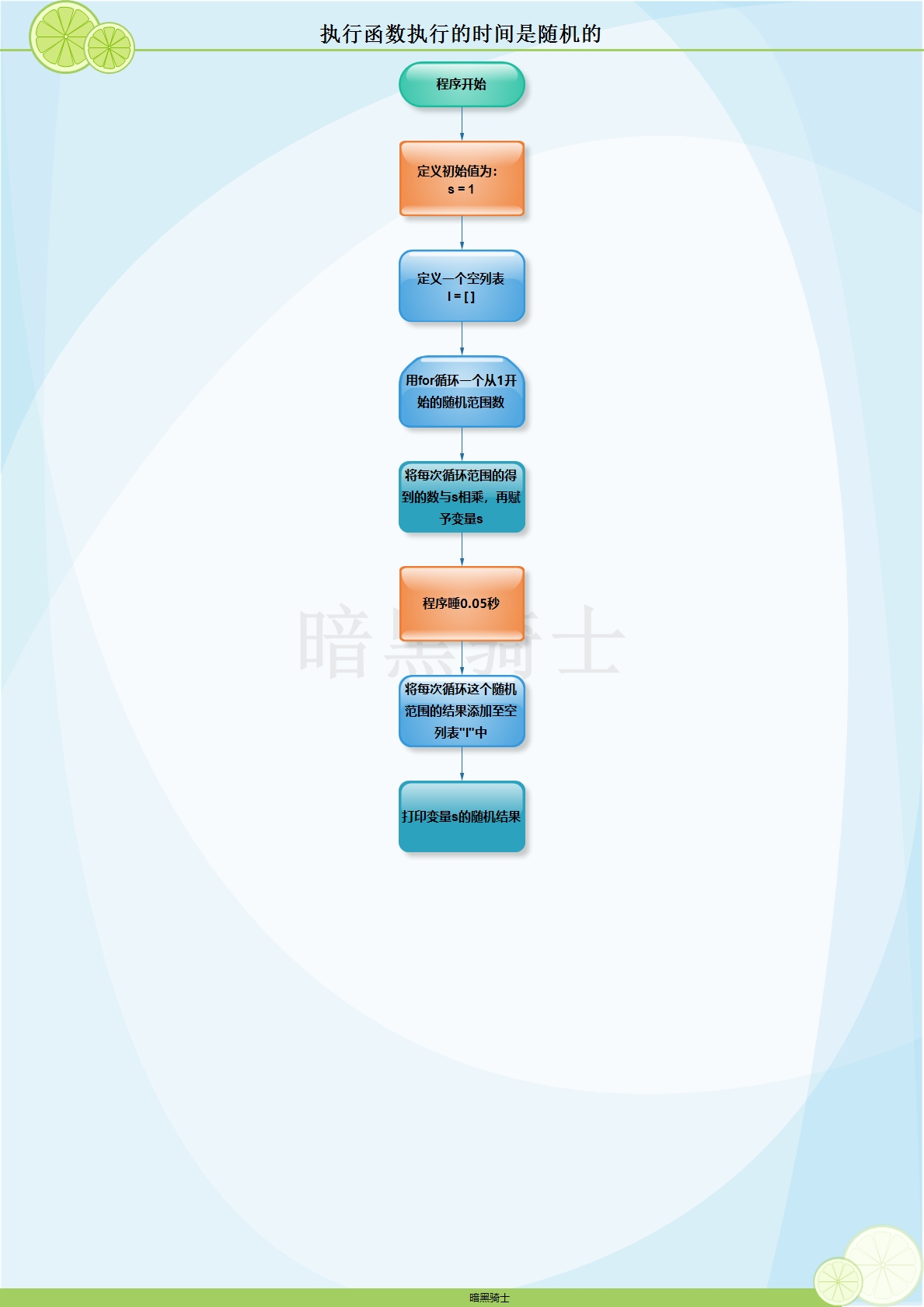
代码:
import time
import random def func():
s = 1
l = []
for i in range(1,random.randrange(1,50)):
s *= i # s的最大值为:s = 1 * 2 * 3...50
time.sleep(0.05)
l.append(i) # 再把变量i添加至列表l里,此时l列表中的元素最大值为l = [1,2,3,4..50]
print("%s‘sproduct is%d"%(l,s))
func()
练习2
题目:编写装饰器,为函数加上统计时间的功能
代码:
import time
import random def timmer(data):
def wrapper(*args,**kwargs):
start_time = time.time()
data(*args,**kwargs)
stop_time = time.time()
print('The function runs %s seconds'%(stop_time - start_time))
return wrapper
@timmer
def func():
s = 1
l = []
for i in range(1,random.randrange(1,50)):
s *= i # s的最大值为:s = 1 * 2 ...* 50
time.sleep(0.05)
l.append(i) # 再把变量i添加至列表l里,此时l列表中的元素最大值为l = [1,2,3...50]
print("%s‘sproduct is:%d"%(l,s))
func()
输出结果:
例:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39]‘sproduct is20397882081197443358640281739902897356800000000
The function runs 2.407280206680298 seconds
练习3
题目:编写装饰器,为函数加上认证的功能
代码:
def auth(data):
def wrapper(*args,**kwargs):
user = 'knight'
pwd = 'dk123'
count = 1
while True:
if count == 4:
print('Too many times')
break
username = input('Please enter username:').strip()
passowrd = input('Please enter password:')
if username == user and passowrd == pwd:
print('Login successfully!')
