Kafka: Exactly-once Semantics
https://www.confluent.io/blog/enabling-exactly-kafka-streams/
https://cwiki.apache.org/confluence/display/KAFKA/KIP-98+-+Exactly+Once+Delivery+and+Transactional+Messaging
Exactly Once Delivery and Transactional Messaging in Kafka
https://docs.google.com/document/d/11Jqy_GjUGtdXJK94XGsEIK7CP1SnQGdp2eF0wSw9ra8/edit#
Overview
Kafka stream其实就是重用的samza,流pipeline上的所有节点都是解耦合的,所以所有节点的snapshot和恢复策略都是local的。
其实Global或local的checkpoint策略没有好坏之分,是全局还是局部,关键是在哪里replay数据
如果你只能在source去replay数据,那么就必须要采用global的snapshot,否则无法保证全局一致
但是如果我们可以在每个处理节点去replay数据,那就没有必要做global snapshot,
而kafka天然作为replay数据的基础设施,如果pipeline中的每个步骤都要kafka来串联,那么就可以简单通过local snapshot来保障一致性
这个就是当年samza做的,但是他只能保障at-least once,而不能保证exactly once
比如下面的场景,就会导致数据重复,
一种是topic B已经写成功,但是返回的ack丢了,或是process收到ack后,没来得及更新offset就crash了
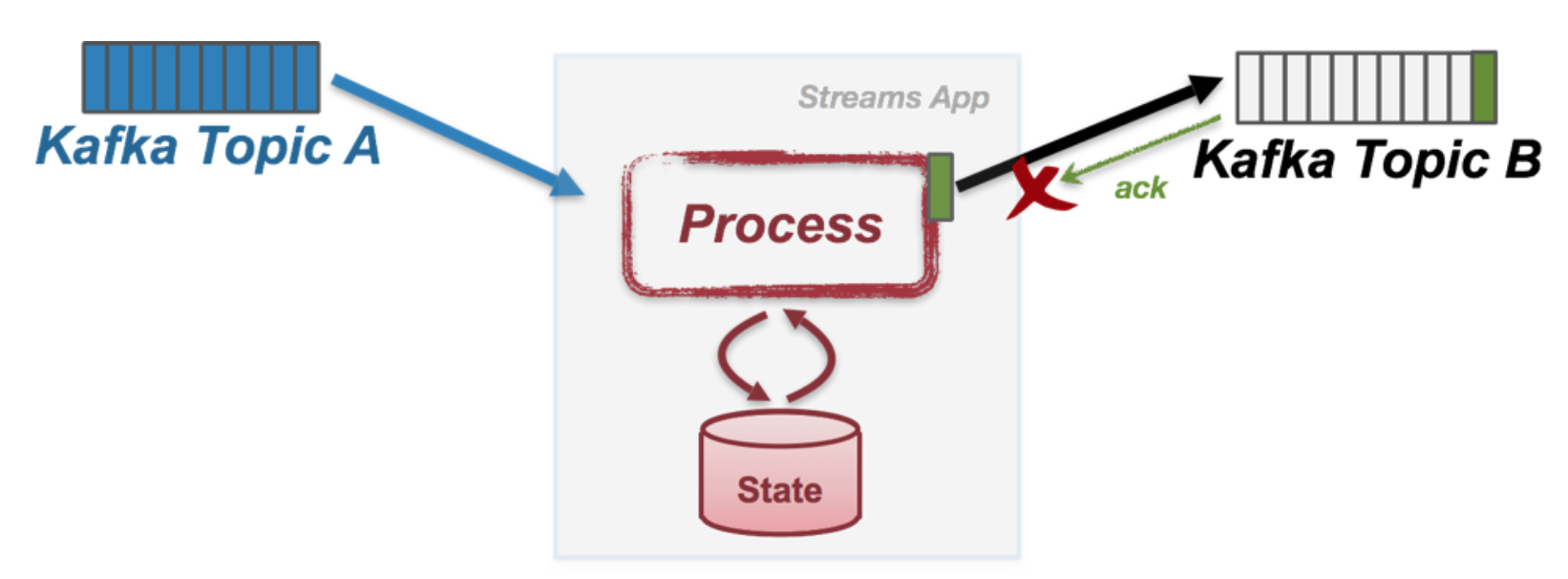
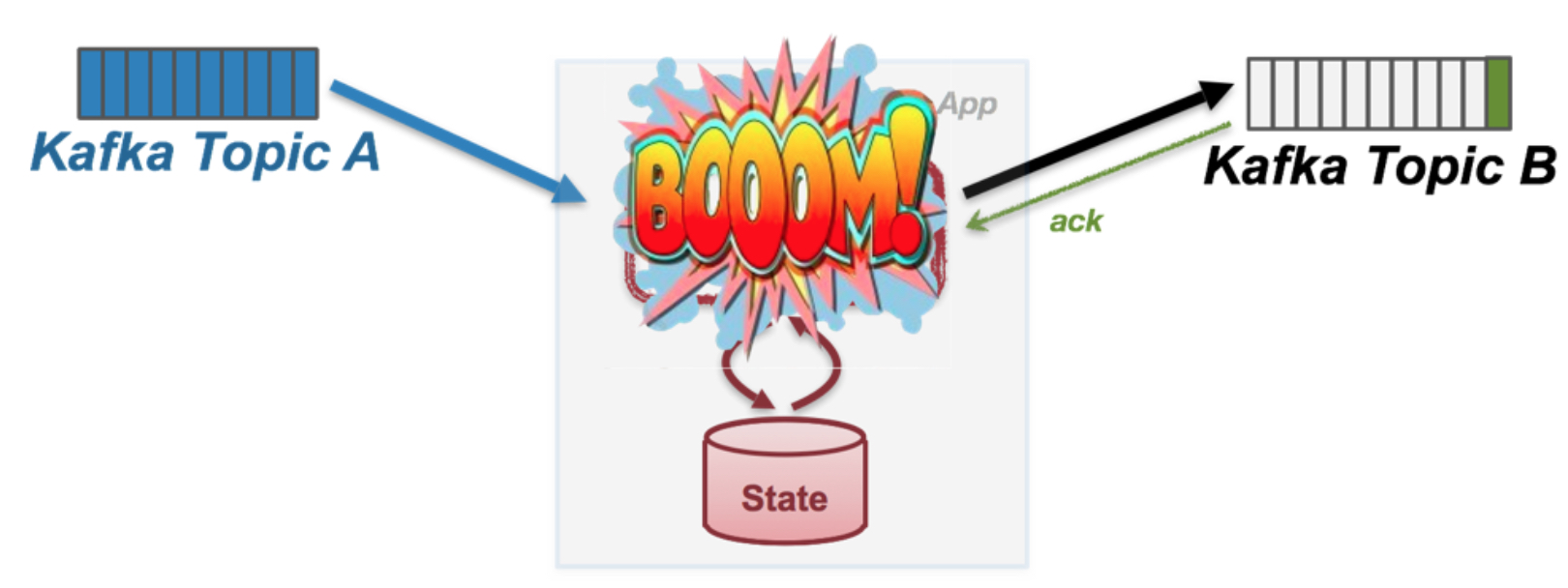
那么如何才能保证exactly once?
这里就要引入transaction的概念,transaction关键就是原子性,所以要保证下面的数据是被原子更新的

这里的state update关键是记录下change log,这个在samza就是这样的机制
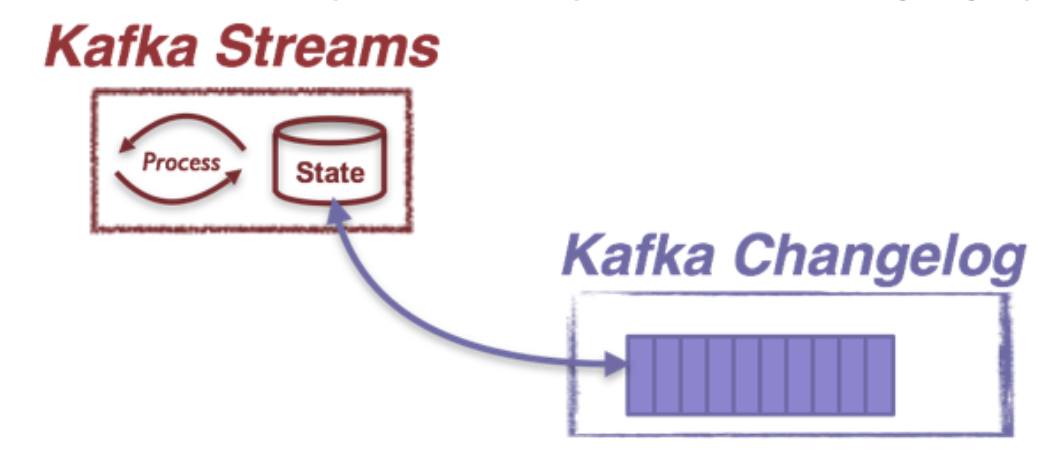
Second of all, in Kafka Streams state updates can also be translated as a sequence of change capture messages.
