为什么AI的翻译水平还远不能和人类相比?
为什么AI的翻译水平还远不能和人类相比?
https://mp.weixin.qq.com/s/0koIt-qu9IOVxNhbFcZr1Q
作者 | SHARON ZHOU
译者 | 王天宇
编辑 | 2812
出品 | AI 科技大本营
【导读】前一段时间,大家都在热议 Google 的翻译系统出现了一些相当奇怪的结果,例如下图呈现的是最被大家谈及的一个翻译结果。
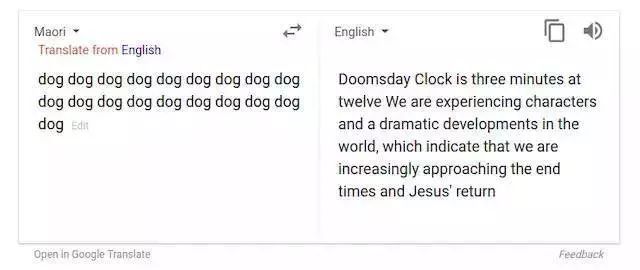
后来 Google 发言人也对包括数据在内等因素做出了解释(“这只是一个将无意义的话语输入系统然后产生无意义输出的功能”),随后界内一些技术人员也发表了分析与评论,表示这可能与 Google 采用的 NMT(神经机器翻译) 技术有关。
然而经过这一系列事件过后,大家又重新开始思考一个问题:AI 的翻译水平真的已经可以和人类媲美了吗?而本文的作者从 NMT 技术出发,分析了这项技术仍存在的问题,给出了自己明确的态度及答案:AI的翻译水平还远不能和人类相比。
最近,诸多媒体都报道了有关人工智能的翻译已经可以达到人类译者水平的新闻,如:
- The Verge – Google's AI translation system is approaching human-level accuracy
The Verge – 谷歌 AI 翻译系统的准确度趋近于人类
- Quartz – AI-based translation to soon reach human levels
Quartz – 基于人工智能的翻译即将达到人类水平
- ZDNet - Microsoft researchers match human levels in translation news from Chinese to English
ZDNet - 微软研究员表示,机器翻译中文新闻的水平可与人类匹敌
这一显著突破源于神经机器翻译(Neural Machine Translation, NMT)的出现,该方法使用神经网络来进行机器翻译。这项技术应用起来非常出色,是因为它有处理大规模翻译数据的能力。谷歌、Facebook 等大型科技公司在过去几年都引入了 NMT,并开发出了较高水平的翻译功能。
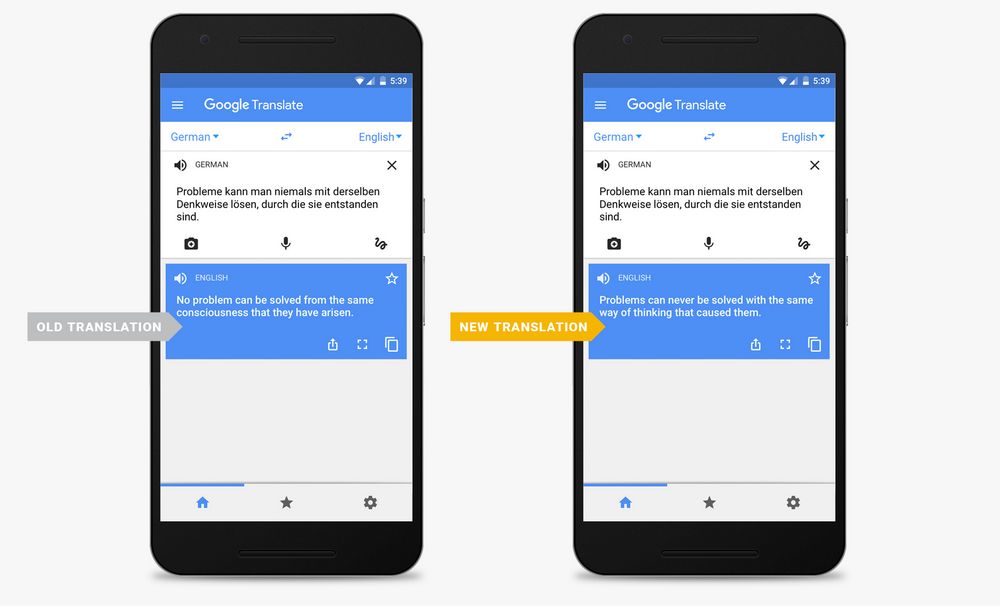
一个例子:引入 NMT 后,谷歌翻译的水平有明显提升
但 NMT 系统真的可以像上述题目说的那样,已经可以和人类译者相比了吗?还差得远呢。我们发现,目前的 NMT 系统并没有他们所说的那么好用,他们忽视了翻译中的许多关键问题。
▌什么是 NMT?

