python基础知识4--数据类型与变量
阅读目录
- 一.变量
- 二.数据类型
- 2.1 什么是数据类型及数据类型分类
- 2.2 标准数据类型:
- 2.2.1 数字
- 2.2.1.1 整型:
- 2.2.1.2 长整型long:
- 2.2.1.3 布尔bool:
- 2.2.1.4 浮点数float:
- 2.2.1.5 复数complex:
- 2.2.1.6 数字相关内建函数
- 2.2.2 字符串
- 2.2.2.1 字符串创建
- 2.2.2.2 字符串常用操作
- 2.2.2.3 字符工厂函数str()
- 2.2.3 列表
- 2.2.3.1 列表创建
- 2.2.3.2 列表常用操作
- 2.2.3.3 列表工厂函数list()
- 2.2.4 元组
- 2.2.4.1 元组创建
- 2.2.4.2 元组常用操作
- 2.2.4.3 元组工厂函数tuple()
- 2.2.5 字典
- 2.2.5.1 字典创建
- 2.2.5.2 字典常用操作
- 2.2.5.3 字典工厂函数dict()
- 2.2.6 集合
- 2.2.6.1 集合创建
- 2.2.6.2 集合常用操作:关系运算
- 2.2.6.3 集合工厂函数set()
- 2.2.7 bytes类型
- 2.2.8 数据类型转换内置函数汇总
- 三.运算符
- 四.标准数据类型特性总结
一.变量
1 什么是变量之声明变量
#变量名=变量值
age=18
gender1='male'
gender2='female'
2 为什么要有变量 变量作用:“变”=>变化,“量”=>计量/保存状态
程序的运行本质是一系列状态的变化,变量的目的就是用来保存状态,变量值的变化就构成了程序运行的不同结果。
例如:CS枪战,一个人的生命可以表示为life=active表示存活,当满足某种条件后修改变量life=inactive表示死亡。
3 变量值之类型与对象
程序中需要处理的状态很多,于是有了不同类型的变量值,x='egon',变量值'egon'存放与内存中,绑定一个名字x,变量值即我们要存储的数据。 在python中所有数据都是围绕对象这个概念来构建的,对象包含一些基本的数据类型:数字,字符串,列表,元组,字典等
程序中存储的所有数据都是对象,
一个对象(如a=1)有:
一个身份(id)
一个类型(type)
一个值(通过变量名a来查看)
1 对象的类型也称为对象的类别,python为每个类型都定制了属于该类型特有的方法,极大地方便了开发者对数据的处理
2 创建某个特定类型的对象也称为创建了该类型的一个实例,工厂函数的概念来源于此
4 可变对象与不可变对象
实例被创建后,身份和类型是不可变的,
如果值是不可以被修改的,则是不可变对象
如果值是可以被修改的,则是可变对象 5 容器对象
某个对象包含对其他对象的引用,则称为容器或集合 6 对象的属性和方法
属性就是对象的值,方法就是调用时将在对象本身上执行某些操作的函数,使用.运算符可以访问对象的属性和方法,如
a=3+4j
a.real b=[1,2,3]
b.append(4) 7 身份比较,类型比较,值比较
x=1
y=1
x is y #x与y是同一个对象,is比较的是id,即身份
type(x) is type(y) #对象的类型本身也是一个对象,所以可以用is比较两个对象的类型的身份
x == y #==比较的是两个对象的值是否相等 7 变量的命名规范
- 变量命名规则遵循标识符命名规则,详见第二篇
8 变量的赋值操作
- 与c语言的区别在于变量赋值操作无返回值
- 链式赋值:y=x=a=1
- 多元赋值:x,y=1,2 x,y=y,x
- 增量赋值:x+=1
二.数据类型
2.1 什么是数据类型及数据类型分类
程序的本质就是驱使计算机去处理各种状态的变化,这些状态分为很多种 例如英雄联盟游戏,一个人物角色有名字,钱,等级,装备等特性,大家第一时间会想到这么表示
名字:德玛西亚------------>字符串
钱:10000 ------------>数字
等级:15 ------------>数字
装备:鞋子,日炎斗篷,兰顿之兆---->列表
(记录这些人物特性的是变量,这些特性的真实存在则是变量的值,存不同的特性需要用不同类型的值) python中的数据类型
python使用对象模型来存储数据,每一个数据类型都有一个内置的类,每新建一个数据,实际就是在初始化生成一个对象,即所有数据都是对象
对象三个特性
- 身份:内存地址,可以用id()获取
- 类型:决定了该对象可以保存什么类型值,可执行何种操作,需遵循什么规则,可用type()获取
- 值:对象保存的真实数据
注:我们在定义数据类型,只需这样:x=1,内部生成1这一内存对象会自动触发,我们无需关心 这里的字符串、数字、列表等都是数据类型(用来描述某种状态或者特性)除此之外还有很多其他数据,处理不同的数据就需要定义不同的数据类型
| 标准类型 | 其他类型 |
| 数字 | 类型type |
| 字符串 | Null |
| 列表 | 文件 |
| 元组 | 集合 |
| 字典 | 函数/方法 |
| 类 | |
| 模块 |
2.2 标准数据类型:
2.2.1 数字
定义:a=1
特性:
1.只能存放一个值
2.一经定义,不可更改
3.直接访问
分类:整型,长整型,布尔,浮点,复数
2.2.1.1 整型:
Python的整型相当于C中的long型,Python中的整数可以用十进制,八进制,十六进制表示。
>>> 10
10 --------->默认十进制
>>> oct(10)
'012' --------->八进制表示整数时,数值前面要加上一个前缀“0”
>>> hex(10)
'0xa' --------->十六进制表示整数时,数字前面要加上前缀0X或0x
python2.*与python3.*关于整型的区别
python2.*
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647 在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
python3.*整形长度无限制
整型工厂函数int()
class int(object):
"""
int(x=0) -> int or long
int(x, base=10) -> int or long Convert a number or string to an integer, or return 0 if no arguments
are given. If x is floating point, the conversion truncates towards zero.
If x is outside the integer range, the function returns a long instead. If x is not a number or if base is given, then x must be a string or
Unicode object representing an integer literal in the given base. The
literal can be preceded by '+' or '-' and be surrounded by whitespace.
The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to
interpret the base from the string as an integer literal.
>>> int('0b100', base=0)
"""
def bit_length(self):
""" 返回表示该数字的时占用的最少位数 """
"""
int.bit_length() -> int Number of bits necessary to represent self in binary.
>>> bin(37)
'0b100101'
>>> (37).bit_length()
"""
return 0 def conjugate(self, *args, **kwargs): # real signature unknown
""" 返回该复数的共轭复数 """
""" Returns self, the complex conjugate of any int. """
pass def __abs__(self):
""" 返回绝对值 """
""" x.__abs__() <==> abs(x) """
pass def __add__(self, y):
""" x.__add__(y) <==> x+y """
pass def __and__(self, y):
""" x.__and__(y) <==> x&y """
pass def __cmp__(self, y):
""" 比较两个数大小 """
""" x.__cmp__(y) <==> cmp(x,y) """
pass def __coerce__(self, y):
""" 强制生成一个元组 """
""" x.__coerce__(y) <==> coerce(x, y) """
pass def __divmod__(self, y):
""" 相除,得到商和余数组成的元组 """
""" x.__divmod__(y) <==> divmod(x, y) """
pass def __div__(self, y):
""" x.__div__(y) <==> x/y """
pass def __float__(self):
""" 转换为浮点类型 """
""" x.__float__() <==> float(x) """
pass def __floordiv__(self, y):
""" x.__floordiv__(y) <==> x//y """
pass def __format__(self, *args, **kwargs): # real signature unknown
pass def __getattribute__(self, name):
""" x.__getattribute__('name') <==> x.name """
pass def __getnewargs__(self, *args, **kwargs): # real signature unknown
""" 内部调用 __new__方法或创建对象时传入参数使用 """
pass def __hash__(self):
"""如果对象object为哈希表类型,返回对象object的哈希值。哈希值为整数。在字典查找中,哈希值用于快速比较字典的键。两个数值如果相等,则哈希值也相等。"""
""" x.__hash__() <==> hash(x) """
pass def __hex__(self):
""" 返回当前数的 十六进制 表示 """
""" x.__hex__() <==> hex(x) """
pass def __index__(self):
""" 用于切片,数字无意义 """
""" x[y:z] <==> x[y.__index__():z.__index__()] """
pass def __init__(self, x, base=10): # known special case of int.__init__
""" 构造方法,执行 x = 123 或 x = int(10) 时,自动调用,暂时忽略 """
"""
int(x=0) -> int or long
int(x, base=10) -> int or long Convert a number or string to an integer, or return 0 if no arguments
are given. If x is floating point, the conversion truncates towards zero.
If x is outside the integer range, the function returns a long instead. If x is not a number or if base is given, then x must be a string or
Unicode object representing an integer literal in the given base. The
literal can be preceded by '+' or '-' and be surrounded by whitespace.
The base defaults to 10. Valid bases are 0 and 2-36. Base 0 means to
interpret the base from the string as an integer literal.
