网络协议自动化逆向工具开山鼻祖discoverer 分析
本文系原创,转载请说明出处:信安科研人
也可关注微信公众号:信安科研人

原论文发表在2007年的USENIX上,链接如下:https://www.usenix.org/legacy/event/sec07/tech/full_papers/cui/cui.pdf
我看目前国内很少有对这个工具具体的实现细节进行分析,仅仅是提及这个工具是协议自动化逆向的开山鼻祖,因此出此文章。
@
简介
在当时的情况下,网络协议逆向的几个难点:
- 对所处理的网络流知之甚少,只有一个数据流向
- 不同协议所显示的明显不同
- 协议消息格式通常是上下文敏感的,其中较早的字段决定了对消息后续部分的解析。
discover的工作与贡献:
1)设计基于推断大部分协议消息格式中常见的协议特定的惯用语,从而能够多种协议通用。
2)将无格式的字节流,分解为文本和二进制段或标记,作为对具有相似模式的消息进行聚类的出发点,其中每个聚类都近似于一种消息格式。
通过比较集群中的消息并观察已知的跨字段依赖的特征(例如长度字段后跟着相应长度的字符串),推断token的其他属性,进而可以利用这些属性细化和划分消息簇,其中每个子簇近似于更精确的格式。 这个过程递归地继续,直到不能再根据新完成的推理划分任何消息集群。
在这个递归聚类阶段之后,通过基于类型的序列比对算法全局地查看所有消息集群,并将相似的集群合并为一个,这样可以生成更简洁的消息格式。
一、背景知识
多种协议之间的共同惯用语
很多应用层协议共享相同的协议特定惯用语,这些惯用语对应协议规范中的基本组件。为了使逆向工程算法适用于更多的协议,设计基于推断常见的协议习惯用法。
1)协议状态机
大多数应用程序级协议都涉及应用程序会话的概念,其由完成特定任务的两个主机之间的一系列消息(也称为应用程序级数据单元或 ADU)组成。应用程序会话的结构由应用程序的协议状态机确定,协议状态机是协议规范中的一个重要组成部分,用于表征所有可能的合法消息序列。
2)消息格式规范
应用程序消息的结构由应用程序的消息格式规范决定,这是协议规范中的另一个重要组成部分。消息格式指定了一系列字段及其语义。
常见的字段语义包括长度(以可变长度反映后续字段的大小)、偏移量(确定另一个字段从某个点(如消息的开头)开始的字节偏移量)、指针(指定任意项数组中字段的索引)、cookie(出现在来自应用程序会话双方的消息中的特定于会话的不透明数据;会话 ID 是 cookie 字段的示例)、端点地址(编码 IP 地址或端口某种形式的数字)和集合(一组可以按任意顺序排列的字段)。
一种特殊类型的字段是 Format Distinguisher (FD) 字段。该字段的值用于区分消息后续部分的格式,这反映了许多应用程序级协议语法中的上下文敏感特性。一条消息可能有一系列 FD 字段,特别是在封装多个协议时。
例如,CIFS/SMB 消息由封装 SMB 头的 NetBIOS 头组成,而 SMB 头又可以封装 RPC 消息。这意味着应用程序需要从左到右扫描消息,在解析消息的后续部分之前解码 FD 字段。
本文专注于推导消息格式规范,并将协议状态机推断留给未来的工作。
二、设计概览

核心思想:将相同格式的消息聚起来,然后通过在单个聚类中比较以推断消息格式。
共三个阶段!