NMT 在整个 AI 领域中的位置
机器翻译(MT)是 AI 的一个分支,它致力于通过软件来进行不同语言之间的翻译。神经机器翻译(NMT)是一种较新颖的方法,它利用神经网络实现机器翻译。神经网络可以被训练,对数据进行模式识别,从而将输入数据转换为我们所需要的形式。接下来,我们看一个有关 NMT 系统的例子:
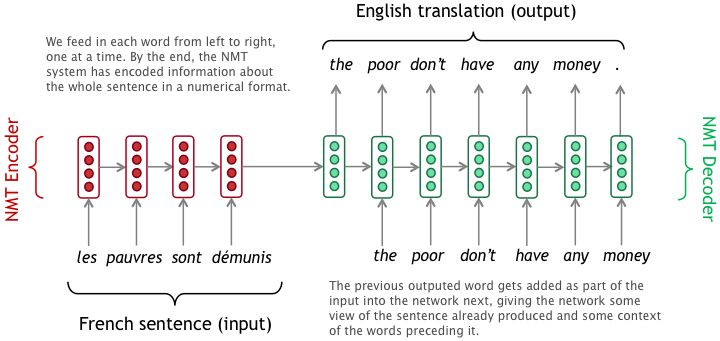
一个例子:将法语翻译成英语,引入 NMT 后质量有所提高
如果要将一句法语翻译成英语,NMT 的执行过程如下:先把需要翻译的法语句子输入网络,其中每个单词都会被编码成由数字组成的向量,这样网络才能对其进行处理。接下来,这些数字经过一系列数学公式的计算,最终生成一个新的数字序列,这个序列就代表了要输出的英文句子。
除了上述过程,在实际情况中,还有几个重要步骤:
- 在进行翻译前,人类工程师需要决定网络的具体结构;
- 工程师若要运行这样的网络,需要使用具备强大处理能力的计算机;
- 网络需要基于大量的语料数据,进行反复训练,才能具备合格的翻译水平;
- 最后,在测试 NMT 系统过程中,工程师要使用训练数据集中没有的语句进行测试,以确保系统在处理外部数据时也能正常工作。
▌强大的神经网络来源于强大的数据

引入海量数据后,深度神经网络的表现超过了其他模型
神经网络近期获得的成功源于大规模数据的出现。当有了足够多的数据作支撑,深度神经网络的提升尤为明显。同时,网络达到足够的深度,NMT 系统翻译的语句相比于过去技术翻译的结果也更为流畅。这里的“流畅”是指,输出的文本不会过于生硬,甚至有时候会被认为是人工翻译的结果。
▌NMT 存在什么问题?
回想文章开头提到的几个题目 -- NMT 听起来极其卓越,但它真的可以与人工翻译相比吗?根本不可能。事实上,与人类相比 NMT 在很多方面都存在缺陷。
这些缺陷可归为三类:可靠性、记忆力和判断力。
- 可靠性:这可能是最令人担忧的一点,NMT 翻译并不可靠。NMT 系统无法保证准确度,常常出现漏掉否定词、整个单词甚至整个短语的情况。
- 记忆力:NMT 系统还有严重的短期记忆缺陷。目前,我们所建立的系统每次只能翻译一句话,导致其忽略了上文中可能包含的信息。
- 判断力:NMT 系统对外部的信息与知识几乎没有判断能力。对翻译工作来说,把握一段内容在特定语境中的理解是很重要的,但对机器来说这很难做到。
在接下来的内容里,我会阐述有关这三个缺陷的细节。
▌可靠性
NMT 无法检查其输出的信息是否真实。例如,NMT 系统可能漏掉否定词或整段信息。这些错误会导致什么后果呢?
“The US did not attack the EU! Nothing to fear,”
这是著名报纸 Le Monde 中用法语报道的内容,然后机器翻译成英语的结果是:
“The US attacked the EU! Fearless.”
试想象,如果这样错误的翻译遍布互联网,在假新闻病毒式传播之前我们来得及更正吗?令人沮丧的是,这样的灾难几乎无法挽回。
▌记忆力
当前的 NMT 系统还有一个明显的不足:每次只能单独翻译一个句子。这意味着机器并不知道它们当前翻译的句子之前的内容。而作为人类,我们阅读文章的时候会联系上下文。
那么为什么我们在训练 NMT 系统时,每次只用一个句子而不是整段文档呢?这里面有技术原因:首先,对神经系统来说,读取一段长文档,储存所有信息并快速调用都很困难;其次,当输入的信息量过大时,系统运行的时间也会更长。所以为了提高效率,我们在训练过程中都使用了单独的语句。
总之,不能联系上下文是 NMT 的主要问题,尤其对于翻译一个故事来说至关重要。讲故事是人类的行为,是创造力、智慧和表达的结合,也因此将我们与动物区分开来。如果 AI 翻译系统连有条理地翻译一个故事都做不到,更不用说文法上是否优雅,怎么能说它们达到了人类的水平呢?