>>> int('0b100', base=0)
# (copied from class doc)
"""
pass def __int__(self):
""" 转换为整数 """
""" x.__int__() <==> int(x) """
pass def __invert__(self):
""" x.__invert__() <==> ~x """
pass def __long__(self):
""" 转换为长整数 """
""" x.__long__() <==> long(x) """
pass def __lshift__(self, y):
""" x.__lshift__(y) <==> x<<y """
pass def __mod__(self, y):
""" x.__mod__(y) <==> x%y """
pass def __mul__(self, y):
""" x.__mul__(y) <==> x*y """
pass def __neg__(self):
""" x.__neg__() <==> -x """
pass @staticmethod # known case of __new__
def __new__(S, *more):
""" T.__new__(S, ...) -> a new object with type S, a subtype of T """
pass def __nonzero__(self):
""" x.__nonzero__() <==> x != 0 """
pass def __oct__(self):
""" 返回改值的 八进制 表示 """
""" x.__oct__() <==> oct(x) """
pass def __or__(self, y):
""" x.__or__(y) <==> x|y """
pass def __pos__(self):
""" x.__pos__() <==> +x """
pass def __pow__(self, y, z=None):
""" 幂,次方 """
""" x.__pow__(y[, z]) <==> pow(x, y[, z]) """
pass def __radd__(self, y):
""" x.__radd__(y) <==> y+x """
pass def __rand__(self, y):
""" x.__rand__(y) <==> y&x """
pass def __rdivmod__(self, y):
""" x.__rdivmod__(y) <==> divmod(y, x) """
pass def __rdiv__(self, y):
""" x.__rdiv__(y) <==> y/x """
pass def __repr__(self):
"""转化为解释器可读取的形式 """
""" x.__repr__() <==> repr(x) """
pass def __str__(self):
"""转换为人阅读的形式,如果没有适于人阅读的解释形式的话,则返回解释器课阅读的形式"""
""" x.__str__() <==> str(x) """
pass def __rfloordiv__(self, y):
""" x.__rfloordiv__(y) <==> y//x """
pass def __rlshift__(self, y):
""" x.__rlshift__(y) <==> y<<x """
pass def __rmod__(self, y):
""" x.__rmod__(y) <==> y%x """
pass def __rmul__(self, y):
""" x.__rmul__(y) <==> y*x """
pass def __ror__(self, y):
""" x.__ror__(y) <==> y|x """
pass def __rpow__(self, x, z=None):
""" y.__rpow__(x[, z]) <==> pow(x, y[, z]) """
pass def __rrshift__(self, y):
""" x.__rrshift__(y) <==> y>>x """
pass def __rshift__(self, y):
""" x.__rshift__(y) <==> x>>y """
pass def __rsub__(self, y):
""" x.__rsub__(y) <==> y-x """
pass def __rtruediv__(self, y):
""" x.__rtruediv__(y) <==> y/x """
pass def __rxor__(self, y):
""" x.__rxor__(y) <==> y^x """
pass def __sub__(self, y):
""" x.__sub__(y) <==> x-y """
pass def __truediv__(self, y):
""" x.__truediv__(y) <==> x/y """
pass def __trunc__(self, *args, **kwargs):
""" 返回数值被截取为整形的值,在整形中无意义 """
pass def __xor__(self, y):
""" x.__xor__(y) <==> x^y """
pass denominator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
""" 分母 = 1 """
"""the denominator of a rational number in lowest terms""" imag = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
""" 虚数,无意义 """
"""the imaginary part of a complex number""" numerator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
""" 分子 = 数字大小 """
"""the numerator of a rational number in lowest terms""" real = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
""" 实属,无意义 """
"""the real part of a complex number""" int python2.7
python2.7
class int(object):
"""
int(x=0) -> integer
int(x, base=10) -> integer Convert a number or string to an integer, or return 0 if no arguments
are given. If x is a number, return x.__int__(). For floating point
numbers, this truncates towards zero. If x is not a number or if base is given, then x must be a string,
bytes, or bytearray instance representing an integer literal in the
given base. The literal can be preceded by '+' or '-' and be surrounded
by whitespace. The base defaults to 10. Valid bases are 0 and 2-36.
Base 0 means to interpret the base from the string as an integer literal.
>>> int('0b100', base=0)
"""
def bit_length(self): # real signature unknown; restored from __doc__
""" 返回表示该数字的时占用的最少位数 """
"""
int.bit_length() -> int Number of bits necessary to represent self in binary.
>>> bin(37)
'0b100101'
>>> (37).bit_length()
"""
return 0 def conjugate(self, *args, **kwargs): # real signature unknown
""" 返回该复数的共轭复数 """
""" Returns self, the complex conjugate of any int. """
pass @classmethod # known case
def from_bytes(cls, bytes, byteorder, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__
"""
int.from_bytes(bytes, byteorder, *, signed=False) -> int Return the integer represented by the given array of bytes. The bytes argument must be a bytes-like object (e.g. bytes or bytearray). The byteorder argument determines the byte order used to represent the
integer. If byteorder is 'big', the most significant byte is at the
beginning of the byte array. If byteorder is 'little', the most
significant byte is at the end of the byte array. To request the native
byte order of the host system, use `sys.byteorder' as the byte order value. The signed keyword-only argument indicates whether two's complement is
used to represent the integer.
"""
pass def to_bytes(self, length, byteorder, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__
"""
int.to_bytes(length, byteorder, *, signed=False) -> bytes Return an array of bytes representing an integer. The integer is represented using length bytes. An OverflowError is
raised if the integer is not representable with the given number of
bytes. The byteorder argument determines the byte order used to represent the
integer. If byteorder is 'big', the most significant byte is at the
beginning of the byte array. If byteorder is 'little', the most
significant byte is at the end of the byte array. To request the native
byte order of the host system, use `sys.byteorder' as the byte order value. The signed keyword-only argument determines whether two's complement is
used to represent the integer. If signed is False and a negative integer
is given, an OverflowError is raised.
"""
pass def __abs__(self, *args, **kwargs): # real signature unknown
""" abs(self) """
pass def __add__(self, *args, **kwargs): # real signature unknown
""" Return self+value. """
pass def __and__(self, *args, **kwargs): # real signature unknown
""" Return self&value. """
pass def __bool__(self, *args, **kwargs): # real signature unknown
""" self != 0 """
pass def __ceil__(self, *args, **kwargs): # real signature unknown
"""
整数返回自己
如果是小数
math.ceil(3.1)返回4
"""
""" Ceiling of an Integral returns itself. """
pass def __divmod__(self, *args, **kwargs): # real signature unknown
""" 相除,得到商和余数组成的元组 """
""" Return divmod(self, value). """
pass def __eq__(self, *args, **kwargs): # real signature unknown
""" Return self==value. """
pass def __float__(self, *args, **kwargs): # real signature unknown
""" float(self) """
pass def __floordiv__(self, *args, **kwargs): # real signature unknown
""" Return self//value. """
pass def __floor__(self, *args, **kwargs): # real signature unknown
""" Flooring an Integral returns itself. """
pass def __format__(self, *args, **kwargs): # real signature unknown
pass def __getattribute__(self, *args, **kwargs): # real signature unknown
""" Return getattr(self, name). """
pass def __getnewargs__(self, *args, **kwargs): # real signature unknown
pass def __ge__(self, *args, **kwargs): # real signature unknown
""" Return self>=value. """
pass def __gt__(self, *args, **kwargs): # real signature unknown
""" Return self>value. """
pass def __hash__(self, *args, **kwargs): # real signature unknown
""" Return hash(self). """
pass def __index__(self, *args, **kwargs): # real signature unknown
""" 用于切片,数字无意义 """
""" Return self converted to an integer, if self is suitable for use as an index into a list. """
pass def __init__(self, x, base=10): # known special case of int.__init__
""" 构造方法,执行 x = 123 或 x = int(10) 时,自动调用,暂时忽略 """
"""
int(x=0) -> integer
int(x, base=10) -> integer Convert a number or string to an integer, or return 0 if no arguments
are given. If x is a number, return x.__int__(). For floating point
numbers, this truncates towards zero. If x is not a number or if base is given, then x must be a string,
bytes, or bytearray instance representing an integer literal in the
given base. The literal can be preceded by '+' or '-' and be surrounded
by whitespace. The base defaults to 10. Valid bases are 0 and 2-36.
Base 0 means to interpret the base from the string as an integer literal.
>>> int('0b100', base=0)
# (copied from class doc)
"""
pass def __int__(self, *args, **kwargs): # real signature unknown """ int(self) """
pass def __invert__(self, *args, **kwargs): # real signature unknown
""" ~self """
pass def __le__(self, *args, **kwargs): # real signature unknown
""" Return self<=value. """
pass def __lshift__(self, *args, **kwargs): # real signature unknown
""" Return self<<value. """
pass def __lt__(self, *args, **kwargs): # real signature unknown
""" Return self<value. """
pass def __mod__(self, *args, **kwargs): # real signature unknown
""" Return self%value. """
pass def __mul__(self, *args, **kwargs): # real signature unknown
""" Return self*value. """
pass def __neg__(self, *args, **kwargs): # real signature unknown
""" -self """
pass @staticmethod # known case of __new__
def __new__(*args, **kwargs): # real signature unknown
""" Create and return a new object. See help(type) for accurate signature. """
pass def __ne__(self, *args, **kwargs): # real signature unknown
""" Return self!=value. """
pass def __or__(self, *args, **kwargs): # real signature unknown
""" Return self|value. """
pass def __pos__(self, *args, **kwargs): # real signature unknown
""" +self """
pass def __pow__(self, *args, **kwargs): # real signature unknown
""" Return pow(self, value, mod). """
pass def __radd__(self, *args, **kwargs): # real signature unknown
""" Return value+self. """
pass def __rand__(self, *args, **kwargs): # real signature unknown
""" Return value&self. """
pass def __rdivmod__(self, *args, **kwargs): # real signature unknown
""" Return divmod(value, self). """
pass def __repr__(self, *args, **kwargs): # real signature unknown
""" Return repr(self). """
pass def __rfloordiv__(self, *args, **kwargs): # real signature unknown
""" Return value//self. """
pass def __rlshift__(self, *args, **kwargs): # real signature unknown
""" Return value<<self. """
pass def __rmod__(self, *args, **kwargs): # real signature unknown
""" Return value%self. """
pass def __rmul__(self, *args, **kwargs): # real signature unknown
""" Return value*self. """
pass def __ror__(self, *args, **kwargs): # real signature unknown
""" Return value|self. """
pass def __round__(self, *args, **kwargs): # real signature unknown
"""
Rounding an Integral returns itself.
