Breastcancer社区评论下载
首页
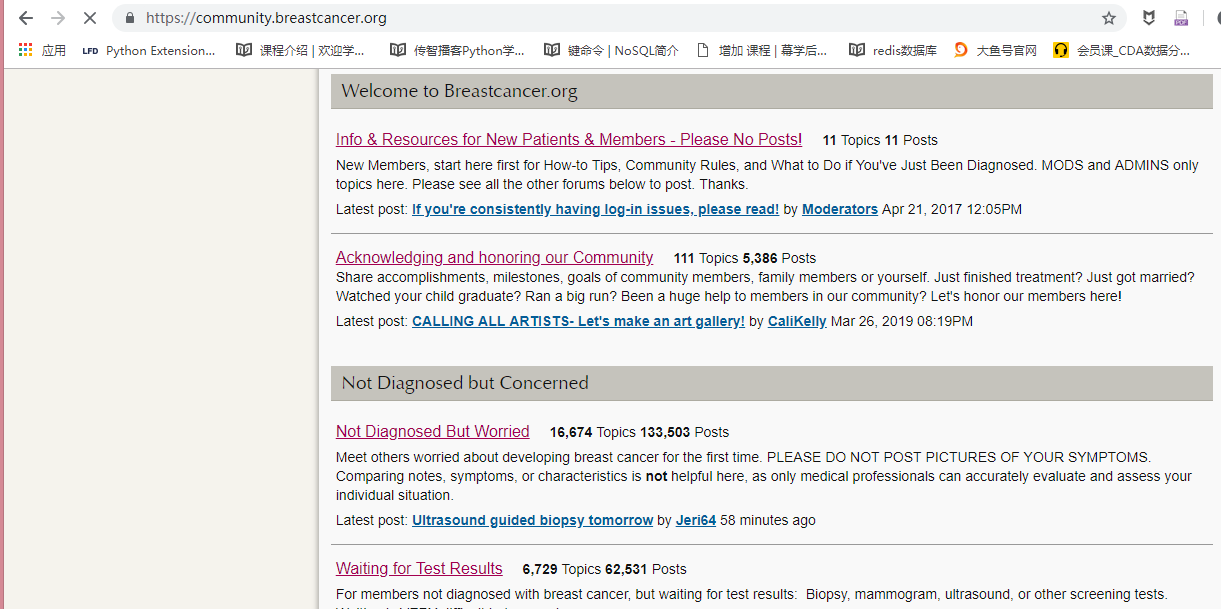
某个社区
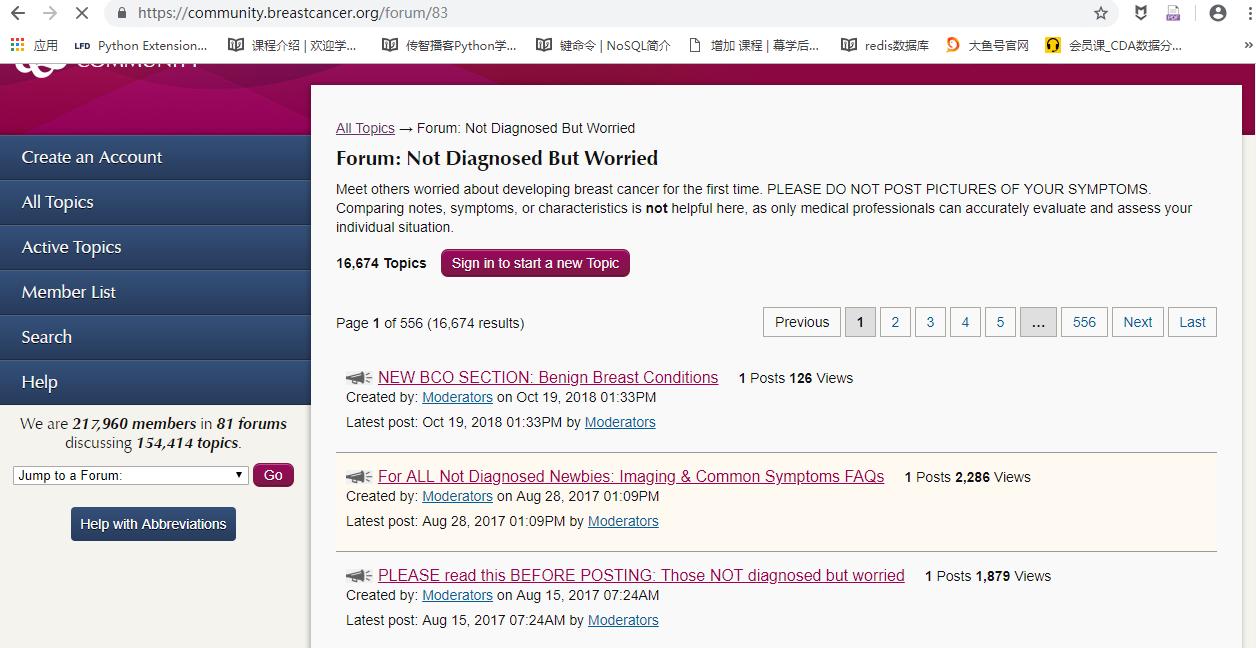
某社区的一个话题
目标:获取这个网站所有话题的所有评论相关信息
python实现
# -*- coding: utf-8 -*- """
@Datetime: 2019/3/17
@Author: Zhang Yafei
"""
import functools
import os
import re
import traceback
import time
from concurrent.futures import ThreadPoolExecutor, wait, as_completed, ProcessPoolExecutor
from itertools import chain
from urllib.request import urljoin import pandas as pd
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options # 控制台输出所有列
pd.set_option('display.max_columns', None) forum_info = pd.read_csv('all_forum_info.csv') def timeit(fun):
@functools.wraps(fun)
def wrapper(*args, **kwargs):
start_time = time.time()
res = fun(*args, **kwargs)
print('运行时间为%.6f' % (time.time() - start_time))
return res return wrapper class Download(object):
""" 请求的下载 """ def __init__(self, url):
self.url = url
self.forum_topic = '【{}】'.format(forum_info[forum_info.forum_url == url[0]].forum_topic.values[0])
self.dir_path = os.path.join('download', self.forum_topic).replace('/', '-').replace(',', '').replace(':', '-').replace('"', '')
if not os.path.exists(self.dir_path):
os.mkdir(self.dir_path)
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.browser = None
self.dispatch(pool=True) def dispatch(self, pool=True):
""" 下载所有社区页面 """
topic_count = int(self.url[1].replace(',', ''))
pages = divmod(topic_count, 30)[0] + 1
remain_pages = self.filter_url(pages)
urls = [self.url[0] + '?page={}'.format(page) for page in remain_pages]
# [self.forum_start(urls), list(map(self.forum_start, self.url))][len(self.url) > 1
if urls and pool:
pool = ThreadPoolExecutor(max_workers=4)
pool.map(self.forum_start, urls, timeout=60)
pool.shutdown()
elif urls:
list(map(self.forum_start, urls))
else:
print(self.dir_path + '共需下载{}页'.format(pages) + '\t下载完成') def filter_url(self, pages):
has_pages = list(map(lambda x: int(x.strip('.html')), os.listdir(self.dir_path)))
down_pages = list(set(range(1, pages + 1)) - set(has_pages))
if len(down_pages):
print(self.dir_path + '共需下载:{}页'.format(pages) + ' 已下载:{}页'.format(len(has_pages)) + ' 未下载:{}页'.format(len(down_pages)))
return down_pages def forum_start(self, url, header=False):
if header:
browser = webdriver.Chrome()
else:
browser = webdriver.Chrome(chrome_options=self.chrome_options)
browser.get(url=url)
