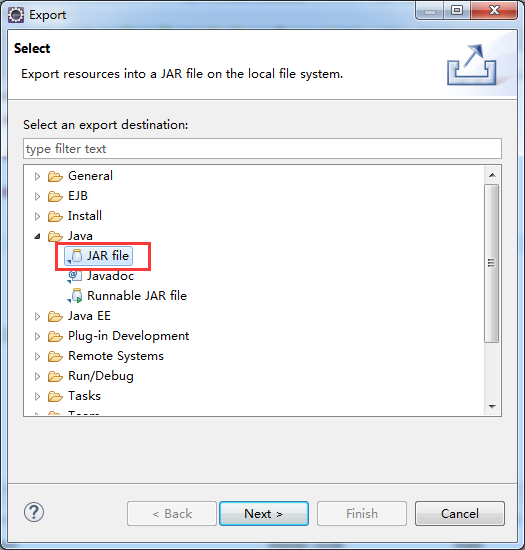
Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)
Hive可以通过实现用户定义函数(User-Defined Functions,UDF)进行扩展(事实上,大多数Hive功能都是通过扩展UDF实现的)。想要开发UDF程序,需要继承org.apache.hadoop.ql.exec.UDF类,并重载evaluate方法。Hive API提供@Description声明,使用声明可以在代码中添加UDF的具体信息。在Hive中可以使用DESCRIBE语句来展现这些信息。
Hive的源码本身就是编写UDF最好的参考资料。在Hive源代码中很容易就能找到与需求功能相似的UDF实现,只需要复制过来,并加以适当的修改就可以满足需求。
下面是一个具体的UDF例子,该例子的功能是将字符串全部转化为小写字母
package com.madhu.udf;
import org.apache.hadoop.hive.ql.exec.Desription;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
//add jar samplecode.jar;
//create temporary function to_upper as 'com.madhu.udf.UpercaseUDF';
@Desription(
name="to_upper",
value="_FUNC_(str) -Converts a string to uppercase",
extended="Example:\n" +
" > select to_upper(producer) from videos_ex;\n" +
" JOHN MCTIERNAN"
)
public class UpercaseUDF extends UDF{
public Text evaluate(Text input){
Text result = new Text("");
if (input != null){
result.set(input.toString().toUpperCase());
}
return result;
}
}
UDF只有加入到Hive系统路径,并且使用唯一的函数名注册后才能在Hive中使用。UDF应该被打成JAR包。
上传打好的 samplecode.jar,然后如下
下面的语句可以把JAR条件放入Hive系统路径,并注册相关函数:
hive > add jar samplecode.jar 这个目录,根据自己的情况而定
Added samplecode.jar to class path
Added resource:samplecode.jar
hive> create temporary function to_upper as 'com.madhu.udf.UppercaseUDF';
现在可以在Hive中使用这个函数了:
hive > describe function to_upper;
OK
to_upper(str) -Converts a string to uppercase
Time taken:0.039 seconds,Fetched:1 row(s)
hive > describe function extended to_upper;
OK
to_upper(str) - Converts a string to uppercase
Example:
> select to_upper(producer) from videos_ex;
JOHN MCTIERNAN
Time taken:0.07 seconds,Fetched:4 row(s)
手动的话,见
3 hql语法及自定义函数 + hive的java api
自动的话,见
Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)

这里,我自己写了一个hiveEvaluateUDF 自定义函数,实现某一个我们自己想要的功能。比如,我这里是转换功能。开始编写代码
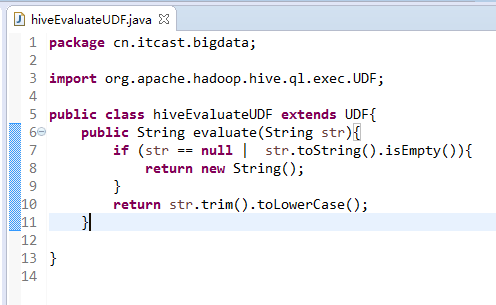
package cn.itcast.bigdata;
import org.apache.hadoop.hive.ql.exec.UDF;
public class hiveEvaluateUDF extends UDF{
public String evaluate(String str){
if (str == null | str.toString().isEmpty()){
return new String();
}
return str.trim().toLowerCase();
}
}
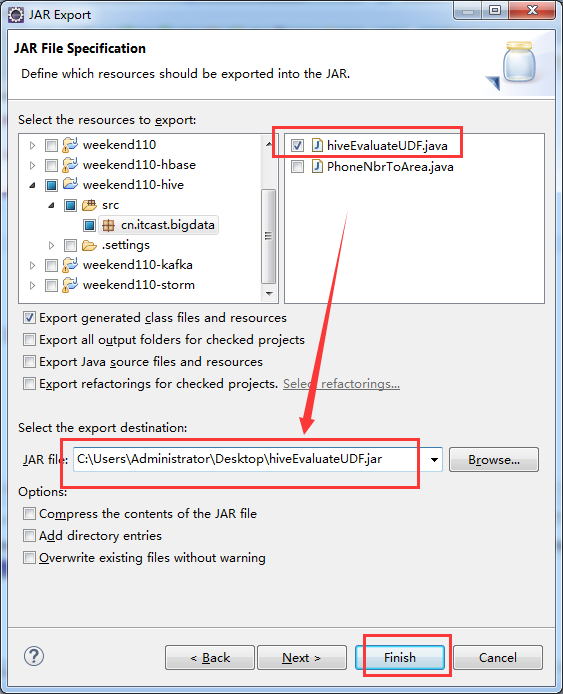


hive> add jar hiveEvaluateUDF.jar;

