S/Kademlia2007 翻译
S/Kademlia:实现安全Key路由的可行方法
摘要
安全性是完全分散式P2P系统中的常见问题。 尽管关于如何创建一个安全的基于Key的路由协议存在几点建议,但一个可行的方法仍然无人参与。 在本文中,我们介绍一种基于Kademlia的安全Key路由协议,该协议通过在多条不相交的路径上使用并行查找来抵抗常见攻击,用隐式密码来限制自由节点ID生成,并引入可靠的兄弟广播。 后者需要以安全复制的方式存储数据。 我们分析评估了我们提出的Kademlia协议扩展的安全性,并模拟了对抗节点影响下多个不相交路径对查找成功的影响。
1介绍
长期以来,像Chord [18]或Pastry [14]这样的结构化P2P网络只引起了研究界的兴趣,但并未广泛应用于实际网络。 现在,随着分布式文件共享应用程序的成功,Internet的情况发生了显著的变化。 而且大型多人在线游戏的新兴领域也引起了人们对使用结构化P2P网络构建可扩展存储和通信服务的兴趣。
完全分散的P2P系统的一个主要问题是安全问题。 已经发现了几起针对结构化P2P网络的常见攻击[3,16,17]。 虽然理论上存在很多如何处理此类攻击的建议,但在构建切实可行的安全P2P网络方面几乎没有实践。
目前在互联网上使用的所有广泛部署的结构化覆盖网络(即BitTorrent,OverNet和eMule)都基于Kademlia [11]协议,容易受到多种攻击[5]的影响。 在本文中,我们分析了对Kademlia网络的攻击并提出了几种可行的对策。
本文的其余部分组织如下:在第2节中,我们提供了一些关于结构化P2P网络的背景知识,并介绍了Kademlia协议。 在第3节中,我们将概述对Kademlia的常见攻击。 我们的Kademlia安全扩展的详细设计在第4节中介绍。在第5节中,我们通过模拟来评估我们的设计。 最后,第6节涵盖相关工作,第7节结束。
2背景
在本节中,我们将提供关于结构化P2P系统的一些背景信息,并描述Kademlia协议的一些属性。所有结构化的P2P网络提供的通用服务是基于Key的路由层(KBR)[6]。该层为来自大标识符空间(称为Key的标识符)提供有效路由(典型地,n比特整数模 ,n = 128或160)。叠加层中的每个参与节点都从相同的id空间中选择唯一的nodeId,并在覆盖拓扑中维护具有nodeIds和邻居IP地址的路由表。根据覆盖协议,拓扑结构类似于环,超立方体或Bruijn图。每个节点都负责标识符空间的特定范围,通常用于ID空间中接近其nodeId的所有键。通过这种方式,通过将消息连续转发到具有更接近目的Key的节点ID的覆盖邻居,KBR可用于有效地将消息路由到任意key。这个KBR层可以用作分布式存储服务等更复杂任务的构建块。
尽管像Chord,Pastry或Kademlia这样的结构化P2P系统提供了类似的KBR服务,但它们在路由表大小和平均查找路径长度等属性方面有所不同。 在下文中,我们将重点放在Kademlia [11]协议上,因为它已经不易受几种常见攻击的影响,同时易于实现。
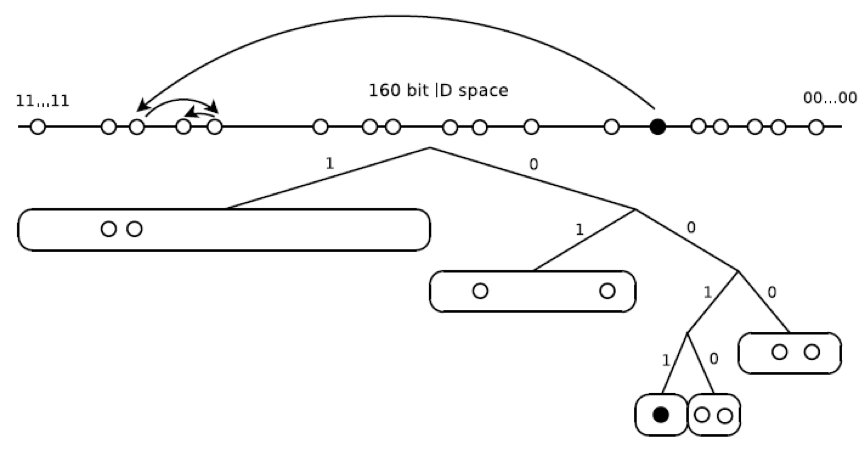
图1. Kademlia中的路由表,其中nodeId前缀为0011的节点
2.1. Kademlia
Kademlia [11]是一个结构化的点对点系统,与Chord [18]这样的协议相比,它具有几个优点,作为在标识符空间中使用新的XOR度量标准点间距的结果。 由于XOR是一种对称操作,Kademlia节点接收来自同样在本地路由表中的同一节点的查找查询。 这对于节点能从查找查询中学习有用的路由信息并更新其路由表很重要。 相比之下,由于覆盖拓扑的不对称特性,Chord需要专用的稳定协议。XOR度量也是单向的:对于任何常数x,存在恰好一个y,其距离为d(x,y)。 这确保了对相同Key的查找沿着相同的路径收敛,而不依赖于始发,这是缓存机制的重要属性。
