python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块
第四章 :常用模块(第二部分)
一、os 模块的 详解
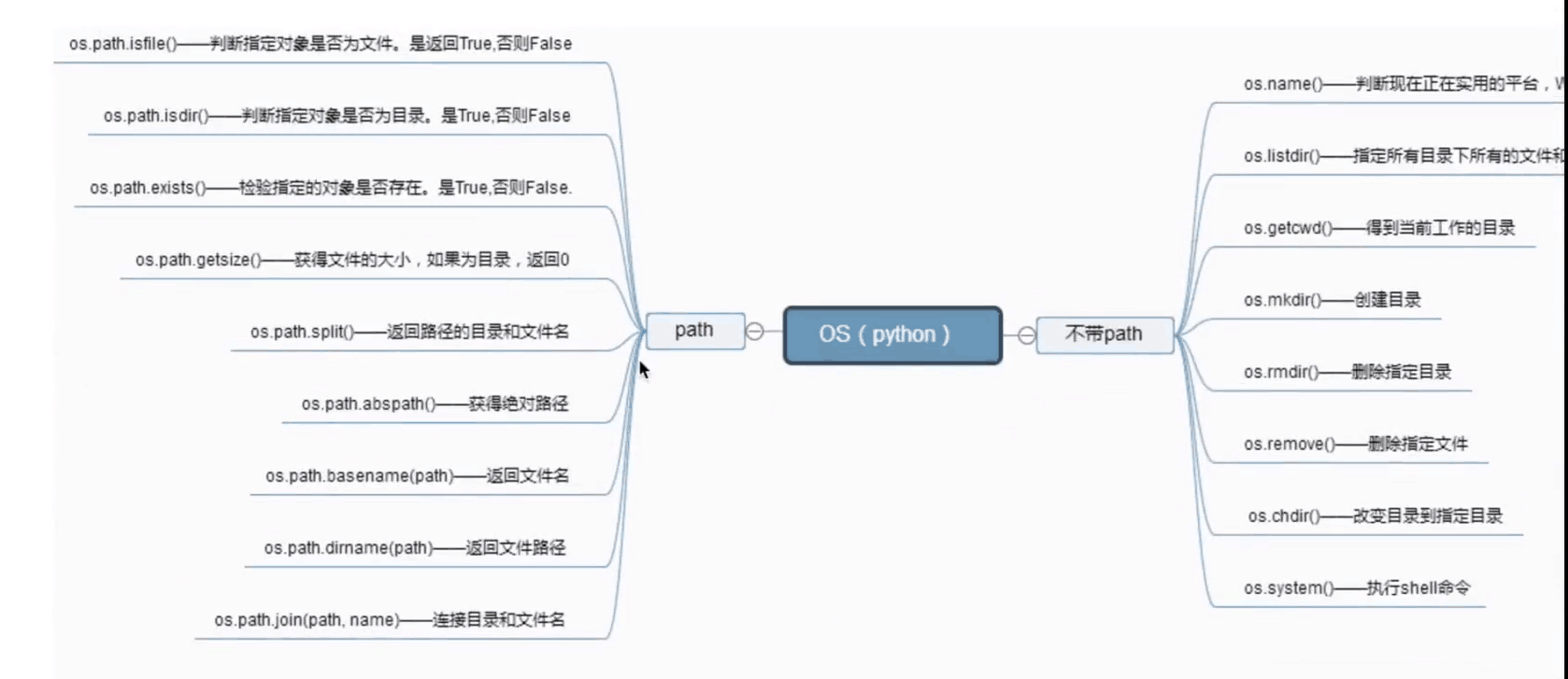
1、os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径
import os
j = os.getcwd() # 返回当前python所在路径,在哪里执行python,返回哪里目录
print(j)
C:\Users\57098\PycharmProjects\untitled\python学习第二模块\第四章\常用模块
import os # 导入os 模块
os.getcwd() # 返回当前 python 所在文件路径(在哪里执行python,返回哪里)
os.listdir(".") # 返回指定目录下的所有文件和目录名("."代表当前目录)
os.remove() # 删除指定文件(括号内填写文件地址)
os.removedirs(r"%s"%**) # 删除多个文件,需要读取文件的路径
os.path.isfile("文件") # 判断是否为一个文件,返回(True/False)
os.path.isdir("目录") # 判断是否为一个目录,返回(True/False)
os.path.isabs("绝对路径") # 判断是否为绝对路径,返回(True/False)
os.path.exists("检验内存") # 检验路径是否为真,返回(True/False)
os.path.split("文件名和目录名") # 返回路径的文件名和目录名并分开
os.path.splitext("分离扩展") # 返回路径的文件名和文件,并分离后缀
os.path.dirname("路径名") # 获取路径名
os.path.abspath("绝对路径") # 获取绝对路径
os.path.basename("文件名") # 获取文件名
os.system("模拟电脑系统") # 运行电脑自带系统命令(模拟电脑系统,执行正确返回 0 执行错误返回其他)
os.getenv("HOME") # 读取操作系统环境变量 HOME 的值
os.environ # 打印当前系统的所有变量(不加括号)
os.environ.setdefault("hello", "/home/guoyilong") # 设置临时系统变量,仅程序运行时有效(交互器退出,自动删除)
os.linesep # 返回当前平台使用的换行符( windows 返回 "\n""\r" , Linux 和 Mac 返回 "\n")
os.name # 返回当前系统操作平台(返回通用接口协议代号 windows 为 "nt"而 linux 和 unix 则返回"posix")
os.rename("旧文件名", "新文件名") # 文件重命名(如果新文件名已存在,或许会报错)
os.makedirs(r"c:\d\c\b\a") # 创建多级文件(递归式的创建文件)如果一级目录不存在,会挨个创建到所有路径实现
os.mkdir("创建单个目录") # 创建单个目录
os.stat("python3.txt") # 执行一个文件(需输入目录下的文件全称(包括后缀))
os.stat_result
st_mode=33206, # 文件权限
st_ino=9851624184895828, # 节点号
st_dev=2557137489, # 接口(存到硬盘上的地址类)(驻留的设备)
st_nlink=1, # 连接数
st_uid=0,# 用户 ID
st_gid=0, # 群组ID
st_size=1425,# 文件大小 (常用的就是能拿到文件大小)
st_atime=1547046564, # 最后访问时间戳
st_mtime=1547046564,# 最后修改时间戳
st_ctime=1543572800,# 最后修改权限时间戳
os.chmod("文件") # 修改文件权限与时间戳
os._exit("文件") # 终止参数内文件的进程
os.path.getsize("文件名") # 获取文件大小
os.path.join("目录名", "文件名") # 结合目录名和文件名(只要是真实的文件名和目录名就会返回)
os.fchdir("要改变的目录地址") # 改变文件目录到指定路径
jk = os.get_terminal_size() # 获取当前终端大小(在python解释器执行)
os.terminal_size(columns=133,lines=44)
# columns=133 每行能写133个字符 lines=44 可写44行(视解释器窗口而定,可自己决定窗口的大小)
os.kill("进程号", "需导入 signal 模块", "执行命令") # 杀死或终止当前进程,需要和 signal (信号处理模块)配合使用
总结:有点多,不好记。需要分类,python 的 os 模块主要分为 2 大类,
一个是带 .path ,一个是不带
二、sys 模块的详解
import sys # 导入模块
sys.argv # 打印程序的当前路径
sys.exit("bye-bye") # 退出程序并打印参数,不再执行其他
sys.version # 打印当前解释器版本
sys.maxsize # 打印 int 最大数值
sys.path # 打印解释器的环境变量(模块的初始路径)
sys.platform # 打印操作系统平台版本
k6 = sys.stdout # 标准输出
<_io.TextIOWrapper name='<stdout>' mode='w' encoding='UTF-8'>
# io 代表文件读写操作, 后面的代表操作输入文件格式
k = sys.getrecursionlimit() # 获取最大递归层数
sys.getrecursionlimit(1200) # 设置最大递归层数
sys.getdefaultencoding() # 获取解释器默认编码
sys.getfilesystemencoding() # 获取内存数据存到文件里

三、shutil 模块详解(做文件处理,压缩解压常用到的模块)
注意:
- 以下几个模块注意编码的转换,
pycharm 所用的编码默认 utf-8 ,
windows 系统默认编码为 unicode 或者 GBK,
在文件处理方面要提前转好统一代码才能实现互通无阻
1、shutil 模块详解
* shutil.copyfileobj拷贝文件(通过文件读写)
import shutil # 创建模块的文件名不能和导入的标准库的模块同名,否则会报错
f1 = open("模块语法.py", "r", encoding="utf-8")
f2 = open("module__copy.py", "w", encoding="utf-8")
shutil.copyfileobj(f1, f2) # 读写方式创建新文件
* shutil.copyfile拷贝文件(通过文件名称)
f3 = "模块语法.py"
f4 = "语法复制.py"
shutil.copyfile(f3, f4) # 直接拷贝文件不用读写