Rounding with an ndigits argument also returns an integer.
"""
pass def __rpow__(self, *args, **kwargs): # real signature unknown
""" Return pow(value, self, mod). """
pass def __rrshift__(self, *args, **kwargs): # real signature unknown
""" Return value>>self. """
pass def __rshift__(self, *args, **kwargs): # real signature unknown
""" Return self>>value. """
pass def __rsub__(self, *args, **kwargs): # real signature unknown
""" Return value-self. """
pass def __rtruediv__(self, *args, **kwargs): # real signature unknown
""" Return value/self. """
pass def __rxor__(self, *args, **kwargs): # real signature unknown
""" Return value^self. """
pass def __sizeof__(self, *args, **kwargs): # real signature unknown
""" Returns size in memory, in bytes """
pass def __str__(self, *args, **kwargs): # real signature unknown
""" Return str(self). """
pass def __sub__(self, *args, **kwargs): # real signature unknown
""" Return self-value. """
pass def __truediv__(self, *args, **kwargs): # real signature unknown
""" Return self/value. """
pass def __trunc__(self, *args, **kwargs): # real signature unknown
""" Truncating an Integral returns itself. """
pass def __xor__(self, *args, **kwargs): # real signature unknown
""" Return self^value. """
pass denominator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
"""the denominator of a rational number in lowest terms""" imag = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
"""the imaginary part of a complex number""" numerator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
"""the numerator of a rational number in lowest terms""" real = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
"""the real part of a complex number""" python3.5
python3.5
2.2.1.2 长整型long:
python2.*:
跟C语言不同,Python的长整型没有指定位宽,也就是说Python没有限制长整型数值的大小,
但是实际上由于机器内存有限,所以我们使用的长整型数值不可能无限大。
在使用过程中,我们如何区分长整型和整型数值呢?
通常的做法是在数字尾部加上一个大写字母L或小写字母l以表示该整数是长整型的,例如:
a = 9223372036854775808L
注意,自从Python2起,如果发生溢出,Python会自动将整型数据转换为长整型,
所以如今在长整型数据后面不加字母L也不会导致严重后果了。 python3.*
长整型,整型统一归为整型
python2.7
>>> a=9223372036854775807
>>> a
>>> a+=1
>>> a
9223372036854775808L python3.5
>>> a=9223372036854775807
>>> a
>>> a+=1
>>> a 查看
查看
2.2.1.3 布尔bool:
True 和False
1和0
2.2.1.4 浮点数float:
Python的浮点数就是数学中的小数,类似C语言中的double。
在运算中,整数与浮点数运算的结果是浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,
一个浮点数的小数点位置是可变的,比如,1.23*109和12.3*108是相等的。
浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,
就必须用科学计数法表示,把10用e替代,1.23*109就是1.23e9,或者12.3e8,0.000012
可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的而浮点数运算则可能会有
四舍五入的误差。
2.2.1.5 复数complex:
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注意,虚数部分的字母j大小写都可以,
>>> 1.3 + 2.5j == 1.3 + 2.5J
True
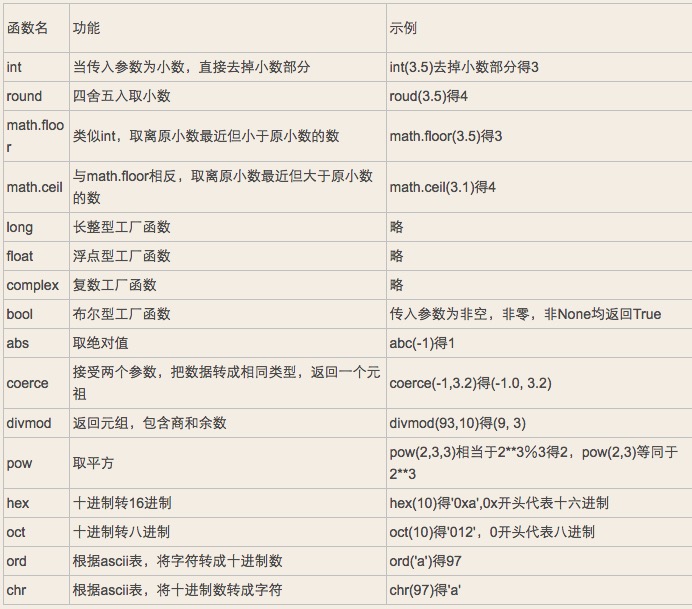
2.2.1.6 数字相关内建函数
2.2.2 字符串
定义:它是一个有序的字符的集合,用于存储和表示基本的文本信息,‘’或“”或‘’‘ ’‘’中间包含的内容称之为字符串
特性:
1.只能存放一个值
2.不可变
3.按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序
补充:
1.字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r'l\thf'
2.unicode字符串与r连用必需在r前面,如name=ur'l\thf'
2.2.2.1 字符串创建
‘hello world’
2.2.2.2 字符串常用操作
移除空白
分割
长度
索引
切片
2.2.2.3 字符工厂函数str()
方法:
1.capitalize() 首字母大写
2.casefold() 大写字母转小写(更牛逼,不仅仅适用于英文字母的大小写转换,也适用于欧洲其他国家字母大小写转换)
** 3.lower() 字母大写转小写(普通英文字母转换)
islower() 判断变量的值是否全部是小写
** 4.upper() 小写改大写
isupper() 判断是否是大写
5.count(“n”,3,6) 在第3至第6个字符中,计算字符n在变量中出现的次数,3,6可以省略,只保留 count("n")
6.encode 后期讲
7.decode 后期讲
8.endswith('a') 判断变量是否以a字母结尾,如果正确返回 True ,错误返回 False
9.startswith('a') 判断变量是否以a字母开头,如果正确返回 True ,错误返回 False
*** 10.find('a',5,8) 变量中查找字符‘a’在变量中第一个出现的位置,(注意:第一个字符从0开始数)从第5个字符开始到第8个字符结束,如果结果是-1,表示没有找到
index() 判断字符所在字符串中的位置 a = 'abc'
v = a.index('b')
print(v) 11.format(name='zhangsan',age=30) 格式化,将字符串中占位符替换为指定的值,举例:
a = 'I am {name},age is {age}'
v = a.format(name = 'zhangsan', age = 30)
print(v) 如果占位符位置按顺序用0,1,2...替代,则format中直接按顺序用值替换即可
b = 'I am {0},age is {1}'
v = a.format('zhangsan',30)
print(v) 12.isalnum() 判断变量是否只包含字母和数字,如是返回True,否,返回False
13.expandtabs(6) 表示变量以6个一组,如果该组内没有tab,则略过,如有tab,则该组tab前面的字符+tab为6个字符,去掉tab前面的字符个数,表示tab所占用的空格数量
a = 'zhangsan\thi'
v = a.expandtabs(6)
print(v,len(v))
----------------
zhangsan hi 14 制作表格,循环提示用户输入用户名、密码,邮箱(不能超过20个字符),如果用户输入q或Q,表示不再继续输入,打印用户输入的结果:
s = ''
while True:
v1 = input("请输入用户名:")
if v1.lower() == 'q':
break
v2 = input("请输入密码:")
v3 = input("请输入邮箱:")
template = "{0}\t{1}\t{2}\n"
v = template.format(v1,v2,v3)
s += v
print(s.expandtabs(20)) 常用于格式化输出:
test = "username\temail\tpassword\nlaiying\tying@q.com\t123\nlaiying\tying@q.com\t123\nlaiying\tying@q.com\t123"
v = test.expandtabs(20)
print(v)
-------------------------
username email password
laiying ying@q.com 123
laiying ying@q.com 123
laiying ying@q.com 123 14.isalpha() 变量中是否只包含字母,汉字也算,如是返回True,否,返回False
15.isdecimal() 判断变量的值是否是数字,仅可识别标准数字
16.isdigit() 判断变量的值是否是数字,可以识别一些特殊的数字,比如②
17.isidentifier() 判断变量是否符合变量名标准 判断用户输入的字母和数字中,有多少个字母和数字
c1 = 0
c2 = 0
val = input(">>>")
for item in val:
# item是数字
if item.isdecimal():
c1 += 1 # 如果item是字母
if item.isalpha():
c2 += 1
print("总数字是:" + str(c1))
print("总字母是:" + str(c2)) *** 18.strip 删除变量左右两侧的空格,移除换行\n,\t,另外还可以去除指定的字符x strip('xyz'),而且,xyz出现在变量中,可以不分顺序,只要包含即可删除,下面同
lstrip 删除变量左侧的空格,移除换行\n,\t
rstrip 删除变量右侧的空格,移除换行\n,\t
19.isdecimal() 识别数字(仅是阿拉伯数字)
20.isdigit() 识别数字(含数字符号,如②)
21.isnumeric() 识别数字(所有数字,如二,②,Ⅱ,贰)
22.isprintable() 是否包含不可见的字符(包含:\n,\t,结果为False)
23.isspace() 判断变量是否全是空格
24.istitle() 判断标题首字母是否是大写,如一句话含多个单词,每个单词首字母要均为大写
** 25.title() 标题首字母全部更改为大写
****26.join(text) 字符串每个字符按照指定分隔符拼接 text = '你是风儿我是沙'
print(text)
v = '_'.join(text)
print(v) 27.center(20,"*") 20个字符宽度,变量名居中,左右两侧以*填充,仅限一个字符,默认空格填充,可以省略
28.ljust(20,*) 20个字符宽度,变量名居左,右侧以*填充,仅限一个字符,默认空格填充,可以省略
29.rjust(20,*) 20个字符宽度,变量名居右,左侧以*填充,仅限一个字符,默认空格填充,可以省略
30.zfill(20) 在变量的左侧用0填充,不可以用其他字符
31.maketrans() 字符串替换
translate()
a = 'abcd'
b = ''
text = 'nihaoma?nizaiganma?'