在Kademlia中,每个节点选择一个随机的160位nodeId并维护一个由多达160个k-buckets组成的路由表。 每个k-buckets最多包含k个其他节点的三元组。 参数k是一个冗余因子,通过跨越覆盖节点之间的几条不相交路径,使路由更加健壮。 存储区按二叉树排列,根据节点标识符的最短唯一前缀将节点分配给存储区。 一个nodeId前缀为0011的节点的示例路由表如图1所示。最初,一个节点的路由表由一个覆盖整个ID空间的bucket组成。 当节点U得知新的联系人C时,节点U根据C的nodeId的前缀将C插入适当的bucket中。 如果这个bucket已经包含k个节点并且bucket的范围包括U自己的nodeId,则buckets被分成两个新的buckets。 否则,新联系人将被丢弃。
如果节点ID不均匀分布,则会出现问题。 在这种情况下,标准bucket拆分算法会导致节点不知道它们的完整k邻域。 图2给出了一个例子。该图显示了nodeId前缀为00的节点U的路由表。根据上面给出的拆分规则,对于前缀01,只有一个存储bucket有k个条目, 不会再分裂。 在这种情况下,与节点U最接近的节点前缀为010的节点可能会丢失,导致邻域不完整。 为了避免这种情况,Kademlia的作者在这些情况下提出也将节点U的nodeId不包含在内的分裂bucket分裂,导致U的nodeIdbucket旁边出现不规则的子树。 bucket分裂算法的这个例外使协议更加复杂,因此我们在4.2节中提出了一种替代方法。
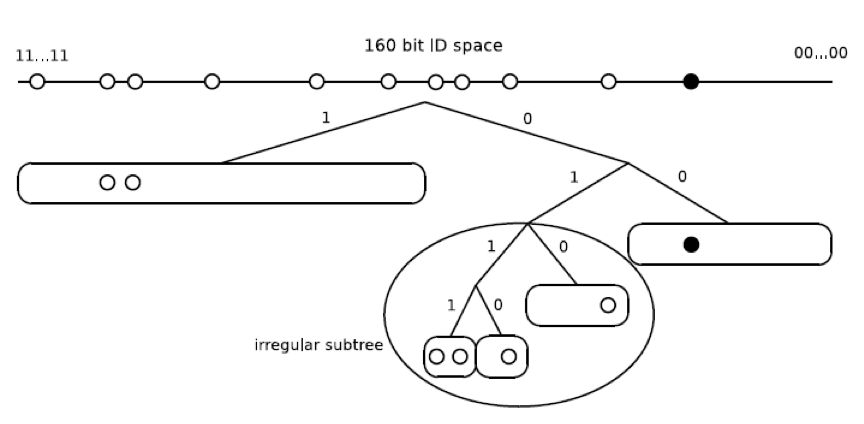
图2.高度不平衡树中Kademlia路由表的不规则性
3. 攻击Kademlia
在这一节中,我们描述了对Kademlia的基于Key的路由和数据存储的可能攻击的分类。此外,我们提出了一个理论估计的查询成功率在一个Kademlia网络与对手节点的一小部分。
3.1. 攻击底层网络
我们假设底层网络层不为覆盖层提供任何安全属性。 因此攻击者可能能够偷听或修改任意数据包。此外,我们假设节点可以欺骗IP地址,并且底层中没有数据包的认证。 因此,对底层的攻击可能会导致对覆盖层的拒绝服务攻击。
3.2.攻击覆盖路由
除了底层攻击之外,还有许多攻击会影响覆盖层路由。 本节总结了目前已知的覆盖稳定性攻击。
日蚀攻击:这种攻击尝试在网络中放置敌对节点,从而将一个或多个节点与其隔离,即所有消息都通过至少一个敌对节点进行路由。 这使攻击者可以控制覆盖网络的一部分。 因此,日蚀攻击可以从覆盖网络“隐藏”一些节点。 首先,如果一个节点不能自由选择其节点ID,其次,当它很难影响其他节点的路由表时,可以避免这种情况。 由于Kademlia青睐K-BUCKETS中的长生命节点,并且只添加节点,如果一个bucket尚未满,只要网络启动,后者就很容易实现。
女巫攻击:在完全分散的系统中,不存在控制攻击者可以获取的nodeIds数量的实例。 因此,攻击者可以用大量nodeIds加入网络,直到他控制网络中所有节点的一小部分为止。Douceur [8]证明,这种攻击是无法预防的,但只能阻止。 在集中式系统中,可以让节点用金钱支付来加入网络,并将该节点绑定到特定的自然人。 在完全分散的系统中,节点只能通过系统资源(带宽,CPU功率等)进行授权才能“付费”。