Here is why: in the Kafka Streams library, all state stores capture their updates by default into some special Kafka topics called the changelog topics.
Each store keeps its updates in a separate changelog topic: whenever an update is applied to that store, a new record capturing this update will be sent to the corresponding changelog topic. A state store’s changelog topic is highly available through replication and is treated as the source-of-truth of the state store’s update history. This topic can hence be used to bootstrap a replica of the state store in another processor upon load balancing, fault recovery, etc.
我们通过changelog可以恢复出state,所以state update可以看成是将update写入changelog topic
所以上面的transaction可以看成是,对多个topic的partition的原子写入

With the transactions API, we can enable producer clients to atomically send to multiple Kafka topic partitions. Messages written to multiple Kafka topics within the same transaction will be readable by consumers as a whole when the transaction is successfully committed, or none of them will not be readable at all if the transaction is aborted. By using this mechanism, Kafka Streams can ensure that records are sent to to the sink topics, the changelog topics, and the offset topics atomically.
并且这里在这个transaction成功前,下一级的consumer是无法看到任何这个transaction内的tuple的,这样保证数据只会被读一遍
为了完成去重,所有的message都会有唯一的标识,有如下数据组成,
PID => int64,代表来自哪个producer
Epoch => int16,防止旧的僵尸producer
Sequence number => int32,每个producer对于每个partititon都会维护seq,保证message在partition层面是按顺序处理
这样对于第一种fail的场景,topic B已经完成写入,但是返回的ack失败了
那么process会重新发送,但这个时候,topic B通过pid和seq就可以知道这个数据是dup的
对于第二种fail的场景会复杂一些,process挂了,那么就是更新offset失败了,那么就是整个transaction都失败了,这样coordinator会abort这个transaction
abort操作会将这个transaction所造成的影响都回滚掉,就是这部分数据会被标识为abort,即不可见
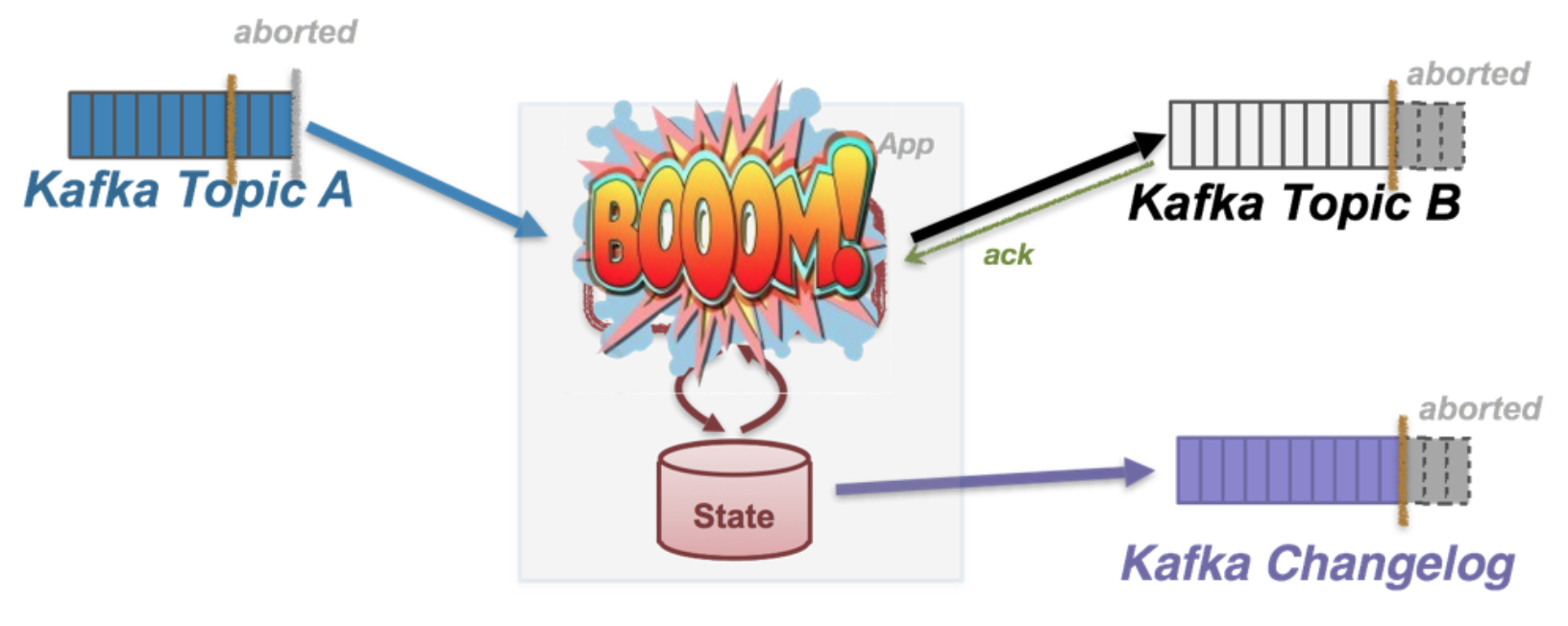
这样由于上次offset没有更新,继续上次replay数据,就能保证数据exactly once
Dataflow

1. 首先通过任意brokers找到transaction coordinator
2. Producer需要获取PID
producer是通过initPidRequest来获取PID,两种cases,
第一种用户没有配置producer的transaction id,那么这种情况,可以从任意broker获取随机的PID,没必要经过transaction coordinator;这样在这次session内这个producer可以做到exactly once语义,但是一旦挂掉,failover后就无法恢复,因为下次他获取的随机PID是和当前的PID对不上的
第二种用户配置了producer的transaction id,那么TransactionalId和transaction timeout都会通过InitPidRequest发送到transaction coordinator
coordinator会首先生成PID,并把TransactionalId和PID的对应关系写到transaction log,这样后面无论你producer怎么重启,相同的TransactionalId都会得到相同的PID
然后coordinator会把这个PID的epoch加一,以防止僵尸producer;
最后把这个PID所对应的所有未完成的transaction完成掉,rolls forward or rolls back
这里transaction log是用于transaction coordinator做HA恢复,新的coordinator可以replay transaction log来恢复所有transaction当前的状态
3. producer开始新的transaction
通过beginTransaction(),这里做的仅仅是producer在local标识新的transaction开始