temp = str.maketrans(a,b)
new_text = text.translate(temp)
print(new_text)
32.partition('x') 默认从左侧找到第一个x进行3份切割,x自身元素可以拿到
rpartition('x') 从右侧找到第一个x进行3份切割,x自身元素可以拿到
*** split('x',2) 字符串切割,本身字符拿不到,2为切分几次,x自身元素不可以拿到
rsplit('x',2) 从右侧字符串切割,本身字符拿不到,2为切分几次,x自身元素不可以拿到
splitlines() 分割换行,值可以是True,False表示是否保留换行 加法计算器:(如 10 + 5)
temp = input("Please input numbers:")
v = temp.split('+')
# print(v)
t1 = int(v[0])
t2 = int(v[1])
f = t1 + t2
print(f) 33.startswith('a') 判断是否以a开头
endswith('a') 判断是否以a结尾
34.swapcase() 大小写转换
35.replace() 替换字符串
用aaa替换变量a中的字符a,替换出现的第一个a,可以省略后面的1,表示全部替换
a = 'zhang'
v = a.replace('a', 'aaa', 1)
print(v) 敏感词替换,用***代替用户输入的苍老师,东京热
v = input(">>>")
v = v.replace('苍老师', '***')
v = v.replace('东京热', '***')
print(v) 必须要记住8个基本方法
-----------------------
join
split
find
strip
upper
lower
title
len
replace
字符串方法
2.2.3 列表
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
特性:
1.可存放多个值
2.可修改指定索引位置对应的值,可变
3.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序
2.2.3.1 列表创建
list_test=[’lhf‘,12,'ok']
或
list_test=list('abc')
或
list_test=list([’lhf‘,12,'ok'])
2.2.3.2 列表常用操作
索引
切片
追加
删除
长度
切片
循环
包含
2.2.3.3 列表工厂函数list()
在列表中添加元素:
在列表末尾添加元素:
在列表中添加新元素时,最简单的方式是将元素附加到列表末尾,给列表附加元素时,它将添加到列表末尾
bicycles.append("meituan")
print(bicycles)
方法append()将元素“meituan”添加到列表末尾,而不影响列表中其他所有元素
方法append()让动态地创建列表易如反掌,例如,先创建一个空列表,再使用一系列的append()语句添加元素,下面我们实际操作一下:
bicycles = []
bicycles.append("ofo")
bicycles.append("mobai")
bicycles.append("youjiu")
bicycles.append("didi")
print(bicycles) 在列表中插入元素:
使用方法insert()可在列表中任何位置添加新元素,为此,你需要将指定新元素的索引和值
bicycles.insert(0,"fenghuang")
print(bicycles) 在这个示例中,将值“fenghuang”插入到列表开头,方法insert在索引0处添加空间,并将值“fenghuang”存储到这个地方,这种操作将列表中既有的每个元素都右移一个位置
['fenghuang', 'ofo', 'mobai', 'youjiu', 'didi'] 清空列表:
方法:clear() 清空列表所有值
a.clear() 浅拷贝:
仅拷贝列表第一层级
方法:copy()
v = a.copy() 深拷贝:
改变列表里第二层级对象,深拷贝后的列表更改不影响原始列表
import copy
b = [[1, 2], 'a', 'b', 'c', 1, 2, 3]
c=copy.deepcopy(b)
c[0][1]=222
print(b)
print(c) 计算元素出现的个数:
方法:count()
a = ['zhsng', 'li', 'wang']
v = a.count('li')
print(v) 扩展原列表(追加可迭代(for循环)对象):
目前可循环对象:字符串,列表,元组,字典(数字不可以循环)
a = ['zhsng', 'li', 'wang']
a.extend([123, 'abc'])
print(a)
-----------------------------
['zhsng', 'li', 'wang', 123, 'abc'] 查询列表元素索引位置:
index() (从前往后找,找到第一个就不再继续往下找,如果需要,可以指定起始位置进行精确查找) a = ['zhsng', 'li', 'wang']
v = a.index('li')
print(v) a = ['zhsng', 'li', 'wang', 'li']
v = a.index('li', 2, 4)
print(v) 从列表中删除元素:
经常需要从列表中删除一个或多个元素,例如:玩家将空中的一个外星人射杀后,你很可能要将其从存活的外星人列表中删除,当用户在你创建的web应用中注销其账户时,你需要将该用户从活跃
用户列表中删除,你可以根据位置或值来删除列表中的元素 使用del语句删除元素:
如果知道要删除的元素在列表中的位置,可以使用del语句
del bicycles[1]
print(bicycles)
['fenghuang', 'mobai', 'youjiu', 'didi'] 此例删除了列表中第二个元素
使用del可以删除任何位置的列表元素,条件是知道其索引
使用del语句删除列表元素,以后就无法再访问它了 使用方法pop()删除元素:
有时候,你要将元素删除后,并接着使用它的值。例如:你可能需要获取刚被射杀的外星人的x和y坐标,比便在相应的位置显示爆炸效果,在web应用程序中,你可能将用户从活跃成员列表中删除,将其添加到非活跃成员中
方法pop()可删除列表末尾的元素,并让你能够接着使用它,pop源自这样的类比,列表就像一个栈,而删除列表末尾的元素相当于弹出栈顶元素
bicycles = []
bicycles.append("ofo")
bicycles.append("mobai")
bicycles.append("youjiu")
bicycles.append("didi")
print(bicycles)
poped_bicycle = bicycles.pop()
print(bicycles)
print(poped_bicycle)
------------------------------------------------
['ofo', 'mobai', 'youjiu', 'didi']
['ofo', 'mobai', 'youjiu']
didi 弹出列表中任何位置的元素
实际上,你可以使用pop()来删除列表中任何位置的元素,只需在括号中指定要删除的元素索引即可
别忘了,每当你使用pop()时,被弹出的元素就不在列表中了 如果你不确定该使用del语句还是pop()方法时,下面是一个简单的判断标准:
如果你要从列表中删除一个元素,且不再以任何方式使用它,就使用del语句,如果你要在删除元素后还能继续使用它,就使用方法pop() 根据值删除元素:
有时候,你不知道要从列表中删除的值所处的位置,如果你只知道要删除的元素的值,你可以使用方法remove()
使用remove()从列表中删除元素时,也可以使用它的值,
例如:我们要从列表bicycles中删除值“yongjiu”
bicycles = ['meituan', 'fenghuang', 'yongjiu', 'didi']
print(bicycles)
too_expensive = "yongjiu"
bicycles.remove(too_expensive)
print(bicycles)
print("\nA " + too_expensive.title() + "is too expensive for me!" "")
-----------------------------------
['meituan', 'fenghuang', 'yongjiu', 'didi']
['meituan', 'fenghuang', 'didi'] A Yongjiuis too expensive for me! 注意:方法remove()只删除第一个指定的值,如果要删除的值可能在列表中出现多次,就需要使用循环来判断是否删除了所有这样的值 组织列表: 创建的列表中,元素的排列顺序常常时无法预测的,因为你并非总能控制用户提供的数据顺序,这虽然在大多数情况下不可避免,但你经常需要以特定的顺序呈现信息
有时候,你希望保留列表元素最初的排列顺序,而有时候又需要调整排列顺序,python提供了很多组织列表的方式,可根据具体情况选用 字符,字母(大小写),数字排序按照ASCII特码从小到大排序
字符 < 数字 < 大写字母 < 小写字母 sort()
使用方法sort()对列表永久性排序,再也无法恢复到原来的排列顺序了:
bicycles = ['meituan', 'fenghuang', 'yongjiu', 'didi']
print(bicycles)
bicycles.sort()
print(bicycles)
----------------------------
['meituan', 'fenghuang', 'yongjiu', 'didi']
['didi', 'fenghuang', 'meituan', 'yongjiu'] 还可以按与字母顺序相反的顺序排列列表元素,为此,只需要向sort()方法传递参数 reverse=True ,同样,对列表元素排列顺序时永久性的 bicycles = ['meituan', 'Fenghuang', 'Yongjiu', 'didi']
print(bicycles)
bicycles.sort()
print(bicycles)
bicycles.sort(reverse=True)
print(bicycles)
-------------------------------
['meituan', 'Fenghuang', 'Yongjiu', 'didi']