客户流失攻击:如果攻击者拥有一些节点,他可能会在网络中引发高流失,直到网络稳定失败。 由于建议Kademlia节点在其路由表中保留长期联系人,因此这种攻击对Kademlia覆盖拓扑没有太大影响。
敌对路由:当路由表既不响应路由信息也不路由任何分组时,简单地从路由表中删除节点,影响网络路由的唯一方式是返回敌对路由信息。 例如,敌对节点可能只是返回更接近查询Key的其他协作节点。 这样一种敌对节点将数据包路由到其协作者的子网中,并且查找到的和给定Key的最近节点都不会被找到。 这可以通过使用考虑多个不相交路径的查找算法来防止。 当一条路径没有敌对节点时,查找成功。 因此,假设m是对抗节点的分数,d是不相交路径的数量,(hi)路径长度分布,则查找成功的概率由下式给出:
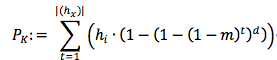
这表明,特别是对于中等数量的敌对节点,查找算法可以显着受益于不相交路径以及低平均路径长度。
3.3. 其他攻击
拒绝服务:敌对方可能试图欺骗受害者以消耗其所有资源,即内存,带宽,计算能力。 因此,协议需要有机制以安全的方式分配资源。 本文不考虑物理攻击,如干扰或边带攻击。
对数据存储的攻击: 基于Key的路由协议通常用作构建块以实现用于数据存储的分布式散列表(DHT)。 为了使对抗节点更难以修改存储的数据项,相同的数据项被复制到多个相邻节点上。 尽管本文不考虑对数据存储的攻击,但基于Key的路由层必须为给定的Key提供安全邻域。
4. 设计
在本节中,我们提出一个切实可行的安全Kademlia协议。 在第4.1节中,我们介绍一种以安全方式分配nodeIds的方法。 进一步提出了一种可靠的兄弟广播,其以安全的方式存储复制的数据。 最后我们解释如何保护路由表维护。
4.1. 安全的nodeId分配
从3.2节可知,攻击者很难产生大量的nodeIds(Sybil攻击),也不能自由选择nodeId(Eclipse攻击)。此外,nodeId应该认证节点,即没有其他节点应该能够窃取或伪造nodeId。后者可以通过以下两种方法之一来实现:在IP地址和端口上使用散列值或通过散列公钥。第一种解决方案有一个明显的缺点,因为动态分配IP地址后,nodeId将会改变。如果您要支持具有多个节点似乎具有相同公共IP地址的NAT的网络,那么也不适合限制生成的nodeIds的数量。最后,没有办法确保与那些节点标识符交换消息的完整性。这就是为什么我们提倡使用公钥上的哈希来生成nodeId。使用这个公钥可以签署节点交换的消息。由于计算开销,我们区分了两种签名类型:
• 弱签名:弱签名不签署整个消息。 它仅限于IP地址,端口和时间戳。 时间戳指定签名有效的时间。 如果使用动态IP地址,这将防止重放攻击。 对于同步问题,时间戳可能以非常粗糙的方式选择。 弱签名主要用于FIND NODE和PING消息,其中整个消息的完整性是可有可无的。
• 强有力的签名:强有力的签名在邮件的全部内容上签名。 这确保了消息的完整性和抵御中间人攻击的弹性。RPC消息内的随机数可以防止重放攻击。
这两种签名类型可以对节点进行身份验证并确保消息的完整性。 我们现在需要阻止女巫攻击和日蚀攻击。这是通过使用加密谜题或来自中央证书颁发机构的签名完成的,因此我们需要将上述签名类型与以下某个签名类型结合使用:
• 受监督签名:如果签名的公钥另外由可信的证书颁发机构签名,则该签名被称为受监督签名。这个签名是必要的,以阻止SybIL攻击在网络的引导阶段,其中只有少数节点存在于网络中。可以使用网络大小估计来决定是否需要该签名。