4. 开始consume-transform-produce,真正的transaction过程,分成多个步骤,
4.1 当第一次往TopicPartition发送数据时,producer会发送AddPartitionsToTxnRequest到coordinator,coordinator会记录下这个partition到transaction log中,因为后面需往相应的partition中写入 commit or abort markers来标识transaction完成;并且当coordinator第一次收到AddPartitionsToTxnRequest,它才认为transaction开始,会启动一个transaction timer,用于transaction超时。
4.2 ProduceRequests,开始往partition去produce数据message,message带有PID, epoch, and sequence number,用于去重
4.3 Producer会调用sendOffsets API,发送AddOffsetsToTxnRequests到transaction coordinator,request中包含需要commit的offset和consume group id,coordinator会把这个信息记录到transaction log中
4.4 Producer在sendOffsets中,继续发送TxnOffsetCommitRequest 到consumer coordinator to persist the offsets in the __consumer_offsets topic。
5 完成transaction
通过调用producer的commitTransaction or abortTransaction methods,无论调用哪个都是往transaction coordinator发送EndTxnRequest,通过字段标识是commit还是abort
coordinator收到这个request后,做如下操作,
往transaction log写入 PREPARE_COMMIT or PREPARE_ABORT message
coordinator通过WriteTxnMarkerRequest往之前注册的所有partition里面写入COMMIT (or ABORT) markers
每个broker收到request后,会往相应的partition中写入 COMMIT(PID) or ABORT(PID) 控制消息,称为marker,以表示给定PID发来的数据是应该被deliver或drop;
Consumer会buffer某个PID发送过来的message,直到收到commit或abort,才判断将buffer的数据发送还是丢弃
这个过程对于__consumer_offsets也同样适用,这个内部topic也会写入commit或abort marker,最终consumer coordinator来判断是commit还是ignore这次offset更新往transaction log写入 COMMITTED (or ABORTED) message
1. Finding a transaction coordinator -- the FindCoordinatorRequest
Since the transaction coordinator is at the center assigning PIDs and managing transactions,the first thing a producer has to do is issue a FindCoordinatorRequest (previously known as GroupCoordinatorRequest, but renamed for general usage) to any broker to discover the location of its coordinator. Note that if no TransactionalId is specified in the configuration, this step can be skipped.
2. Getting a producer Id -- the InitPidRequest
The producer must send an InitPidRequest to get idempotent delivery or to use transactions. Which semantics are allowed depends on whether or not the transactional.id configuration is provided or not.
2.1 When a TransactionalId is specified
After discovering the location of its coordinator, the next step is to retrieve the producer’s PID. This is achieved by sending an InitPidRequest to the transaction coordinator.
The TransactionalId is passed in the InitPidRequest along with the transaction timeout, and the mapping to the corresponding PID is logged in the transaction log in step 2a. This enables us to return the same PID for the TransactionalId to future instances of the producer, and hence enables recovering or aborting previously incomplete transactions.
