【Spark篇】---Spark中广播变量和累加器
一、前述
Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量。
累机器相当于统筹大变量,常用于计数,统计。
二、具体原理
1、广播变量
- 广播变量理解图

- 注意事项
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
val conf = new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc = new SparkContext(conf)
val list = List("hello xasxt")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("./words.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println}
sc.stop()
2、累加器
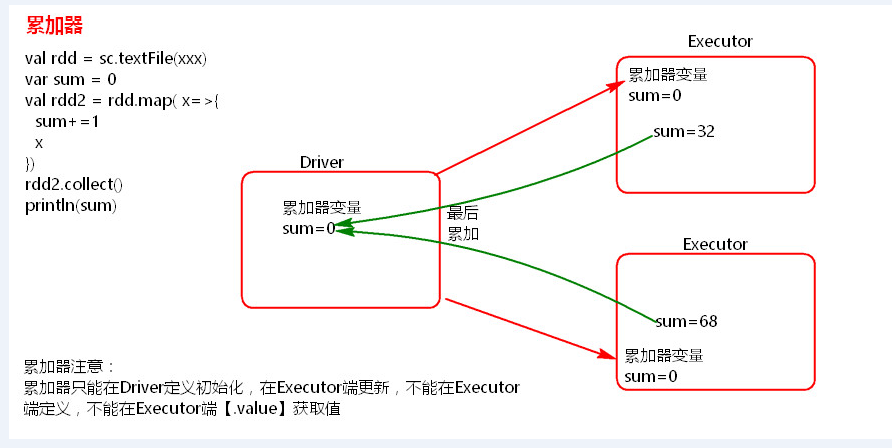
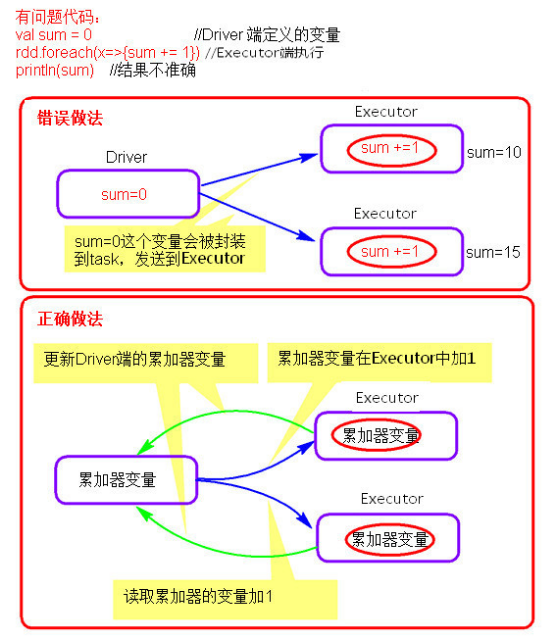
- 累加器理解图
Scala代码:
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorOperator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
val accumulator = sc.accumulator(0)
sc.textFile("./records.txt",2).foreach {//两个变量
x =>{accumulator.add(1)
println(accumulator)}}
println(accumulator.value)
sc.stop()
}
}
java代码:
package com.spark.spark.others; import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
/**
* 累加器在Driver端定义赋初始值和读取,在Executor端累加。
* @author root
*
*/
public class AccumulatorOperator {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("accumulator");
JavaSparkContext sc = new JavaSparkContext(conf);
final Accumulator<Integer> accumulator = sc.accumulator(0);
// accumulator.setValue(1000);
sc.textFile("./words.txt",2).foreach(new VoidFunction<String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
accumulator.add(1);
// System.out.println(accumulator.value());
System.out.println(accumulator);
}
});
System.out.println(accumulator.value());
sc.stop(); }
}
结果:

- 注意事项
累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
【Spark篇】---Spark中广播变量和累加器的更多相关文章
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- Spark性能优化(2)——广播变量、本地缓存目录、RDD操作、数据倾斜
广播变量 背景 一般Task大小超过10K时(Spark官方建议是20K),需要考虑使用广播变量进行优化.大表小表Join,小表使用广播的方式,减少Join操作. 参考:Spark广播变量与累加器 L ...
- 广播变量、累加器、collect
广播变量.累加器.collect spark集群由两类集群构成:一个驱动程序,多个执行程序. 1.广播变量 broadcast 广播变量为只读变量,它由运行sparkContext的驱动程序创建后发送 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
随机推荐
- SpringBoot与日志框架2(日志内斗)
一.SpringBoot如何引入slf4j+logback框架的呢? 在POM文件中 <dependency> <groupId>org.springframework.boo ...
- IO流2
一.IO流简介及分类 1.IO流简介 IO流: 简单理解数据从一个地方流向另外一个地方 2.IO流分类 按照数据流动的方向 分为 输入流和输出流 按照数据流动的单位分为 字节流和字符流 二.四大 ...
- scala_2
一.scala类 . 在java中程序的入口是main方法->定义在class中 在scala中程序的入口是main方法->定义在object对象中 案例一: class People { ...
- 网络对抗技术 20165220 Exp6 信息搜集与漏洞扫描
网络对抗技术 20165220 Exp6 信息搜集与漏洞扫描 实验任务 (1)各种搜索技巧的应用 (2)DNS IP注册信息的查询 (3)基本的扫描技术:主机发现.端口扫描.OS及服务版本探测.具体服 ...
- 第二次作业-熟悉git
GIT地址 https://github.com/gentlemanzq/yunsuanhomework GIT用户名 gentlemanzq 学号后五位 62320 博客地址 https://w ...
- 使用SQL-Front启动MySQL8.0报错
这学期学习数据库,电脑上分别装有phpStudy(自带的MySQL版本为5.5)和MySQL8.0.11,于是想用phpStudy中的SQL Front连接到8.0的数据库.手动开启8.0的MySQL ...
- linux centos环境下,perl使用DBD::Oracle遇到报错Can't locate DBD/Oracle.pm in @INC 的解决办法
前言 接手前辈的项目,没有接触.安装.使用过perl和DBD::Oracle,也没有相关的文档记录,茫茫然不知所措~~.一开始发现这个问题,就想着迅速解决,就直接在google上搜报错信息,搜索的过程 ...
- centos7搭建zabbix3.0监控系统
关闭防火墙和selinux systemctl stop firewalld.service (停止防火墙) systemctl disable firewalld.se ...
- vue table-tree 组件
最近接到一个需要使用table-tree开发 百度的一圈.什么的都有.感觉不怎么靠谱.最后找到一个感觉挺 huo shi 先附上demo和代码地址: 代码地址:https://github.com/s ...
- typescript 安装
1,全局安装 cnpm install typescript -g (tsc -v) 2,初始化 tsc --init 3,自动编译(hbuilder) 工具-插件安装-浏览eclipse插件市场-搜 ...