得到 cn.itcast.bigdata.hiveEvaluateUDF
hive> create temporary function to_lower as 'cn.itcast.bigdata.hiveEvaluateUDF';
剩下的,自行去尝试。
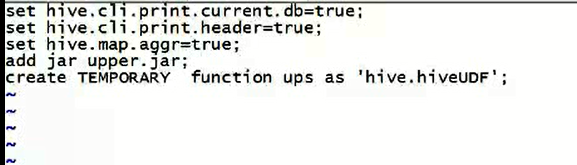
如何用好自己写好的自定义UDF函数
方法一:
比如,我这里,有个转大写的自定义UDF函数,自己写个vi hiveupperrc文件。每次执行这个文件,这个自定义的转大写函数能用了。
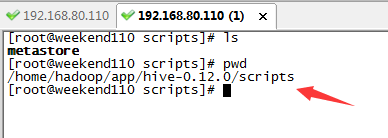
方法二:
在$HIVE_HOME/scripts目录下,写个如 hiveupperrc.sh脚本。
Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)的更多相关文章
- Hadoop HBase概念学习系列之HBase里的列式数据库(十七)
列式数据库,从数据存储方式上有别于行式数据库,所有数据按列存取. 行式数据库在做一些列分析时,必须将所有列的信息全部读取出来 而列式数据库由于其是按列存取,因此只需在特定列做I/O即可完成查询与分析, ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hadoop Hive概念学习系列之hive里的HiveQL——查询语言(十五)
Hive的操作与传统关系型数据库SQL操作十分类似. Hive主要支持以下几类操作: DDL 1.DDL:数据定义语句,包括CREATE.ALTER.SHOW.DESCRIBE.DROP等. 详细点, ...
- Hadoop Hive概念学习系列之hive里如何显示当前数据库及传参(十九)
这个小知识点,看似简单,用处极大. $ hive --hiveconf hive.cli.print.current.db=true $ hive --hiveconf hive.cli.print. ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
- Hadoop Hive概念学习系列之hive里的分区(九)
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”. 分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助. 分 ...
- Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例 在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.在hive安装目录下的bin,使用下面命令进行开启: hive -service hives ...
随机推荐
- 3.2.2.5 BRE运算符优先级
在数学表达式里,正则表达式的运算符具有某种已定义的优先级,指的是某个运算符(优先级较高)将比其他运算符先被处理. BRE运算符优先级,由高至低 运算符 表示含义 [..] [= ...
- 【Codeforces 464A】No to Palindromes!
[链接] 我是链接,点我呀:) [题意] 题意 [题解] 因为原序列没有任何长度超过2的回文串. 所以,我们在改变的时候,只要时刻保证改变位置s[i]和s[i-1]以及s[i-2]都不相同就好. 因为 ...
- 【Codeforces 986B】Petr and Permutations
[链接] 我是链接,点我呀:) [题意] 题意 [题解] n为奇数时3n和7n+1奇偶性不同 n为偶数时也是如此 然后交换任意一对数 逆序对的对数的奇偶性会发生改变一次 求出逆序对 对n讨论得出答案. ...
- PhantomJS & headless browser & pdf
PhantomJS http://phantomjs.org/ https://github.com/Medium/phantomjs https://github.com/Medium/phanto ...
- HDU 1325 拓扑排序
根据题目所给的3个不符合情况的条件,一个个判断图是否符合这3个条件即可 1.不能出现内部环,拓扑排序判断 2.不能有超过1个点的入度为0,因为只有一个树根 3.每个点最多一个入度 这里要注意的一点是这 ...
- noip模拟赛 猜数字
题目描述 LYK在玩猜数字游戏. 总共有n个互不相同的正整数,LYK每次猜一段区间的最小值.形如[li,ri]这段区间的数字的最小值一定等于xi. 我们总能构造出一种方案使得LYK满意.直到…… LY ...
- jd-eclipse插件的安装
一,资源 jd-eclipse-site-1.0.0-RC2.zip 百度网盘链接:https://pan.baidu.com/s/1GTFFY_1jg4k9vjZNE4JliQ 提 ...
- Portal嵌入SAPUI5应用程序
Embedding SAPUI5 Applications You can embed SAPUI5 applications directly into the SAP Fiori launchpa ...
- Pivotal-tc-Server与Tomcat区别
Pivotal-tc-Server之前叫做SpringSource tc Server,包含三个版本分别是:Spring版.标准版和开发版,但其中只有开发版是免费的.比如在STS中包含的版本就是开发板 ...
- vue2源码浏览分析01
1.构造函数 Vue$3 function Vue$3 (options) { if ("development" !== 'production' && !(t ...