阶段1 > 标识化与初始化聚类
该模块处理初始化数据包,识别一个消息报文的区域边界,并反馈第一阶顺序的结构至未标签的消息报文。
1 标识化
标识,下文都用token来表示,一个标识是一段连续的字节序列,这些连续的字节序列有很大的可能属于同一应用层字段。
在对消息进行标识化的过程中,不需要对消息的字段中的二进制字段与文本字段进行特别的区分,因为作者发明discoverer工具的初衷之一就是全自动化的让用户免于陷入手动区分文本字段与二进制字段的过程中。另一个原因是真的很难很难认定这个协议是纯文本协议还是纯二进制协议,因为文本协议可能包含二进制字段(例如HTTP协议传输一个二进制图片),二进制协议又可能包含一些文本字段(例如传输一个文件的名字)。
标识化过程主要产生两种标识,也就是上文说到的二进制token和文本token。
对于文本token:
文本token旨在跨越地表示某些文本的单个消息字段的几个字节(例如 HTTP 请求中的“GET”)。识别文本token的程序如下:
1)通过与可打印出来的ascii字符进行比较,来识别文本字段;
2)将夹在两个二进制字节之间的文本序列视为文本字段。
为了不将二进制字段识别为文本字段,discoverer认定这个字节序列有最小的长度。然后,用一些间隔符号,将这些文本序列分成token。discoverer也会寻找消息报文中的unicode编码。
对于二进制token:
真的很难找到token的边界。 在这里仅仅是将单个字节视作一个二进制token。这个过程可能会出现如下的错误:
- 具有可打印字符的 ASCII 值的连续二进制字节被错误地标记为文本标记;
- 短于最小长度的文本字符串被错误地标记为二进制标记;
- 由一些空白字符组成的文本字段被错误地划分为多个文本标记。
不用着急,在discoverer的合并阶段解决这个问题。
2 通过token模式初始化聚类
基于 Needleman-Wunsch 算法的逐字节序列比对已在先前的很多研究中用于比对和比较消息。 逐字节序列对齐虽然非常适合对齐具有相似字节模式的消息,但不适合对齐具有相同格式的消息。 例如,具有可变长度的字段可能会导致两个相同格式的消息不对齐。 此外,序列比对的参数选择也很困难。
为了避免这种问题,discoverer通过token模式初始化第一次消息聚类,一个token模式是一个元组,格式如下:
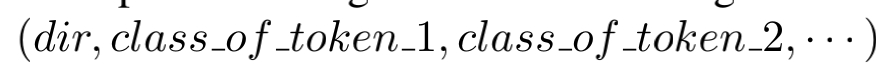
其中,dir代表消息传送的方向,后面跟着一个消息中的所有token类。考虑到dir的原因是响应包与请求包往往有着不同的消息格式。如:
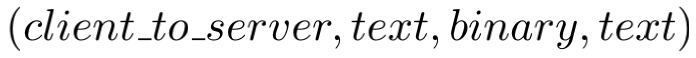
需要注意的是,初始聚类是粗粒度的,因为具有不同格式的消息可能具有相同的token 模式。 例如,SMTP 命令通常有两个文本标记(“MAIL 接收者”、“RCPT 发件人”、“HELO 服务器名称”)。
discoverer将在递归聚类阶段,通过递归识别 FD(格式区分字段) token 和 划分聚类来提高这种聚类的粒度。
阶段2 > 递归聚类
递归聚类的核心是识别格式区分符 (FD) token。 为了找到 FD 标记,需要格式推断和格式比较。
1 格式推断
格式推断阶段将一组消息作为输入,并推断出简洁地捕获该组消息内容的格式。所推断出来的消息格式不仅包括token的语义,还包括token属性。
引入token属性是因为无法推断每个token的语义含义,并且某些token属性对于描述消息格式很有用。token属性包括,二进制与文本,常量与变量。也就是两大类,第一类表示token的类别,第二类决定令牌是在相同格式消息中采用相同的值还是可变的值。同时,对于标记的类别,定义为语义和属性的总和。
属性推断
首先,在标记化阶段(第一阶段)已经确定了token类别。
第二,常量或变量token也可以很容易地识别。 因为一组中的消息的token模式是相同的,那么就可以通过简单地使用token偏移量直接将一条消息中的token与另一条消息中的对应toekn进行比较。 因此,常量token是那些在整个消息集中采用相同值的token,而可变token是那些采用多个值的token。
