Java基于opencv—矫正图像
更多的时候,我们得到的图像不可能是正的,多少都会有一定的倾斜,就比如下面的
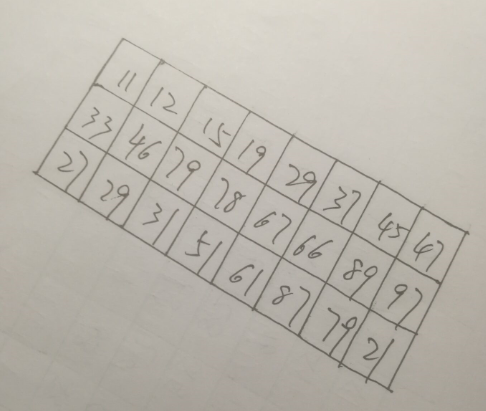
我们要做的就是把它们变成下面这样的
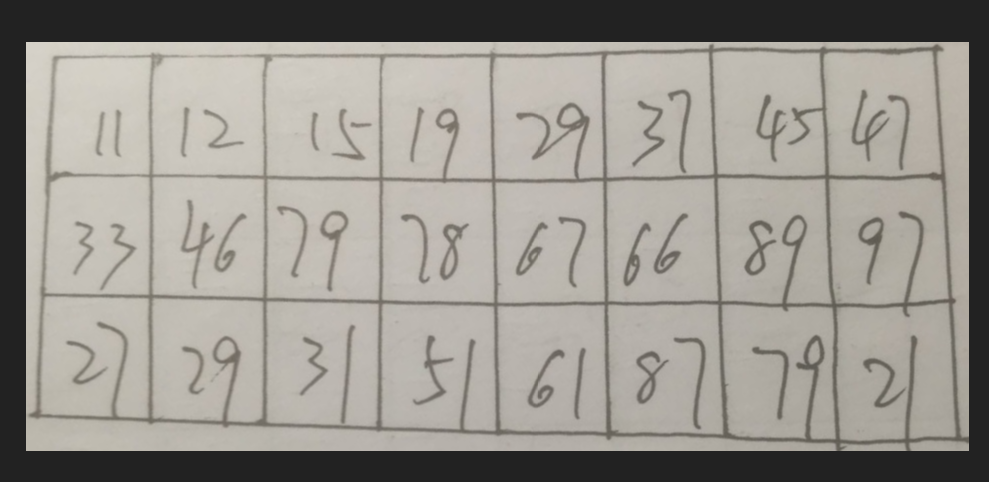
我们采用的是寻找轮廓的思路,来矫正图片;只要有明显的轮廓都可以采用这种思路
具体思路:
1、先用opencv提供的canny函数,进行一次边缘检测
2、再用opencv提供的findContours函数,寻找图像的轮廓,从中间结果种,找到最大的轮廓,就是我们图像的最外面的轮廓
3、得到最终轮廓后,计算矩形轮廓与水平的夹角,然后旋转图像
4、最后我们在从旋转后的图像中,把我们感兴趣的切割出来,就可以了
我们实际的实现一下
先用opencv提供的canny函数,进行一次边缘检测;具体的函数就不再讲解,百度上非常多
/**
* canny算法,边缘检测
*
* @param src
* @return
*/
public static Mat canny(Mat src) {
Mat mat = src.clone();
Imgproc.Canny(src, mat, 60, 200);
HandleImgUtils.saveImg(mat , "C:/Users/admin/Desktop/opencv/open/x/canny.jpg");
return mat;
}
再用opencv提供的findContours函数,寻找图像的轮廓,从中间结果种,找到最大的轮廓,就是我们图像的最外面的轮廓
/**
* 返回边缘检测之后的最大矩形,并返回
*
* @param cannyMat
* Canny之后的mat矩阵
* @return
*/
public static RotatedRect findMaxRect(Mat cannyMat) {
List<MatOfPoint> contours = new ArrayList<MatOfPoint>();
Mat hierarchy = new Mat();
// 寻找轮廓
Imgproc.findContours(cannyMat, contours, hierarchy, Imgproc.RETR_EXTERNAL, Imgproc.CHAIN_APPROX_NONE,
new Point(0, 0));
// 找出匹配到的最大轮廓
double area = Imgproc.boundingRect(contours.get(0)).area();
int index = 0;
// 找出匹配到的最大轮廓
for (int i = 0; i < contours.size(); i++) {
double tempArea = Imgproc.boundingRect(contours.get(i)).area();
if (tempArea > area) {
area = tempArea;
index = i;
}
}
MatOfPoint2f matOfPoint2f = new MatOfPoint2f(contours.get(index).toArray());
RotatedRect rect = Imgproc.minAreaRect(matOfPoint2f);
return rect;
}
得到最终轮廓后,计算矩形轮廓与水平的夹角,然后旋转图像
/**
* 旋转矩形
*
* @param src
* mat矩阵
* @param rect
* 矩形
* @return
*/
public static Mat rotation(Mat cannyMat, RotatedRect rect) {
// 获取矩形的四个顶点
Point[] rectPoint = new Point[4];
rect.points(rectPoint);
double angle = rect.angle + 90;
Point center = rect.center;
Mat CorrectImg = new Mat(cannyMat.size(), cannyMat.type());
cannyMat.copyTo(CorrectImg);
// 得到旋转矩阵算子
Mat matrix = Imgproc.getRotationMatrix2D(center, angle, 0.8);
Imgproc.warpAffine(CorrectImg, CorrectImg, matrix, CorrectImg.size(), 1, 0, new Scalar(0, 0, 0));
return CorrectImg;
}
最后我们在从旋转后的图像中,把我们感兴趣的切割出来,就可以了