* 其他 shutil 的应用
shutil.copymode() # 仅拷贝权限(内容、组和用名都不变)
shutil.copystat() # 拷贝状态信息包括(mode(权限), bits, atime, fiage)
shutil.copy() # 拷贝文件和权限
shutil.copy2() # 拷贝文件和状态信息
* shutil 模块的组合使用
递归拷贝文件(在同目录下,拷贝多级目录的大文件)(拷贝目录用得到)
f5 = shutil.ignore_patterns("__init__.py", "kk") # 忽略拷贝目录内的文件名需在参数内填写
shutil.copytree("包的解析与应用", "常用模块副本", symlinks=False, ignore=f5)
# 以上两个组合使用(注意括号内参数软链接、和忽略拷贝的对象)
* shutil.rmtree 递归删除文件或路径内文件
shutil.rmtree(path="%s"%"常用模块副本",) # 递归删除文件路径内全部文件并忽略报错信息
* shutil.move 移动或创建
shutil.move("常用模块副本", "astr") # 需同级目录下进行,如果移动到的文件名不存在,会重新创建(就像剪切一样)
****重点**** 压缩包的创建
#重点** 创建压缩包并返回文件路径
shutil.make_archive(base_name,format,.....)
# base_name : 压缩包的文件名,也可以是文件路径。只是文件时,则保存至当前目录,否则保存指定路径
# 如: staff:保存当前路径, /User/57098/Dskfmmn/ ; 则保存至此路径下
# format :压缩包类型,("zip", "tar", "bztar", "gztar")
# root_dir : 要压缩的文件路径(默认当前目录)
# owner :用户(默认当前用户)
# group :组(默认当前组)
# logger : 用于记录日志,通常是logging.Logger对象
shutil.make_archive("fffff", "zip", root_dir="包的解析与应用") # 压缩包只能压缩普通文件,不支持多级目录的文件夹压缩
#("fffff" 和 root_dir="包的解析与应用",可更换不的同路径地址)
#没有路径格式默认打包当前目录下的文件存到当前目录下,如果不把压缩包放在同一目录,需指定目录
#shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行处理的
2、zipfile (压缩打包)模块详解
# # 压缩文件
import zipfile
f6 = zipfile.ZipFile("f1f2.zip", "w", ) # 先创建压缩包的名称和读写方式
f6.write("语法复制.py") # 写入的文件
f6.write("astr") # 写入的文件夹
f6.write("包的解析与应用")
f6.close() # 关闭文件
# # 解压文件
f7 = zipfile.ZipFile("f1f2.zip", "r") # 解压压缩包
f7.extractall() # 内置解压包语法
f7.close()
3、tarfile (只打包)模块解析
f8 = tarfile.open("f3f4.zip", "w") # 创建打包名称和读写方式
f8.add("包的解析与应用", arcname="包")
# 要打包的路径或同目录下的文件名(Windows系统,注意编码的转换),arcname=为打包后为包重新命名
f8.add("压缩解压专用")
f8.close() # 此方法会打包文件夹下所有内容
注意:
- tayfile和 zipfile 模块的区别;
- zipfile 打包多级文件夹时,只能打包目录下的空文件夹,
- 而 tarfile 则是打包文件夹内的所有目录及内容
四、序列化模块(json、pickle 和 shelve)
1、json 模块详解
(1)、只在内存执行
import json
date = {
"状态": {
"英雄": ["德玛", "亚索", "蔚"],
"怪": ["大龙", "小龙", "蓝Buf", "红Buf"]
}}
# 转换成系统识别的字符
g = json.dumps(date) # 把内容转成字符串(电脑识别的格式)unicode或者其他格式
print(g, type(date)) # 已转成字符
# 系统识别字符转换成正常格式
g2 = json.loads(g) # 转成相应的数据类型,和上一个语法是相应的
print(g2)
(2)转换字符串并存进文件
fd = open("date.json", "w", encoding="utf-8") # 注意命名规范(json 序列化化转变文件一般都会有 .json 的后缀)便于识别文件
g5 = json.dump(date, fd) # 转换成 unicode 编码格式(或者其他编码格式)并存进指定文件
# 自动识别把文件内容转换相应格式
fs = open("date.json", "r", encoding="utf-8") # 注意读写模式
g6 = json.load(fs) # 转换成相应格式
(3) 把数据类型转成字符串存在内存的意义( json.dumps json.loads )
(1、把内存的数据,通过网络,共享给其他人
(2、跨平台,跨语言,定义了不同语言沟通之前的交互规则和方法
*纯文本文件,缺点是:不能共享复杂的数据类型
**xml 文件, 缺点; 占用空间大
*** json 处理 , 简单,可读性好,是所有语言共同的交互平台,也是最常用方法、
注意:dump 和 load 不支持同一文件夹多次执行,都属于一次性的,执行多次会带来很多麻烦
2、pickle 模块详解
pickle 和 json 的方法基本相同
import pickle
h = {"alex": "will", "will": 1233} # 在内存执行
h3 = pickle.dumps(h) # 会转成存进硬盘的bytes类型(二进制格式) # 存文件执行
ph = open("will", "wb") # 注意读写类型,由于存的是二进制编码,必须是 wb 或者 rb 模式
pickle.dump(h, ph) # 存进自己能识别的数据(可能看的时候是乱码),
自己能识别并能转回
ph2 = open("will", "rb") # 打开文件(rb格式)
ph3 = pickle.load(ph2, encoding="utf-8") # 可定义转成为什么格式的字
3、shelve 模块的详解
* shelve 操作转换类型,通常以字典形式存储和读取,还可写多行转换(就像json 内的 dump 可执行多行)
import shelve
f = shelve.open("shelve_file") # shelve模式打开文件
s = {"hello": "will", "alex": 25} # 创建2个类型
sa = ["hello my name is will", "i'm is age 27", 13555555555]
f["info"] = s
