矩池云 | Tony老师解读Kaggle Twitter情感分析案例

今天Tony老师给大家带来的案例是Kaggle上的Twitter的情感分析竞赛。在这个案例中,将使用预训练的模型BERT来完成对整个竞赛的数据分析。
导入需要的库
import numpy as np
import pandas as pd
from math import ceil, floor
import tensorflow as tf
import tensorflow.keras.layers as L
from tensorflow.keras.initializers import TruncatedNormal
from sklearn import model_selection
from transformers import BertConfig, TFBertPreTrainedModel, TFBertMainLayer
from tokenizers import BertWordPieceTokenizer
读取并解释数据
在竞赛中,对数据的理解是非常关键的。因此我们首先要做的就是读取数据,然后查看数据的内容以及特点。
先用pandas来读取csv数据,
train_df = pd.read_csv('train.csv')
train_df.dropna(inplace=True)
test_df = pd.read_csv('test.csv')
test_df.loc[:, "selected_text"] = test_df.text.values
submission_df = pd.read_csv('sample_submission.csv')
再查看下我们的数据的数量,我们一共有27485条训练数据,3535条测试数据,
print("train numbers =", train_df.shape)
print("test numbers =", test_df.shape)
紧接着查看训练数据和测试数据前10条表单的字段跟数据,表单中包含了一下几个数据字段:
textID: 文本数据记录的唯一ID;
text: 原始语句;
selected_text: 表示情感的语句;
sentiment: 情感类型, neutral中立, positive积极, negative消极;
从数据中我们可以得出,目标就是根据现有的情感从原本是的语句中选出能代表这个情感的语句部分。
train_df.head(10)
test_df.head(10)
定义常量
# bert预训练权重跟数据存放的目录
PATH = "./bert-base-uncased/"
# 语句最大长度
MAX_SEQUENCE_LENGTH = 128
载入词向量
BERT是依据一个固定的词向量来进行训练的。因此在竞赛中需要先使用BertWordPieceTokenizer来加载这些词向量,其中的lowercase=True表示所有的词向量都是小写。设置大小写不敏感可以减少模型对资源的占用。
TOKENIZER = BertWordPieceTokenizer(f"{PATH}/vocab.txt", lowercase=True)
定义数据加载器
定义数据预处理函数
def preprocess(tweet, selected_text, sentiment):
# 将被转成byte string的原始字符串转成utf-8的字符串
tweet = tweet.decode('utf-8')
selected_text = selected_text.decode('utf-8')
sentiment = sentiment.decode('utf-8')
tweet = " ".join(str(tweet).split())
selected_text = " ".join(str(selected_text).split())
# 标记出selected text和text共有的单词
idx_start, idx_end = None, None
for index in (i for i, c in enumerate(tweet) if c == selected_text[0]):
if tweet[index:index+len(selected_text)] == selected_text:
idx_start = index
idx_end = index + len(selected_text)
break
intersection = [0] * len(tweet)
if idx_start != None and idx_end != None:
for char_idx in range(idx_start, idx_end):
intersection[char_idx] = 1
# 对原始数据用词向量进行编码, 这里会返回原始数据中的词在词向量中的下标
# 和原始数据中每个词向量的单词在文中的起始位置跟结束位置
enc = TOKENIZER.encode(tweet)
input_ids_orig, offsets = enc.ids, enc.offsets
target_idx = []
for i, (o1, o2) in enumerate(offsets):
if sum(intersection[o1: o2]) > 0:
target_idx.append(i)
target_start = target_idx[0]
target_end = target_idx[-1]
sentiment_map = {
'positive': 3893,
'negative': 4997,
'neutral': 8699,
}
# 将情感标签和原始的语句的词向量组合在一起组成我们新的数据
input_ids = [101] + [sentiment_map[sentiment]] + [102] + input_ids_orig + [102]
input_type_ids = [0] * (len(input_ids_orig) + 4)
attention_mask = [1] * (len(input_ids_orig) + 4)
offsets = [(0, 0), (0, 0), (0, 0)] + offsets + [(0, 0)]
target_start += 3
target_end += 3
# 计算需要paddning的长度, BERT是以固定长度进行输入的,因此对于不足的我们需要做pandding
padding_length = MAX_SEQUENCE_LENGTH - len(input_ids)
if padding_length > 0:
input_ids = input_ids + ([0] * padding_length)
attention_mask = attention_mask + ([0] * padding_length)
input_type_ids = input_type_ids + ([0] * padding_length)
offsets = offsets + ([(0, 0)] * padding_length)
elif padding_length < 0:
pass
return (