['Fenghuang', 'Yongjiu', 'didi', 'meituan']
['meituan', 'didi', 'Yongjiu', 'Fenghuang'] sorted()
要保留列表元素原来的排列顺序,同时以特定的顺序呈现他们,可使用函数 sorted(),它能让你按特定的顺序显示列表元素,同时不影响他们在列表中的原始排列顺序 bicycles = ['meituan', 'Fenghuang', 'Yongjiu', 'didi']
print(bicycles)
print(sorted(bicycles))
print(bicycles)
-----------------------------
['meituan', 'Fenghuang', 'Yongjiu', 'didi']
['Fenghuang', 'Yongjiu', 'didi', 'meituan']
['meituan', 'Fenghuang', 'Yongjiu', 'didi'] 先进行原始排序,再进行特定顺序显示列表,最后再次核实,确认列表的排列顺序与以前相同(print(sorted(bicycles)) 仅当条排序语句生效) 注意:调用函数sorted()后,列表元素的排列顺序并没有变,如果你要按照与字母顺序相反,显示列表,也可以向函数sorted() 传递参数 reverse=True 倒着打印列表:
要反转列表元素的排列顺序,可使用方法reverse()
bicycles = ['meituan', 'Fenghuang', 'Yongjiu', 'didi']
print(bicycles)
bicycles.reverse()
print(bicycles)
--------------------------
['meituan', 'Fenghuang', 'Yongjiu', 'didi']
['didi', 'Yongjiu', 'Fenghuang', 'meituan'] 注意:reverse()不是按照与字母顺序相反的顺序排列列表元素,而只是反转列表元素的排列顺序
方法reverse()永久性地修改列表元素的排列顺序,但可随时恢复到原来的排列顺序,为此只需对列表再次调用reverse()即可 确定列表的长度:
使用函数len()可快速的获悉列表的长度,在你需要完成如下任务时,len()很有用,确定还有多少外星人未被射杀,需要管理多少项可视化数据,网站有多少注册用户等
bicycles = ['meituan', 'Fenghuang', 'Yongjiu', 'didi']
print(bicycles)
print(len(bicycles))
---------------------
['meituan', 'Fenghuang', 'Yongjiu', 'didi']
4 注意:python计算列表元素时从1开始,因此确定列表长度时,你应该不会遇到差一错误 使用列表时避免索引错误:
刚开始使用列表时,经常会遇到一种错误,假设你有一个包含4个元素的列表,却要求获取第五个元素
bicycles = ['meituan', 'Fenghuang', 'Yongjiu', 'didi']
print(bicycles[4])
------------------------
Traceback (most recent call last):
File "/root/python/ex1/py1.py", line 10, in <module>
print(bicycles[4])
IndexError: list index out of range 鉴于列表索引差一特征,这种错误很常见,有些人从1开始数,因此以为第4个元素的索引是4,但在python中,第四个元素的索引是3,因为索引是从0开始的
索引错误意味着python无法理解你指定的索引,在程序发生错误时,请尝试将你指定的索引减一,然后再次运行,看看结果是否正确 别忘了,每当需要访问最后一个元素时,都可以使用索引-1,这在任何情况下都行之有效,即便你最后一次访问列表后,其长度发生了变化
bicycles = ['meituan', 'Fenghuang', 'Yongjiu', 'didi']
print(bicycles[-1])
-----------------------------
didi 索引-1总是返回最后一个列表元素,仅当列表为空时,这种访问最后一个元素的方式才会导致错误:
car = []
print(car[-1])
------------------
Traceback (most recent call last):
File "/root/python/ex1/py1.py", line 12, in <module>
print(car[-1])
IndexError: list index out of range 注意:发生索引错误却找不到解决办法时,请尝试将列表或其长度打印出来,列表可能与你以为的截然不同,在程序对其进行了动态处理时尤其如何,通过查看列表或其包含的元素,可帮助你找出这种逻辑错误 操作列表: 遍历整个列表:
经常需要遍历列表的所有元素,对每个元素执行相同的操作,可以使用for循环
举例:使用for循环遍历朋友的姓名
names = ['zhangsan', 'lisi', 'wangwu']
for name in names:
print(name) for循环:
循环是让计算机自动完成重复工作的常见方式之一
for name in names:
这行代码让python获取列表names中的第一个值(‘zhangsan’),并将其存储到变量name中(相当于还是要先给name变量赋值),解下来,python读取下一行代码
print(name)
它让python打印name的值,依然是‘zhangsan’,鉴于该列表还包含其他值,python返回循环的第一行
for name in names:
python获取列表中的下一个名字‘lisi’,并将其存储到变量name中,再执行打印下面的print(name)代码
接下来,python再次执行整个循环,对列表最后一个值‘wangwu’进行处理,至此,列表没有其他值了,因此python接着执行下一行代码,在这个示例中
for循环后面没有其他代码,因此程序就此结束了 刚开始使用循环时请牢记,对列表中的每个元素,都将执行循环指定的步骤,而不管列表包含多少元素,如果列表包含一百万个元素,python就重复执行指定的步骤一百万次,且通常速度非常快
另外,编写for循环时,对于用于存储列表中每个值的临时变量,可指定任何名称,然后,选择描述单个列表元素的有意义名称大有帮助
例如:
for cat in cats:
for dog in dogs:
for item in items:
这些命名约定有助于你明白for循环中将对每个元素执行的操作,使用单数和复数式名称,可帮助你判断代码段处理的是单个列表元素还是整个列表 在for循环中执行更多的操作
names = ['zhangsan', 'lisi', 'wangwu']
for name in names:
print(name.title() + ", You are my friend!")
print('Welcome to my home' + ": " + name.title()) 在for循环中,想包含多少行代码都可以,在代码 for name in names 后面,每个缩进的代码行都是循环的一部分,且将对列表中的每个值都执行一次
实际上你会发现使用for循环对每个元素执行众多不同的操作很有用 在for循环结束后执行一些操作:
在for循环后面,没有缩进的代码只执行一次,而不会重复执行
使用for循环处理数据是一种对数据集执行整体操作的不错方式 避免缩进错误:
python根据缩进来判断代码行与前一个代码行的关系,当你开始编写必须正确缩进代码时,需要注意一些缩进错误: 忘记缩进:对于for语句后面且属于循环组成部分的代码行,一定要缩进 忘记缩进额外的代码行:有时候,循环能够运行而不会报错,但结果可能会出乎意料,这通常是一个逻辑错误,从语法上,这些代码是合法的,但由于存储逻辑错误,结果并不符合预期 不必要的缩进:如果不小心缩进了无需缩进的代码行,python将指出这一点,为了避免意外错误,请只缩进需要缩进的代码 循环后不必要的缩进:如果你不小心缩进了应在循环结束后执行的代码,这些代码将针对每个列表元素重复执行,在有些情况下,这可能导致报告语法错误,但在大多数情况下,这只会导致逻辑错误 遗漏了冒号:for语句结尾的冒号告诉python,下一行是循环的第一行,如果你不小心遗漏了冒号,将导致语法错误 创建数字列表; 列表非常适合用于储存数字集合,而python提供了很多工具,可以帮助你高效地处理数字列表
使用函数range()
python函数range()让你能够轻松地生成一系列数字
for value in range(1, 5):
print(value)
--------------------
1
2
3
4
在这个示例中,range()只是打印数字1-4,这是你在编程语言中经常看到的差一行为的结果
函数range()让python从你指定的第一个值开始数,并在到达你指定的第二个值后停止,因此输出不包含第二值(这里是5)
要打印数字1-5,需要使用range(1,6)
使用range()时,如果输出不符合预期,请尝试将指定的值加1或减一 使用range()创建数字列表:
要创建数字列表,可以使用函数list()将range()的结果直接转换为列表,如果将range()作为list()的参数,输出将是一个数字列表
numbers = list(range(1, 6))
print(type(numbers), numbers)
-----------------------------------
<class 'list'> [1, 2, 3, 4, 5] 使用函数range()时,还可以指定步长,例如打印1-10内的偶数
numbers = list(range(2, 11, 2))
print(type(numbers), numbers)
------------------------------
<class 'list'> [2, 4, 6, 8, 10] 使用函数range()几乎能够创建任何需要的数字集,例如,创建一个1-10数字平方的列表
numbers = []
for number in range(1, 11):
seq = number ** 2
numbers.append(seq)
print(numbers)
-------------------------
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100] 为了让这些代码更简洁,可以不使用临时变量,而直接将每个计算得到的值附加到列表末尾