• 加密拼图签名:在没有可信权威的情况下,我们需要用加密拼图来阻止日蚀和女巫攻击。 在[3]中使用加密谜题来生成nodeId是因为它们不能被用来完全阻止攻击。 但是,在我们看来,它们是在完全分散的环境中没有可信权威的分布式nodeId生成的最有效的方法,因此应该用于在这样的网络中尽可能地进行攻击。
出于这个原因,我们引入了两个加密谜题,如图3所示。一个静态谜题阻碍了NodeId的自由选择和一个动态谜题,以确保生成大量nodeIds的复杂性。H表示密码安全散列函数,⊕是异或运算, 表示加密难题复杂度。 很明显,的增加减少了可能的公钥的空间,因此公钥的大小必须随后增加。被认为是一个常数。 一旦生成了nodeId,它就保持固定一定的值。 当计算资源变得更便宜时,可以随着时间的推移而被修改或扩展。
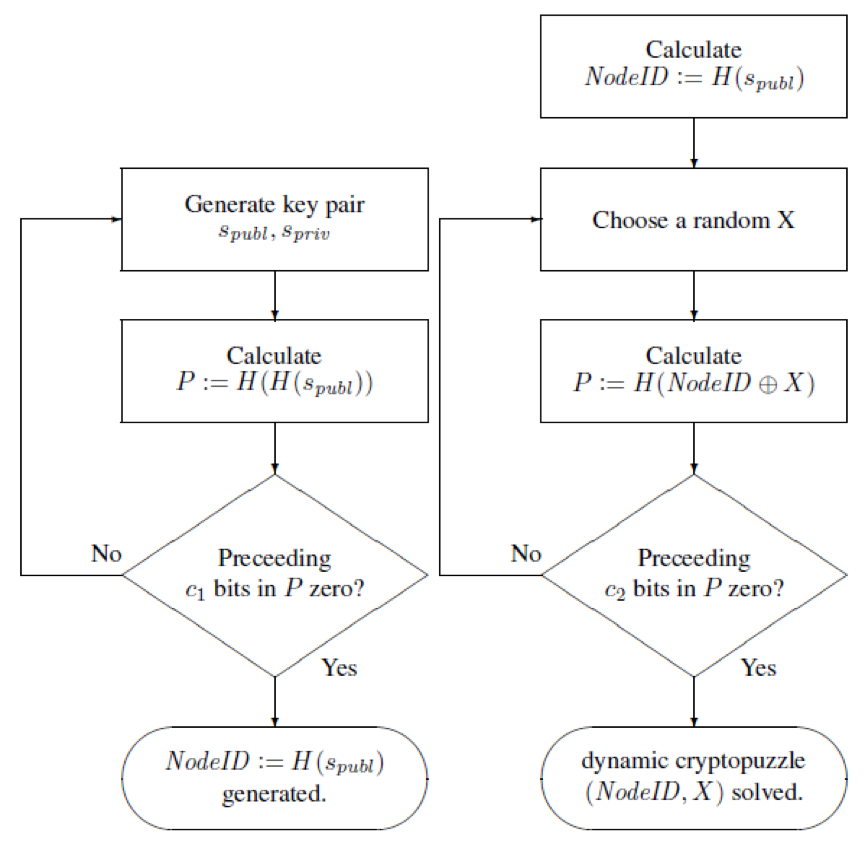
图3. 用于nodeId生成的静态(左)和动态(右)加密难题
如果一个节点收到一个签名的消息,它现在可以首先验证它的签名,然后检查密码拼图是否被解决。 两个操作对于恒定公钥大小都具有O(1) 复杂性,而加密难题创建具有O(2c1 + 2c2)复杂性。
4.2. 可靠兄弟广播
兄弟是负责需要存储在DHT中的某个键值对的节点。 在Kademlia的情况下,这些键值对被复制到k个最接近的节点上(我们记得:k是bucket大小)。 在本文中,我们希望独立于bucket大小k考虑这个数量的节点,并引入兄弟数量作为参数s。 这很有意义,因为存储区大小通常定义了覆盖连接的冗余度,而不是DHT需要存储的副本数量。
一个常见的安全问题是兄弟信息的可靠性,当复制的信息需要存储在使用多数决定来补偿敌对节点的DHT中时产生。 由于Kademlia的原始协议收敛到兄弟列表中,分析和证明兄弟信息的一致性是很复杂的。 出于这个原因,我们引入一个大小为每个节点η · s的兄弟列表,这确保了每个节点至少在节点的兄弟范围内以高概率知道兄弟的一个ID。 我们现在必须确定η并证明约束具有很高的概率。Gai和Viennot在他们关于Broose DHT的论文中已经完成了这项工作[10],其中兄弟名单以相同的方式构建。 由于这个证明不必要地使用了Chernoff边界,我们在这里回顾证明:
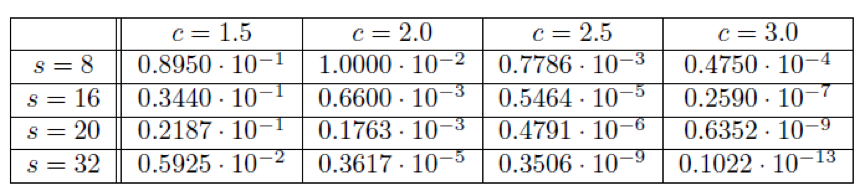
表1.不完整的兄弟列表的概率
如前所述,XOR度量是单向的,这意味着对于一个固定的x和每个,只有一个y存在。 考虑随机选择两个节点ID,则一个节点ID小于节点ID的概率由
(n是节点ID的位数)给出。 令N为网络中节点的数量,则两个相邻节点之间XOR度量的平均距离为
.。 现在考虑距离
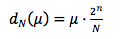
两个节点与nodeId x和y,那么x和y之间的期望节点数N(x, y)为E[N(x, y)] = µ,节点放置在x和y之间的概率为由给出。 由于nodeIds是随机选择的,因此x和y之间的实际节点数量与期望值μ有所不同。 因此,在距离
(cs)
 处x和y之间少于s个节点的概率由下式给出:
处x和y之间少于s个节点的概率由下式给出:
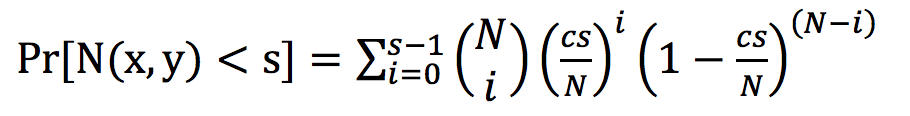
对于小s> 0,这个概率是可计算的,因为以下是必须的:

所以使用Chernoff边界是没有必要的。 这使得该解更精确,并且可以如表1所示计算具有N = 的上限网络大小的依赖于c和s的以下概率。
其余的证明如下[10]。 有趣的事实是,显示η ≥ (2·c) ≥ 5的值足以满足我们需要的约束w.h.p.