html = browser.page_source
browser.close()
file_path = os.path.join(self.dir_path, url.split('?page=')[-1] + '.html')
with open(file_path, mode='w', encoding='utf-8') as f:
f.write(html)
print(url + '下载成功') # def close(self):
# self.browser.close() class BreastCancer(object):
""" BreastCancer社区评论下载 """ def __init__(self):
self.base_url = 'https://community.breastcancer.org/'
self.all_forum_columns = ['hgroup', 'forum_topic', 'forum_url', 'count_topic', 'count_post']
self.all_forum_file = 'all_forum_info.csv'
self.all_topic_columns = ['forum', 'topic_url', 'founder', 'count_posts', 'count_views', 'created_time', 'file_path']
self.all_topic_file = 'all_topic_info.csv' if not os.path.exists(self.all_topic_file):
self.write_to_file(columns=self.all_topic_columns, file=self.all_topic_file, mode='w') def download_forums_index(self):
"""
下载社区首页
"""
browser = webdriver.Chrome()
browser.get(url=self.base_url)
html = browser.page_source
with open('download/community.html', mode='w', encoding='utf-8') as f:
f.write(html)
browser.close() def parse_forums_index(self):
""" 解析社区首页 获取所有社区页面id """
# 创建csv文件, 写入表头
if not os.path.exists(self.all_forum_file):
data = pd.DataFrame(columns=self.all_forum_columns)
data.to_csv(self.all_forum_file, index=False)
# 读取html文件,提取有用信息,写入到文件尾部
with open('download/community.html', encoding='utf-8') as f:
response = f.read()
response = etree.HTML(response)
rowgroups = response.xpath('//div[@class="rowgroup"]')
list(map(self.get_all_forums_ids, rowgroups)) def get_all_forums_ids(self, response):
"""
获取所有:
hgroup、
forum_topic(社区主题)、
url(社区页面地址)、
count_topic(话题数量)、
count_post(评论数量)
"""
hgroup = response.xpath('.//h2/text()')[0]
forums = response.xpath('.//li')
data_list = []
for forum in forums:
forum_topic = forum.xpath('h3/a/text()')[0]
forum_url = urljoin('https://community.breastcancer.org/', forum.xpath('h3/a/@href')[0])
count_topic = forum.xpath('.//span[@class="count_topic"]/strong/text()')[0]
count_post = forum.xpath('.//span[@class="count_post"]/strong/text()')[0]
data_dict = {'hgroup': hgroup, 'forum_topic': forum_topic, 'forum_url': forum_url,
'count_topic': count_topic,
'count_post': count_post}
data_list.append(data_dict) df = pd.DataFrame(data=data_list)
# 固定输出列的顺序
df = df.loc[:, self.all_forum_columns]
df.to_csv(self.all_forum_file, index=False, header=False, mode='a')
