Spark环境搭建(三)-----------yarn环境搭建及测试作业提交
配置好HDFS之后,接下来配置单节点的yarn环境
1,修改配置文件
文件 : /root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/yarn-site-xml
插入
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
文件: /root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/mapred-site.xml
插入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2,启动yarn
命令: sbin/start.yarn.sh
3,验证yarn启动成功
1) 命令:jps
显示
7945 Jps
6227 SecondaryNameNode
6060 DataNode
5745 NameNode
5031 NodeManager
4922 ResourceManager
2) 浏览器:
http://hadoop001:8088/
4,提交作业到yarn执行(以wordcount为例)
1) 现将一个文本文件上传到HDFS中
2)执行一个Jar文件,使用命令
hadoop jar /home/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /data/wc-text.txt /output/wc/
3) 使用浏览器查看任务
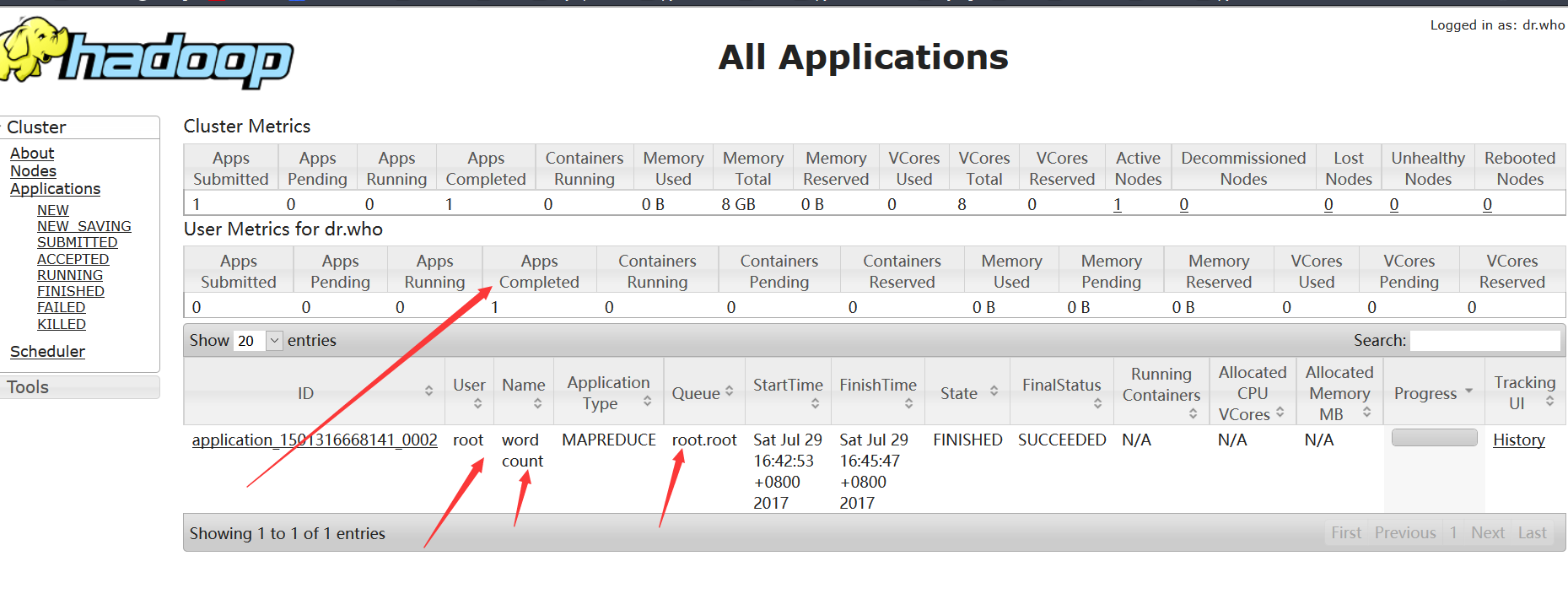
4)在HDFS中查看结果
命令: hadoop fs -ls -R /
hadoop fs -cat /output/wc/part-r-00000
5)结果:

原文件:

至此,yarn环境搭建完毕
Spark环境搭建(三)-----------yarn环境搭建及测试作业提交的更多相关文章
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建三:配置spring并测试
这一部分的主要目的是 配置spring-service.xml 也就是配置spring 并测试service层 是否配置成功 用IntelliJ IDEA 开发Spring+SpringMVC+M ...