语义推断
discoverer支持三种语义:长度、偏移量、cookie。
- 对于cookie的推断,需要在合并阶段也就是第三阶段结束时识别。
而对于长度和偏移量,discoverer用到了这篇文章中提到的做法的扩展,主要是启发式的方法,具体内容有机会再具体写。
- 对于长度字段,直觉上来说,两个消息中该区域的令牌不同可能会让两个消息的大小不同,或者后续的一些token不同。也就是说,将消息大小的差值与token之间的差值匹配可以起到较为有效的认定。如果说,这个集群种,所有的消息对之间的差值都能与所有消息对之间的token的差值相匹配,那么就认定这个是长度token。
- 对于偏移量字段,将值差异与一些后续token的偏移量差异相匹配。
2 格式比较
此过程的目标是确定两个推断的消息格式是否相同。 给定两种格式,从左到右逐个标记地扫描这两种格式,并将一种格式的标记的推断类型(即语义和属性)与另一种格式的对应部分进行匹配。 如果所有标记都匹配,则认为这两种格式相同。
理想情况下,如果两个token的语义匹配,则可以认为它们匹配。 然而,由于总是存在没有语义的token,因此需要比较它们的值(它们具有相同的token类因为两种格式具有相同的token模式):
如果变量token至少取一次常量token的值,则允许常量token与变量token匹配;
如果两个变量token之间所取的两组值有重叠,则允许变量token与另一变量token匹配。
3 通过格式比较器递归聚类
识别FD token的方法如下:
- 首先对一个消息集群使用格式推断;
- 接着,从左到右以token为单位逐个扫描消息格式,以识别FD TOKEN。
三种标准判断FD token:
首先检查该token在一组消息中采取的独特值的数量是否小于一个阈值,那么将这个阈值称为FD token的最大的不同值。 这是因为fd token的取值通常与不同格式的总数相对应。

对于满足第一个标准的token,进行的第二次测试。将整个集群按照这个token的不同取值分为几个子集群。也就是每个子集群由候选FD TOKEN所采取的特定的值分成。认定最大的子消息集群的大小超过了一个阈值,这个阈值被称为最小集群大小。这么做可以至少在一个子集群中的格式推断有效果,否则这么划分什么都得不到。比如,一个子群如果只有一个消息,那我推断个锤子。

当候选FD TOKEN过了第二关,调用上一节的格式比较来判断这些子集群之间的格式是否两两不同。然后合并那些相同的格式的子集群并保持其他完整不变,那么未合并的token与其他token互相独立成为其对应的格式代表,以达到一种识别格式区分符的目的。
这个过程在每个子集群上递归执行,因为一条消息可能有多个 FD token。 通过向消息的右侧(末尾)进一步向下扫描消息来找到下一个 FD token。 这就需要一直扫描到最后,因为需要识别所有的 FD 以获得较完善的聚类和格式推断。
在查找下一个 FD token时,会再次对每个子集群中的消息集调用格式推断。 这是因为推断的token属性和语义可能会因为消息集变得更小而改变,并且有可能拥有更强的属性。 例如,以前可变的token现在可能是常量令牌; 以前可变的令牌现在可能被标识为长度字段。
阶段3 > 与基于类型的序列比对合并
1 问题提出
在标记化和递归聚类阶段,算法保守地确保格式推理过程在一组相同格式的消息上正确地运行。 然而,这导致了过度分类的新问题,即相同格式的消息可能分散到多个集群中。 这个问题可能非常严重; 例如,在近 400 万条消息的 CIFS/SMB 网络流中,有大约 7,000 个簇/格式作为此阶段的输入,而真正格式的总数为 130。合并过程的目标是将来自不同集群的相似格式合并为一个单一的格式。
合并阶段背后的关键是,虽然序列比对不能用于对相同格式的消息进行聚类,但它可以用于对齐格式以识别不同聚类中的相似消息。 这是因为可以利用在递归聚类阶段推断出的多样化的token类型(即语义和属性),例如,知道一个特定的token是一种格式中的一个长度字段,就需要它在另一种格式中的对应物也是一个长度字段,这两种格式才能被认为是匹配的。 那么,本文将用于对齐格式的算法称为基于类型的序列对齐。