input_ids, attention_mask, input_type_ids, offsets,
target_start, target_end, tweet, selected_text, sentiment,
)
定义数据加载器
class TweetDataset(tf.data.Dataset):
outputTypes = (
tf.dtypes.int32, tf.dtypes.int32, tf.dtypes.int32,
tf.dtypes.int32, tf.dtypes.float32, tf.dtypes.float32,
tf.dtypes.string, tf.dtypes.string, tf.dtypes.string,
)
outputShapes = (
(128,), (128,), (128,),
(128, 2), (), (),
(), (), (),
)
def _generator(tweet, selected_text, sentiment):
for tw, st, se in zip(tweet, selected_text, sentiment):
yield preprocess(tw, st, se)
def __new__(cls, tweet, selected_text, sentiment):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.outputTypes,
output_shapes=cls.outputShapes,
args=(tweet, selected_text, sentiment)
)
@staticmethod
def create(dataframe, batch_size, shuffle_buffer_size=-1):
dataset = TweetDataset(
dataframe.text.values,
dataframe.selected_text.values,
dataframe.sentiment.values
)
dataset = dataset.cache()
if shuffle_buffer_size != -1:
dataset = dataset.shuffle(shuffle_buffer_size)
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
return dataset
定义模型
我们使用BERT模型来进行这次竞赛,这里对BERT模型做一些简单的介绍。
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。
模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别representation。
BERT主要特点如下:
使用了Transformer作为算法的主要框架,Trabsformer能更彻底的捕捉语句中的双向关系;
使用了Mask Language Model 和 Next Sentence Prediction的多任务训练目标;
使用更强大的机器训练更大规模的数据,Google开源了BERT模型,我们可以直接使用BERT作为Word2Vec的转换矩阵并高效的将其应用到自己的任务中。
BERT的本质是在海量的语料基础上,运行自监督学习方法让单词学习得到一个较好的特征表示。
在之后特定任务中,可以直接使用BERT的特征表示作为该任务的词嵌入特征。所以BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。
在竞赛中,我们定义了一个BertModel类,里面使用TFBertPreTrainedModel来进行推理。
BERT的输出我们保存在hidden_states中,然后将这个得到的hidden_states结果在加入到Dense Layer,最后输出我们需要提取的表示情感的文字的起始位置跟结束位置。
这两个位置信息就是我们需要从原文中提取的词向量的位置。
class BertModel(TFBertPreTrainedModel):
# drop out rate, 防止过拟合
dr = 0.1
# hidden state数量
hs = 2
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.bert = TFBertMainLayer(config, name="bert")
self.concat = L.Concatenate()
self.dropout = L.Dropout(self.dr)
self.qa_outputs = L.Dense(
config.num_labels,
kernel_initializer=TruncatedNormal(stddev=config.initializer_range),
dtype='float32',
name="qa_outputs")
@tf.function
def call(self, inputs, **kwargs):
_, _, hidden_states = self.bert(inputs, **kwargs)
hidden_states = self.concat([
hidden_states[-i] for i in range(1, self.hs+1)
])
hidden_states = self.dropout(hidden_states, training=kwargs.get("training", False))
logits = self.qa_outputs(hidden_states)
start_logits, end_logits = tf.split(logits, 2, axis=-1)
start_logits = tf.squeeze(start_logits, axis=-1)
end_logits = tf.squeeze(end_logits, axis=-1)
return start_logits, end_logits
定义训练函数
def train(model, dataset, loss_fn, optimizer):
@tf.function
def train_step(model, inputs, y_true, loss_fn, optimizer):
with tf.GradientTape() as tape:
y_pred = model(inputs, training=True)
loss = loss_fn(y_true[0], y_pred[0])
loss += loss_fn(y_true[1], y_pred[1])
scaled_loss = optimizer.get_scaled_loss(loss)
scaled_gradients = tape.gradient(scaled_loss, model.trainable_variables)
gradients = optimizer.get_unscaled_gradients(scaled_gradients)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss, y_pred
epoch_loss = 0.