f["info_age"] = sa # 直接调用f,并以字典形式创建 value 并对应赋值
f.close() # 关闭文件
f = shelve.open("shelve_file")
sc = list(f.keys()) # 字典形式读取文件内的数据(不抓换字典吗,打印的是一个内存地址)
sd = list(f.values()) # 返回字典内的 value 值
se = f.get("info_age") # 查看字典内 info 对应值
** 不但可以获取还可以删除、创建 和修改文件内容
f = shelve.open("shelve_file") # 打开文件
del f["info"] # 删除文件
f["info"] = [1, 4, 5, 2, "asdd", 5, 8, 55] # 重新创建(也可视为重新修改,但是不能修改局部,只能修改整体)
f.close()
f = shelve.open("shelve_file")
se = f.get("info")
***总结:json 和 pickle 的区别
1、json优点:可以跨平台、跨语言实现互通
缺点:转换类型是有限的 (只支持 字符串str、数字int、列表list、字典dict、元祖tuple)
不能支持太复杂的数据结构
2、pickle 优点: 支持 python 内所有数据类型(转成二进制格式,再按照所需转成指定编码)
缺点:只局限于 python ,不可跨平台、夸语言 五、xml 模块详解
- xml 模块为不同语言或程序之间进行数据交互的协议,
- json 出来之前的老模块,适用于老互联网模式比如金融行业
- 现已很少用,( 大部分都在用 json 类的标准化模块 )金融累还有部分在应用
- 下面以操作 xml 文件为例学习
- xml 是类似于网络前段的形式存储文件的,在很多语言都有支持
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year attr_test="yes" update="yes">2039</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year attr_test="yes" update="yes">2042</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year attr_test="yes" update="yes">2042</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
<state>
<name>德国</name>
<population>首尔</population>
</state>
</data>
* xml是通过 <>来标记区别数据结构的,xml 模块在各种语言里都是支持的,在python中可以导入以下模块来进行操作
import xml.etree.ElementTree as ET
(一)1、先查看下它的对应功能
char = ET.parse("xml test") # 和 open()打开文件一个道理
pych = char.getroot() # 找到根目录地址相当于用处理文件内的f.seek(0)
print(dir(pych )) # 查看对应功能
print(pych.tag) # 返回 xml 入口标签
2、遍历文件
# 遍历循环 xml 文档
for srr in pych:
print("------")
print(srr.tag, srr.attrib) # 依次取标签内节点的值(srr = county 的标签值)
for y in srr:
print(y.tag, y.text) # 取出每一个 county 内的子标签的值 # 也可只遍历子节点中的某一个节点
for f in pych.iter("gdppc"): # 你要找什么,就把对应的名字填上
print(f.tag, f.text) # 打印对应名字和对应值
3、xml 文件的修改
# xml 文件的修改
char = ET.parse("xml test")
pych = char.getroot() # 拿到节点起始的数据(seek(0)) # 把每个年份都加10
for v in pych.iter("year"):
new = int(v.text) + 10 # 把属性内的值转回数字并相加
v.text = str(new) # 所有的文件都是字符串,所以还要再转回字符串
v.set("update", "yes") # 可自行添加一些特殊标注(字符串形式)
char.write("xml test") # 写进原文件(修改成功)
4、xml 部分删除
# 删除部分信息
for country in pych.findall("country"): # 用到 findall
rank = int(country.find("rank").text) # 拿到值 转回数字
if rank > 50:
pych.remove(country) # 删除对应值 char.write("xml del test") # 写进新文件(删除成功)
(二) 创建 xml 文件
xml_info = ET.Element("name_dict") # 创建根目录节点
1、创建第一个节点
name = ET.SubElement(xml_info, "name", attrib={"enrolled": "yes"}) # 创建第一个节点
age = ET.SubElement(name, "age", attrib={"chord": "no"}) # 创建节点属性
sex = ET.SubElement(age, "sex") # 在目录下创建属性
name_ = ET.SubElement(name, "name")
name_.text = "will Guo"
sex.text = "male" # 赋值操作
2、创建第二个节点
name_two = ET.SubElement(xml_info, "name_two", attrib={"enrolled": "not"}) # 创建第二个节点
age = ET.SubElement(name_two, "age")
age.text = ""
3、生成文件对象
et = ET.ElementTree(xml_info) # 生成文件对象
et.write("text.xml", encoding="utf-8", xml_declaration=True)
# 写进文件命名为“text.xml”, 编码格式为 utf-8 , 版本号为默认True
总结:
xml 文件操作,相对其他操作方法,会麻烦很多,不建议用,但是老程序的文件也要会操作 六、configParser 模块( 主要应用于配置文档的操作 )
- 在 pycharm 内,到相应目录下创建一个普通文件, 以 .ini 结尾都会自动识别为配置文件
- 配置文件内,一般分为三部分,可以根据配置软件的不同,设置相应配置
import configparser conf = configparser.ConfigParser() # 定义打开格式并赋值