In addition to returning the PID, the InitPidRequest performs the following tasks:
Bumps up the epoch of the PID, so that any previous zombie instance of the producer is fenced off and cannot move forward with its transaction.
Recovers (rolls forward or rolls back) any transaction left incomplete by the previous instance of the producer.
The handling of the InitPidRequest is synchronous. Once it returns, the producer can send data and start new transactions.
2.2 When a TransactionalId is not specified
If no TransactionalId is specified in the configuration, the InitPidRequest can be sent to any broker. A fresh PID is assigned, and the producer only enjoys idempotent semantics and transactional semantics within a single session.
3. Starting a Transaction -- the beginTransaction API
The new KafkaProducer will have a beginTransaction() method which has to be called to signal the start of a new transaction. The producer records local state indicating that the transaction has begun, but the transaction won’t begin from the coordinator’s perspective until the first record is sent.
4. The consume-transform-produce loop
In this stage, the producer begins to consume-transform-produce the messages that comprise the transaction. This is a long phase and is potentially comprised of multiple requests.
4.1 AddPartitionsToTxnRequest
The producer sends this request to the transaction coordinator the first time a new TopicPartition is written to as part of a transaction. The addition of this TopicPartition to the transaction is logged by the coordinator in step 4.1a. We need this information so that we can write the commit or abort markers to each TopicPartition (see section 5.2 for details). If this is the first partition added to the transaction, the coordinator will also start the transaction timer.
4.2 ProduceRequest
The producer writes a bunch of messages to the user’s TopicPartitions through one or more ProduceRequests (fired from the send method of the producer). These requests include the PID, epoch, and sequence number as denoted in 4.2a.
4.3 AddOffsetsToTxnRequest
The producer has a new sendOffsets API method, which enables the batching of consumed and produced messages. This method takes a map of the offsets to commit and a groupId argument, which corresponds to the name of the associated consumer group.
The sendOffsets method sends an AddOffsetsToTxnRequests with the groupId to the transaction coordinator, from which it can deduce the TopicPartition for this consumer group in the internal __consumer_offsets topic. The transaction coordinator logs the addition of this topic partition to the transaction log in step 4.3a.