data(*args, **kwargs)
break
else:
print('Login failed')
print('You still have %s chances'%(3-count))
count += 1
return wrapper
@auth
def func():
s = 1
l = []
for i in range(1,random.randrange(1,50)):
s *= i # s的最大值为:s = 1 * 2 ...* 50
time.sleep(0.05)
l.append(i) # 再把变量i添加至列表l里,此时l列表中的元素最大值为l = [1,2,3...50]
print("%s‘sproduct is:%d"%(l,s))
func()
练习4
题目:
编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件),要求登录成功一次,后续的函数都无需再输入用户名和密码
注意:从文件中读出字符串形式的字典,可以用eval('{"name":"knight","password":"dk123"}')转成字典格式
文件内容如下:
{'name': 'knight', 'password': 'dk123'}
{'name': 'lisa', 'password': '123'}
{'name': 'tangbao', 'password': 'tangbao123'}
{'name': 'zhuozi', 'password': 'zz123'}
{'name': 'laozhang', 'password': 'lz110'}
图示:

代码:
# 编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件),要求登录成功一次,后续的函数都无需再输入用户名和密码
# 注意:从文件中读出字符串形式的字典,可以用eval('{"name":"knight","password":"dk123"}')转成字典格式 db_path=r'C:\Users\William\PycharmProjects\Item_Python1\day7\user_info.txt'
user_dic={
'knight':'dk123',
'lisa':'123',
'tangbao':'tangbao123',
'zhuozi':'zz123',
'laozhang':'lz110'
} # 将字典强转为字符串写入至文件db_path中
with open(db_path,'w',encoding='utf-8') as f:
f.write(str(user_dic)) # 定义一个字典,让用户名默认对应None,登陆状态默认对应False
login_dic={
'user':None,
'status':False,
} # 装饰器函数
def auth(func):
def wrapper(*args,**kwargs):
with open(db_path,'r',encoding='utf-8') as f:
user_dic=eval(f.read()) # 将文件"db_path"里的内容转成字典形式 # 用户名不为空,并且登陆状态不是False
while not login_dic['user'] and not login_dic['status']:
username = input('Please enter username:').strip()
password = input('Please enter password:')
if username in user_dic: # 判断用户名是否在字典user_dic内,当在字典user_dic中时 if password == user_dic[username]: # 判断密码是否为字典user_dic中键所对应的值。
print('login successful')
login_dic['user'] = username # 将用户输入的用户名添加至login_dic字典里
login_dic['status'] = True # 将login_dic中的’status‘的False改为True
# (登陆状态改为True)
res=func(*args,**kwargs)
return res
else:
print('password error') # 密码若不匹配字典user_dic[username]中时,提示密码错误
continue # 并退出本次循环继续循环(反复输入) else:print('not found username') # 如果不在字典user_dic里时提示没有找到用户名 # 表示用户为为空时并且登陆状态为False时,直接输出原函数
else:
res = func(*args, **kwargs)
return res
return wrapper @auth
# 原函数index
def index():
print('welcome to index') # 原函数home
@auth
def home(name):
print('welcome %s to home page'%name) # 调用函数index与home
index()
home('knight')
输出结果:
1、输入一个不存在于字典user_dic中的用户名:
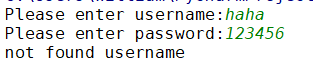
2、输入一个存在于字典user_dic中的用户名,但密码不匹配:

3、输入一个存在于字典user_dic中的,并且密码匹配:

练习5
题目:编写下载网页内容的函数,要求功能是:用户传入一个url,函数返回下载页面的结果
代码:
from urllib.request import urlopen def get(url):
return urlopen(url).read() # 将下载的内容直接返回
print(get('https://www.python.org'))
练习6
题目:为练习5编写装饰器,实现缓存网页内容的功能:
具体:实现下载的页面存放于文件中,如果文件内有值(文件大小不为0),就优先从文件中读取网页内容,否则,就去下载,然后存到文件中
图示:
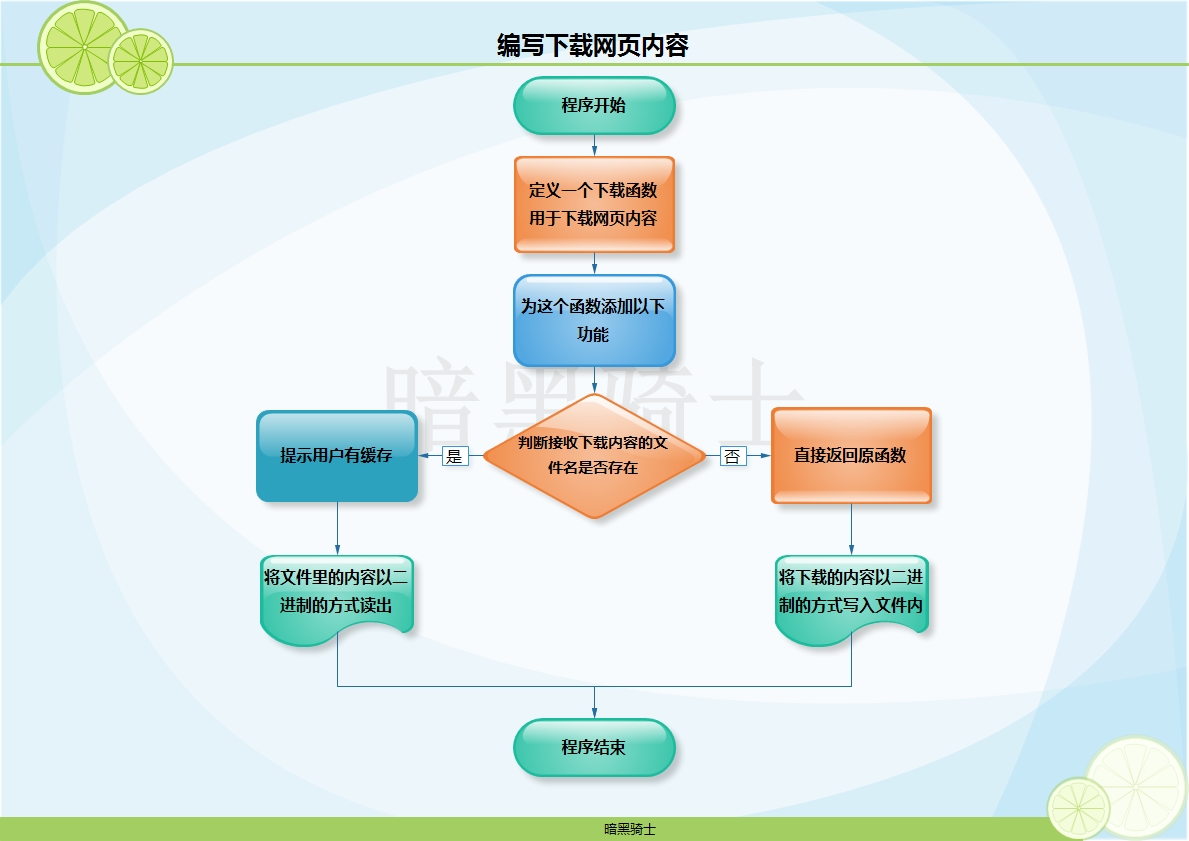
代码:
from urllib.request import urlopen # 调用下载模块
import os cache_path=r'C:\Users\William\PycharmProjects\Item_Python1\day7\cache.txt'
def make_cache(func):
def wrapper(*args,**kwargs):
if os.path.getsize(cache_path):
# 返回文件大小,如果文件不存在就返回错误,这里表示有缓存 print('\033[45m*******有缓存*******\033[0m') # 打印有缓存,\033[45m...\033[0m 表示字体颜色
with open(cache_path,'rb') as f: # 将这个文件以"rb"的模式读取出来,二进制的方式读
res = f.read() # 得到二进制 else:
# 文件没有内容,直接返回原函数,这里表示无缓存
res=func(*args,**kwargs)
with open(cache_path,'wb') as f: # 将原函数的内容以二进制的写的方式直接写入至文件cache_path中
f.write(res)
return res
return wrapper @make_cache
# 原函数
def get(url):
return urlopen(url).read() # 调用函数
print('========>first')
print(get('https://www.python.org'))
print('========>second')
print(get('https://www.python.org'))
print('========>third')
print(get('https://www.python.org'))
练习7
题目:基于上面网页缓存装饰器的基础上,实现缓存不同网页的功能,要求,用户提交的不同url,都能缓存下来,对相同的url发起下载请求,优先从缓存里取内容。
图示:
示例:
Python基础第七天的更多相关文章
- python基础-第七篇-7.2面向对象(进阶篇)
进入到今天的探索前,我先对上节内容进行一下回顾: 面向对象是一种编程方式,此编程方式的实现是基于对类和对象的使用 类是一个模板,模板中包装了多个函数可供使用 对象是基于类创建的,实例用于调用被包装在类 ...