t = conf.read("appr.ini") # 得到执行方法(执行文件)
ta = conf.sections() # 执行得到配置文件内的后两段配置编码名,
配置文件第一段为默认配置(不写也会有)
tb = conf.default_section # 拿到默认配置码的名(第一段)
1、拿到配置文件内的对应值(操作方法与字典内取值相似)
tc = dir(conf["bitbucket.org"]) # 查看有多少可执行的方法(和字典的参数和操作有点相同)
td = list(conf["bitbucket.org"].keys()) # 执行取出所有 keys (和字典相同)拿到的是一个内存地址,需转成列表方可看
te = conf["bitbucket.org"]["user"] # 得到参数内的 key ,和字典一样找出对应对的值
2、循环节点下所有的值并作出判断
for tf, tv in conf["bitbucket.org"].items(): # 填写的 第二段编码的值却取出目录节点下所有值
# 在原文件内修改第二段编码,发现也会 一起打印所有值,
# 是因为不管操作哪个群文件[DEFAULT] 是一个默认值,即便不调用,也会出现在操作的文件中
# 同样如果在每一个节点段落内,都要有相同的参数在内,可以把他写进第一个节点段落内,这样每次执行 都会出现
3、判断条件在不在文件内
# 判断条件在不在文件内
if "sdf" in conf["bitbucket.org"]:
print("info")
else:
print("def")
4、配置文件的增删改查
# 配置文件的增删改查
conf = configparser.ConfigParser()
conf.read("add.ini") print(dir(conf)) # 查看语法 fk = conf.options("date1") # 会拿到对应节点下的所有 key
fm = conf["date1"]["key2"] # 拿到对应 key 的值(和字典操作相同)
5、增加文件配置
# 增加一个配置
conf.add_section("date3") # 创建新的节点
conf["date3"]["name"] = "will" # 创建节点内容
conf["date3"]["age"] = ""
conf.write(open("add.ini", "r+")) # 写入创建的节点 conf.set("date2", "name", "will") # 也可在节点内新增内容
conf.write(open("add.ini", "w")) # 写入新增值
6、删除文件内的节点或节点内容
# 删除节点或内容
conf.remove_section("date3") # 删除节点和节点内全部内容
conf.write(open("add.ini", "w")) conf.remove_option("date3", "") # 可以选择删除节点内的某一项和对应值
conf.write(open("add.ini", "w"))
七、 hashlib(加密处理)模块详解
hashlib 加密模块和之前学的 hash 函数有一些关系,还包括 MD5 的算法结合
(一)、hash 的函数,就是把普通的字符串、数字、列表 等一系列正常字符通过内部转换,
生成一串不可反解(也称不可逆)的数字进行 基础加密,也就是找到一种数据类型和内存地址有关的映射关系
(二)、MD5 加密算法,是一种被广泛应用的密码杂凑函数, 可以生成一个 128 位的散列值,用于确保信息传输的完整一致,
MD5 的前身:MD2、MD3、MD4。
1、MD5 的功能:
输入任意长度信息都会返回128位的信息(数字指纹 ),每一次 输入都不会有相同的返回值。
2、MD5 算法的特点:
①压缩性(输入的任意长度,输出的 MD5 值都是固定的长度)
②容易计算(从原数据计算出 MD5 很容易)
③抗修改性(对原数据进行任何改动,ND5 的值都不会一致,哪怕只是一个字符)
④强抗碰撞(即使得知原数据和 MD5 的值,也不会再次生成相同的值(即伪造数据)
3、MD5 算法 是否可逆(反解):MD5 算法不可逆,即唯一值,因为是其中一种散列函数,
使用了 hash 算法,计算中只抽取部分数据
网络上的破解算法是通过撞库来查找数据库得出相应的值
(提前把简单的数值对应加密算法得出的结果存进数据库以供查询)
4、MD5 用途:
① 防止被篡改(发送邮件前后对照 MD5 生成值,下载文件前公布 MD5 供下载后对照是否相同)
SVN 在检测文件是否在 CheckOut 被篡改过,也会用到MD5
② 防止直接看到明文(很多登录系统,都是通过 MD5 加密存储的用户数据,就算得到用户数据,也不能使用)
只有用户自己登陆,将字符转换后与数据库对比正确了,才能登录。这样就保证了用户数据的安全性)
③ 防止抵赖(就像数字签名:经过第三方认证之后,就会防止抵赖不承认)
(三)MD5 算法的生成(语法必须在python交互器执行)
# MD5 算法的生成
# 必须在 python 交互器进行
>>> import hashlib # 导入 hashlib 模块
>>> m = hashlib.md5() # 调用 MD5 并赋值
>>> m.update(b"will") # 以二进制格式输入要加密的字符串(b"****")
>>> m.hexdigest() # 调用生成算法
'18218139eec55d83cf82679934e5cd75' # 加密生成
八、subprocess模块(此模块需注意:Windows、Unix 和 Mac 不一样的系统执行命令)
官方推出subprocess模块是为了提供统一的模块来实现对系统命令或脚本的调用。
三种执行命令的方法
- subprocess.run()
- subprocess.call()
- subprocess.Popen()
1、run()方法
subprocess.run(['df', '-h'], stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True)
stdout标准输出,stdin标准输入,stderr标准错误
subprocess.PIPE是把结果存到管道里进行缓存
涉及管道符的命令需写 subprocess.run("df -h|grep disk1",shell=True) shell 意思是交给系统执行命令
此处需要用到windows 的 cmd 系统命令
有关某个命令的详细信息,请键入 HELP 命令名
ASSOC 显示或修改文件扩展名关联。
ATTRIB 显示或更改文件属性。
BREAK 设置或清除扩展式 CTRL+C 检查。
BCDEDIT 设置启动数据库中的属性以控制启动加载。
CACLS 显示或修改文件的访问控制列表(ACL)。
CALL 从另一个批处理程序调用这一个。
CD 显示当前目录的名称或将其更改。
CHCP 显示或设置活动代码页数。
CHDIR 显示当前目录的名称或将其更改。
CHKDSK 检查磁盘并显示状态报告。
CHKNTFS 显示或修改启动时间磁盘检查。
CLS 清除屏幕。
CMD 打开另一个 Windows 命令解释程序窗口。
COLOR 设置默认控制台前景和背景颜色。
COMP 比较两个或两套文件的内容。