4.4 TxnOffsetCommitRequest
Also as part of sendOffsets, the producer will send a TxnOffsetCommitRequest to the consumer coordinator to persist the offsets in the __consumer_offsets topic (step 4.4a). The consumer coordinator validates that the producer is allowed to make this request (and is not a zombie) by using the PID and producer epoch which are sent as part of this request.
The consumed offsets are not visible externally until the transaction is committed, the process for which we will discuss now.
5. Committing or Aborting a Transaction
Once the data has been written, the user must call the new commitTransaction or abortTransaction methods of the KafkaProducer. These methods will begin the process of committing or aborting the transaction respectively.
5.1 EndTxnRequest
When a producer is finished with a transaction, the newly introduced KafkaProducer.commitTranaction or KafkaProducer.abortTransaction must be called. The former makes the data produced in step 4 above available to downstream consumers. The latter effectively erases the produced data from the log: it will never be accessible to the user (at the READ_COMMITTED isolation level), ie. downstream consumers will read and discard the aborted messages.
Regardless of which producer method is called, the producer issues an EndTxnRequest to the transaction coordinator, with a field indicating whether the transaction is to be committed or aborted. Upon receiving this request, the coordinator:
Writes a PREPARE_COMMIT or PREPARE_ABORT message to the transaction log. (step 5.1a)
Begins the process of writing the command messages known as COMMIT (or ABORT) markers to the user logs through the WriteTxnMarkerRequest. (see section 5.2 below).
Finally writes the COMMITTED (or ABORTED) message to transaction log. (see 5.3 below).
5.2 WriteTxnMarkerRequest
This request is issued by the transaction coordinator to the the leader of each TopicPartition which is part of the transaction. Upon receiving this request, each broker will write a COMMIT(PID) or ABORT(PID) control message to the log. (step 5.2a)
This message indicates to consumers whether messages with the given PID should be delivered or dropped. As such, the consumer will buffer messages which have a PID until it reads a corresponding COMMIT or ABORT message, at which point it will deliver or drop the messages respectively.
Note that, if the __consumer_offsets topic is one of the TopicPartitions in the transaction, the commit (or abort) marker is also written to the log, and the consumer coordinator is notified that it needs to materialize these offsets in the case of a commit or ignore them in the case of an abort (step 5.2a on the left).
5.3 Writing the final Commit or Abort Message
After all the commit or abort markers are written the data logs, the transaction coordinator writes the final COMMITTED or ABORTED message to the transaction log, indicating that the transaction is complete (step 5.3 in the diagram). At this point, most of the messages pertaining to the transaction in the transaction log can be removed.
We only need to retain the PID of the completed transaction along with a timestamp, so we can eventually remove the TransactionalId->PID mapping for the producer. See the Expiring PIDs section below.
应用例子
通过上面的流程,例子就很容易理解public class KafkaTransactionsExample {
public static void main(String args[]) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfig);
// Note that the ‘transactional.id’ configuration _must_ be specified in the
// producer config in order to use transactions.
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
// We need to initialize transactions once per producer instance. To use transactions,
// it is assumed that the application id is specified in the config with the key
// transactional.id.
//
// This method will recover or abort transactions initiated by previous instances of a
// producer with the same app id. Any other transactional messages will report an error
// if initialization was not performed.
//
// The response indicates success or failure. Some failures are irrecoverable and will
// require a new producer instance. See the documentation for TransactionMetadata for a
// list of error codes.
producer.initTransactions();
while(true) {
ConsumerRecords<String, String> records = consumer.poll(CONSUMER_POLL_TIMEOUT);
if (!records.isEmpty()) {
// Start a new transaction. This will begin the process of batching the consumed
// records as well
// as an records produced as a result of processing the input records.
//
// We need to check the response to make sure that this producer is able to initiate
// a new transaction.
producer.beginTransaction();
// Process the input records and send them to the output topic(s).
List<ProducerRecord<String, String>> outputRecords = processRecords(records);
for (ProducerRecord<String, String> outputRecord : outputRecords) {
producer.send(outputRecord);
}
// To ensure that the consumed and produced messages are batched, we need to commit
// the offsets through
// the producer and not the consumer.