numbers = []
for number in range(1, 11):
numbers.append(number ** 2)
print(numbers)
------------------------------
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
创建更复杂的列表时,可使用上述两种方法中的任何一种,有时候,使用临时变量会让代码更易读,而在其他情况下,这样做只会让代码无谓地变长,
你首先应该考虑的是,编写清晰易懂且能完成所需功能的代码,等到审核代码时,再考虑采用更高效的方法 对数字列表进行简单的统计计算
有几个专门用于处理数字列表的函数:
min()
max()
sum() numbers = []
for number in range(1, 11):
numbers.append(number ** 2)
print(numbers)
print(min(numbers))
print(max(numbers))
print(sum(numbers))
----------------------------
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
1
100
385 1-100求和
numbers = []
for number in range(1,101):
numbers.append(number)
print(sum(numbers))
---------------------------
5050 列表解析:
前面介绍生成列表的方式包含了三四行代码,而列表解析让你只需编写一行代码就能生成这样的列表,列表解析将for循环和创建新元素的代码合并成一行,并自动附加新元素,这里for循环语句末尾没有冒号:
numbers = [temp ** 2 for temp in range(1, 11)]
print(numbers)
---------------------
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100] 要创建自己的列表解析,需要经过一定的练习,但能够熟练地创建常规列表后,你会发现这样做是完全值得的,当你觉得编写三四行代码来生成列表有点繁琐时,就应该考虑列表解析了 使用列表的一部分: 切片 要创建切片,可指定要使用的第一个元素的索引和最后一个元素的索引加1,与函数range()一样,python在到达你指定的第二个索引前面的元素后停止,要输出列表中的前三个元素,需要指定索引0-3,这将输出分别为0,1,2的元素
numbers = [temp - 1 for temp in range(1, 11)]
print(numbers[0:3])
---------------------
[0, 1, 2] 如果你没有指定第一个索引,python将自动从列表开头开始:
numbers = [temp - 1 for temp in range(1, 11)]
print(numbers[:5])
---------------------
[0, 1, 2, 3, 4] 要将切片终止于列表末尾,也可以使用类似的语法:
numbers = [temp - 1 for temp in range(1, 11)]
print(numbers[8:])
--------------------
[8, 9] 无论列表有多长,这种语法都能够让你输出从特定位置到列表末尾的所有元素,前面说过,负数索引返回离列表末尾相应距离的元素,因此你可以输出列表末尾的任何切片
numbers = [temp - 1 for temp in range(1, 11)]
print(numbers[-3:])
-------------------------
[7, 8, 9] 遍历切片
如果要遍历列表的部分元素,可以在for循环中使用切片,下面的例子,我们遍历了前三名队员,并打印了他们的名字,这里我们并没有遍历整个队员的列表,而只是遍历前三名
names = ['zhangsan', 'lisi', 'wangwu', 'zhouliu']
for name in names[:3]:
print(name)
-------------------------------
zhangsan
lisi
wangwu 在很多情况下,切片都很有用,例如:在编写游戏时,你可以在玩家退出游戏时将其最终得分加入到一个列表中,然后,为获取该玩家的三个最高得分,你可以将该列表按降序排列,再创建一个只包含前三个得分
的切片。在处理数据时,可使用切片来进行批量处理,编写web应用程序时,可使用切片来分页显示信息,并在每页显示数量合适的信息 复制列表
你经常需要根据既有列表创建全新的列表,要复制列表,可创建一个包含完整列表的切片,方法是同时省略起始索引和终止索引([:]),这让python创建一个始于第一个元素,终止于最后一个元素的切片,即复制整个列表
my_goods = ['pizza', 'cake', 'fala']
friend_goods = my_goods[:]
print(my_goods)
print(friend_goods)
-------------------------
['pizza', 'cake', 'fala']
['pizza', 'cake', 'fala'] 验证:向每个列表各添加了一种食品
my_goods = ['pizza', 'cake', 'fala']
friend_goods = my_goods[:]
my_goods.append('coffer')
friend_goods.append('ice')
print(my_goods)
print(friend_goods)
----------------------
['pizza', 'cake', 'fala', 'coffer']
['pizza', 'cake', 'fala', 'ice'] 这里不能使用赋值的方法将 my_goods赋值给 friend_goods,因为这两个列表都指向了同一个列表,并不是完全独立的两个列表 注意:现在暂时不要考虑这个示例中的细节,基本上,当你试图使用列表的副本时,如果结果出乎意料,请确认你像第一个示例那样使用切片复制了列表
列表方法
2.2.4 元组
定义:与列表类似,只不过[]改成()
特性:
1.可存放多个值
2.不可变
3.按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
2.2.4.1 元组创建
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
2.2.4.2 元组常用操作
索引
切片
循环
长度
包含
2.2.4.3 元组工厂函数tuple()
2.2.5 字典
定义:{key1:value1,key2:value2},key-value结构,key必须可hash
特性:
1.可存放多个值
2.可修改指定key对应的值,可变
3.无序
2.2.5.1 字典创建
person = {"name": "sb", 'age': 18}
或
person = dict(name='sb', age=18)
person = dict({"name": "sb", 'age': 18})
person = dict((['name','sb'],['age',18]))
{}.fromkeys(seq,100) #不指定100默认为None
注意:
>>> dic={}.fromkeys(['k1','k2'],[])
>>> dic
{'k1': [], 'k2': []}
>>> dic['k1'].append(1)
>>> dic
{'k1': [1], 'k2': [1]}
2.2.5.2 字典常用操作
索引
新增
删除
键、值、键值对
循环
长度
2.2.5.3 字典工厂函数dict()
6.2使用字典
在python中,字典是一系列键值对,每个键都与一个值相关联,你可以使用健来访问与之关联的值。与健相关的值可以是数字、字符串、列表乃至字典,事实上,可将任何python对象用做字典中的值
在python中,字典放在花括号中一系列键值对表示,键值对是两个相关的值,指定键时,返回相关联的值,键和值之间用冒号分隔,而键值对之间用逗号分隔,在字典中,想存储多少个键值对都可以
最简单的字典只有一个键值对
name_0 = {'zhangsan':20} 6.2.1访问字典中的值
要获取与键相关联的值,可依次指定字典名和放在方括号内的键
name_0 = name_0['zhangsan'] 6.2.2添加键值对
字典是一种动态结构,可随时在其中添加键值对,要添加键值对,可依次指定字典名、用方括号括起来的键和相关联的值
name_0['lisi'] = 30
name_0['wangwu'] = 35
print(name_0)
--------------------
{'zhangsan': 20, 'lisi': 25, 'wangwu': 30} 注意:键值对的排列顺序与添加顺序不同,python不关心键值对添加的顺序,而只关心键和值之间的关联关系 6.2.3先创建一个空字典
有时候,在空字典中添加键值对是为了方便,而有时候必须这样做,为此,可先使用一对空的花括号定义一个字典,再分行添加各个键值对
使用字典来存储用户提供的数据或在编写能自动生成大量键值对的代码,通常都需要先定义一个空字典
定义一个空的字典:my_dict = {} 或 my_dict = dict() di = dict()
di['name0'] = 'zhangsan'
print(di['name0'])
print(di) 6.2.4修改字典中的值
要修改字典中的值,可依次指定字典名、用方括号括起来的键以及与该键相关联的新值
di['name0'] = 'zhangsan' 6.2.5删除键值对
对于字典中不再需要的信息,可使用del语句将相应的键值对彻底删除,使用del语句时,必须指定字典名和要删除的键
删除与这个键相关联的值,输出表明'name0'已从字典删除,但其他键值对未受到影响
del di['name0'] 注意:删除的键值对永远消失了 6.2.6由类似对象组成的字典
在前面的示例中,字典存储的是一个对象的多种信息,但你也可以使用字典来存储众多对象的同一种信息
例如:假设你要调查很多人,询问他们最喜欢的编程语言,可使用一个字典来存储这种简单的调查结果
favorite_language = {
'zhangsan': 'python',
'lisi': 'java',
'wangwu': 'python',