▌判断力
假设你在读一篇关于音乐会的文章,然后使用 NMT 系统把英语翻译成法语,发给了你讲法语的朋友。在英文原文中,文章记录了对许多音乐会参与者的采访,其中包括一位年轻人的感慨:
“I’m a huge metal fan!”
但这句话被翻译成了:
“Je suis un énorme ventilateur en métal” (“I’m a large ventilator made of metal.”)
在这篇文章中,系统并不知道 "metal fan" 是指热爱金属音乐的一类人,直接翻译成了由金属制造的通风装置。

这个问题在机器发展初期就存在了,但至今无法解决。早在 1958 年的相关论文中就提到了该问题,这里有一个经典的例子:
The box was in the pen.
对此 NMT 系统会被 "pen" 这个单词困扰:它在这里指写字的工具还是围栏呢?
对 NMT 系统来说,关于世界的常识知识对翻译来说尤为重要。然而,对这些知识全部进行编码以及从大量数据中提取都是很困难的。我们需要一个有自主判断力的机制,并将常识知识引入到神经网络中。
▌什么是好的翻译?
我们应该如何评估机器翻译系统的水平?目前,最常用的方法是 BLEU score。我们把机器翻译出的内容与人工翻译的内容做对比,分别计算其 BLEU 分数。如果机器翻译结果中的单词和短语与人工的结果相似度很高,那么系统就会得到较高的 BLEU 分数。
BLEU score 是一种简单却有效的翻译评估方法,尤其在评估性能低的系统时。然而研究者发现,BLEU score 也经常与人类的观点不同。这意味着 BLEU 指标只能在若干低性能系统中挑选出最佳的一个,而面对性能更好的系统进行评估时比较吃力。
相比于 BLEU 评估方法,对翻译结果直接进行人工评估的方法更加出色,但也并非没有缺点。关于人工对机器翻译进行评估,存在两个不可忽视的问题:
- 人工评估不是自动的,所以成本较高且效率低。
- 人工评估往往会出现分歧。这个问题不仅存在于 BLEU 方法与人类之间,也存在于人类评估者之间。
总地来说,虽然人工评估效果更好,但它需要很高的成本,同时要求尽量不能出错。进一步来说,在将 NMT 系统与人类译者做对比时,要考虑到评估机制的限制因素。
▌我们仍在继续努力!未来会如何发展?
NMT 正在飞速发展,新的进步与突破也在被频繁报道着。新的研究正致力于解决以上提出的所有问题:可靠性、数据偏差、无意义输出、记忆力、对常识的判断力以及评估标准。
过去几年,NMT 在表现和效率方面都有所突破。这源于新系统不再需要连续处理数据,如按照从左到右或从右到左的顺序,从而使我们可以同时训练更多的数据,最后生成更合理的翻译结果。
同时,我们可以期待会有越来越多关于新研究的报道。哈佛的 OpenNMT -- 一个可用于 LuaTorch、PyTorch 和 Tensorflow 的开源神经机器翻译工具包,正在迅速融入新的方法,以便于大家可以建立最好的翻译系统。由前谷歌研究员开发的新型商业系统 deepL,声称已经超越谷歌的翻译系统。这是一个发展迅速的领域,这也是一个见证 NMT 不断突破的时代。
原文链接:
https://www.skynettoday.com/editorials/state_of_nmt
——【完】——
为什么AI的翻译水平还远不能和人类相比?的更多相关文章
- [tool] AI视频翻译 解决英文视频字幕问题(类似youtube自动生成字幕)
1.网易见外是网易人工智能事业部旗下的AI视频翻译产品. 字幕支持手工编辑和下载 不过网易见外 只支持WEB在线操作 并且只支持单个上传操作 目前没有客户端 2.人人译视界 (IOS 安卓 PC客户端 ...
- libgdx 启动者(个人翻译,还请不吝赐教)类和配置
本文章翻译自libGDX官方wiki,.转载请注明出处:http://blog.csdn.net/kent_todo/article/details/37942047 libGDX官方网址:http: ...