因此,在S/Kademlia中,路由表由包含具有距离d且具有≤d <
, 0≤i≤n的节点的k个bucket的列表组成,大小η · s。 由于新引入的同级列表,第2.1节中介绍的特殊子树处理可以省略。 由于Kademlia中的路由表通过传入的查找请求隐式刷新,并且我们兄弟表中的许多节点必须存储在Kademlia的k-bucket中,因此维护兄弟表的额外通信开销很小。
4.3. 路由表维护
Kademlia使用反应式方法来维护路由表。由于XOR度量确保所有迭代查找沿着同一路径收敛,Kademlia可以从传入的RPCs中了解新节点的存在。为了确保S/Kademlia中的路由表维护,我们将信令消息分类为以下类:传入签名的RPC请求、响应或未签名消息。这些消息中的每一个都包含发送者地址。如果消息弱或强签名,则此地址不能伪造或与另一个nodeId关联(见第4.1节)。如果发送方地址有效并且来自RPC响应,则如果消息被签名并有效,则调用发送方地址有效。Kademlia使用那些发送者地址来维护他们的路由表。
当活动有效的发件人地址未满时,会立即将其添加到相应的存储区中。 如果nodeId前缀在适当的位数χ中不同(例如,χ > 32),则有效的发件人地址只能添加到存储bucket中。 这是必要的,因为攻击者可以很容易地生成与受害者nodeId共享前缀并溢出他的bucket的nodeId,因为靠近自己的nodeId的bucket只在Kademlia中稀疏填充。 来自未签名消息的发件人地址将被忽略。 如果消息包含有关其他节点的更多信息,则可以通过调用它们上的ping RPC来添加每个节点。 如果一个节点已经存在于路由表中,它将在bucket的尾部移动。
4.4. 通过不相交的路径进行查找
在3.2节中,我们展示了使用多条不相交路径来查找具有对抗节点的网络中的Key的重要性。 原始的Kademlia查找迭代地查询具有FIND NODE RPC的α节点,以找到与目标Key最近的k个节点。α是系统范围的冗余参数,例如2.在每个步骤中,将来自先前RPC的返回节点合并到排序列表中,从中选择下一个α节点。 这种方法的一个主要缺点是,只要查询单个敌对节点,查找就会失败。
我们将该算法推广到使用D不相交路径,从而提高了具有对抗节点的网络中的查找成功率。发起方通过从本地路由表中获取K个最接近节点到目标Key并将其分配到与D无关的查找桶开始查找。从那里节点继续与传统的KMDELLA查找相似的D并行查找。查找是独立的,除了重要的事实,每个节点只在整个查找过程中使用一次,以确保所产生的路径真的不相交。通过使用来自第4.2节的兄弟列表,查找不会在单个节点上收敛,而是在邻居关闭的D上结束,所有邻居都知道目标Key的完整S兄弟。因此,即使k近邻的1是对立的,查找仍然是成功的。

图4.具有固定bucket大小k = 16的成功节点查找的分数
5. 评估
在本节中,我们用OverSim [2]来评估S/Kademlia,这是一个用于叠加模拟的灵活框架。 我们描述了仿真设置和程序,并最终描述了我们的仿真结果。
5.1. 模拟假设
我们用以下假设模拟敌对节点:敌对节点在最坏情况下返回损害网络的数据。 因此,在FIND NODE RPC的情况下,最差的行为只会返回其他更接近目标nodeId的协作节点。 对手还会收获其他现有的有效nodeIds,以便将它们映射到虚假的传输地址。 这是最坏的情况,因为可以检测到诸如空结果或无效数据之类的其他反应,并且将该节点从网络中移除,即该节点将被视为陈旧联系人。

图5.具有自适应bucket大小k = 2d的成功节点查找的分数
另一方面,我们假设良好行为的节点以平均分布的方式返回对抗节点信息。 这个假设在第4节中得到证实,因为敌对节点几乎不可能影响其他节点的路由表。
通过这些假设,我们预计如果没有对抗节点位于负责节点的一条路径上,则节点或兄弟节点的查找是成功的。 在多条路径上进行并行查找的情况下,我们只需停止追踪遇到敌对节点的每条路径,并且只有一条路径没有任何敌对节点时,才会将查找视为成功。
5.2. 仿真程序
为了保持仿真效率,我们首先创建一个静态Kademlia覆盖网络,其中包含N个完全稳定的节点。 然后我们继续处理N个节点查找并评估成功查询的比例。 随着对抗节点增加5%重复该过程,直到90%的节点是对抗的。 由于我们不评估流失,所有仿真都是在α= 1的参数下完成的,并且我们假定网络在引导阶段后保持稳定状态,但是在对抗节点的影响下。
5.3. 结果
我们使用d ∈ {1, 2, 4, 8} 不相交的路径模拟了网络规模为N = 10000个节点,s = 16个兄弟的两个设置。 在图4中,我们展示了取决于固定存储区大小k = 16的对抗节点数的成功查找部分。对于d = 1,查找过程与标准Kademlia查找相似。 该图清楚地表明,通过增加并行不相交路径的数量d,成功查找的比例可以大大提高。 在这种情况下,通信开销随着d线性增加。 我们还可以看到,当k = 16时,k-buckets中有足够的冗余来实际创建不相交的路径。
在第二种设置中,我们将k = 2 · d调整为不相交路径的数量,以保持路由表中的最小冗余度,并因此减少通信开销。 图5中的结果显示,与图4相比,较小的k导致成功查找的一小部分。其原因是由于路径表中较小的路由表增加了平均路径长度,如路径长度分布图中所示。
我们得出结论,d = 4..8,k = 8..16对S/Kademlia来说是个不错的选择。 较高的d和k值似乎不值得额外的通信成本。 较大的k值也会增加很大一部分bucket长时间不满的概率。 这不必要地使路由表更容易受到日蚀攻击。