- python基础-第七篇-7.4异常处理
异常基础: 异常处理首先要捕获异常,不让程序中断,也不让错误信息直接呈现出来,然后就是你该怎么处理异常,以什么方式显示 try: pass except Exception,ex: pass 在需要用 ...
- Python基础(七)内置函数
今天来介绍一下Python解释器包含的一系列的内置函数,下面表格按字母顺序列出了内置函数: 下面就一一介绍一下内置函数的用法: 1.abs() 返回一个数值的绝对值,可以是整数或浮点数等. 1 2 3 ...
- python基础知识七
我们会使用raw_input和print语句来完成这些功能. 对于输出,也可以使用多种多样的str(字符串)类. 例如使用rjust方法来得到一个按一定宽度右对齐的字符串. 可以通过创建一个file类 ...
- Python基础(七)-文件操作
一.文件处理流程 1.打开文件,得到文件句柄赋值给一个变量 2.通过句柄对文件进行操作 3.关闭文件 二.基本操作 f = open('zhuoge.txt') #打开文件 first_line = ...
- python基础(七)
一.接口开发 import pymysql def my_db(sql): conn = pymysql.connect( host='118.24.3.40', user='jxz', passwo ...
- python基础(七)——网络编程
服务端 我们使用 socket 模块的 socket 函数来创建一个 socket 对象.socket 对象可以通过调用其他函数来设置一个 socket 服务. 现在我们可以通过调用 bind(hos ...
- python基础-第七篇-7.1初识类和对象
创建类和对象 刚开始我们接触得多的编程方式为面向过程编程,这种方式就是根据业务逻辑从上往下垒代码,后来又出现了函数式编程,就是为了提高代码的重用性,减轻程序猿的工作量--而今天我们即将学的 面向对象编 ...
- Python基础学习七 Excel操作
python操作excel,python操作excel使用xlrd.xlwt和xlutils模块, xlrd模块是读取excel的,xlwt模块是写excel的,xlutils是用来修改excel的. ...
随机推荐
- 【最长上升子序列记录路径(n^2)】HDU 1160 FatMouse's Speed
https://vjudge.net/contest/68966#problem/J [Accepted] #include<iostream> #include<cstdio> ...
- 由八数码问题引入。对BFS有更深考虑
12号到今天共研究八数码问题poj1077,首先用的是普通BFS,遇到很多问题,开始用一个二级指针作为结构成员,知道了二级指针与二维数值名的不同!http://write.blog.csdn.net/ ...
- 【Java源码】树-概述
树的基本术语 结点(node)由数据元素以及指向子树的地址构成. 若 X 结点有子树,则子树的根结点称为 X 的孩子(child)结点,相应地, X 称为其孩子的双亲(parents)结点,又称父母结 ...
- java 并发基础,及案例分析
对于我们开发的网站,如果网站的访问量非常大的话,那么我们就需要考虑相关的并发访问问题了,然而并发问题是令我们大多数程序员头疼的问题,但话又说回来了,既然逃避不掉,那我们就坦然面对吧~今天就让我们深入研 ...
- 细说分布式Redis架构设计和踩过的那些坑
细说分布式Redis架构设计和踩过的那些坑_redis 分布式_ redis 分布式锁_分布式缓存redis 细说分布式Redis架构设计和踩过的那些坑
- ArcEngine影像图配准
转自原文ArcEngine影像图配准 影像图配准主要包括以下几个方面 1.打开影像图 2.配准 3.影像图入库/保存 1.打开影像图的代码以前已经写过了. 2.配准 配准 主要使用IGeoRefe ...
- POJ 1679 The Unique MST 推断最小生成树是否唯一
The Unique MST Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 22715 Accepted: 8055 D ...
- kill mediaserver脚本
#!/bin/bash adb shell kill $(adb shell ps | grep mediaserver | awk '{print $2}') adb shell pm clear ...
- Web开发从零单排之一:在新浪云平台SAE上开发一个html5电子喜帖
需求描述: 本人大婚将至,女朋友说“现在都流行在微信上发电子请帖了,你不是技(cheng)术(xu)宅(yuan)嘛,不会连这个都搞不定吧” 本人嘴上说这等小事何足挂齿,但心里还是七上八下的,虽然自认 ...
- Javascript 运行机制
先看一下下面这段js代码: console.log('1'); setTimeout(function(){ console.log('2'); },0); console.log('3'); 请问打 ...