//
// If this returns an error, we should abort the transaction.
sendOffsetsResult = producer.sendOffsetsToTransaction(getUncommittedOffsets());
// Now that we have consumed, processed, and produced a batch of messages, let's
// commit the results.
// If this does not report success, then the transaction will be rolled back.
producer.endTransaction();
}
}
}
}
Kafka: Exactly-once Semantics的更多相关文章
- Kafka 0.11.0.0 实现 producer的Exactly-once 语义(官方DEMO)
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients&l ...
- kafka分析
目录 1,kafka简介 2, Kafka Server 2.1,kafka中zookeeper的作用 2.2, Broker 2.2.1,Broker高性能设计 2.2.2,Broker选举机制 2 ...
- <译>Spark Sreaming 编程指南
Spark Streaming 编程指南 Overview A Quick Example Basic Concepts Linking Initializing StreamingContext D ...
- Kafka消息delivery可靠性保证(Message Delivery Semantics)
原文见:http://kafka.apache.org/documentation.html#semantics kafka在生产者和消费者之间的传输是如何保证的,我们可以知道有这么几种可能提供的de ...
- Apache Kafka(八)- Kafka Delivery Semantics for Consumers
Kafka Delivery Semantics 在Kafka Consumer中,有3种delivery semantics,分别为:至多一次(at most once).至少一次(at least ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- Kafka 文档引言
原文地址:https://kafka.apache.org/documentation.html#semantics 1.开始 1.1 引言 Kafka是一个分布式,分区队列,冗余备份的消息存储服务. ...
- Kafka基本原理
简介 Apache Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交 ...
- Apache Kafka - Schema Registry
关于我们为什么需要Schema Registry? 参考, https://www.confluent.io/blog/how-i-learned-to-stop-worrying-and-love- ...
随机推荐
- dubbo启动时检查服务
Dubbo 缺省会在启动时检查依赖的服务是否可用,不可用时会抛出异常,阻止 Spring 初始化完成,以便上线时,能及早发现问题,默认 check="true". 可以通过 che ...
- 可持久化并(xian)查(duan)集(shu)
随便地点开了这道可持久化并查集,发现了真相...这和并查集有 PI 关系哦.除了find_father(而且还不能路径压缩),全都是线段树0.0 题目链接: luogu.org 题目没什么描述,就是三 ...
- LNMP下安装Pureftpd开启FTP服务以及修改FTP端口的方法
LNMP 环境包 1.2 内置了 Pureftpd 的安装程序. 安装 Pureftpd 进入lnmp解压后的目录,执行:./pureftpd.sh 会显示如下图: 按提示输入当前MySQL的root ...
- 解决 Composer-Setup.exe 安装过程中的报错
问题 在 Windows 7 执行 Composer-Setup.exe 以安装 Composer 过程中 上图中点击[Next]时,出现如下报错信息 原因分析 由上述提示信息,可推测两方面原因: 1 ...
- 入坑C++
c++中的++来自c语言中的递增运算符,该运算符将变量加1,c++起初也叫c with class ,通过通过名称表面,C++是对c的扩展,因此C++是c语言的超集,这以为这任何有效的c程序都是有效的 ...
- P4147 玉蟾宫--单调栈
P4147 玉蟾宫 题目背景 有一天,小猫rainbow和freda来到了湘西张家界的天门山玉蟾宫,玉蟾宫宫主蓝兔盛情地款待了它们,并赐予它们一片土地. 题目描述 这片土地被分成N*M个格子,每个格子 ...
- jackson对日期的处理(序列化与反序列化)
https://blog.csdn.net/cover1231988/article/details/76021478
- vuejs使用jsx语法
想要vuejs项目支持jsx语法,需要一些插件 babel-plugin-transform-vue-jsx Babel plugin for Vue 2.0 JSX 使用方法: 安装 npm ins ...
- js分析 邮箱地址加密 [email protected]
0.参考 https://segmentfault.com/q/1010000000117476 javascript里function之前加上感叹号 ' ! ' 会怎么样? // 这么写会报错,因为 ...
- Spring Conditional注解使用小结
今天我们来总结下Conditional注解的使用. Conditional注解 增加配置类Config package condition; import org.springframework.co ...