由于我们仅提供了N = 10000个节点的模拟,有人可能会认为这是一个相当少的节点,并不能与大型网络相媲美。 事实上,路径长度与成功查找的比例高度相关。 另一方面,网络拓扑结构可以很容易地调整为具有较小的直径,因此较短的平均路径长度。 这通常通过在每个步骤中考虑nodeId的多个位b来完成。 因此,可以将网络调整到不同情况下所需的安全级别。
6. 相关工作
Castro等人[3]研究对结构化点对点覆盖中消息路由的攻击。 他们提出了一些防御措施来确保加入过程,路由表维护和消息转发。 将nodeIds的安全分配委托给中央信任的证书颁发机构。
Sit和Morris [16]在Chord,CAN和Pastry的基础上提出了针对点对点分布式哈希表的攻击分类。 他们表示,防御这些攻击的重要步骤是通过定义可验证的系统不变量进行检测。 例如,节点可以通过验证查找是否“接近”目标Key来检测不正确的查找路由。
Srivatsa和Liu [17]研究了基于DHT的P2P系统中的三种安全威胁。 首先,他们对路由方案提出攻击,其中单个敌对节点可以在没有备用路径的情况下阻止所有查找请求。 因此,他们强调了几种备选最佳路径的重要性,以及检测不正确查找结果的可行性。 此外,他们对数据放置方案提出了攻击,并表明单靠复制不足以容忍敌对节点的攻击,但必须与密码技术相结合才能有效。 最后,他们显示必须限制nodeId选择过程,以防止敌对节点破坏特定的数据项。
Awerbuch和Scheideler [1]提出了一种理论上的DHT,它可以抵抗对抗式加入假以及插入式查找攻击。DHT的设计是高层次的,它是一个开放的问题,将它们的想法转化为可行的协议是多么困难。 另一个可以处理加入- 离开攻击的DHT是SChord [9],但它仅限于线性数量的对抗加入请求。
Cerri等人[4]重点关注无限选择nodeIds引起的攻击,并用Kademlia协议举例说明其发现。 他们建议通过散列函数将IP地址和端口耦合到nodeId来限制空闲的nodeId选择。 为了使敌对节点难以攻击特定的数据项,他们建议将数据项存储在一个临时Key中,该Key会定期轮换。 这是通过用一些暂时信息对数据项的Key进行散列来计算临时Key来完成的,
有几篇论文提出了针对女巫攻击的对策:在[13] Rowaihy 等。 为结构化的同行P2P系统提供准入控制系统。 这些系统构建了协作接纳控制节点的树状分层结构,从中加入节点必须获得接纳。 另一种限制女巫攻击的方法是将参与节点的IP地址存储在安全的DHT中。 通过这种方式,每个IP地址的nodeIds数量可以通过查询DHT来限制,如果新节点想要加入。
Singh等人[15]研究Eclipse攻击对结构化覆盖网络的影响,并提出通过让节点互相审计连接来抵御这种攻击。 这个想法是,一个挂载Eclipse攻击的节点的节点度高于平均值。
Nielson等人[12]认为理性攻击的类别。 他们认为P2P系统中很大一部分节点是自私的,并试图最大限度地消耗系统资源,同时尽量减少自己的使用。
7. 结论
在本文中,我们提出了一个基于Kademlia的基于安全Key的路由协议。 尽管优雅的路由表维护使得Kademlia已经不易受到某些攻击,但我们已经表明,存在多个易受攻击节点控制网络的漏洞。
我们提出几个切实可行的解决方案,使Kademlia更具弹性。 首先,我们建议通过结合公钥密码术使用加密谜题来限制免费的nodeId生成。 此外,我们通过兄弟列表扩展Kademlia路由表。 这降低了bucket分裂算法的复杂性,并允许DHT以安全复制的方式存储数据。 最后,我们提出了一种查找算法,该算法使用多条不相交路径来提高查找成功率。
S/Kademlia在仿真框架OverSim中的评估表明,即使使用20%的对抗节点,如果使用不相交路径,所有查找的99%仍然是成功的。我们相信,建议的Kademlia协议的扩展是实用的,可以用来方便地安全现有的Kademlia网络。
承认
这项研究得到了德国联邦教育与研究部的支持,作为ScaleNet项目01BU567的一部分,以及作为SpoVNet项目一部分的BW-FIT支持计划。
参考
[1] B. Awerbuch and C. Scheideler. Towards a scalable and robust dht. In SPAA ’06: Proceedings of the eighteenth annual ACM symposium on Parallelism in algorithms and architectures, pages 318–327, New York, NY, USA, 2006. ACM Press.
[2] I. Baumgart, B. Heep, and S. Krause. OverSim: A flexible overlay network simulation framework. In Proceedings of 10th IEEE Global Internet Symposium (GI ’07) in conjunction with IEEE INFOCOM 2007, Anchorage, AK, USA, May 2007.
[3] M. Castro, P. Druschel, A. Ganesh, A. Rowstron, and D. S. Wallach. Secure routing for structured peer-to-peer overlay networks. SIGOPS Oper. Syst. Rev., 36(SI):299–314, 2002.
