聚类--K均值算法
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def initcenter(x,k): #初始聚类中心数组
return x[0:k].reshape(k) def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc-i))
w = np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值进行分类,shape[0]读取矩阵第一维度的长度
y[i] = nearest(kc,x[i])
return y def kcmean(x,y,kc,k): #计算各聚类新均值
l = list(kc)
flag = False
for c in range(k):
print(c)
m = np.where(y == c)
n=np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生变化
print(l,flag)
return (np.array(l),flag) k = 3
kc = initcenter(x,k) flag = True
print(x,y,kc,flag) #判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2
while flag:
y = xclassify(x,y,kc)
kc, flag = kcmean(x,y,kc,k)
print(y,kc,type(kc)) print(x,y)
import matplotlib.pyplot as plt
plt.scatter(x,x,c=y,s=50,cmap="rainbow");
plt.show()

x=np.random.randint(1,100,[20,1]) y=np.zeros(20) k=3 def initcenter(x,k): return x[:k] def nearest(kc,i): d = (abs(kc - i)) w = np.where(d ==np.min(d)) return w [0] [0] kc = initcenter(x,k) nearest(kc,14)

for i in range(x.shape[0]):
print(nearest(kc,x[i]))
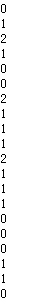
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
print(y)
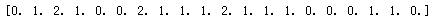
for i in range(x.shape[0]):
y[i]=nearest(kc,x[i])
print(y)
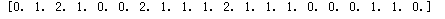
def initcenter(x,k):
return x[:k] def nearest(kc, i):
d = (abs(kc - 1))
w= np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y kc = initcenter(x,k)
nearest(kc,93)
m = np.where(y == 0)
np.mean(x[m])
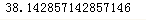
kc[0]=24
flag = True
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def nearest(kc,i): #初始聚类中心数组
return x[0:k] def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc - i))
w = np.where(d == np.min(d))
return w[0][0] def kcmean(x, y, kc, k): #计算各聚类新均值
l =list(kc)
flag = False
for c in range(k):
m = np.where(y == c)
if m[0].shape != (0,):
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生改变
return (np.array(1),flag) def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值分类
y[i] = nearest(kc,x[i])
return y k = 3
kc = initcenter(x,k) falg = True
print(x, y, kc, flag)
while flag:
y = xclassify(x, y, kc)
xc, flag = kcmean(x, y, kc, k) print(y,kc)
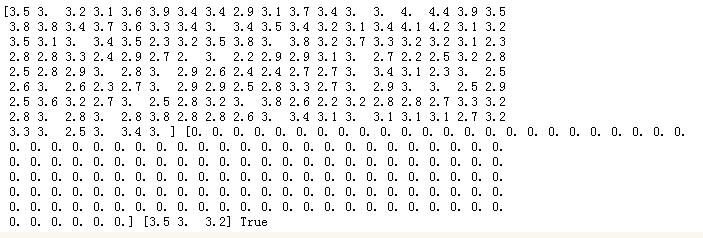
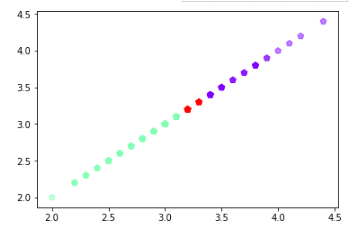
import matplotlib.pyplot as plt
plt.scatter(x, x, c=y, s=50, cmap='rainbow',marker='p',alpha=0.5);
plt.show()
from sklearn.cluster import KMeans
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
data = load_iris()
iris = data.data
petal_len = iris
print(petal_len)
k_means = KMeans(n_clusters=3) #三个聚类中心
result = k_means.fit(petal_len) #Kmeans自动分类
kc = result.cluster_centers_ #自动分类后的聚类中心
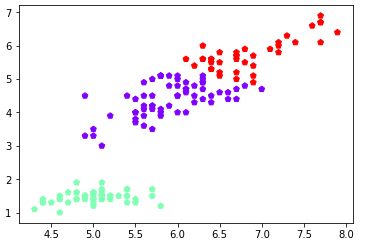
y_means = k_means.predict(petal_len) #预测Y值
plt.scatter(petal_len[:,0],petal_len[:,2],c=y_means, marker='p',cmap='rainbow')
plt.show()
聚类--K均值算法的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
随机推荐
- vector某元素是否存在、查找指定元素 、去重
vector.map 判断某元素是否存在.查找指定元素 [C++]判断元素是否在vector中,对vector去重,两个vector求交集.并集 PS:注意重载
- MemoryCache
https://docs.microsoft.com/en-us/dotnet/api/system.runtime.caching.memorycache?view=netframework-4.8 ...
- Office 2016 自定义安装
Office2016已经不提供自定义安装功能,而采用C2R安装方式.使用镜像安装时,默认全部安装.想要自定义安装就需要用到微软提供的Office2016部署工具. 步骤 下载并运行微软提供的Offic ...
- spring事务的7种传播行为
https://blog.csdn.net/weixin_39625809/article/details/80707695 一般用于并发,分布式锁.复杂业务情况
- 记 Swagger 2
Maven坐标: <dependency> <groupId>io.springfox</groupId> <artifactId>springfox- ...
- UI组件--element-ui--Table组件自定义合计行
需求: Element-ui的Table组件自带合计行, 但是需求需要在合计行的某些单元格有特别的样式以及事件, 没有研究出怎么在既有合计行上完成此需求, 于是利用其原本的一些属性完成自定义合计行. ...
- 如何在开发过程中获取客户端的ip呢?
在开发工作中,我们常常需要获取客户端的IP.一般获取客户端的IP地址的方法是:request.getRemoteAddr();但是在通过了Apache,Squid等反向代理软件就不能获取到客户端的真实 ...
- JAVA-类方法与实例方法
1.实例方法:一个方法如果不加static关键字,那么这个方法是实例方法.意思是他属于类的某个实例,通过这个实例调用它,对类的其他实例不产生影响. 2.类方法:也称静态方法.在方法前加static关键 ...
- 雷林鹏分享:jQuery EasyUI 数据网格 - 创建复杂工具栏
jQuery EasyUI 数据网格 - 创建复杂工具栏 数据网格(datagrid)的工具栏(toolbar)可以包含按钮及其他组件. 您可以通个一个已存在的 DIV 标签来简单地定义工具栏布局,该 ...
- 一款好用的JS时间日期插件layDate
觉得这个插件很不错,使用起来也很方便,推荐使用 1.插件截图 2.插件配置 选择很多,配置也很简单,插件官网:https://www.layui.com/laydate/配置说得很明确,基本操作就是: ...