print(hgroup + '数据解析完成') def get_all_forum_page(self, pool=True):
""" 获取所有社区url 并下载所有社区相关页面 """
df = pd.read_csv(self.all_forum_file)
forum_urls = df.apply(lambda x: (x.forum_url, x.count_topic), axis=1)
if pool:
# 多线程下载
# BreastCancer.thread_pool_download(forum_urls)
# 多进程
BreastCancer.process_pool_download(forum_urls)
else:
# 单线程下载
list(map(Download, forum_urls)) @staticmethod
def thread_pool_download(urls):
""" 多线程下载 """
pool = ThreadPoolExecutor(max_workers=4)
tasks = [pool.submit(Download, url) for url in urls]
wait(tasks)
# pool.map(Download, urls)
pool.shutdown() @staticmethod
def process_pool_download(urls):
""" 多进程下载 """
pool = ProcessPoolExecutor(max_workers=4)
pool.map(Download, urls)
pool.shutdown() def get_topic_info(self, response):
""" 获取所有话题相关信息 """
topic_url = urljoin(self.base_url, response.xpath('./h3/a/@href')[0])
count_posts = response.xpath('./p[1]/span[1]/strong/text()')[0]
count_views = response.xpath('./p[1]/span[2]/strong/text()')[0]
founder = response.xpath('./p[2]/a/text()')[0]
created = response.xpath('./p[2]')[0].xpath('string(.)').replace('\n', '').replace(' ', '')
created_time = re.search('on(.*)', created).group(1)
data_dict = {'topic_url': topic_url, 'founder': founder,
'count_posts': count_posts, 'count_views': count_views,
'created_time': created_time
}
return data_dict @staticmethod
def get_file_path_list(row):
forum_topic = '【{}】'.format(row.forum_topic)
dir_path = os.path.join('download', forum_topic).replace('/', '-').replace(',', '').replace(':', '-').replace(
'"', '')
file_path_list = list(map(lambda file: os.path.join(dir_path, file), os.listdir(dir_path)))
return file_path_list @timeit
def start_parse_forum_page(self, pool=False):
""" 开始解析社区页面 """
file_path_lists = forum_info.apply(BreastCancer.get_file_path_list, axis=1).tolist()
file_path_lists = functools.reduce(lambda x, y: x + y, file_path_lists)
# 每次解析前过滤已解析的页面
file_path_lists = self.filter_file_path(file_path_lists)
if pool:
pool = ThreadPoolExecutor(max_workers=4)
pool.map(self.parse_forum_page, file_path_lists)
pool.shutdown()
else:
list(map(self.parse_forum_page, file_path_lists)) def filter_file_path(self, file_path_list):
parse_file = pd.read_csv(self.all_topic_file).file_path.unique()
file_list = set(file_path_list) - set(parse_file)
print('共{}个页面'.format(len(set(file_path_list))), '\n\r已解析{}个页面'.format(len(set(parse_file))))