[4] D. Cerri, A. Ghioni, S. Paraboschi, and S. Tiraboschi. Id mapping attacks in p2p networks. In Global Telecommunications Conference, GLOBECOM’05. IEEE, 2005.
[5] S. A. Crosby and D. S. Wallach. An analysis of two bittorrent distributed trackers. Presentation at the South Central Information Security Symposium (SCISS ’06), 2006.
[6] F. Dabek, B. Zhao, P. Druschel, J. Kubiatowicz, and I. Stoica. Towards a common api for structured peer-to-peer overlays. In Proceedings of the 2nd International Workshop on Peer-to-Peer Systems (IPTPS ’03), volume Volume 2735/2003, pages 33–44, 2003.
[7] J. Dinger and H. Hartenstein. Defending the sybil attack in p2p networks: Taxonomy, challenges, and a proposal for self-registration. ares, 0:756–763, 2006.
[8] J. R. Douceur. The sybil attack. In IPTPS ’02: Revised Papers from the First International Workshop on Peer-toPeer Systems, pages 251–260, London, UK, 2002. SpringerVerlag.
[9] A. Fiat, J. Saia, and M. Young. Making chord robust to byzantine attacks. In ESA, Lecture Notes in Computer Science, pages 803–814. Springer, 2005.
[10] A.-T. Gai and L. Viennot. Broose: a practical distributed hashtable based on the de-bruijn topology. In Fourth International Conference on Peer-to-Peer Computing, 2004, pages 167–174, aug 2004.
[11] P. Maymounkov and D. Mazires. Kademlia: A peer-to-peer information system based on the xor metric. In Peer-to-Peer Systems: First InternationalWorkshop, IPTPS 2002 Cambridge, MA, USA, March 7-8, 2002. Revised Papers, volume Volume 2429/2002, pages 53–65, 2002.
[12] S. Nielson, S. Crosby, and D. Wallach. A taxonomy of rational attacks. In 4th International Workshop on Peer-To-Peer Systems, Ithaca, New York, USA, February 2005.
[13] H. Rowaihy, W. Enck, P. Mcdaniel, and T. La-Porta. Limiting sybil attacks in structured peer-to-peer networks. Technical Report NAS-TR-0017-2005, Network and Security Research Center, Department of Computer Science and Engineering, Pennsylvania StateUniversity, University Park, PA, USA, 2005.
[14] A. Rowstron and P. Druschel. Pastry: Scalable, decentralized object location, and routing for large-scale peer-to-peer systems. In Middleware 2001 : IFIP/ACM International Conference on Distributed Systems Platforms Heidelberg, Germany, November 12-16, 2001. Proceedings, volume Volume 2218/2001, pages 329+, 2001.