/**
* 把矫正后的图像切割出来
*
* @param correctMat
* 图像矫正后的Mat矩阵
*/
public static void cutRect(Mat correctMat , Mat nativeCorrectMat) {
// 获取最大矩形
RotatedRect rect = findMaxRect(correctMat);
Point[] rectPoint = new Point[4];
rect.points(rectPoint);
int startLeft = (int)Math.abs(rectPoint[0].x);
int startUp = (int)Math.abs(rectPoint[0].y < rectPoint[1].y ? rectPoint[0].y : rectPoint[1].y);
int width = (int)Math.abs(rectPoint[2].x - rectPoint[0].x);
int height = (int)Math.abs(rectPoint[1].y - rectPoint[0].y);
System.out.println("startLeft = " + startLeft);
System.out.println("startUp = " + startUp);
System.out.println("width = " + width);
System.out.println("height = " + height);
for(Point p : rectPoint) {
System.out.println(p.x + " , " + p.y);
}
Mat temp = new Mat(nativeCorrectMat , new Rect(startLeft , startUp , width , height ));
Mat t = new Mat();
temp.copyTo(t);
HandleImgUtils.saveImg(t , "C:/Users/admin/Desktop/opencv/open/x/cutRect.jpg");
}
整合整个过程
/**
* 矫正图像
*
* @param src
* @return
*/
public static void correct(Mat src) {
// Canny
Mat cannyMat = canny(src);
// 获取最大矩形
RotatedRect rect = findMaxRect(cannyMat);
// 旋转矩形
Mat CorrectImg = rotation(cannyMat , rect);
Mat NativeCorrectImg = rotation(src , rect);
//裁剪矩形
cutRect(CorrectImg , NativeCorrectImg);
HandleImgUtils.saveImg(src, "C:/Users/admin/Desktop/opencv/open/x/srcImg.jpg");
HandleImgUtils.saveImg(CorrectImg, "C:/Users/admin/Desktop/opencv/open/x/correct.jpg");
}
测试代码
/**
* 测试矫正图像
*/
public void testCorrect() {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
Mat src = HandleImgUtils.matFactory("C:/Users/admin/Desktop/opencv/open/x/x7.jpg");
HandleImgUtils.correct(src);
}
Java方面opencv的例子还是蛮少的,代码都是自己参考博客写的,照顾不周的地方,请见谅
本项目的所有代码地址:https://github.com/YLDarren/opencvHandleImg
Java基于opencv—矫正图像的更多相关文章
- Java基于opencv实现图像数字识别(五)—投影法分割字符
Java基于opencv实现图像数字识别(五)-投影法分割字符 水平投影法 1.水平投影法就是先用一个数组统计出图像每行黑色像素点的个数(二值化的图像): 2.选出一个最优的阀值,根据比这个阀值大或小 ...
- Java基于opencv实现图像数字识别(四)—图像降噪
Java基于opencv实现图像数字识别(四)-图像降噪 我们每一步的工作都是基于前一步的,我们先把我们前面的几个函数封装成一个工具类,以后我们所有的函数都基于这个工具类 这个工具类呢,就一个成员变量 ...