在基于类型的序列比对中,只允许同一类(二进制或文本)的两个标记相互比对。同时声称如果两个对齐的标记具有相同的语义或共享至少一个值,则它们是匹配的。
2 补偿标记化阶段做法
为了补偿标记化阶段错误,允许在基于类型的序列比对中存在间隙。除了使用差距惩罚来控制差距之外,本文还引入了额外的约束来避免过度的差距。
- 首先,一种消息格式的连续二进制token如果在对齐中位于另一种消息格式的文本token之前或之后,则允许与间隙对齐,并且二进制token的数量最多为文本token的大小,如果文本token与间隙对齐,或者如果与另一个文本token对齐,则为大小差异。此约束用于处理将二进制token序列误认为是文本token或反之亦然的情况。
- 其次,允许文本token与间隙对齐,但最多允许两个此类间隙。此约束用于处理由一些空白字符组成的文本字段被错误地划分为多个token的情况。
3 合并
当对齐和比较两种消息格式以决定是否合并它们时,首先检查是否可以满足间隙约束。如果不满足,停止并声称这两种格式不匹配;否则,继续检查不匹配的数量。如果最多有一对对齐的token不匹配,声称这两种格式匹配并合并它们。请注意,这是一种比较保守的方式,因为不匹配的token可以被视为变量token,它从涵盖两种格式的新集合中获取值。
由于使用间隙约束和不匹配的数量来决定是否合并两种消息格式,因此的合并性能对序列比对参数(匹配、不匹配和间隙的分数)不敏感。
三 举例
为了更好的理解,这里给出一个基于SMB“Tree Connect AndX Request”消息格式的具体例子来解释Discoverer的设计和输出。从 Ethereal 获得真实的消息格式(参见图 2 和图 3)。 Discoverer 的最终推断格式如表 1 所示。
1 效果
首先是图 2:Ethereal 的示例 SMB“Tree Connect AndX 请求”消息的 XML 输出(经过编辑以更好地展示)

看起来很复杂,而discoverer主要是用来识别格式区域的,所以可以简化成识别这些:

然后识别出来的效果如下:

这个表格展示了Discoverer 对图 3 中真实格式所推断出来的格式。对于 C(x,y),C 表示常量,x 表示二进制(“b”)或文本(“t”,即文本;在文本token中,“u”表示 Unicode ,“n” 表示它以空值结尾),y 是令牌的十六进制值或字符串; 对于 V(x,z),V表示变量,x与上文相同,z 是token的不同值的数量。
2 结果分析
可以看到,推断的格式是具有标记属性(二进制与文本、常量与变量)和语义(例如长度字段)的标记序列。对于语义未知的token,格式中也考虑了它们的可能值。
在合并步骤之前,这种真实格式的消息以 18 种不同的token模式分散到 24 个集群中。不同的token模式归因于“smb.signature”字段。
由于该字段可能采用任何随机值,因此当不同偏移量的三个以上连续字节从可打印的 ASCII 范围内获取值并被错误地视为文本token时,将具有不同的token模式。由于方法比较保守,某些token模式中的消息在递归聚类阶段被进一步拆分为细粒度的集群。合并技术有效地缓解了这种过度分类问题。最后,所有 24 个集群合并为一个集群。
此示例还显示了不精确的字段边界的可能性。例如,字段“smb.nt status”的第一个空字节被视为它之前的文本标记的空终止符。但是,discoverer认为这种不精确不会影响推断格式的有效性,而是会为“smb.nt status”创建一些具有不同值的额外推断格式。
网络协议自动化逆向工具开山鼻祖discoverer 分析的更多相关文章
- 网络协议分析之wireshark---抓包使用
Wireshark基本介绍和学习TCP三次握手 之前写过一篇博客:用 Fiddler 来调试HTTP,HTTPS. 这篇文章介绍另一个好用的抓包工具wireshark, 用来获取网络数据封包,包括ht ...
- 网络抓包及Http Https通信协议分析
Wireshark基本介绍和学习TCP三次握手 之前写过一篇博客:用 Fiddler 来调试HTTP,HTTPS. 这篇文章介绍另一个好用的抓包工具wireshark, 用来获取网络数据封包,包括ht ...