[15] A. Singh, T.-W. J. Ngan, P. Druschel, and D. Wallach. Eclipse attacks on overlay networks: Threats and defenses. In In Proceedings of INFOCOM 06, Barcelona, Spain. April 2006, 2006.
[16] E. Sit and R. Morris. Security considerations for peer-topeer distributed hash tables. In IPTPS ’02: Revised Papers from the First International Workshop on Peer-to-Peer Systems, pages 261–269, London, UK, 2002. Springer-Verlag.
[17] M. Srivatsa and L. Liu. Vulnerabilities and security threats in structured overlay networks: A quantitative analysis. In ACSAC ’04: Proceedings of the 20th Annual Computer Security Applications Conference (ACSAC’04), pages 252–261, Washington, DC, USA, 2004. IEEE Computer Society.
[18] I. Stoica, R. Morris, D. Liben-Nowell, D. Karger, M. Kaashoek, F. Dabek, and H. Balakrishnan. Chord: a scalable peer-to-peer lookup protocol for internet applications. IEEE/ACM Transactions on Networking, 11(1):17–32, feb 2003.
如果有关于区块链学习的交流,可以通过下面的方式联系我:
wechat:omnigeeker
S/Kademlia2007 翻译的更多相关文章
- 《Django By Example》第五章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者@ucag注:大家好,我是新来的翻译, ...
- 《Django By Example》第四章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:祝大家新年快乐,这次带来<D ...
- [翻译]开发文档:android Bitmap的高效使用
内容概述 本文内容来自开发文档"Traning > Displaying Bitmaps Efficiently",包括大尺寸Bitmap的高效加载,图片的异步加载和数据缓存 ...
- 【探索】机器指令翻译成 JavaScript
前言 前些时候研究脚本混淆时,打算先学一些「程序流程」相关的概念.为了不因太枯燥而放弃,决定想一个有趣的案例,可以边探索边学. 于是想了一个话题:尝试将机器指令 1:1 翻译 成 JavaScript ...
- 《Django By Example》第三章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第三章滚烫出炉,大家请不要吐槽文中 ...
- 《Django By Example》第二章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:翻译完第一章后,发现翻译第二章的速 ...
- 《Django By Example》第一章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:本人目前在杭州某家互联网公司工作, ...
- 【翻译】Awesome R资源大全中文版来了,全球最火的R工具包一网打尽,超过300+工具,还在等什么?
0.前言 虽然很早就知道R被微软收购,也很早知道R在统计分析处理方面很强大,开始一直没有行动过...直到 直到12月初在微软技术大会,看到我软的工程师演示R的使用,我就震惊了,然后最近在网上到处了解和 ...
- ASP.NET MVC with Entity Framework and CSS一书翻译系列文章之第一章:创建基本的MVC Web站点
在这一章中,我们将学习如何使用基架快速搭建和运行一个简单的Microsoft ASP.NET MVC Web站点.在我们马上投入学习和编码之前,我们首先了解一些有关ASP.NET MVC和Entity ...
随机推荐
- 报错【org.springframework.validation.BeanPropertyBindingResult】
报错内容:org.springframework.validation.BeanPropertyBindingResult: 1 errors Field error in object 'price ...
- 刷新浏览器 protractor
//refresh browser.ignoreSynchronization = true; browser.refresh(); browser.sleep(3000); browser.swit ...
- EM 算法最好的解释
https://wenku.baidu.com/view/fcb6a52bf5335a8102d220e3.html
- 浅谈get,post,put和delete请求
get.put.post.delete含义与区别 1.GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改.增加数据,不会影 ...
- maven各个属性参数详解
<project xmlns="http://maven.apache.org/POM/4.0.0 " xmlns:xsi="http://www.w3.org/2 ...
- memcache 杂记
它是一个一个高性能的分布式内存对象缓存系统. 端口号 11211 目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的. 需要频繁访问数据库的网站访问速度提升效果十分显著 根据一个sql取出的 ...
- 在Django中使用ForeignKey()报错问题的解决
在Django2的models中建立一对多的关系使用ForeignKey(): student = models.ForeignKey("Classes") 报错: TypeErr ...
- libpointmatcher安装和使用
libpointmatcher介绍: libpointmatcher is a modular library implementing the Iterative Closest Point (IC ...
- javaSE-多线程
[线程池概念] 由于系统启动一个新线程的成本是比较高的,因为他涉及与操作系统的交互(这也就是为什么可以有百万个Goroutines,却只有几千个java线程).在这种情形下,使用线程池可以很好地提高性 ...
- (转)python中函数参数中如果带有默认参数list的特殊情况
在python中函数参数中如果带有默认参数list遇到问题 先看一段代码 1 2 3 4 5 6 7 8 9 def f(x,l=[]): for i in range(x): ...