- Java学习笔记之linux配置java环境变量(三种环境变量)
0x00 压安装jdk 在shell终端下进入jdk-6u14-linux-i586.bin文件所在目录, 执行命令 ./jdk-6u14-linux-i586.bin 这时会出现一段协议,连继敲回车 ...
- 【源码学习之spark core 1.6.1 standalone模式下的作业提交】
说明:个人原创,转载请说明出处 http://www.cnblogs.com/piaolingzxh/p/5656876.html 未完待续
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(2 配置spring-dao和测试)
用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(1 搭建目录环境和依赖) 四:在\resources\spring 下面 ...
- 通过IDEA搭建scala开发环境开发spark应用程序
一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安装scala插件,具体安装办法如下. 1.打开idea,点击c ...
- IDEA搭建scala开发环境开发spark应用程序
通过IDEA搭建scala开发环境开发spark应用程序 一.idea社区版安装scala插件 因为idea默认不支持scala开发环境,所以当需要使用idea搭建scala开发环境时,首先需要安 ...
- Spark开发环境搭建和作业提交
Spark高可用集群搭建 在所有节点上下载或上传spark文件,解压缩安装,建立软连接 配置所有节点spark安装目录下的spark-evn.sh文件 配置slaves 配置spark-default ...
- 搭建Data Mining环境(Spark版本)
前言:工欲善其事,必先利其器.倘若不懂得构建一套大数据挖掘环境,何来谈Data Mining!何来领悟“Data Mining Engineer”中的工程二字!也仅仅是在做数据分析相关的事罢了!此文来 ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
随机推荐
- vue实战记录(二)- vue实现购物车功能之创建vue实例
vue实战,一步步实现vue购物车功能的过程记录,课程与素材来自慕课网,自己搭建了express本地服务器来请求数据 作者:狐狸家的鱼 本文链接:vue实战-实现购物车功能(二) GitHub:sue ...
- cogs2479 偏序(CDQ套CDQ)
题目链接 思路 四维偏序 \(CDQ\)套\(CDQ\),第一维默认有序.第二维用第一个\(CDQ\)变成有序的.并且对每个点标记上第一维属于左边还是右边.第二个\(CDQ\)处理第三维,注意两个\( ...
- 启动多个logstash脚本
一台服务器上启动多个logstash脚本 # more logstash_click #!/bin/sh # Init script for logstash # Maintained by Elas ...
- js检测移动设备并跳转到相关适应页面。
PS:网页自适应的方式有多种.有通过CSS样式表来实现自适应(主流),也有通过显示不同的页面来实现的方式. 下面代码是记录通过判断设备特征来跳转到相关的页面的方法. 实现要求: 当手机,平板访问 a. ...
- Python“函数式编程”中常用的函数
1.map(func,seq[,seq,...]) 对序列中的每个元素应用函数,python2中map()返回的是列表,python3中返回的是迭代器,可以用list()转换成列表.以下例子为pyth ...
- C++中数组作为形参进行传递(转)
有两种传递方法,一种是function(int a[]); 另一种是function(int *a) 这两种两种方法在函数中对数组参数的修改都会影响到实参本身的值! 对于第一种,根据之前所学,形参是实 ...
- 🍓 DOM常用基础知识点汇总(入门者适用) 🍓
铛-今天又没啥事,来总结一下DOM的基础知识.(公司没活干我也很无奈
- audio autoplay 是pause 不会停止播放
$("#alarmWav").append( $('<audio id="alarmAudio" autoplay loop src="../j ...
- jsp注释<%-- --%>和<!-- -->的区别
最近在写JSP页面注释的时候,遇到一个问题,在JSP页面引用的静态属性资源文件时,在浏览器控制台报错,当我把引用的标签注释掉后,用的是<!-- -->.然后浏览器仍然报了之前那个错,经过查 ...
- Alpha 事后诸葛亮(团队)
前言 事后诸葛亮?作业名真的不好听,下一届还要沿用吗? 队名:小白吃 通向hjj博客的任意门 思考总结 设想和目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? ...