return list(file_list) def parse_forum_page(self, file_path):
""" 解析社区页面具体功能实现 """
with open(file_path, encoding='utf-8') as f:
response = f.read()
response = etree.HTML(response)
try:
forum = response.xpath('//div[@id="section-content"]/h1/text()')[0]
forum = re.search('Forum: (.*)', forum).group(1)
topics = response.cssselect('#section-content > ul.rowgroup.topic-list > li')
data_list = list(map(self.get_topic_info, topics))
for data_dict in data_list:
data_dict['forum'] = forum
data_dict['file_path'] = file_path
BreastCancer.write_to_file(data=data_list, file=self.all_topic_file, columns=self.all_topic_columns, mode='a')
print(file_path + '解析完成')
except Exception:
traceback.print_exc()
print(file_path + '解析错误')
return @staticmethod
def write_to_file(file, data=None, columns=None, mode=None, index=False, header=False):
if mode == 'w':
data = pd.DataFrame(columns=columns)
data.to_csv(file, index=False)
elif mode == 'a':
df = pd.DataFrame(data=data)
df = df.loc[:, columns]
df.to_csv(file, mode=mode, index=index, header=header) @staticmethod
def all_forum_stat():
all_hgroup_count = forum_info.hgroup.nunique()
all_forum_count = forum_info.forum_topic.nunique()
all_topic_count = pd.to_numeric(forum_info.count_topic.str.replace(',', ''), downcast='integer').sum()
all_post_count = pd.to_numeric(forum_info.count_post.str.replace(',', ''), downcast='integer').sum()
all_topic_pages = forum_info.apply(lambda x: divmod(int(x.count_topic.replace(',', '')), 30)[0] + 1,
axis=1).sum()
print('共有hgroup:{}个'.format(all_hgroup_count))
print('共有社区:{}个'.format(all_forum_count))
print('共有话题:{}个'.format(all_topic_count))
print('共有评论:{}个'.format(all_post_count))
print('共需下载:{}个页面'.format(all_topic_pages)) if __name__ == '__main__':
breastcancer = BreastCancer()
# breastcancer.all_forum_stat()
# 1. 下载社区首页
# breastcancer.parse_forums_index() # 2. 获取所有社区页面url
# breastcancer.get_all_forums_ids() # 3. 下载所有社区页面
# breastcancer.get_all_forum_page(pool=False) # 4. 解析所有社区页面
breastcancer.start_parse_forum_page()
Breastcancer社区评论下载的更多相关文章
- SQLyog 社区免费版下载
SQLyog 是一个快速而简洁的图形化管理MYSQL数据库的工具,它能够在任何地点有效地管理你的数据库,由业界著名的Webyog公司出品.使用SQLyog可以快速直观地让您从世界的任何角落通过网络来维 ...
- Visual Studio 2015官方汇总包括下载和视频
7月20日 23:30 Visual Studio 2015正式版正式发布,作为微软新一代开发利器,在全地球乃至全宇宙乃至全太阳系中最强大 且没有之一的IDE(上述描述来自微博用户评论)跨平台支持成 ...