'zhouliu': 'javascript',
}
print(favorite_language) 正如你看到的,我们将一个较大的字典放在了多行中,其中每个键都是一个被调查者的名字,而每个值都是被调查者喜欢的语言,确定需要使用多行来定义字典时,在输入左括号后按回车
键,再在下一行缩进四个空格,指定第一个键值对,并在后面加上一个逗号,此后你再次按回车键时,文本编辑器,将自动缩进后续键值对,且缩进量与第一个键值对相同
定义好字典后,在最后一个键值对的下一行添加一个右花括号,并缩进四个空格,使其与字典中的键对齐,另外一种不错的做法是在最后一个键值对后面也加上逗号,为以后在下一行添加键值对做好准备 注意:对于较长的列表和字典,大多数编辑器都有类似方式设置其格式的功能,对于较长的字典,还有其他一些可行的格式设置方式 下面为较长的print语句格式,单词print比大多数字典名都短,因此让输出的第一部分紧跟在左括号后面是合理的,请选择在合适的地方拆分要打印的内容,并在第一行末尾加上一个拼接运算符 + 按回车
进入print语句后续各行,并使用tab键将他们对齐缩进一级,指定要打印的内容,在print语句的最后一行末尾加上右括号 print("Zhang san favorite language is " +
favorite_language['zhangsan'] +
".") 6.3遍历字典
一个python字典可能只包含几个键值对,也可能包含数百万个键值对, *** 6.3.1遍历所有键值对
可以使用for循环来遍历字典,要编写用于遍历字典的for循环,可申请两个变量,用于存储键值对中的键和值
对于这两个变量,可使用任何名称: favorite_language = {
'zhangsan': 'python',
'lisi': 'java',
'wangwu': 'python',
'zhouliu': 'javascript',
}
for key, value in favorite_language.items():
print("\nKey:" + key)
print("Value:" + value) for语句的第二部分包含字典名和方法 items() 它返回一个键值对列表,接下来,for循环依次将每个键值对存储到指定的两个变量中,第一条print语句中的"\n"确保输出的每个键值对前都插入一个空行 注意:即使遍历字典时,键值对的返回顺序也与存储顺序不同,python不关心键值对的存储顺序,而只是跟踪键和值之间的关联关系 *** 6.3.2遍历字典中所有的键
在不需要使用字典中的值时,方法keys()很有用 favorite_language = {
'zhangsan': 'python',
'lisi': 'java',
'wangwu': 'python',
'zhouliu': 'javascript',
}
for key in favorite_language.keys():
print(key.title()) 遍历字典时,会默认遍历所有的键,因此,如果将上述代码中的 for key in favorite_language.keys() 替换为 for key in favorite_language: 输出不变
如果显式地使用方法keys()可让代码更容易理解,方法keys()并非只能用于遍历,实际上,它将返回一个列表,其中包含字典中所有键 6.3.3按顺序遍历字典中所有键
字典总是明确地记录键和值之间的关联关系,但获取字典元素时,获取顺序是不可预测的,这不是问题,因为通常你想要的只是获取和键相关联的正确的值
要以特定的顺序返回元素,一种办法是在for循环中对返回的键进行排序,为此,可使用函数 sorted() 来获得按特定顺序排列的键列表的副本
for key in sorted(favorite_language.keys()):
print(key.title()) di1={'zhangsan': 200, 'wangwu': 100, 'zhouliu': 300}
for k in sorted(di1.keys()):
print(k)
print(di1[k])
-----------------------
wangwu
100
zhangsan
200
zhouliu
300 函数sorted()在遍历前对列表进行排序,输出表明,按顺序显示了所有被调查的名字 *** 6.3.4遍历字典中所有的值
如果你感兴趣的是字典中包含的值,可以使用方法 values(),它返回一个值列表,而不包含任何键 for value in sorted(favorite_language.values()):
print("Values:" + value) 这种做法提取字典中所有的值,而没有考虑是否重复,涉及的值很少时,这不是问题,但如果被调查者很多,最终的列表可能包含大量的重复项,为剔除重复项,可以使用集合 set ,集合类似于列表,但每个元素必须是独一无二的: for value in sorted(set(favorite_language.values())):
print("Value:" + value)
----------------------------
Value:java
Value:javascript
Value:python 通过对包含重复元素的列表调用set() 可让python找出列表独一无二的元素,并使用这些元素来创建一个集合 方法: 1.clear() 清空字典
info = {
'k1': 'v1',
'k2': 'v2',
}
print(info)
v = info.clear()
print(v)
---------
{'k1': 'v1', 'k2': 'v2'}
None 2.copy() 浅拷贝 3.fromkeys() 根据第一个参数创建一个新字典,根据第二个参数设置新字典统一值
# 例如,创建一个所有人都是25岁的字典
di = dict.fromkeys(['zhangsan','lisi','wangwu'],25)
print(di) *** 4.get('key','default vlaue') 根据第一个键参数,从字典获取值,如果该键不存在,则返回第二个参数默认值
info = {
'k1': 'v1',
'k2': 'v2',
}
v1 = info.get('k1',888)
v2 = info.get('k3',888)
print(v1)
print(v2)
-----------------------
v1
888 5.pop('key','default value') 移除字典里的键值,如果键不存在,可以返回默认值,并可以获取被删除键的值
info = {
'k1': 'v1',
'k2': 'v2',
}
v1 = info.pop('k1')
v2 = info.pop('k3',888)
print(info)
print(v1)
print(v2)
---------------
{'k2': 'v2'}
v1
888 6.popitem() 随机删除字典里的键值对,并获取值
k, v = info.popitem()
print(k, v) 7.setdefault('key','default value') 设置值,如果键key已存在,则原有值不变,并取得原有值,如果key在字典中不存在,则增加新的键值对,并取得新值
v = info.setdefault('k3', 'v3')
print(info)
print(v)
-------------
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
v3 *** 8.update() 更新字典
info.update(k1='v1', k3=123, k10='abc')
print(info)
---------------------
{'k1': 'v1', 'k2': 'v2', 'k3': 123, 'k10': 'abc'} 9.enumerate(dic, 1) 序号
dic = {'a': 1, 1: 123, ('a', 'b'): 'hello'}
for k, v in enumerate(dic, 1):
print(k, v)
-------------------
1 a
2 1
3 ('a', 'b')
字典方法
2.2.6 集合
定义:由不同元素组成的集合,集合中是一组无序排列的可hash值,可以作为字典的key
特性:
1.集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
2.2.6.1 集合创建
{1,2,3,1}
或
定义可变集合set
>>> set_test=set('hello')
>>> set_test
{'l', 'o', 'e', 'h'}
改为不可变集合frozenset
>>> f_set_test=frozenset(set_test)
>>> f_set_test
frozenset({'l', 'e', 'h', 'o'})
2.2.6.2 集合常用操作:关系运算
in
not in
==
!=
<,<=
>,>=
|,|=:合集
&.&=:交集
-,-=:差集
^,^=:对称差分
se1 = {'zhangsan', 'lisi', 'wangwu', 'zhangsan8'}
se2 = {'zhangsan', 'lisi', 'zhouliu', 'kim'}
for s in se1:
print(s)
#
# print('zhangsan' in se1)
# print(se1 == se2)
# 集合交集
se3 = se1.intersection(se2)
# se3 = se1 & se2
print(se3)
# 集合并集
se4 = se1.union(se2)
# se4 = se1 | se2
print(se4)
# 集合se1 和 se2的差集
se5 = se1.difference(se2)
# se5=se1 - se2
print(se5)
# 集合se2 和 se1的差集
se6 = se2.difference(se1)
# se6=se2-se1
print(se6)
# 集合子集
se7 = se1.issubset(se2)
print(se7)
# 集合父集
se8 = se1.issuperset(se2)
print(se8)
# 集合交叉补集
se9 = se1.symmetric_difference(se2)
# se9 = se1 ^ se2
print(se9)
2.2.6.3 集合工厂函数set()
集合的基本操作:
1.添加元素
s.add( x )