COMPACT 显示或更改 NTFS 分区上文件的压缩。
CONVERT 将 FAT 卷转换成 NTFS。你不能转换
当前驱动器。
COPY 将至少一个文件复制到另一个位置。
DATE 显示或设置日期。
DEL 删除至少一个文件。
DIR 显示一个目录中的文件和子目录。
DISKPART 显示或配置磁盘分区属性。
DOSKEY 编辑命令行、撤回 Windows 命令并
创建宏。
DRIVERQUERY 显示当前设备驱动程序状态和属性。
ECHO 显示消息,或将命令回显打开或关闭。
ENDLOCAL 结束批文件中环境更改的本地化。
ERASE 删除一个或多个文件。
EXIT 退出 CMD.EXE 程序(命令解释程序)。
FC 比较两个文件或两个文件集并显示
它们之间的不同。
FIND 在一个或多个文件中搜索一个文本字符串。
FINDSTR 在多个文件中搜索字符串。
FOR 为一组文件中的每个文件运行一个指定的命令。
FORMAT 格式化磁盘,以便用于 Windows。
FSUTIL 显示或配置文件系统属性。
FTYPE 显示或修改在文件扩展名关联中使用的文件
类型。
GOTO 将 Windows 命令解释程序定向到批处理程序
中某个带标签的行。
GPRESULT 显示计算机或用户的组策略信息。
GRAFTABL 使 Windows 在图形模式下显示扩展
字符集。
HELP 提供 Windows 命令的帮助信息。
ICACLS 显示、修改、备份或还原文件和
目录的 ACL。
IF 在批处理程序中执行有条件的处理操作。
LABEL 创建、更改或删除磁盘的卷标。
MD 创建一个目录。
MKDIR 创建一个目录。
MKLINK 创建符号链接和硬链接
MODE 配置系统设备。
MORE 逐屏显示输出。
MOVE 将一个或多个文件从一个目录移动到另一个
目录。
OPENFILES 显示远程用户为了文件共享而打开的文件。
PATH 为可执行文件显示或设置搜索路径。
PAUSE 暂停批处理文件的处理并显示消息。
POPD 还原通过 PUSHD 保存的当前目录的上一个
值。
PRINT 打印一个文本文件。
PROMPT 更改 Windows 命令提示。
PUSHD 保存当前目录,然后对其进行更改。
RD 删除目录。
RECOVER 从损坏的或有缺陷的磁盘中恢复可读信息。
REM 记录批处理文件或 CONFIG.SYS 中的注释(批注)。
REN 重命名文件。
RENAME 重命名文件。
REPLACE 替换文件。
RMDIR 删除目录。
ROBOCOPY 复制文件和目录树的高级实用工具
SET 显示、设置或删除 Windows 环境变量。
SETLOCAL 开始本地化批处理文件中的环境更改。
SC 显示或配置服务(后台进程)。
SCHTASKS 安排在一台计算机上运行命令和程序。
SHIFT 调整批处理文件中可替换参数的位置。
SHUTDOWN 允许通过本地或远程方式正确关闭计算机。
SORT 对输入排序。
START 启动单独的窗口以运行指定的程序或命令。
SUBST 将路径与驱动器号关联。
SYSTEMINFO 显示计算机的特定属性和配置。
TASKLIST 显示包括服务在内的所有当前运行的任务。
TASKKILL 中止或停止正在运行的进程或应用程序。
TIME 显示或设置系统时间。
TITLE 设置 CMD.EXE 会话的窗口标题。
TREE 以图形方式显示驱动程序或路径的目录
结构。
TYPE 显示文本文件的内容。
VER 显示 Windows 的版本。
VERIFY 告诉 Windows 是否进行验证,以确保文件
正确写入磁盘。
VOL 显示磁盘卷标和序列号。
XCOPY 复制文件和目录树。
WMIC 在交互式命令 shell 中显示 WMI 信息。 有关工具的详细信息,请参阅联机帮助中的命令行参考。
2、call()方法
a = subprocess.call(['df', '-h'])
执行命令,返回命令执行状态,(0 或 非0)
subprocess.check_call(['ls', '-l'])
如果命令结果为0,就返回,否则抛出异常
subprocess.getstatusoutput('ls /bin/ls')
接收字符串格式命令,返回元组形式,第一个元素为执行状态,第二个元素为命令结果(0,'/bin/ls')
subprocess.getoutput('ls /bin/ls')
接收字符串格式命令,返回结果
a = subprocess.check_output(['ls', '-l'])
执行命令并返回结果,需要有接收返回值的变量
3、Popen()方法
(以上2个方法都是通过本方法封装而成,也就是说上面2个方法的底层代码都是通过本方法实现的)
常用参数:
args: shell命令,可以是字符串或者序列类型(如:list,元组)
stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
preexec_fn: 只在 Unix平台下有效,用于指定一个可执行对象(callable object),
它将在子进程运行之前被调用
shell:同上
cwd:用于设置子进程的当前目录
env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
a = subprocess.run('sleep 10', shell=True, stdout=subprocess.PIPE)
a = subprocess.Popen('sleep 10', shell=True, stdout=subprocess.PIPE)
注意:windows encoding='gbk' linux/mac 默认uft-8
print(a.stdout.read())输出结果
run方法 在主程序执行
Popen方法 发起一个新的子进程,不影响主程序
pid 获取所启动的进程的进程号
poll() 检测子进程是否终止,返回代码
wait() 等待发起的进程结束
terminate() 终止所启动的进程
kill() 杀死所启动的进程
communicate() 和启动的进程交互,通过stdin发送数据,通过stdout接收输出数据 只能交互一次
f = subprocess.Popen("dir", shell=True,stdout=subprocess.PIPE) # 执行 cmd 命令
print(f.pid) # 拿到执行进程的编号
f = f.stdout.read() # 得到执行结果
# (由于用 windows 系统默认编码为 GBK 所以需要把当前执行所用的 utf-8 转为 GBK)
f = f.decode(encoding="GBK") # 转换成 windows 系统的默认编码
print(f) # 正常显示
f.terminate(8896) # 杀掉执行的进程
九、logging日志模块(编写日志)
在开发中,记录日志,是一个必不可少的过程,包含内容广泛,有正常访问程序的日志,还有错误、警告等信息输出,
提供了标准的日志接口,可以储各种格式日志,其中包括:
日志由上到下,级别由低到高,(debug级别最低,critical级别最高)
- debug() # 调试模式(开发时调试需用)
- info() # 普通的记录(错误除外)