for batch_num, sample in enumerate(dataset):
loss, y_pred = train_step(model, sample[:3], sample[4:6], loss_fn, optimizer)
epoch_loss += loss
print(
f"training ... batch {batch_num+1:03d} : "
f"train loss {epoch_loss/(batch_num+1):.3f} ",
end='\r')
定义预制函数
def predict(model, dataset, loss_fn, optimizer):
@tf.function
def predict_step(model, inputs):
return model(inputs)
def to_numpy(*args):
out = []
for arg in args:
if arg.dtype == tf.string:
arg = [s.decode('utf-8') for s in arg.numpy()]
out.append(arg)
else:
arg = arg.numpy()
out.append(arg)
return out
offset = tf.zeros([0, 128, 2], dtype=tf.dtypes.int32)
text = tf.zeros([0,], dtype=tf.dtypes.string)
selected_text = tf.zeros([0,], dtype=tf.dtypes.string)
sentiment = tf.zeros([0,], dtype=tf.dtypes.string)
pred_start = tf.zeros([0, 128], dtype=tf.dtypes.float32)
pred_end = tf.zeros([0, 128], dtype=tf.dtypes.float32)
for batch_num, sample in enumerate(dataset):
print(f"predicting ... batch {batch_num+1:03d}"+" "*20, end='\r')
y_pred = predict_step(model, sample[:3])
# add batch to accumulators
pred_start = tf.concat((pred_start, y_pred[0]), axis=0)
pred_end = tf.concat((pred_end, y_pred[1]), axis=0)
offset = tf.concat((offset, sample[3]), axis=0)
text = tf.concat((text, sample[6]), axis=0)
selected_text = tf.concat((selected_text, sample[7]), axis=0)
sentiment = tf.concat((sentiment, sample[8]), axis=0)
pred_start, pred_end, text, selected_text, sentiment, offset = \
to_numpy(pred_start, pred_end, text, selected_text, sentiment, offset)
return pred_start, pred_end, text, selected_text, sentiment, offset
判断函数
这个竞赛采用单词级Jaccard系数,计算公式如下
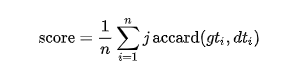
Jaccard系数计算的是你预测的单词在数据集中的个数,
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))
定义预测结果解码函数
解码函数通过模型预测拿到的start和end的index位置信息,然后和之前拿到的词向量在样本句子中的位置进行比较,将这个区间内的所有的单词都提取出来作为我们的预测结果。
def decode_prediction(pred_start, pred_end, text, offset, sentiment):
def decode(pred_start, pred_end, text, offset):
decoded_text = ""
for i in range(pred_start, pred_end+1):
decoded_text += text[offset[i][0]:offset[i][1]]
if (i+1) < len(offset) and offset[i][1] < offset[i+1][0]:
decoded_text += " "
return decoded_text
decoded_predictions = []
for i in range(len(text)):
if sentiment[i] == "neutral" or len(text[i].split()) < 2:
decoded_text = text[i]
else:
idx_start = np.argmax(pred_start[i])
idx_end = np.argmax(pred_end[i])
if idx_start > idx_end:
idx_end = idx_start
decoded_text = str(decode(idx_start, idx_end, text[i], offset[i]))
if len(decoded_text) == 0:
decoded_text = text[i]
decoded_predictions.append(decoded_text)
return decoded_predictions
开始训练
将训练数据分成5个folds,每个folds训练5个epoch,使用adam优化器,learning rate设置成3e-5,batch size使用32。
num_folds = 5
num_epochs = 5
batch_size = 32
learning_rate = 3e-5
optimizer = tf.keras.optimizers.Adam(learning_rate)
optimizer = tf.keras.mixed_precision.experimental.LossScaleOptimizer(
optimizer, 'dynamic')