# 将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作
se10 = se1.add('add1')
print(se1)
s.update( x )
x 可以有多个,用逗号分开,如果是一组字符串,则会把字符串中的每个字符作为一个元素添加到集合中
se11 = se1.update('add2')
print(se1)
2.删除元素
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误
s.remove( x )
se12 = se1.remove('zhangsan8')
print(se1)
s.discard( x )
移除集合中的元素,且如果元素不存在,不会发生错误
se13=se1.discard('zhangsan9')
print(se1)
s.pop()
随机删除集合中的一个元素
多次执行测试结果都不一样
然而在交互模式,pop 是删除集合的第一个元素(排序后的集合的第一个元素)
集合的排序
sorted(se1)
se16=sorted(se1)
print(se16)
3.计算集合的个数
len(s)
se18=len(se1)
print(se18)
4.清空集合
se1.clear()
print(se1)
-----------
set()
5.判断元素是否在集合中存在
x in s
判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False
se19 = 'add1' in se1
print(se19)
---------------
True
集合内置方法完整列表:
方法 描述
add() 为集合添加元素
clear() 移除集合中的所有元素
copy() 拷贝一个集合
difference() 返回多个集合的差集
difference_update() 移除集合中的元素,该元素在指定的集合也存在。
discard() 删除集合中指定的元素
intersection() 返回集合的交集
intersection_update() 删除集合中的元素,该元素在指定的集合中不存在。
isdisjoint() 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
issubset() 判断指定集合是否为该方法参数集合的子集。
issuperset() 判断该方法的参数集合是否为指定集合的子集
pop() 随机移除元素
remove() 移除指定元素
symmetric_difference() 返回两个集合中不重复的元素集合。
symmetric_difference_update() 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
union() 返回两个集合的并集
update() 给集合添加元素
2.2.7 bytes类型
定义:存8bit整数,数据基于网络传输或内存变量存储到硬盘时需要转成bytes类型,字符串前置b代表为bytes类型
>>> x
'hello sb'
>>> x.encode('gb2312')
b'hello sb'
2.2.8 数据类型转换内置函数汇总
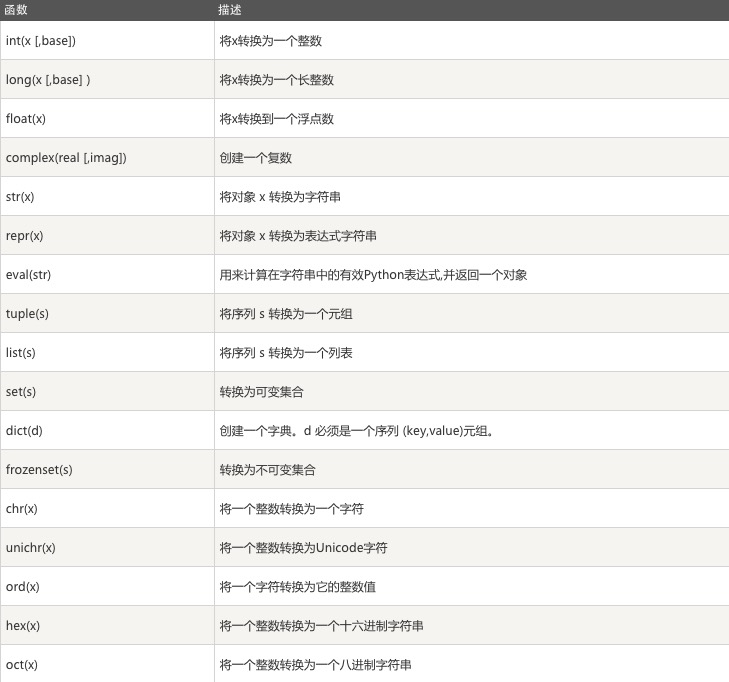
注:真对acsii表unichr在python2.7中比chr的范围更大,python3.*中chr内置了unichar
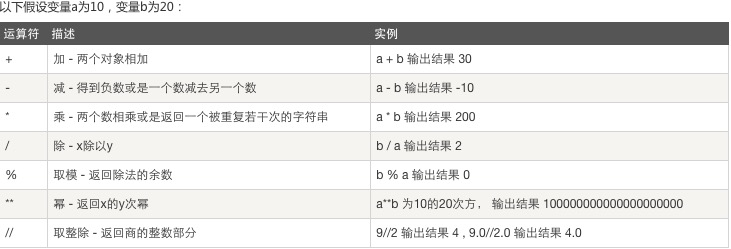
三.运算符
2、比较运算:

3、赋值运算:
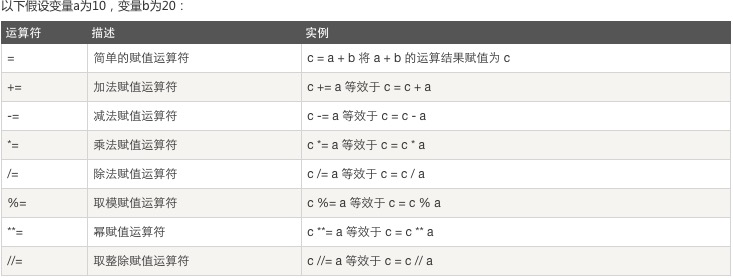
4、位运算:
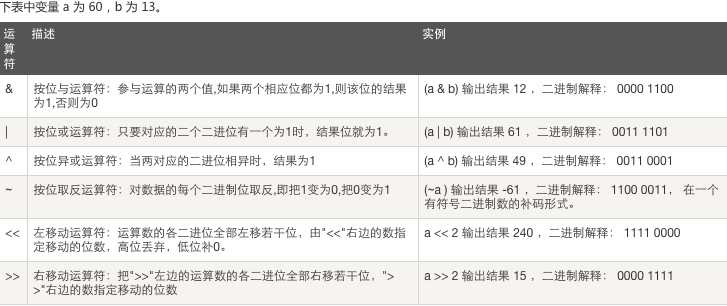
注: ~ 举例: ~5 = -6 解释: 将二进制数+1之后乘以-1,即~x = -(x+1),-(101 + 1) = -110
按位反转仅能用在数字前面。所以写成 3+~5 可以得到结果-3,写成3~5就出错了
5、逻辑运算:

and注解:
- 在Python 中,and 和 or 执行布尔逻辑演算,如你所期待的一样,但是它们并不返回布尔值;而是,返回它们实际进行比较的值之一。
- 在布尔上下文中从左到右演算表达式的值,如果布尔上下文中的所有值都为真,那么 and 返回最后一个值。
- 如果布尔上下文中的某个值为假,则 and 返回第一个假值
or注解:
- 使用 or 时,在布尔上下文中从左到右演算值,就像 and 一样。如果有一个值为真,or 立刻返回该值
- 如果所有的值都为假,or 返回最后一个假值
- 注意 or 在布尔上下文中会一直进行表达式演算直到找到第一个真值,然后就会忽略剩余的比较值
and-or结合使用:
- 结合了前面的两种语法,推理即可。
- 为加强程序可读性,最好与括号连用,例如:
(1 and 'x') or 'y'
6、成员运算:

7.身份运算

8.运算符优先级:自上而下,优先级从高到低
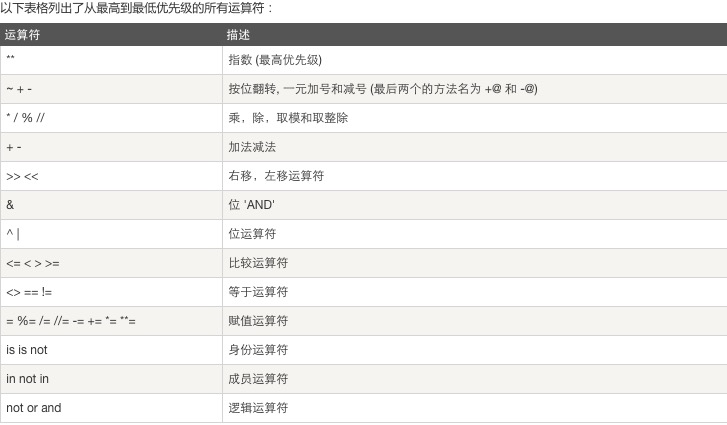
四.标准数据类型特性总结
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
| 不可变 | 数字,字符串,元组 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
python基础知识4--数据类型与变量的更多相关文章
- 01-Java基础知识:数据类型与变量、标识符、运算符、表达式
Java基础知识:数据类型与变量.标识符.运算符.表达式 一.数据类型 Java定义了基本数据类型.引用数据类型.自定义类型. 八种基本数据类型:byte (1). short (2). int ( ...
- python基础知识-01-编码输入输出变量
python其他知识目录 名词解释: 编辑器 ide 程序员 操作系统 ASCAII码 unicode utf-8 浅谈CPU.内存.硬盘之间的关系 操作系统及Python解释器工作原理讲解 关于编译 ...
- python基础知识之数据类型
一.与用户的交互 古时候,我们去银行取钱,需要有一个银行业务员等着我们把自己的账号密码输入给他, 然后他去进行验证,成功后,我们再将取款金额输入/告诉他 骄傲的现代人,会为客户提供一台ATM机(就是一 ...
- python基础知识(七)---数据类型补充、"雷区"、编码
数据类型补充."雷区".编码 1.数据类型补充 str: #字符串数据类型补充 s1=str(123) #常用于类型转换 print(s1) #capitalize()首字母大写 ...
- 漫漫Java路1—基础知识3—数据类型和变量作用域以及常量
强类型语言 所有变量定义后才能使用,区别于js等弱类型语言 数据类型分类 基本类型(primitive type) 引用类型(reference type) 整数类 byte:占1字节 short:占 ...
- 第二章(1.5)Python基础知识(数据类型)
一.list(列表) list是一种有序的集合,可以随时添加和删除其中的元素 用len()函数可以获得list元素的个数 列表操作包含以下函数: cmp(list1, list2):比较两个列表的元素 ...
- Python 基础知识(一)
1.Python简介 1.1.Python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时 ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
- python基础知识小结-运维笔记
接触python已有一段时间了,下面针对python基础知识的使用做一完整梳理:1)避免‘\n’等特殊字符的两种方式: a)利用转义字符‘\’ b)利用原始字符‘r’ print r'c:\now' ...
随机推荐
- stand up
#version_s#1.7#version_e# #update_s#https://files.cnblogs.com/files/dyh221/update.zip#update_e#
- mysql_pconnect 问题
不同于mysql_connect的短连接,mysql_pconnect持久连接的时候,将先尝试寻找一个在同一个主机上用同样的用户名和密码已经打开的(持久)连接,如果找到,则返回此连接标识而不打开新连接 ...
- nginx 配置 同一域名端口下,根据URL 导向不同的项目目录
我们现在拥有2个项目.但是只有一个域名,通过nginx配置来实现以下url导向不同的项目. 后台管理台:{域名}/admin 用户客户端:{域名}/client server { listen 888 ...
- mysql数据库的备份
有时会遇到需要重装虚拟机的情况,这时候之前创建好的数据库就需要备份啦,等重新装好虚拟机直接导入就可以正常使用. 数据库备份大体分为两步: 第一步.导出数据库,因为是备份,会将所有的数据库导出,因此需要 ...
- ios 传递JSON串过去 前面多了个等号
先说下我的问题 后台让我这边把请求的参数弄成一个实体转化成 json 串放body里传给他,当然header也有设置,提前设置好了, 但是后来了解 所谓的把实体转成json串的本质就是先把实体用run ...
- xterm配置
最近转到i3wm桌面下, 发现调用xfce4-terminal有些慢,索性卸载掉一切所谓高级的终端,使用xterm,其实这个才是更牛的家伙. 安装 apt install xterm in i3-wm ...
- AJ的笔记之上拉电阻的工作原理分析
第二章:聊一聊上拉电阻的工作原理 **********本文所采用的单片机是:STC89C52RC系******************** [重点提要]其实,理解上拉电阻的原理,关键是理解这两个词:锁 ...
- 百战程序员——Spring框架
什么是容器,我们学过了哪些容器,Spring与我们之前学习的容器有哪些异同点? 容器可以管理对象的生命周期.对象与对象之间的依赖关系,您可以使用一个配置文件(通常是XML),在上面定义好对象的名称.如 ...
- H5视频直播扫盲
H5视频直播扫盲 2016-05-25 • 前端杂项 • 14 条评论 • lvming19901227 视频直播这么火,再不学就out了. 为了紧跟潮流,本文将向大家介绍一下视频直播中的基本流程和主 ...
- android studio连接真机大概问题
首先,确定手机Android的版本(最好用统一版本) 版本一样的话错误会少一点... 手机打开开发者选项(每个手机不同,百度可查) 开发者选项中打开USB调试 点击OK,可以进入Android mon ...