- (1.3.1)连接安全(连接实例与网络协议及TDS端点)
连接安全是sql server安全配置的第1道防线,它保证只有许可的客户端能够连接sql server,而且可以限制连接可用的通道(各种网络协议). 1.连接到sql server实例 sql ser ...
- NETPLIER : 一款基于概率的网络协议逆向工具(一)理论
本文系原创,转载请说明出处:信安科研人 关注微信公众号 信安科研人 获取更多网络安全学术技术资讯 今日介绍一篇发表在2021 NDSS会议上的一项有关协议逆向的工作: @ 目录 1 网络协议逆向工程简 ...
- 网络协议图形化分析工具EtherApe
网络协议图形化分析工具EtherApe 在对网络数据分析的时候,渗透测试人员往往只关心数据流向以及协议类型,而不关心具体数据包的内容.因为这样可以快速找到网络的关键节点或者重要的协议类型. Kal ...
- PYTHON黑帽编程1.5 使用WIRESHARK练习网络协议分析
Python黑帽编程1.5 使用Wireshark练习网络协议分析 1.5.0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks At ...
- TFTP网络协议分析---15
TFTP网络协议分析 周学伟 文档说明:所有函数都依托与两个出口,发送和接收. 1:作为发送时,要完成基于TFTP协议下的文件传输,但前提是知道木的PC机的MAC地址,因为当发送TFTP请求包时必须提 ...
- Wireshark数据抓包分析——网络协议篇
Wireshark数据抓包分析--网络协议篇 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvZGF4dWViYQ==/ ...
- linux 网络协议分析---3
本章节主要介绍linxu网络模型.以及常用的网络协议分析以太网协议.IP协议.TCP协议.UDP协议 一.网络模型 TCP/IP分层模型的四个协议层分别完成以下的功能: 第一层 网络接口层 网络接口层 ...
随机推荐
- kali下对Docker的详细安装
镜像下载.域名解析.时间同步请点击 阿里云开源镜像站 前言 Docker是渗透测试中必学不可的一个容器工具,在其中,我们能够快速创建.运行.测试以及部署应用程序.如,我们对一些漏洞进行本地复现时,可以 ...
- python 模块之 selenium 自动化使用教程
一.安装 pip install Selenium 二.初始化浏览器 Chrome 是初始化谷歌浏览器 Firefox 是初始化火狐浏览器 Edge 是初始化IE浏览器 PhantomJS 是一个无界 ...
- 《前端运维》四、Jenkins--持续构建
首先,我们先来了解下什么叫做持续构建.持续构建简称CI,负责拉取代码库中的代码后,执行用户预定义的脚本,通过一系列编译操作构建出一个制品,并将制品推送到制品库里.常用的持续构建工具有 Gitlab C ...
- 什么是GUI?
图形用户界面(Graphical User Interface,简称 GUI,又称图形用户接口)是指采用图形方式显示的计算机操作用户界面.图形用户界面是一种人与计算机通信的界面显示格式,允许用户使用鼠 ...
- docker容器登录,退出等操作命令
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口 ...
- idea-spring-boot打包jar/var
下面的插件配置的里面需要加上具体的main类 <groupId>org.springframework.boot</groupId> <artifactId>spr ...
- HTML 5中不同的新表单元素类型是什么?
HTML 5推出了10个重要的新的表单元素: Color. Date Datetime-local Email Time Url Range Telephone Number Search
- 区分 BeanFactory 和 ApplicationContext?
BeanFactory ApplicationContext 它使用懒加载 它使用即时加载 它使用语法显式提供资源对象 它自己创建和管理资源对象 不支持国际化 支持国际化 不支持基于依赖的注解 支持基 ...
- springboot项目中的日志输出
#修改默认输出级别,trace < debug < info < warn < errorlogging.level.com.lagou=trace#控制台输出logging. ...
- (stm32学习总结)—SPI-FLASH 实验
SPI总线 SPI 简介 SPI 的全称是"Serial Peripheral Interface",意为串行外围接口,是Motorola 首先在其 MC68HCXX 系列处理器上 ...