- warning() # 即将发生的错误或者潜在的问题
- error() # 出问题,报错,错误
- critical() # 严重问题,影响正常运行或即将瘫痪
(一)logging 基础语语法和应用
logging.warning("user Will attrs wrong module python3 is not yes") # 基础语法
logging.critical("hello bye_bye") # 更高等级
1、写入日志的语法
创建日志文件时,level=日志级别过滤条件(如果是 DEBUG 则所有的都会写进去,如果更高级别,则低级别的会被忽略写入)
logging.basicConfig(filename="logging.log", # 创建日志文件
level=logging.DEBUG, # 指定写入级别
format='%(asctime)s:' # 指定写入时间(固定格式)
'%(levelname)s:' # 输出日记级别
'%(filename)s:' # 输出输出模块的文件名
'%(funcName)s:' # 输出其在的函数名
'%(lineno)d:' # 输出其所在文件的行列
'%(relativeCreated)d:' # 输出创建以来的毫秒
'%(process)d:' # 输出进程编号
'%(message)s', # 用户输出的消息
datefmt="%Y-%m-%d %I:%M:%S %p") # 指定写入时间格式(注意大小写)
def haha(): # 写入一个函数
logging.error("hello my name's will") haha() logging.debug("hello my name is will , i'm age 22")
logging.info("is ides not logging for file")
logging.warning("error is windows10 not python3") # 写入日志文件
**可以写入时间格式,还可以增加很多方法格式
%(name)s # logger的名字
%(levelno)s # 数字形式的日志级别,会根据输入的语法级别用(10--60)表示最低和最高级别的日志
%(levelname)s # 文本形式的日志级别,会把写入的日志级别的名字,同步写进日志
%(pathname)s # 调用日志输出函数的模块和完整路径名(把执行时所在目录和生成的日志全部写入**不常用)
%(filename)s # 调用日志输出函数模块的文件名
%(module)s # 调用日志输出函数的模块名
%(funcName)s # 调用日志输出函数的函数名(日志中表明其所在的函数名)
%(lineno)d # 调用日志输出函数语句所在的代码行列(注意后缀字符)(输出其所在文件内的多少行)
%(created)f # 当前时间(用 Unix 标准的表示时间的浮点数表示)(注意后缀字符)
%(relativeCreated)d # 输出日志信息时,自logger 创建以来的毫秒数 (调试时会有用)
%(asctime)s # 字符串形式的当前时间,默认格式“年-月-日 时:分:秒(精确到微秒)
%(thread)d # 线程 ID (可能没有)
%(threadName)s # 线程名称(可能没有)
%(process)d # 进程 ID (执行程序的进程号)(可能没有)(调试会用到)
%(message)s # 用户输出的消息
(二)logging 模块进阶(同时输出到屏幕和文件) python使用的 logging 模块日志涉及 4 个主要类:
- logger 提供了应用程序可直接使用的接口
- handler将(logger创建的)日志发送到合适的位置输出
- filter提供了输出日志记录的过滤,细化设置决定输出哪条日志记录
- formatter 决定了日志记录的最终输出格式
1、logger 的的使用:每个程序在输出信息之前都要获得一个 logger。logger通常对应程序的模块名
(如:聊天工具的图形界面)模块可以以此获得他的logger
log = logging.getLogger("chat.gui")
而核心模块可以这样
LOG = logging.getLogger("chat.kernel")
还可以绑定 handler 和 filters
logging.Logger.setLevel(lel) # 指定最低的日志级别,低于lel级别的将被忽略 debug 为最低级别,critical为最高级别
logging.Logger.addFilter(filter=) # 添加指定的 filter
logging.Logger.removeFilter(filter=) # 删除指定的 filter
logging.Logger.addHandler(hdlr=) # 添加指定的 handler
logging.Logger.removeHandler(hdlr=) # 删除指定的 handler
可以指定的日志级别
logging.Logger.debug() # 最低级
logging.Logger.info()
logging.Logger.warning()
logging.Logger.error()
logging.Logger.critical() # 最高级
2、handler 的使用:handler对象负责发送信至指定位置,python 的日志系统有多个 handler 函数可用,
可以输送到控制台,也可输出信息至文件内,还可以把信息发送网络上,如果有其他要求,更可以自己编写 handler
还可通过 addHandler()方法添加多个 handler 进行操作
也可设置级别
logging.Handler.setLevel(lel) # 指定被处理信息级别,低于指定级别的将被忽略
logging.Handler.setFormatter() # 指定 handler 的输出对象和输出格式
logging.Handler.addFilter(filter()) # 新增 filter 对象
logging.Handler.removeFilter(filter=) # 删除 filter 对象
# 每一个 logger 都可以附加多个 Handler
3、常用 handler 的方法需导入模块(logging.handlers)
3.1、logging.StreamHandler :
使用这个 handler 可向类似于 sys.stdouut 、sys.stderr 的任何文件对象( fileobject )输出信息
3.2、logging.FileHandler :
和上一个(logging.StreamHandlerS)类似,用于向一个文件输出日志信息。不过本语法会自动打开文件
3.3、logging.handlers.RotatingFileHandler :
这个语法类似(logging.FileHandler)的作用,区别在于本方法可以管理文件大小,当文件达到一定容量,
将当前文件改名,自动创建新的同名文件继续输出,(比如当前文件为:handler.log , 如果此文件容量不足,
本方法会将装满内容的文件命名为 handler.log.1 或 继续增加,然后重新再创建一个 handler.log 的文件写入)(末尾数字越大代表文件越早)