- 无需付费,教你IDEA社区版中开发Web项目(SpringBoot\Tomcat)
1.IDEA 版本介绍 最近有小伙伴私信我说 IDEA 破解怎么总是失效?难道就没有使用长一点的吗... 咳咳,除了给我留言「激活码」外,或许社区版可能完全满足你的需求. 相信有挺多小伙伴可能不清楚或 ...
- 应用集成-在Hexo、Hugo博客框架中使用Gitalk基于Github上仓库项目的issue无后端服务评论系统实践
关注「WeiyiGeek」公众号 设为「特别关注」每天带你玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 本章目录 目录 0x00 Gi ...
- ActiveReports 9实战教程(1): 手把手搭建环境Visual Studio 2013 社区版
原文:ActiveReports 9实战教程(1): 手把手搭建环境Visual Studio 2013 社区版 ActiveReports 9刚刚发布3天,微软就发布了 Visual Studio ...
- 搭建环境Visual Studio 2013 社区版
搭建环境Visual Studio 2013 社区版 ActiveReports 9刚刚发布3天,微软就发布了 Visual Studio Community 2013 开发环境. Visual St ...
- VS2017在线安装包下载
VS2017个人免费版即社区官方下载地址为:https://download.microsoft.com/download/D/1/4/D142F7E7-4D7E-4F3B-A399-5BACA91E ...
- iReport 5.6.0 安装包下载&安装
iReport 5.6.0 下载 方式有两种: 1.在官网社区上下载,下载地址:https://community.jaspersoft.com/project/ireport-designer/re ...
- 微信web开发者工具、破解文件、开发文档和开发Demo下载
关注,QQ群,微信应用号社区 511389428 下载: Win: https://pan.baidu.com/s/1bHJGEa Mac: https://pan.baidu.com/s/1slhD ...
随机推荐
- LeetCode算法题-Maximum Depth of N-ary Tree(Java实现)
这是悦乐书的第261次更新,第274篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第128题(顺位题号是559).给定n-ary树,找到它的最大深度.最大深度是从根节点到 ...
- 【Python 05】Python开发环境搭建
Python3安装和使用 1.安装 Python管方下载地址 选择Customize installation安装,并且勾选Add Python 3.X to PATH. 勾选Documentatio ...
- 【Python 03】程序设计与Python语言概述
人生苦短,我用Python. Python在1990年诞生于荷兰,2010年Python2发布最后一版2.7,Python核心团队计划在2020年停止支持 Python2,目前Python3是未来. ...
- java.util.NoSuchElementException问题定位
Iterator 迭代器越界 例子如下: Iterator i = set.iterator(); while (i.hasNext()) { System.out.println(i.next()) ...
- ESP8266产品ID
ESP.getChipId() https://github.com/espressif/arduino-esp32/blob/master/libraries/ESP32/examples/Chip ...
- GRE与VXLAN
一 GRE 1.1 概念 GRE全称是Generic Routing Encapsulation,是一种协议封装的格式,具体格式内容见:https://tools.ietf.org/html/rfc2 ...
- Spring Security Oauth2 的配置
使用oauth2保护你的应用,可以分为简易的分为三个步骤 配置资源服务器 配置认证服务器 配置spring security 前两点是oauth2的主体内容,但前面我已经描述过了,spring sec ...
- java常识
什么是java语言? java语言是美国Sun公司,在1995年推出的高级编程语言.所谓编程语言,是计算机的语言,人们可以使用编程语言对计算机下达命令,让计算机完成人们需要的功能. java语言发展历 ...
- MySQL RPM二进制安装
+++++++++++++++++++++++++++++++++++++++++++标题:MySQL RPM二进制安装时间:2019年2月24日内容:MySQL RPM二进制安装重点:MySQL R ...
- OracleSql语句学习(一)
--SQL语句本身是不区分大小写的,每个关键字用空格隔开,为了增加可读性,退出所有关键字--全部大写,非关键字都小写SELECT SYSDATE FROM dual--创建表CREATE TABLE ...