config = BertConfig(output_hidden_states=True, num_labels=2)
model = BertModel.from_pretrained(PATH, config=config)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
kfold = model_selection.KFold(
n_splits=num_folds, shuffle=True, random_state=42)
test_preds_start = np.zeros((len(test_df), 128), dtype=np.float32)
test_preds_end = np.zeros((len(test_df), 128), dtype=np.float32)
for fold_num, (train_idx, valid_idx) in enumerate(kfold.split(train_df.text)):
print("\nfold %02d" % (fold_num+1))
# 创建train, valid, test数据集
train_dataset = TweetDataset.create(
train_df.iloc[train_idx], batch_size, shuffle_buffer_size=2048)
valid_dataset = TweetDataset.create(
train_df.iloc[valid_idx], batch_size, shuffle_buffer_size=-1)
test_dataset = TweetDataset.create(
test_df, batch_size, shuffle_buffer_size=-1)
best_score = float('-inf')
for epoch_num in range(num_epochs):
print("\nepoch %03d" % (epoch_num+1))
train(model, train_dataset, loss_fn, optimizer)
pred_start, pred_end, text, selected_text, sentiment, offset = \
predict(model, valid_dataset, loss_fn, optimizer)
selected_text_pred = decode_prediction(
pred_start, pred_end, text, offset, sentiment)
jaccards = []
for i in range(len(selected_text)):
jaccards.append(
jaccard(selected_text[i], selected_text_pred[i]))
score = np.mean(jaccards)
print(f"valid jaccard epoch {epoch_num+1:03d}: {score}"+" "*15)
if score > best_score:
best_score = score
# predict test set
test_pred_start, test_pred_end, test_text, _, test_sentiment, test_offset = \
predict(model, test_dataset, loss_fn, optimizer)
test_preds_start += test_pred_start * 0.2
test_preds_end += test_pred_end * 0.2
# 重置模型,避免OOM
session = tf.compat.v1.get_default_session()
graph = tf.compat.v1.get_default_graph()
del session, graph, model
model = BertModel.from_pretrained(PATH, config=config)
预测测试数据,并生成提交文件
selected_text_pred = decode_prediction(
test_preds_start, test_preds_end, test_text, test_offset, test_sentiment)
def f(selected):
return " ".join(set(selected.lower().split()))
submission_df.loc[:, 'selected_text'] = selected_text_pred
submission_df['selected_text'] = submission_df['selected_text'].map(f)
submission_df.to_csv("submission.csv", index=False)
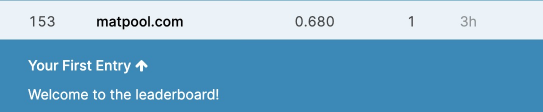
这个方案在提交的时候在553个队伍中排名153位, 分数为0.68。
Twitter情感分析案例之后会在矩池云Demo镜像中上线,可以直接使用。另矩池云还支持了Paddle、MindSpore、MegEngine、Jittor等国产深度学习框架,可免安装直接运行。
矩池云 | Tony老师解读Kaggle Twitter情感分析案例的更多相关文章
- 矩池云 | 高性价比的GPU租用深度学习平台
矩池云是一个专业的国内深度学习云平台,拥有着良好的深度学习云端训练体验.在性价比上,我们以 2080Ti 单卡为例,36 小时折扣后的价格才 55 元,每小时单价仅 1.52 元,属于全网最低价.用户 ...
- 矩池云上使用nvidia-smi命令教程
简介 nvidia-smi全称是NVIDIA System Management Interface ,它是一个基于NVIDIA Management Library(NVML)构建的命令行实用工具, ...
- 矩池云里查看cuda版本
可以用下面的命令查看 cat /usr/local/cuda/version.txt 如果想用nvcc来查看可以用下面的命令 nvcc -V 如果环境内没有nvcc可以安装一下,教程是矩池云上如何安装 ...
- 在矩池云上复现 CVPR 2018 LearningToCompare_FSL 环境
这是 CVPR 2018 的一篇少样本学习论文:Learning to Compare: Relation Network for Few-Shot Learning 源码地址:https://git ...