它的函数是: logging.handlers.RotatingFileHandler(filename=[, mode[, maxBytes[, backupCount]]])
其中 filename 和 mode 两个参数和 FileHandler 一样,
import logging
from logging import handlers # 日志文件自动截取(注意需要导入logging的子模块 handlers)
logger = logging.getLogger("web") # 生成 logger 对象,设置并创建日志文件 # 2、生成 handler 对象,按大小自动截取文件
fh = logging.handlers.RotatingFileHandler(filename="web.log", mode="S", maxBytes=50, backupCount=3)
# ① maxBytes :用于指定文件的容量,如果此参数为 0 ,则表示文件可以无限大,也不会创建新文件
# ② backupCount :用于指定保留备份文件的数量,如:指定文件为 2 则表示重命名创建文件过程中,
# 只能存在 2 个文件(handler.log.1 和 handler.log)其余文件会被清理删除 logger.addHandler(fh)
fc = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s')
fh.setFormatter(fc)
logger.debug("最低级别")
logger.info("中低级别")
logger.error("中级")
logger.warning("中高级")
logger.critical("最高级别") # 写入日志内容,不设置日志级别,默认级别为 warning
3.4、logging.handlers.TimedRotatingFileHandler :
import logging
from logging import handlers # 日志文件自动截取(注意需要导入logging的子模块 handlers)
logger = logging.getLogger("web") # 生成 logger 对象,设置并创建日志文件
# 2、生成 handler 对象,按时间自动截取文件
# 这个和上一个类似,不同之处是:它不是通过文件大小判断是否创建新文件,而是间隔一定时间,自动创建新的文件
# 它的函数是:logging.handlers.TimedRotatingFileHandler(filename=[, when[, interval[, backupCount]]])
# 其中,filename 参数和 backupCount 和 RotatingFileHandler 具有相同的意义
ch = logging.handlers.TimedRotatingFileHandler("web.log", when="s", interval=4, backupCount=3)
# ① interval :是设定间隔时间(大部分都只是个数值)
# ② when= :是一个字符串,表示时间的间隔单位,不区分大小写。
# 取值范围 【S:秒 M:分 H:时 D:天 W:周( interval==0 时,代表周一 ),midnight为每天凌晨】
logger.addHandler(ch)
fd = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s')
ch.setFormatter(fd
logger.debug("最低级别")
logger.info("中低级别")
logger.error("中级")
logger.warning("中高级")
logger.critical("最高级别") # 写入日志内容,不设置日志级别,则默认级别为 warning
4、formatter 组件:日志的 formatter 是一个独立的组件,可以配合 handler 使用
# -*- coding:utf-8 -*-
import logging
# 1、生成 logger 对象
logger = logging.getLogger("web") # 设置并创建日志文件
logger.setLevel(logging.INFO) # 设置全局最高权限日志级别(不设置默认级别为 warning )
logger.setLevel(logging.DEBUG) # 如果把全局的等级设置最低,则相当于下放权限给子级别权限设置 # 2、生成 handler 对象
ch = logging.StreamHandler() # 生成屏幕输出
ch.setLevel(logging.DEBUG) # 为屏幕输出时,设置局部级别(子级别权限,会受到最高权限的影响)
fh = logging.FileHandler("web.log") # 生成文件输出
fh.setLevel(logging.WARNING) # 为生成文件输出时,设置输出局部级别(子级别权限,会受到最高权限的影响) # 2.1、把 handler 对象绑定到 logger
logger.addHandler(ch)
logger.addHandler(fh) # 3.生成 formatter 对象
fc = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s')
fd = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s') # 3.1、把 formatter 对象绑定到 handler 对象
ch.setFormatter(fd)
fh.setFormatter(fc) logger.debug("最低级别") # 写入日志内容
logger.info("中低级别")
logger.error("中级")
logger.warning("中高级")
logger.critical("最高级别") # 不设置日志级别,默认级别为 warning
5、filter组件:如果要过滤日志内容,可以自定义一个 filter
# -*- coding:utf-8 -*-
import logging class IgnoreBackupLogFilter(logging.Filter): # 创建类
"""忽略带db backup的日志"""
def filter(self, record): # 固定写法( filter 过滤语法用的少 )
return "db backup" not in record.getMessage() # 如果"db backup"不在获取的日志行列,
# 注意:filter 会执行后返回 True 或 False ,logger 会根据此值决定是否输出日志 # 1、生成 logger 对象
logger = logging.getLogger("web") # 设置并创建日志文件
logger.setLevel(logging.INFO) # 设置全局最高权限日志级别(不设置默认级别为 warning )