- Java基于opencv实现图像数字识别(三)—灰度化和二值化
Java基于opencv实现图像数字识别(三)-灰度化和二值化 一.灰度化 灰度化:在RGB模型中,如果R=G=B时,则彩色表示灰度颜色,其中R=G=B的值叫灰度值:因此,灰度图像每个像素点只需一个字 ...
- Java基于opencv实现图像数字识别(二)—基本流程
Java基于opencv实现图像数字识别(二)-基本流程 做一个项目之前呢,我们应该有一个总体把握,或者是进度条:来一步步的督促着我们来完成这个项目,在我们正式开始前呢,我们先讨论下流程. 我做的主要 ...
- Java基于opencv实现图像数字识别(一)
Java基于opencv实现图像数字识别(一) 最近分到了一个任务,要做数字识别,我分配到的任务是把数字一个个的分开:当时一脸懵逼,直接百度java如何分割图片中的数字,然后就百度到了用Buffere ...
- Java基于opencv实现图像数字识别(五)—腐蚀、膨胀处理
腐蚀:去除图像表面像素,将图像逐步缩小,以达到消去点状图像的效果:作用就是将图像边缘的毛刺剔除掉 膨胀:将图像表面不断扩散以达到去除小孔的效果:作用就是将目标的边缘或者是内部的坑填掉 使用相同次数的腐 ...
- Java基于OpenCV实现走迷宫(图片+路线展示)
Java基于OpenCV实现走迷宫(图片+路线展示) 由于疫情,待在家中,太过无聊.同学发了我张迷宫图片,让我走迷宫来缓解暴躁,于是乎就码了一个程序出来.特此记录. 原图: 这张图,由于不是非常清晰, ...
- Java基于opencv—透视变换矫正图像
很多时候我们拍摄的照片都会产生一点畸变的,就像下面的这张图 虽然不是很明显,但还是有一点畸变的,而我们要做的就是把它变成下面的这张图 效果看起来并不是很好,主要是四个顶点找的不准确,会有一些偏差,而且 ...
- 为基于OpenCV的图像处理程序编写界面—关于QT\MFC\CSharp的选择以及GOCW的介绍
基于OpenCV编写图像处理项目,除了算法以外,比较重要一个问题就是界面设计问题.对于c++语系的程序员来说,一般来说有QT/MFC两种考虑.QT的确功能强大,特别是QML编写andr ...
随机推荐
- JavaScript中的获取元素的方法
通过id获取元素 document.getElementById(id名字) 通过标签获取元素 document/元素.getElementsByTagName(标签名) 通过css选择器获取元素 d ...
- python运算符与数据类型
python运算符 Python语言支持以下类型的运算符: 算术运算符 比较(关系)运算符 赋值运算符 逻辑运算符 位运算符 成员运算符 身份运算符 运算符优先级 以下假设变量: a=10,b=20: ...
- spring为什么推荐使用构造器注入
一.前言 项目中遇到一个问题:项目启动完成前,在A类中注入B类,并调用B类的某个方法. 那么调用B类的这个方法写在哪里呢,我选择写到构造器里,但是构造器先于Spring注入执行,那么执行构造器时, ...
- elasticsearch kabana中创建索引
在kabana中创建索引和索引类型语法 PUT clockin{ "mappings": { "time": { } }} 查询索引下的所有数据 GET clo ...
- 代码规范mark一下
转自于:https://github.com/zh-google-styleguide/zh-google-styleguide/blob/master/google-python-styleguid ...
- java 反射获取方法返回值类型
//ProceedingJoinPoint pjp //获取方法返回值类型 Object[] args = pjp.getArgs(); Class<?>[] paramsCls = ne ...
- JavaWeb项目三要素
- org.apache.commons.vfs 配置文件里面 密码包含 @
登录ftp的用户名 sftpuser ,密码 @sftpuser 在配置文件里面 需要 把 @ 转义 成 %40 ftppath=sftp://sftpuser:%40sftpuser@127.0.0 ...
- Mysql和Hadoop+Hive有什么关系?
1.Hive不存储数据,Hive需要分析计算的数据,以及计算结果后的数据实际存储在分布式系统上,如HDFS上. 2.Hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑, ...
- 如何将plist大图拆分成原来的小图
我们一般为了提升性能和减少包体,大多会使用textpackture将图片打包成大图,有时候我们也需要查看它的原来小图,但是没有原图,这时候我们就可以使用cocos的工具,cocos studio. 预 ...