- 矩池云上安装yolov4 darknet教程
这里我是用PyTorch 1.8.1来安装的 拉取仓库 官方仓库 git clone https://github.com/AlexeyAB/darknet 镜像仓库 git clone https: ...
- 用端口映射的办法使用矩池云隐藏的vnc功能
矩池云隐藏了很多高级功能待用户去挖掘. 租用机器 进入jupyterlab 设置vnc密码 VNC_PASSWD="userpasswd" ./root/vnc_startup.s ...
- 矩池云上安装ikatago及远程链接教程
https://github.com/kinfkong/ikatago-resources/tree/master/dockerfiles 从作者的库中可以看到,该程序支持cuda9.2.cuda10 ...
- 矩池云上编译安装dlib库
方法一(简单) 矩池云上的k80因为内存问题,请用其他版本的GPU去进行编译,保存环境后再在k80上用. 准备工作 下载dlib的源文件 进入python的官网,点击PyPi选项,搜索dilb,再点击 ...
- 如何在矩池云上运行FinRL-Libray股票交易策略框架
FinRL-Libray 项目:https://github.com/AI4Finance-LLC/FinRL-Library 选择FinRL镜像 在矩池云-主机市场选择合适的机器,并选择FinRL- ...
随机推荐
- ApacheCN 数据库译文集 20211112 更新
创建你的 Mysql 数据库 零.前言 一.介绍 MySQL 设计 二.数据采集 三.数据命名 四.数据分组 五.数据结构调整 六.补充案例研究 Redis 学习手册 零.序言 一.NoSQL 简介 ...
- AT2401 [ARC072C] Alice in linear land
基于观察,可以发现这样一条性质: 我们并不关心当前位置和终点的绝对关系,只在乎当前位置和终点的距离,当这个距离确定的时候接下来能走到的位置也是确定的. 基于这个观察可以发现,本质上每个位置的状态就是和 ...
- Shell中退出状态码exit
shell中运行的每个命令都使用退出状态码(exit status)来告诉shell它完成了处理.退出状态码是一个0~255之间的整数值,在命令结束时由命令传回shell. 1 .查看退出状态码 Li ...
- Failed to connect to raw.githubusercontent.com 443 解决方案
wget 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid ...
- 利用shell脚本[带注释的]部署单节点多实例es集群(docker版)
文章目录 目录结构 install_docker_es.sh elasticsearch.yml.template 没事写写shell[我自己都不信,如果不是因为工作需要,我才不要写shell],努力 ...
- Dubbo扩展点应用之二负载均衡
负载均衡其本质就是将请求分摊到多个操作单元上进行,从而共同完成工作任务.其策略主要用于客户端春常在多个提供者时根据算法选择某个提供者.在集群负载均衡时,Dubbo提供了多种均衡策略(包括随机.轮询.最 ...
- 【摸鱼神器】UCode Cms管理系统 内置超好用的代码生成器 解决多表连接痛点
一.序言 UCode Cms管理系统是面向企业级应用软件开发的脚手架.当前版本1.3.4.快速体验: git clone https://gitee.com/decsa/demo-cms.git (一 ...
- 反射、反射机制、类加载、Class类专题复习
一.反射概念 1.反射机制允许程序在执行期借助于ReflectionAPI取得任何类的内部信息(比如成员变量,构造器,成员方法等等),并能操作对象的属性及方法.反射在设计模式和框架底层都会用到. 2. ...
- CSRF靶场练习
实验目的 了解CSRF跨站伪造请求实验 实验原理 CSRF的原理 CSRF(Cross-site Request Forgery)是指跨站点请求伪造,也就是跨站漏洞攻击,通常用来指 WEB 网站的这一 ...
- 单网口RFC2544测试——信而泰网络测试仪实操
一.测试拓扑 拓扑说明 测试仪一个端口和DUT一个端口相连 DUT假设是一台交换设备,它能够把测试仪发送的流量直接转发回来 注意:要求DUT必须能够把收到的流量环回出来,否则没有办法测试 二.测试思路 ...