logger.setLevel(logging.DEBUG) # 如果把全局的等级设置最低,则相当于下放权限给子级别权限设置 # 1.1、把 filter 添加到 logger 中
logger.addFilter(IgnoreBackupLogFilter()) # 就会把符合条件的过滤掉 # 2、生成 handler 对象
ch = logging.StreamHandler() # 生成屏幕输出
# ch.setLevel(logging.DEBUG) # 为屏幕输出时,设置局部级别(子级别权限,会受到最高权限的影响) fh = logging.FileHandler("web.log") # 生成文件输出
# fh.setLevel(logging.WARNING) # 为生成文件输出时,设置输出局部级别(子级别权限,会受到最高权限的影响) # 2.1、把 handler 对象绑定到 logger
logger.addHandler(ch)
logger.addHandler(fh) # 3.生成 formatter 对象
fc = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s')
fd = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(lineno)d-%(message)s') # 3.1、把 formatter 对象绑定到 handler 对象
ch.setFormatter(fd)
fh.setFormatter(fc) logger.debug("最低级别") # 写入日志内容
logger.info("中低级别")
logger.error("中级,db backup")
logger.warning("中高级")
logger.critical("最高级别") # 不设置日志级别,默认级别为 warning
python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)的更多相关文章
- python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记 第三章:员工信息增删改查作业代码 作业要求: 员工增删改查表用代码实现一个简单的员工信息增删改查表需求: 1.支持模糊查询,(1.find name ,age fo ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
- python全栈开发中级班全程笔记(第二模块)第 二 部分:函数基础(重点)
python学习笔记第二模块 第二部分 : 函数(重点) 一.函数的作用.定义 以及语法 1.函数的作用 2.函数的语法和定义 函数:来源于数学,但是在编程中,函数这个概念 ...
- python全栈开发中级班全程笔记(第二模块)第一部分:文件处理
第二模块 第一部分:文件处理与函数 #插曲之人丑就要多读书:读书能够提高个人素质与内涵,提升个人修养与能力,以及层次的提升. 推荐书籍:追风筝的人.白鹿原 电影:阿甘正传.辛德勒的名单 第一节:三 ...
- python全栈开发,Day43(引子,协程介绍,Greenlet模块,Gevent模块,Gevent之同步与异步)
昨日内容回顾 I/O模型,面试会问道 I/O操作,不占用CPU,它内部有一个专门的处理I/O模块 print和写log属于I/O操作,它不占用CPU 线程 GIL保证一个进程中的多个线程在同一时刻只有 ...
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- 老男孩最新Python全栈开发视频教程(92天全)重点内容梳理笔记 看完就是全栈开发工程师
为什么要写这个系列博客呢? 说来讽刺,91年生人的我,同龄人大多有一份事业,或者有一个家庭了.而我,念了次985大学,年少轻狂,在大学期间迷信创业,觉得大学里的许多课程如同吃翔一样学了几乎一辈子都用不 ...
- 自学Python全栈开发第一次笔记
我已经跟着视频自学好几天Python全栈开发了,今天决定听老师的,开始写blog,听说大神都回来写blog来记录自己的成长. 我特别认真的跟着这个视频来学习,(他们开课前的保证书,我也写 ...
随机推荐
- 学习RenderScript,以此来修改LiveWallpaper
先留个坑,花5天的时间来填满.
- Python 进程(一)理论部分
进程 进程(Process)是计算机中的程序关于某数据集合上的一次运行,即正在运行的程序,是系统进行资源分配和调度的基本单位,进程是对正在运行程序的一个抽象,在早期面向进程设计的计算机结构中,进程是程 ...
- python3 re模块正则匹配字符串中的时间信息
匹配时间: # -*- coding:utf-8 -*- import re def parseDate(l): patternForTime = r'(\d{4}[\D]\d{1,2}[\D]\d{ ...
- Microsoft Store应用安装路径和应用推荐——如何用Linux命令操控windows
本人是cnblog萌新,刚学编程不久的菜鸟,这是我的第一篇博客,请各位轻喷 Microsoft store安装路径: 相信很多人都跟我一样有强迫症,文件找不到安装目录就不舒服.一开始在系统盘找不到Wi ...
- robotframework上的字体放大和缩小是ctr++和ctl--
- Swagger 报错 no mapping found for http request with uri [/***/swagger-ui.html] in dispatcherservlet with name '***'
swagger报错: no mapping found for http request with uri [/***/swagger-ui.html] in dispatcherservlet wi ...
- Java 常见数据交换格式——xml、json、yaml
目录 数据交换格式介绍 XML 使用DOM方式解析 使用SAX方式解析 使用DOM4J方式解析 使用JDOM方式解析 JSON 使用JSONObject方式将数据转换为JSON格式 利用JSONObj ...
- ansible copy 模块详解
ansible 模块 copy one.概述 copy 模块的作用就是拷贝文件,它与之前介绍过的 fetch 模块类似,不过,fetch 模块是从远程主机中拉取文件到 ansible 管理主机,而 c ...
- 如何实现Echart不刷新页面,多语言切换下的地图数据重新加载,api请求数据加载,soketed数据实时加载
可视化项目中经常用到ecahrt,各种异步加载,连接socket,多语言切换等问题,现在汇总一下: Ecahrt初始化,全局统一init,可以初始化为0,等待后续数据操作 1.如果是api重新请求,数 ...
- Supervisor安装与使用
一.简介 1.supervisor是什么 superviosr是一个Linux/Unix系统上进程监控和管理的工具,它由python编写,可以用pip安装.supervisor能将一个普通的命令行进程 ...