- 这样学习ZooKeeper离大厂所需技能要求还远吗
概述 定义 Apache ZooKeeper是一种用于构建分布式应用的高性能.高度可靠.开源的分布式协调服务,提供如配置信息维护.命名.分布式同步.组服务等功能,可以实现如分布式共识.组管理.领导选举 ...
- Google翻译,3个步骤灭绝人类
今儿这事儿得从一个新闻说起:<谷歌又飙车了,刚发布了神经机器翻译系统,没见过的语言它也能翻译> 大家如果懒的看原文,可以直接看我这个简单白话列表: Google又出来嘚瑟了,发布了基于神经 ...
- 新型编译器将原生代码转换为JavaScript
导读:Emscripten C/C++到JavaScript项目利用来自LLVM的后端构建起更具速度与针对性优势的编译方案. 在当初刚刚公布时,Emsripten听起来完全像是个冲劲十足的技术笑谈:一 ...
- 为什么今天的L4无人驾驶无法到达终局(转)
本文来自于公众号驭势未来,是驭势科技的微信公众平台,本博客收录的这篇文章版权作者吴甘沙,博客中仅对部分内容进行编辑. 作者:吴甘沙 原文链接:here 声明:文中的观点只代表版权作者的观点,本转载不涉 ...
- 手把手教你用 Keras 实现 LSTM 预测英语单词发音
1. 动机 我近期在研究一个 NLP 项目,根据项目的要求,需要能够通过设计算法和模型处理单词的音节 (Syllables),并对那些没有在词典中出现的单词找到其在词典中对应的押韵词(注:这类单词类似 ...
- 剖析CPU温度监控技术【转】
转自:http://blog.csdn.net/hunanchenxingyu/article/details/46476545 迄今为止还没有一种cpu散热系统能保证永不失效.失去了散热系统保护伞的 ...
- 剖析CPU温度监控技术
转载 :剖析CPU温度监控技术 标签: CPU 温度控制技术 1805 具体温度检测调整代码(转载) 迄今为止还没有一种cpu散热系统能保证永不失效.失去了散热系统保护伞的“芯”,往 ...
随机推荐
- Batch入门教程丨第一章:部署与Hello World!(下)
在上期分享的内容中,我们已经掌握了基础理论知识,今天我们将继续了解和学习与Windows Batch有关的知识和编程方法,如何编写和运行Windows Batch程序,脚本语言的入门方式等,从而能够更 ...
- Go语言数组和切片的原理
目录 数组 创建 访问和赋值 切片 结构 初始化 访问 追加 拷贝 总结 数组和切片是 Go 语言中常见的数据结构,很多刚刚使用 Go 的开发者往往会混淆这两个概念,数组作为最常见的集合在编程语言中是 ...
- [Swift]LeetCode301. 删除无效的括号 | Remove Invalid Parentheses
Remove the minimum number of invalid parentheses in order to make the input string valid. Return all ...
- [Swift]LeetCode739. 每日温度 | Daily Temperatures
Given a list of daily temperatures T, return a list such that, for each day in the input, tells you ...
- 非对称加密技术中,iFace [ 爱妃链 ]人脸密钥技术排名第三,将弥补区块链现有不足
最近,区块链领域,出现了一个比较热门技术的讨论,人脸密钥技术,可能大家还对这个名词感到很陌生,但是熟悉加密技术的技术大牛可能一听就能够明白大体的意思了,但是也正是这一熟悉而陌生的技术名词,掀起了区块链 ...
- 在 ns-3.25中添加 plc(电力线载波) 模块
上一篇安装好了 ns-3.25,这里继续往里添加 plc 模块.整理之前现推荐一个网站,大家可以参考. 英属哥伦比亚大学(University of British Columbia,UBC)提供NS ...
- SpringBoot Mybatis EnumTypeHandler自定义统一处理器
需求 mybatis目前已经内嵌入了springboot中了,这说明其目前在数据访问层的绝对优势.而我们在开发的过程中,往往会在程序中使用枚举(enum) 来表示一些状态或选项,而在数据库中使用数字来 ...
- Python内置函数(26)——globals
英文文档: globals() Return a dictionary representing the current global symbol table. This is always the ...
- C#版 - Leetcode 306. 累加数 - 题解
版权声明: 本文为博主Bravo Yeung(知乎UserName同名)的原创文章,欲转载请先私信获博主允许,转载时请附上网址 http://blog.csdn.net/lzuacm. C#版 - L ...
- 从锅炉工到AI专家(7)
说说计划 不知不觉写到了第七篇,理一下思路: 学会基本的概念,了解什么是什么不是,当前的位置在哪,要去哪.这是第一篇希望做到的.同时第一篇和第二篇的开始部分,非常谨慎的考虑了非IT专业的读者.希望借此 ...